 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BAN-Cap: A Multi-Purpose English-Bangla Image Descriptions Dataset
May 28, 2022


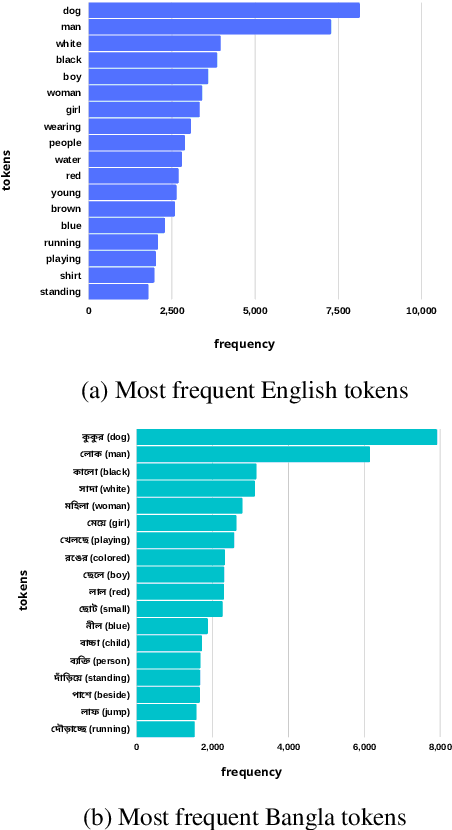

As computers have become efficient at understanding visual information and transforming it into a written representation, research interest in tasks like automatic image captioning has seen a significant leap over the last few years. While most of the research attention is given to the English language in a monolingual setting, resource-constrained languages like Bangla remain out of focus, predominantly due to a lack of standard datasets. Addressing this issue, we present a new dataset BAN-Cap following the widely used Flickr8k dataset, where we collect Bangla captions of the images provided by qualified annotators. Our dataset represents a wider variety of image caption styles annotated by trained people from different backgrounds. We present a quantitative and qualitative analysis of the dataset and the baseline evaluation of the recent models in Bangla image captioning. We investigate the effect of text augmentation and demonstrate that an adaptive attention-based model combined with text augmentation using Contextualized Word Replacement (CWR) outperforms all state-of-the-art models for Bangla image captioning. We also present this dataset's multipurpose nature, especially on machine translation for Bangla-English and English-Bangla. This dataset and all the models will be useful for further research.
Learning to Immunize Images for Tamper Localization and Self-Recovery
Oct 28, 2022

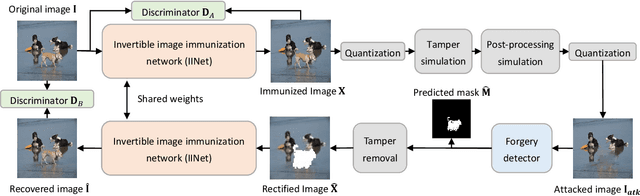
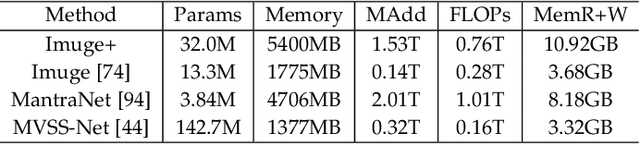
Digital images are vulnerable to nefarious tampering attacks such as content addition or removal that severely alter the original meaning. It is somehow like a person without protection that is open to various kinds of viruses. Image immunization (Imuge) is a technology of protecting the images by introducing trivial perturbation, so that the protected images are immune to the viruses in that the tampered contents can be auto-recovered. This paper presents Imuge+, an enhanced scheme for image immunization. By observing the invertible relationship between image immunization and the corresponding self-recovery, we employ an invertible neural network to jointly learn image immunization and recovery respectively in the forward and backward pass. We also introduce an efficient attack layer that involves both malicious tamper and benign image post-processing, where a novel distillation-based JPEG simulator is proposed for improved JPEG robustness. Our method achieves promising results in real-world tests where experiments show accurate tamper localization as well as high-fidelity content recovery. Additionally, we show superior performance on tamper localization compared to state-of-the-art schemes based on passive forensics.
Conditioning Covert Geo-Location (CGL) Detection on Semantic Class Information
Nov 27, 2022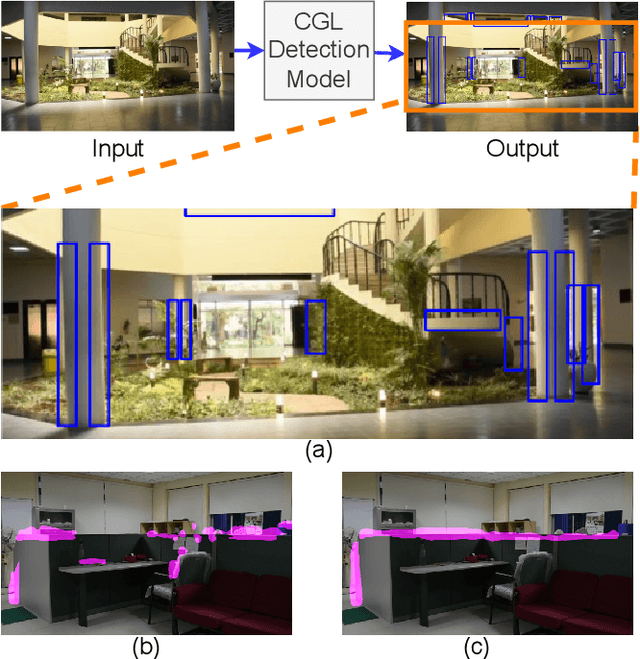
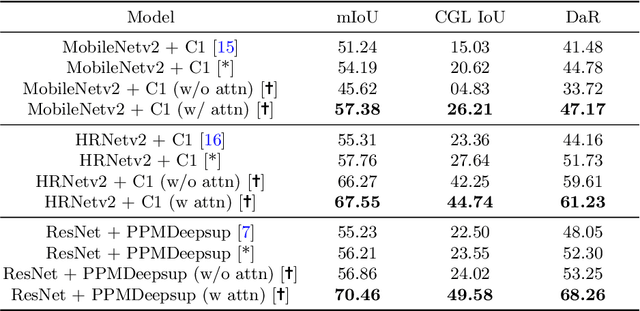
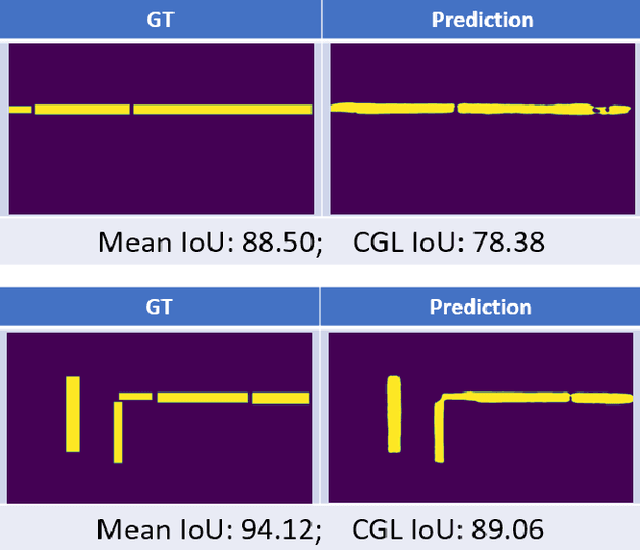
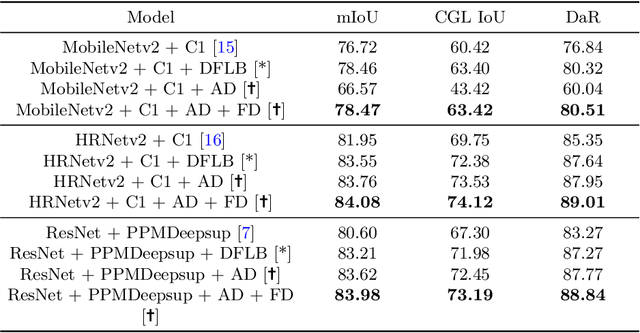
The primary goal of artificial intelligence is to mimic humans. Therefore, to advance toward this goal, the AI community attempts to imitate qualities/skills possessed by humans and imbibes them into machines with the help of datasets/tasks. Earlier, many tasks which require knowledge about the objects present in an image are satisfactorily solved by vision models. Recently, with the aim to incorporate knowledge about non-object image regions (hideouts, turns, and other obscured regions), a task for identification of potential hideouts termed Covert Geo-Location (CGL) detection was proposed by Saha et al. It involves identification of image regions which have the potential to either cause an imminent threat or appear as target zones to be accessed for further investigation to identify any occluded objects. Only certain occluding items belonging to certain semantic classes can give rise to CGLs. This fact was overlooked by Saha et al. and no attempts were made to utilize semantic class information, which is crucial for CGL detection. In this paper, we propose a multitask-learning-based approach to achieve 2 goals - i) extraction of features having semantic class information; ii) robust training of the common encoder, exploiting large standard annotated datasets as training set for the auxiliary task (semantic segmentation). To explicitly incorporate class information in the features extracted by the encoder, we have further employed attention mechanism in a novel manner. We have also proposed a better evaluation metric for CGL detection that gives more weightage to recognition rather than precise localization. Experimental evaluations performed on the CGL dataset, demonstrate a significant increase in performance of about 3% to 14% mIoU and 3% to 16% DaR on split 1, and 1% mIoU and 1% to 2% DaR on split 2 over SOTA, serving as a testimony to the superiority of our approach.
Recognition of Cardiac MRI Orientation via Deep Neural Networks and a Method to Improve Prediction Accuracy
Nov 15, 2022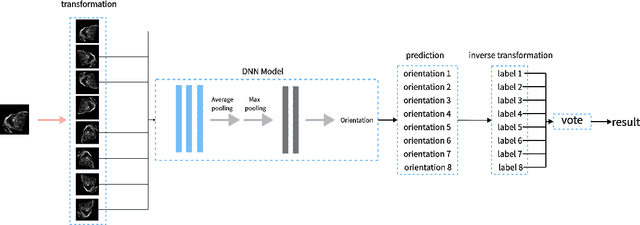

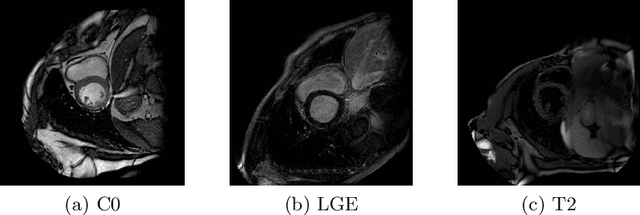

In most medical image processing tasks, the orientation of an image would affect computing result. However, manually reorienting images wastes time and effort. In this paper, we study the problem of recognizing orientation in cardiac MRI and using deep neural network to solve this problem. For multiple sequences and modalities of MRI, we propose a transfer learning strategy, which adapts our proposed model from a single modality to multiple modalities. We also propose a prediction method that uses voting. The results shows that deep neural network is an effective way in recognition of cardiac MRI orientation and the voting prediction method could improve accuracy.
Beyond Cross-view Image Retrieval: Highly Accurate Vehicle Localization Using Satellite Image
Apr 10, 2022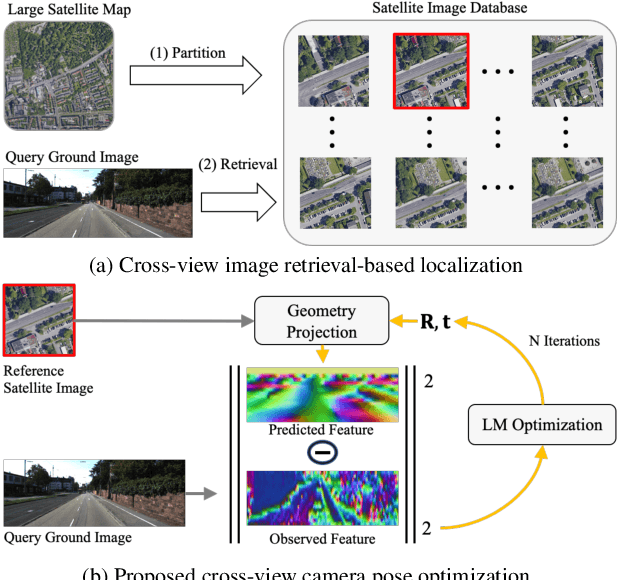
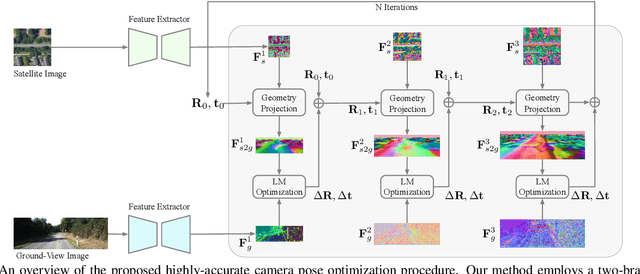


This paper addresses the problem of vehicle-mounted camera localization by matching a ground-level image with an overhead-view satellite map. Existing methods often treat this problem as cross-view image retrieval, and use learned deep features to match the ground-level query image to a partition (eg, a small patch) of the satellite map. By these methods, the localization accuracy is limited by the partitioning density of the satellite map (often in the order of tens meters). Departing from the conventional wisdom of image retrieval, this paper presents a novel solution that can achieve highly-accurate localization. The key idea is to formulate the task as pose estimation and solve it by neural-net based optimization. Specifically, we design a two-branch {CNN} to extract robust features from the ground and satellite images, respectively. To bridge the vast cross-view domain gap, we resort to a Geometry Projection module that projects features from the satellite map to the ground-view, based on a relative camera pose. Aiming to minimize the differences between the projected features and the observed features, we employ a differentiable Levenberg-Marquardt ({LM}) module to search for the optimal camera pose iteratively. The entire pipeline is differentiable and runs end-to-end. Extensive experiments on standard autonomous vehicle localization datasets have confirmed the superiority of the proposed method. Notably, e.g., starting from a coarse estimate of camera location within a wide region of 40m x 40m, with an 80% likelihood our method quickly reduces the lateral location error to be within 5m on a new KITTI cross-view dataset.
Machine Learning Challenges of Biological Factors in Insect Image Data
Nov 04, 2022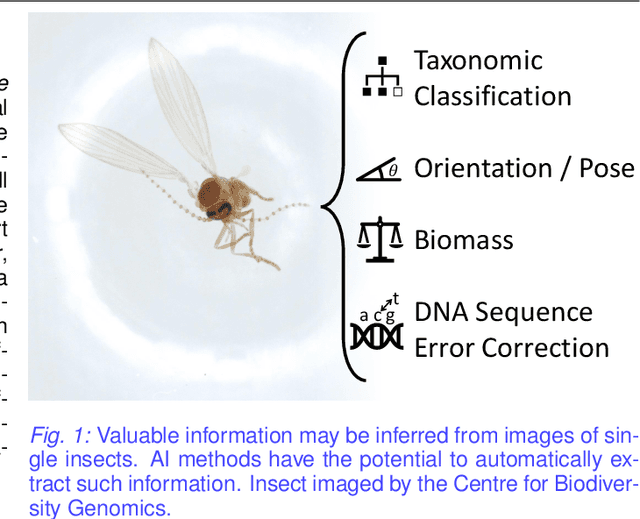

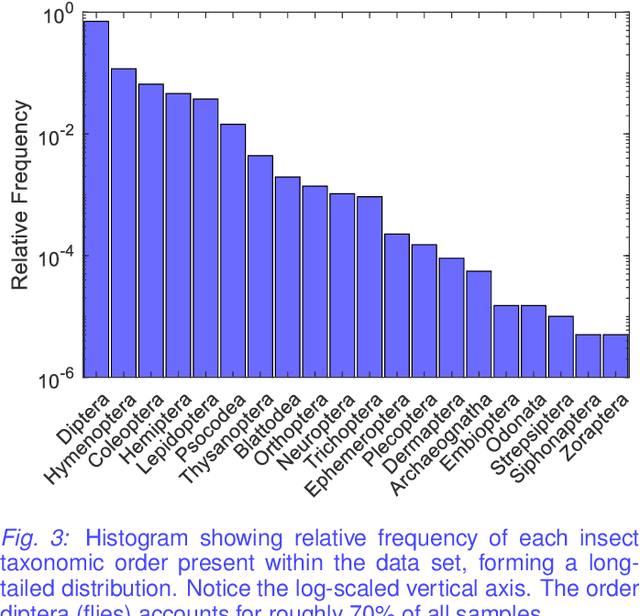
The BIOSCAN project, led by the International Barcode of Life Consortium, seeks to study changes in biodiversity on a global scale. One component of the project is focused on studying the species interaction and dynamics of all insects. In addition to genetically barcoding insects, over 1.5 million images per year will be collected, each needing taxonomic classification. With the immense volume of incoming images, relying solely on expert taxonomists to label the images would be impossible; however, artificial intelligence and computer vision technology may offer a viable high-throughput solution. Additional tasks including manually weighing individual insects to determine biomass, remain tedious and costly. Here again, computer vision may offer an efficient and compelling alternative. While the use of computer vision methods is appealing for addressing these problems, significant challenges resulting from biological factors present themselves. These challenges are formulated in the context of machine learning in this paper.
SIGNet: Intrinsic Image Decomposition by a Semantic and Invariant Gradient Driven Network for Indoor Scenes
Aug 30, 2022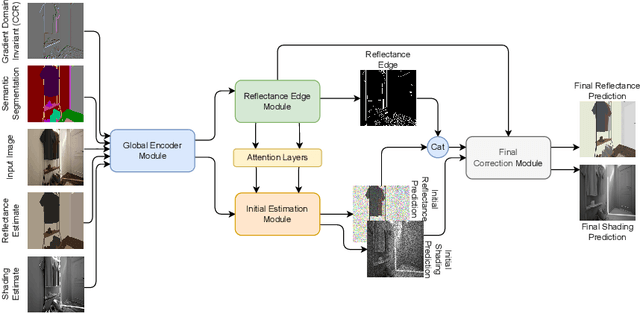
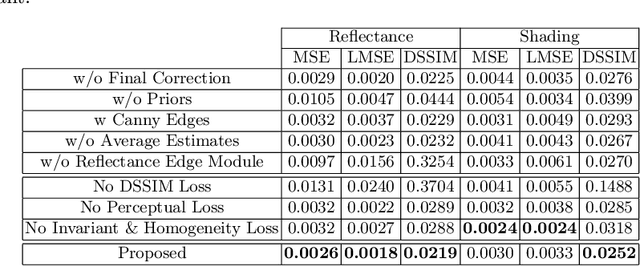
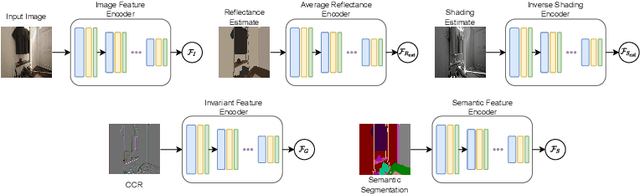
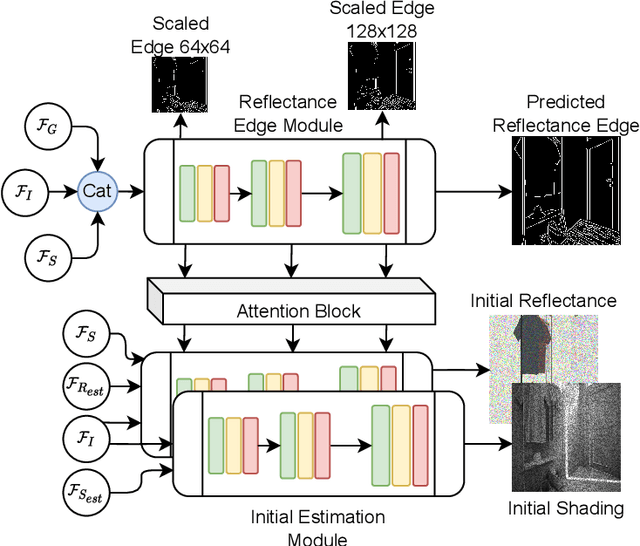
Intrinsic image decomposition (IID) is an under-constrained problem. Therefore, traditional approaches use hand crafted priors to constrain the problem. However, these constraints are limited when coping with complex scenes. Deep learning-based approaches learn these constraints implicitly through the data, but they often suffer from dataset biases (due to not being able to include all possible imaging conditions). In this paper, a combination of the two is proposed. Component specific priors like semantics and invariant features are exploited to obtain semantically and physically plausible reflectance transitions. These transitions are used to steer a progressive CNN with implicit homogeneity constraints to decompose reflectance and shading maps. An ablation study is conducted showing that the use of the proposed priors and progressive CNN increase the IID performance. State of the art performance on both our proposed dataset and the standard real-world IIW dataset shows the effectiveness of the proposed method. Code is made available at https://github.com/Morpheus3000/SIGNet
Towards Realistic Underwater Dataset Generation and Color Restoration
Nov 27, 2022

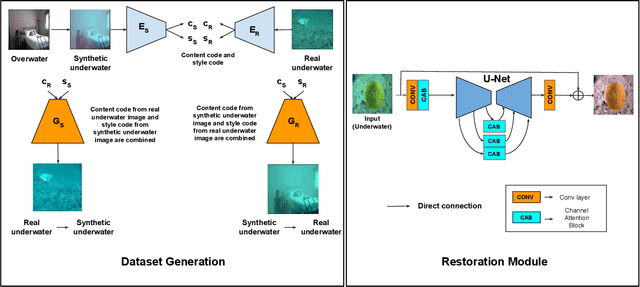
Recovery of true color from underwater images is an ill-posed problem. This is because the wide-band attenuation coefficients for the RGB color channels depend on object range, reflectance, etc. which are difficult to model. Also, there is backscattering due to suspended particles in water. Thus, most existing deep-learning based color restoration methods, which are trained on synthetic underwater datasets, do not perform well on real underwater data. This can be attributed to the fact that synthetic data cannot accurately represent real conditions. To address this issue, we use an image to image translation network to bridge the gap between the synthetic and real domains by translating images from synthetic underwater domain to real underwater domain. Using this multimodal domain adaptation technique, we create a dataset that can capture a diverse array of underwater conditions. We then train a simple but effective CNN based network on our domain adapted dataset to perform color restoration. Code and pre-trained models can be accessed at https://github.com/nehamjain10/TRUDGCR
I Can't Believe There's No Images! Learning Visual Tasks Using only Language Data
Nov 17, 2022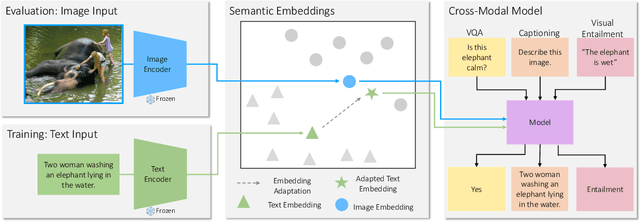
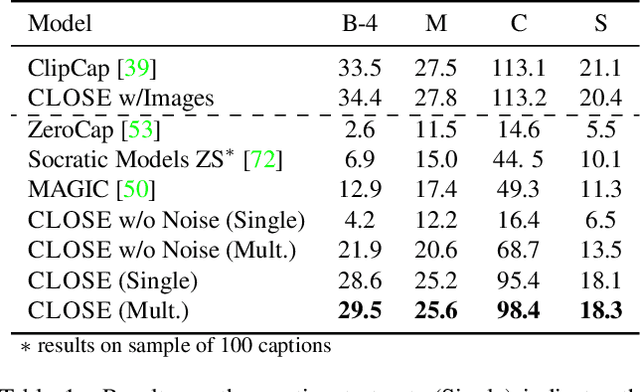

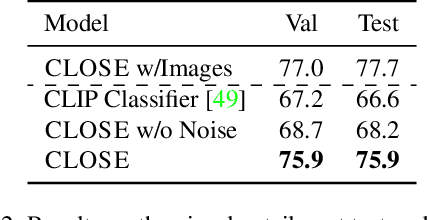
Many high-level skills that are required for computer vision tasks, such as parsing questions, comparing and contrasting semantics, and writing descriptions, are also required in other domains such as natural language processing. In this paper, we ask whether this makes it possible to learn those skills from text data and then use them to complete vision tasks without ever training on visual training data. Key to our approach is exploiting the joint embedding space of contrastively trained vision and language encoders. In practice, there can be systematic differences between embedding spaces for different modalities in contrastive models, and we analyze how these differences affect our approach and study a variety of strategies to mitigate this concern. We produce models using only text training data on three tasks: image captioning, visual entailment and visual question answering, and evaluate them on standard benchmarks using images. We find that this kind of transfer is possible and results in only a small drop in performance relative to models trained on images. We also showcase a variety of stylistic image captioning models that were trained using no image data and no human-curated language data, but instead text data from books, the web, or language models.
Adaptive De-noising of Photoacoustic Signal and Image based on Modified Kalman Filter
Nov 18, 2022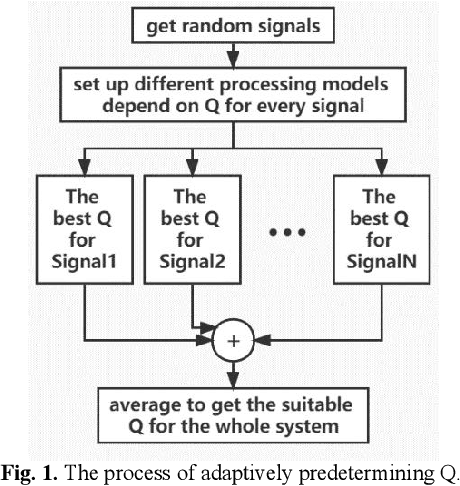
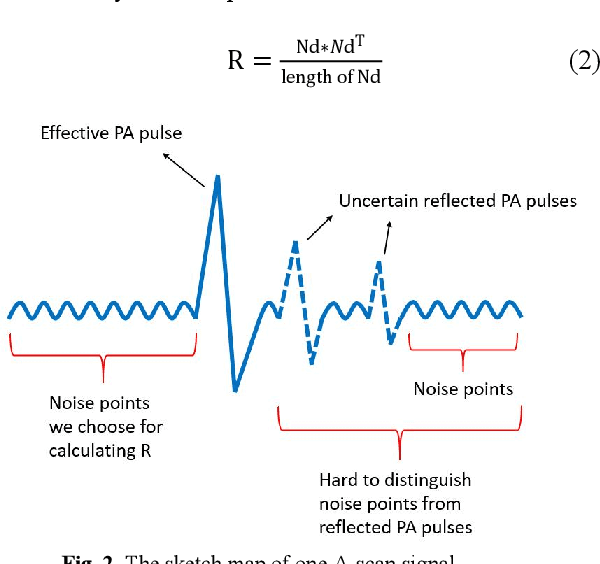
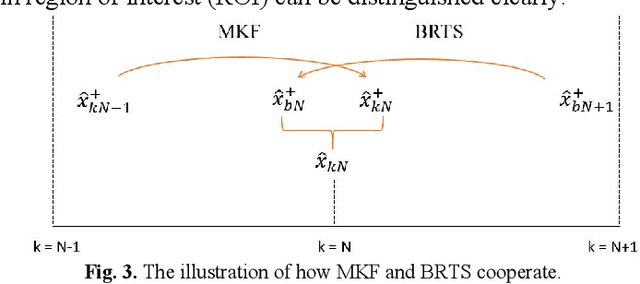
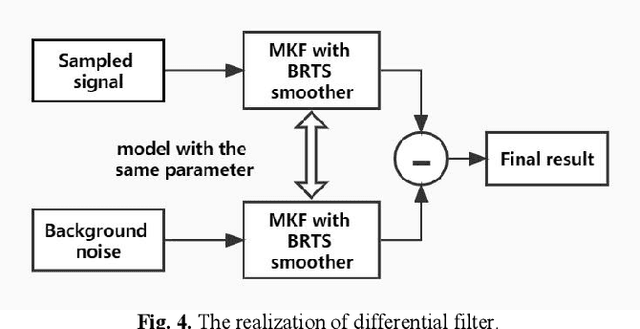
As a burgeoning medical imaging method based on hybrid fusion of light and ultrasound, photoacoustic imaging (PAI) has demonstrated high potential in various biomedical applications recently, especially in revealing the functional and molecular information to improve diagnostic accuracy. However, stemming from weak amplitude and unavoidable random noise, caused by limited laser power and severe attenuation in deep tissue imaging, PA signals are usually of low signal-to-noise ratio (SNR), and reconstructed PA images are of low quality. Despite that conventional Kalman Filter (KF) can remove Gaussian noise in time domain, it lacks adaptability in real-time estimating condition due to its fixed model. Moreover, KF-based de-noising algorithm has not been applied in PAI before. In this paper, we propose an adaptive Modified Kalman Filter (MKF) targeted at PAI de-noising by tuning system noise matrix Q and measurement noise matrix R in the conventional KF model. Additionally, in order to compensate the signal skewing caused by KF, we cascade the backward part of Rauch-Tung-Striebel smoother (BRTS), which also utilizes the newly determined Q. Finally, as a supplement, we add a commonly used differential filter to remove in-band reflection artifacts. Experimental results using phantom and ex vivo colorectal tissue are provided to prove the validity of the algorithm.