 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vision Transformers for Single Image Dehazing
Apr 08, 2022
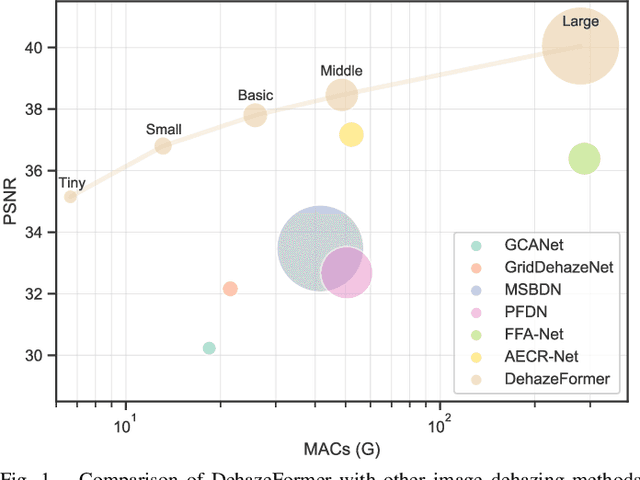


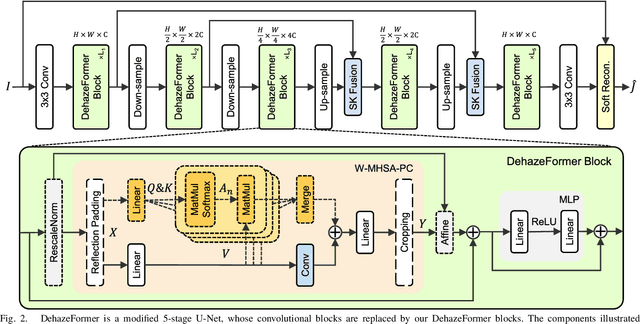
Image dehazing is a representative low-level vision task that estimates latent haze-free images from hazy images. In recent years, convolutional neural network-based methods have dominated image dehazing. However, vision Transformers, which has recently made a breakthrough in high-level vision tasks, has not brought new dimensions to image dehazing. We start with the popular Swin Transformer and find that several of its key designs are unsuitable for image dehazing. To this end, we propose DehazeFormer, which consists of various improvements, such as the modified normalization layer, activation function, and spatial information aggregation scheme. We train multiple variants of DehazeFormer on various datasets to demonstrate its effectiveness. Specifically, on the most frequently used SOTS indoor set, our small model outperforms FFA-Net with only 25% #Param and 5% computational cost. To the best of our knowledge, our large model is the first method with the PSNR over 40 dB on the SOTS indoor set, dramatically outperforming the previous state-of-the-art methods. We also collect a large-scale realistic remote sensing dehazing dataset for evaluating the method's capability to remove highly non-homogeneous haze.
Backdoor Attack Detection in Computer Vision by Applying Matrix Factorization on the Weights of Deep Networks
Dec 15, 2022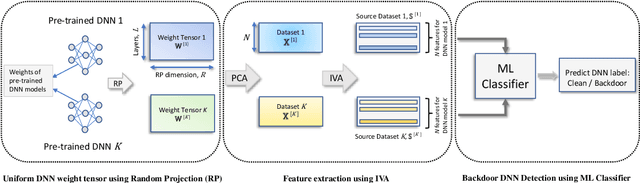
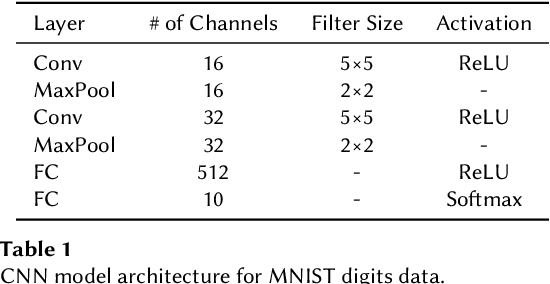
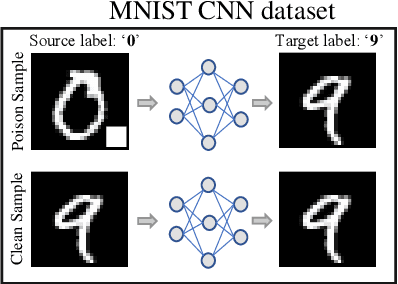
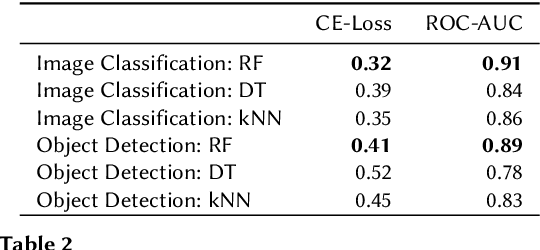
The increasing importance of both deep neural networks (DNNs) and cloud services for training them means that bad actors have more incentive and opportunity to insert backdoors to alter the behavior of trained models. In this paper, we introduce a novel method for backdoor detection that extracts features from pre-trained DNN's weights using independent vector analysis (IVA) followed by a machine learning classifier. In comparison to other detection techniques, this has a number of benefits, such as not requiring any training data, being applicable across domains, operating with a wide range of network architectures, not assuming the nature of the triggers used to change network behavior, and being highly scalable. We discuss the detection pipeline, and then demonstrate the results on two computer vision datasets regarding image classification and object detection. Our method outperforms the competing algorithms in terms of efficiency and is more accurate, helping to ensure the safe application of deep learning and AI.
Huber-energy measure quantization
Dec 15, 2022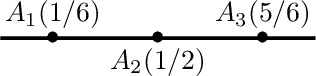
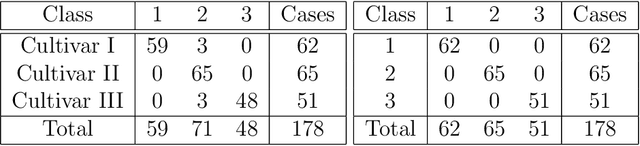
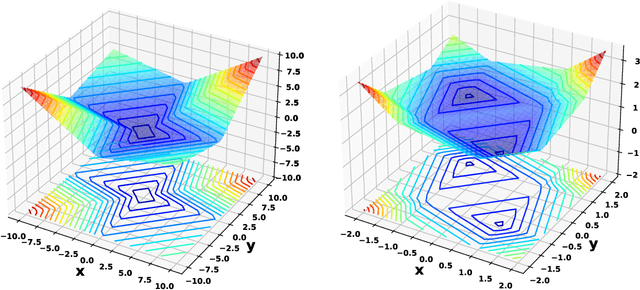
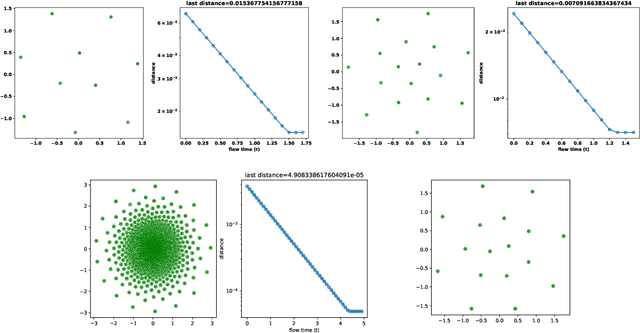
We describe a measure quantization procedure i.e., an algorithm which finds the best approximation of a target probability law (and more generally signed finite variation measure) by a sum of Q Dirac masses (Q being the quantization parameter). The procedure is implemented by minimizing the statistical distance between the original measure and its quantized version; the distance is built from a negative definite kernel and, if necessary, can be computed on the fly and feed to a stochastic optimization algorithm (such as SGD, Adam, ...). We investigate theoretically the fundamental questions of existence of the optimal measure quantizer and identify what are the required kernel properties that guarantee suitable behavior. We test the procedure, called HEMQ, on several databases: multi-dimensional Gaussian mixtures, Wiener space cubature, Italian wine cultivars and the MNIST image database. The results indicate that the HEMQ algorithm is robust and versatile and, for the class of Huber-energy kernels, it matches the expected intuitive behavior.
Task-Specific Data Augmentation and Inference Processing for VIPriors Instance Segmentation Challenge
Nov 21, 2022



Instance segmentation is applied widely in image editing, image analysis and autonomous driving, etc. However, insufficient data is a common problem in practical applications. The Visual Inductive Priors(VIPriors) Instance Segmentation Challenge has focused on this problem. VIPriors for Data-Efficient Computer Vision Challenges ask competitors to train models from scratch in a data-deficient setting, but there are some visual inductive priors that can be used. In order to address the VIPriors instance segmentation problem, we designed a Task-Specific Data Augmentation(TS-DA) strategy and Inference Processing(TS-IP) strategy. The main purpose of task-specific data augmentation strategy is to tackle the data-deficient problem. And in order to make the most of visual inductive priors, we designed a task-specific inference processing strategy. We demonstrate the applicability of proposed method on VIPriors Instance Segmentation Challenge. The segmentation model applied is Hybrid Task Cascade based detector on the Swin-Base based CBNetV2 backbone. Experimental results demonstrate that proposed method can achieve a competitive result on the test set of 2022 VIPriors Instance Segmentation Challenge, with 0.531 AP@0.50:0.95.
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models
Nov 21, 2022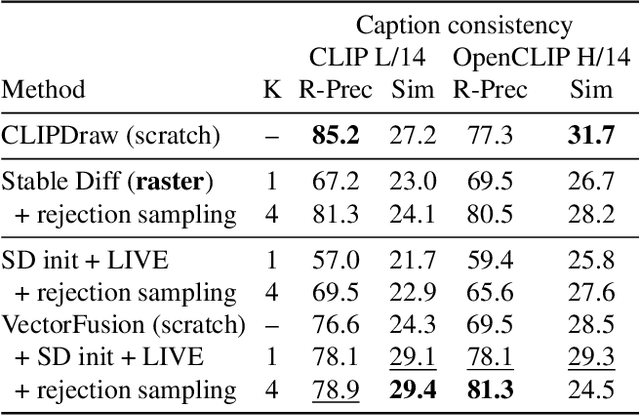
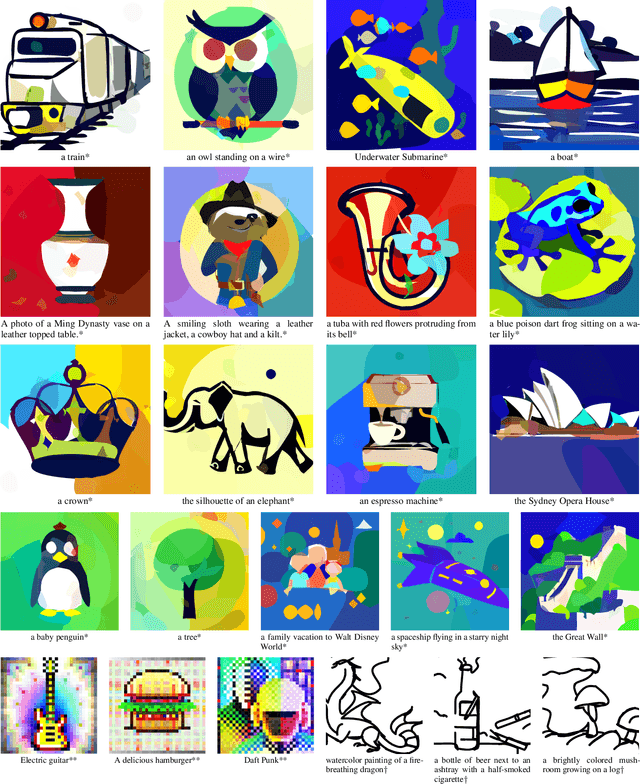

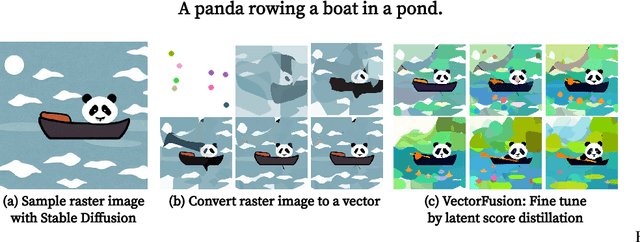
Diffusion models have shown impressive results in text-to-image synthesis. Using massive datasets of captioned images, diffusion models learn to generate raster images of highly diverse objects and scenes. However, designers frequently use vector representations of images like Scalable Vector Graphics (SVGs) for digital icons or art. Vector graphics can be scaled to any size, and are compact. We show that a text-conditioned diffusion model trained on pixel representations of images can be used to generate SVG-exportable vector graphics. We do so without access to large datasets of captioned SVGs. By optimizing a differentiable vector graphics rasterizer, our method, VectorFusion, distills abstract semantic knowledge out of a pretrained diffusion model. Inspired by recent text-to-3D work, we learn an SVG consistent with a caption using Score Distillation Sampling. To accelerate generation and improve fidelity, VectorFusion also initializes from an image sample. Experiments show greater quality than prior work, and demonstrate a range of styles including pixel art and sketches. See our project webpage at https://ajayj.com/vectorfusion .
Test Time Transform Prediction for Open Set Histopathological Image Recognition
Jun 20, 2022
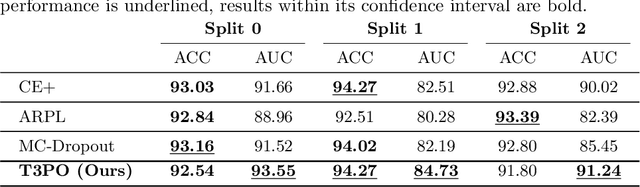
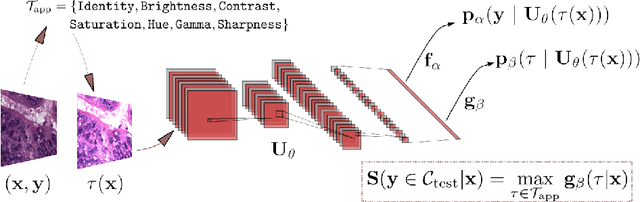
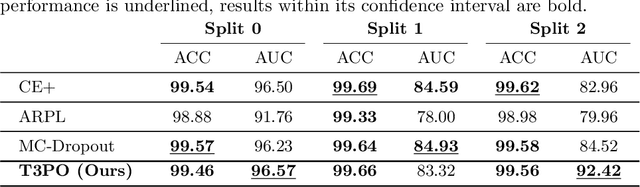
Tissue typology annotation in Whole Slide histological images is a complex and tedious, yet necessary task for the development of computational pathology models. We propose to address this problem by applying Open Set Recognition techniques to the task of jointly classifying tissue that belongs to a set of annotated classes, e.g. clinically relevant tissue categories, while rejecting in test time Open Set samples, i.e. images that belong to categories not present in the training set. To this end, we introduce a new approach for Open Set histopathological image recognition based on training a model to accurately identify image categories and simultaneously predict which data augmentation transform has been applied. In test time, we measure model confidence in predicting this transform, which we expect to be lower for images in the Open Set. We carry out comprehensive experiments in the context of colorectal cancer assessment from histological images, which provide evidence on the strengths of our approach to automatically identify samples from unknown categories. Code is released at https://github.com/agaldran/t3po .
Recurrent Image Registration using Mutual Attention based Network
Jun 04, 2022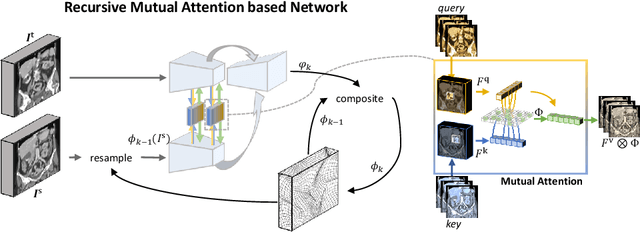
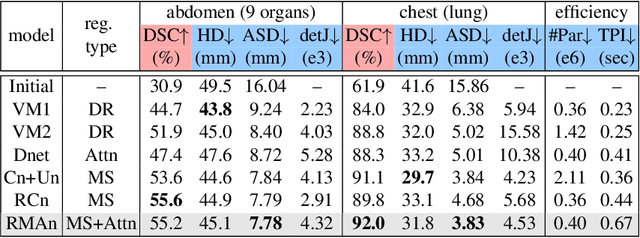
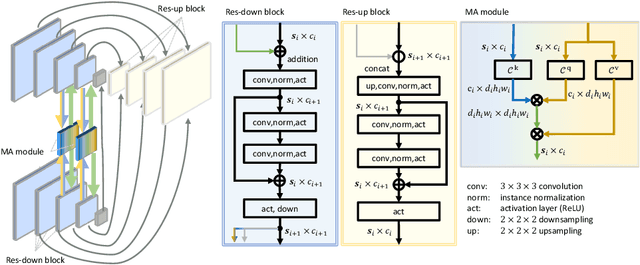
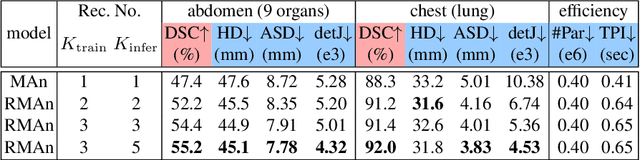
Image registration is an important task in medical imaging which estimates the spatial transformation between different images. Many previous studies have used learning-based methods for multi-stage registration to perform 3D image registration to improve performance. The performance of the multi-stage approach, however, is limited by the size of the receptive field where complex motion does not occur at a single spatial scale. We propose a new registration network combining recursive network architecture and mutual attention mechanism to overcome these limitations. Compared with the previous deep learning methods, our network based on the recursive structure achieves the highest accuracy in lung Computed Tomography (CT) data set (Dice score of 92\% and average surface distance of 3.8mm for lungs) and one of the most accurate results in abdominal CT data set with 9 organs of various sizes (Dice score of 55\% and average surface distance of 7.8mm). We also showed that adding 3 recursive networks is sufficient to achieve the state-of-the-art results without a significant increase in the inference time.
Predicting Eye Gaze Location on Websites
Nov 26, 2022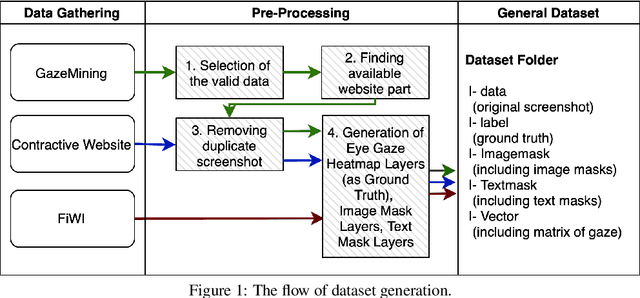
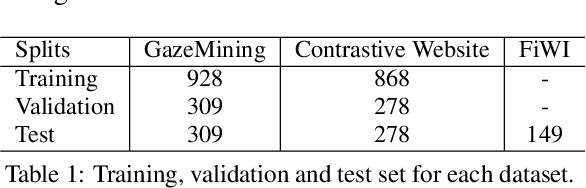
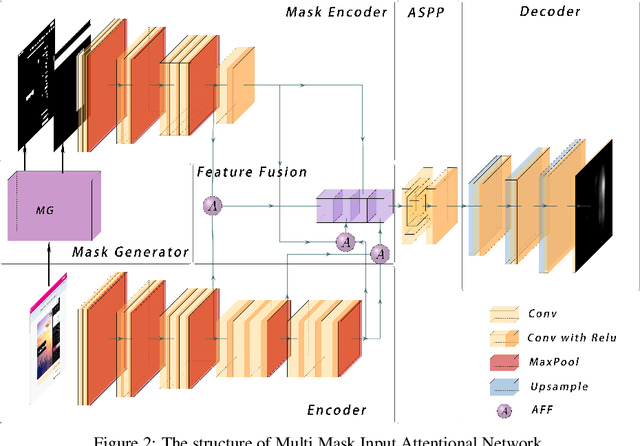
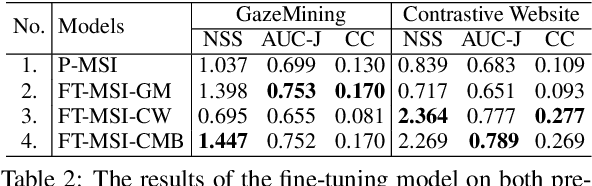
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.
Backdoor Attacks for Remote Sensing Data with Wavelet Transform
Nov 15, 2022
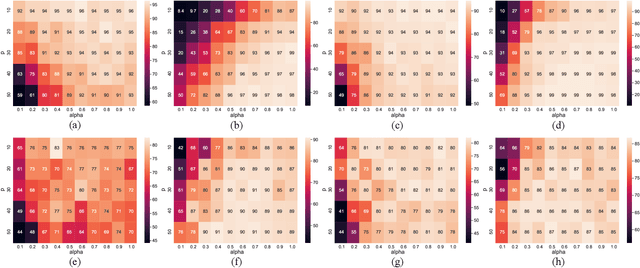

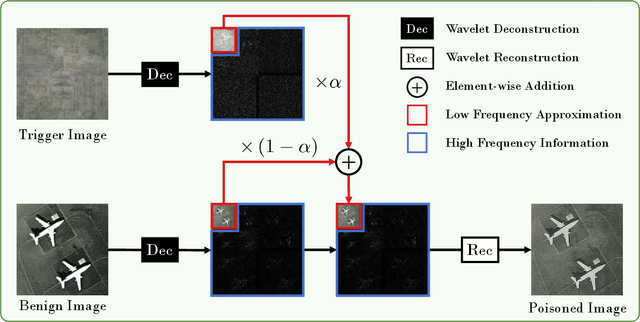
Recent years have witnessed the great success of deep learning algorithms in the geoscience and remote sensing realm. Nevertheless, the security and robustness of deep learning models deserve special attention when addressing safety-critical remote sensing tasks. In this paper, we provide a systematic analysis of backdoor attacks for remote sensing data, where both scene classification and semantic segmentation tasks are considered. While most of the existing backdoor attack algorithms rely on visible triggers like squared patches with well-designed patterns, we propose a novel wavelet transform-based attack (WABA) method, which can achieve invisible attacks by injecting the trigger image into the poisoned image in the low-frequency domain. In this way, the high-frequency information in the trigger image can be filtered out in the attack, resulting in stealthy data poisoning. Despite its simplicity, the proposed method can significantly cheat the current state-of-the-art deep learning models with a high attack success rate. We further analyze how different trigger images and the hyper-parameters in the wavelet transform would influence the performance of the proposed method. Extensive experiments on four benchmark remote sensing datasets demonstrate the effectiveness of the proposed method for both scene classification and semantic segmentation tasks and thus highlight the importance of designing advanced backdoor defense algorithms to address this threat in remote sensing scenarios. The code will be available online at \url{https://github.com/ndraeger/waba}.
Learning Treatment Plan Representations for Content Based Image Retrieval
Jun 06, 2022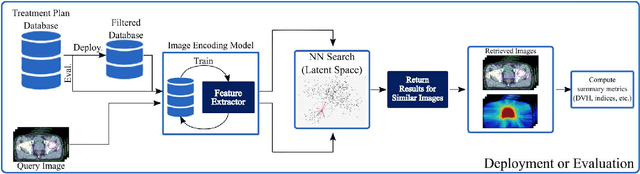

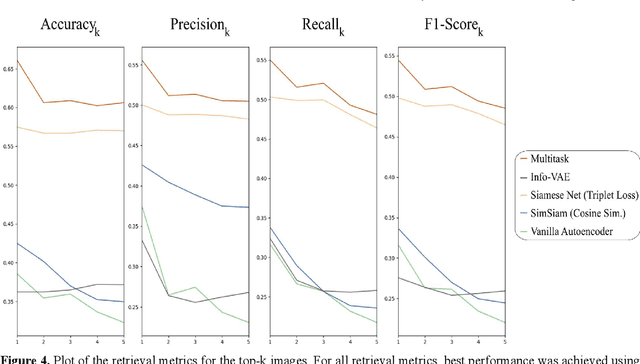
Objective: Knowledge based planning (KBP) typically involves training an end-to-end deep learning model to predict dose distributions. However, training end-to-end KBP methods may be associated with practical limitations due to the limited size of medical datasets that are often used. To address these limitations, we propose a content based image retrieval (CBIR) method for retrieving dose distributions of previously planned patients based on anatomical similarity. Approach: Our proposed CBIR method trains a representation model that produces latent space embeddings of a patient's anatomical information. The latent space embeddings of new patients are then compared against those of previous patients in a database for image retrieval of dose distributions. Summary metrics (e.g. dose-volume histogram, conformity index, homogeneity index, etc.) are computed and can then be utilized in subsequent automated planning. All source code for this project is available on github. Main Results: The retrieval performance of various CBIR methods is evaluated on a dataset consisting of both publicly available plans and clinical plans from our institution. This study compares various encoding methods, ranging from simple autoencoders to more recent Siamese networks like SimSiam, and the best performance was observed for the multitask Siamese network. Significance: Applying CBIR to inform subsequent treatment planning potentially addresses many limitations associated with end-to-end KBP. Our current results demonstrate that excellent image retrieval performance can be obtained through slight changes to previously developed Siamese networks. We hope to integrate CBIR into automated planning workflow in future works, potentially through methods like the MetaPlanner framework.