 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Kindle the Starlight
Nov 16, 2022
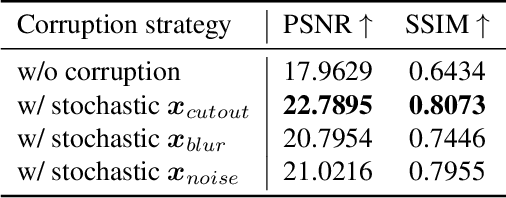

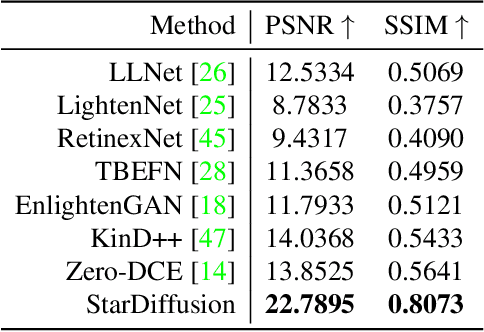

Capturing highly appreciated star field images is extremely challenging due to light pollution, the requirements of specialized hardware, and the high level of photographic skills needed. Deep learning-based techniques have achieved remarkable results in low-light image enhancement (LLIE) but have not been widely applied to star field image enhancement due to the lack of training data. To address this problem, we construct the first Star Field Image Enhancement Benchmark (SFIEB) that contains 355 real-shot and 854 semi-synthetic star field images, all having the corresponding reference images. Using the presented dataset, we propose the first star field image enhancement approach, namely StarDiffusion, based on conditional denoising diffusion probabilistic models (DDPM). We introduce dynamic stochastic corruptions to the inputs of conditional DDPM to improve the performance and generalization of the network on our small-scale dataset. Experiments show promising results of our method, which outperforms state-of-the-art low-light image enhancement algorithms. The dataset and codes will be open-sourced.
Feature Refinement to Improve High Resolution Image Inpainting
Jun 29, 2022
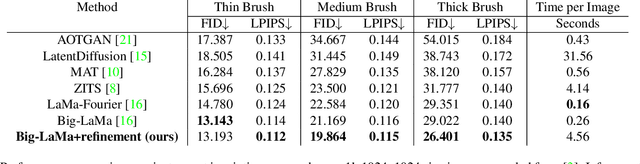
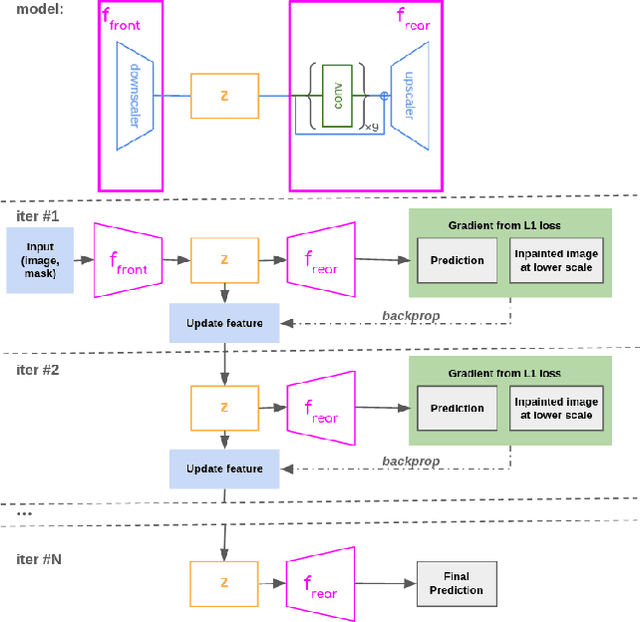

In this paper, we address the problem of degradation in inpainting quality of neural networks operating at high resolutions. Inpainting networks are often unable to generate globally coherent structures at resolutions higher than their training set. This is partially attributed to the receptive field remaining static, despite an increase in image resolution. Although downscaling the image prior to inpainting produces coherent structure, it inherently lacks detail present at higher resolutions. To get the best of both worlds, we optimize the intermediate featuremaps of a network by minimizing a multiscale consistency loss at inference. This runtime optimization improves the inpainting results and establishes a new state-of-the-art for high resolution inpainting. Code is available at: https://github.com/geomagical/lama-with-refiner/tree/refinement.
Ponder: Point Cloud Pre-training via Neural Rendering
Dec 31, 2022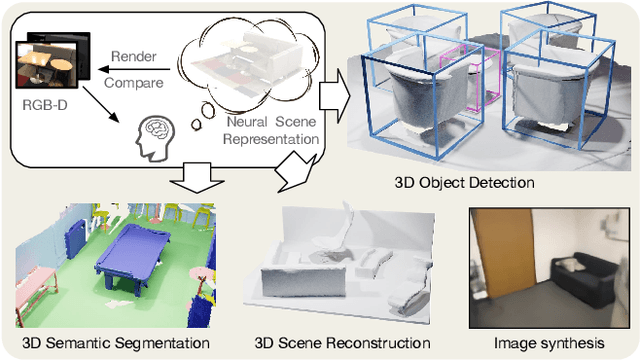
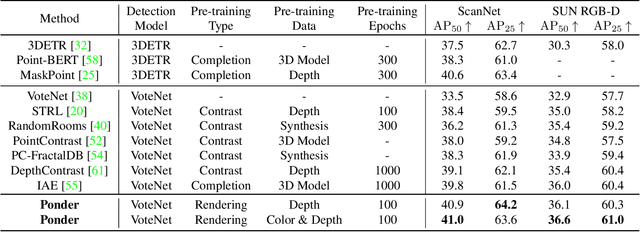
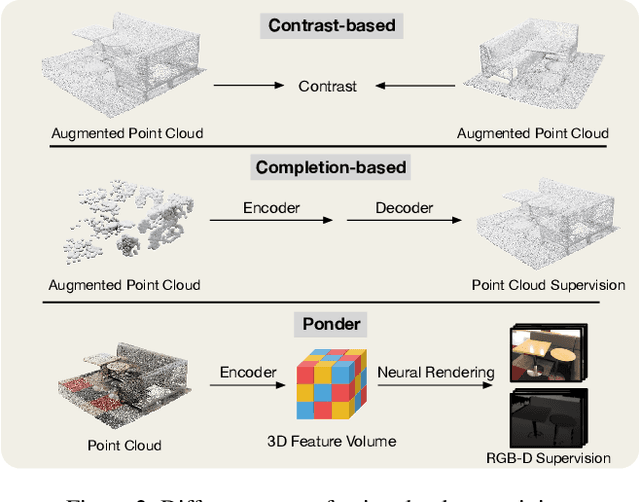
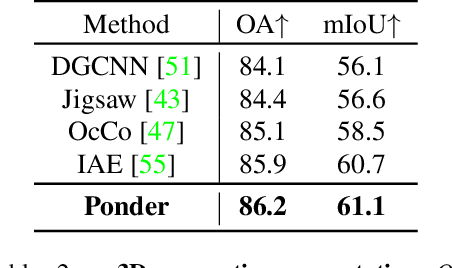
We propose a novel approach to self-supervised learning of point cloud representations by differentiable neural rendering. Motivated by the fact that informative point cloud features should be able to encode rich geometry and appearance cues and render realistic images, we train a point-cloud encoder within a devised point-based neural renderer by comparing the rendered images with real images on massive RGB-D data. The learned point-cloud encoder can be easily integrated into various downstream tasks, including not only high-level tasks like 3D detection and segmentation, but low-level tasks like 3D reconstruction and image synthesis. Extensive experiments on various tasks demonstrate the superiority of our approach compared to existing pre-training methods.
Potential Auto-driving Threat: Universal Rain-removal Attack
Nov 18, 2022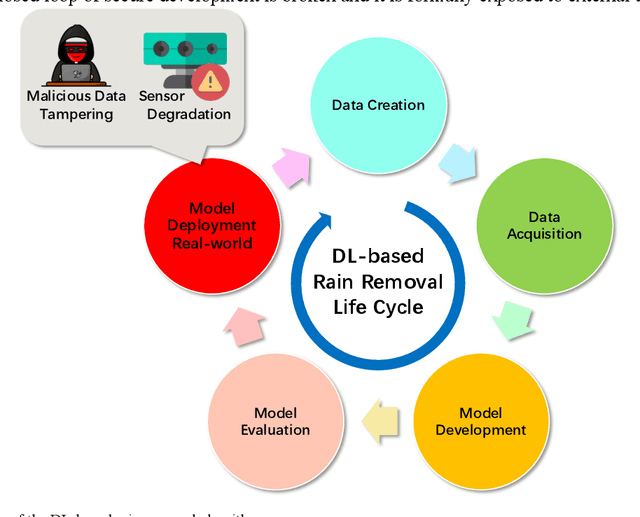
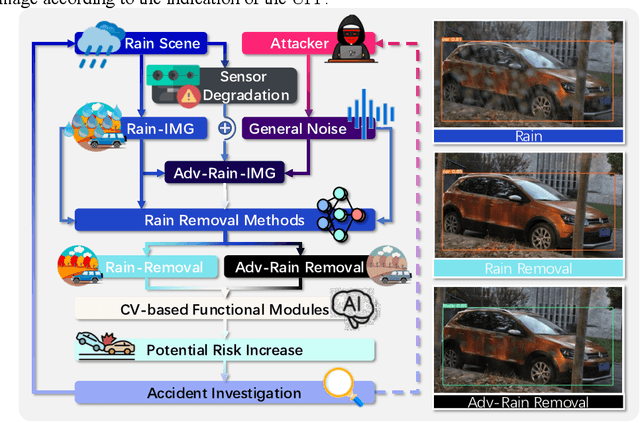
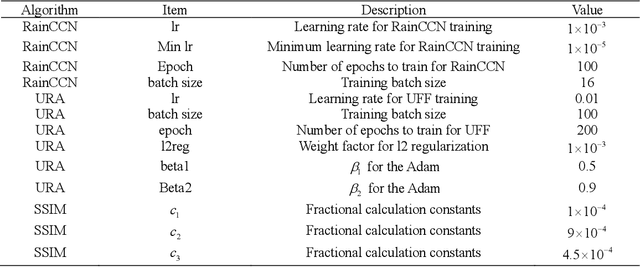
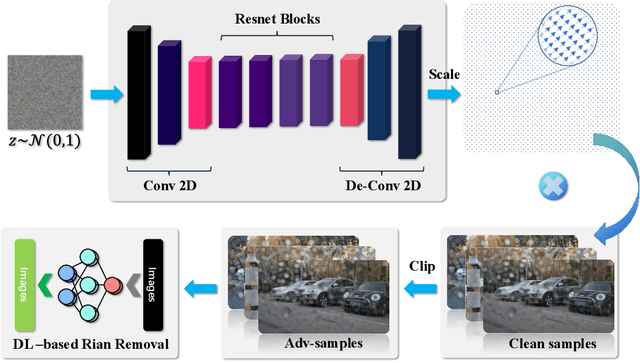
The problem of robustness in adverse weather conditions is considered a significant challenge for computer vision algorithms in the applicants of autonomous driving. Image rain removal algorithms are a general solution to this problem. They find a deep connection between raindrops/rain-streaks and images by mining the hidden features and restoring information about the rain-free environment based on the powerful representation capabilities of neural networks. However, previous research has focused on architecture innovations and has yet to consider the vulnerability issues that already exist in neural networks. This research gap hints at a potential security threat geared toward the intelligent perception of autonomous driving in the rain. In this paper, we propose a universal rain-removal attack (URA) on the vulnerability of image rain-removal algorithms by generating a non-additive spatial perturbation that significantly reduces the similarity and image quality of scene restoration. Notably, this perturbation is difficult to recognise by humans and is also the same for different target images. Thus, URA could be considered a critical tool for the vulnerability detection of image rain-removal algorithms. It also could be developed as a real-world artificial intelligence attack method. Experimental results show that URA can reduce the scene repair capability by 39.5% and the image generation quality by 26.4%, targeting the state-of-the-art (SOTA) single-image rain-removal algorithms currently available.
Compressed Gastric Image Generation Based on Soft-Label Dataset Distillation for Medical Data Sharing
Sep 29, 2022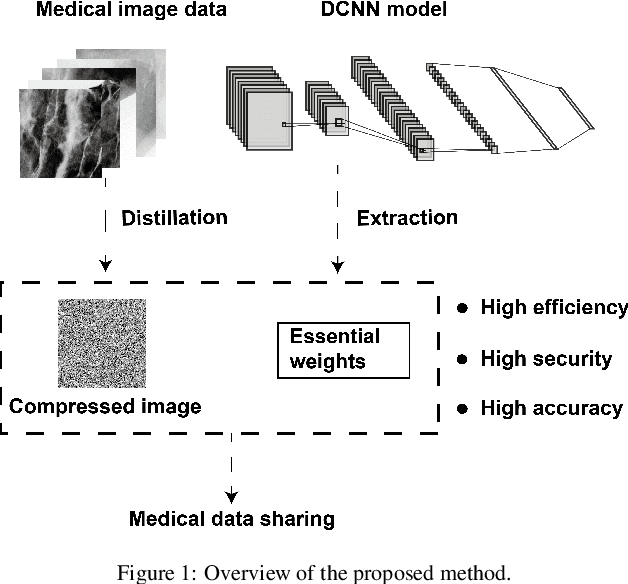
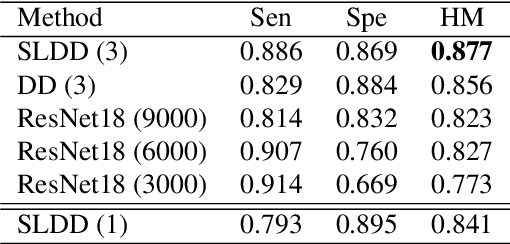
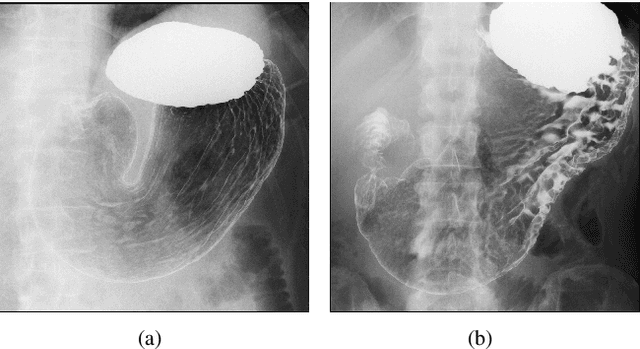
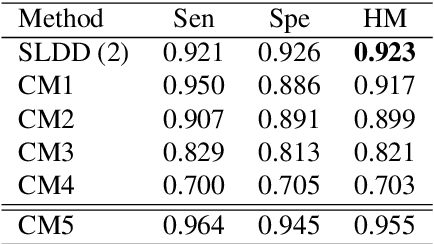
Background and objective: Sharing of medical data is required to enable the cross-agency flow of healthcare information and construct high-accuracy computer-aided diagnosis systems. However, the large sizes of medical datasets, the massive amount of memory of saved deep convolutional neural network (DCNN) models, and patients' privacy protection are problems that can lead to inefficient medical data sharing. Therefore, this study proposes a novel soft-label dataset distillation method for medical data sharing. Methods: The proposed method distills valid information of medical image data and generates several compressed images with different data distributions for anonymous medical data sharing. Furthermore, our method can extract essential weights of DCNN models to reduce the memory required to save trained models for efficient medical data sharing. Results: The proposed method can compress tens of thousands of images into several soft-label images and reduce the size of a trained model to a few hundredths of its original size. The compressed images obtained after distillation have been visually anonymized; therefore, they do not contain the private information of the patients. Furthermore, we can realize high-detection performance with a small number of compressed images. Conclusions: The experimental results show that the proposed method can improve the efficiency and security of medical data sharing.
Trustworthy clinical AI solutions: a unified review of uncertainty quantification in deep learning models for medical image analysis
Oct 05, 2022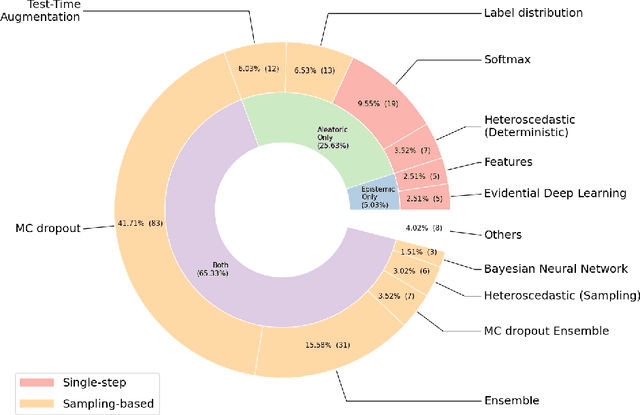
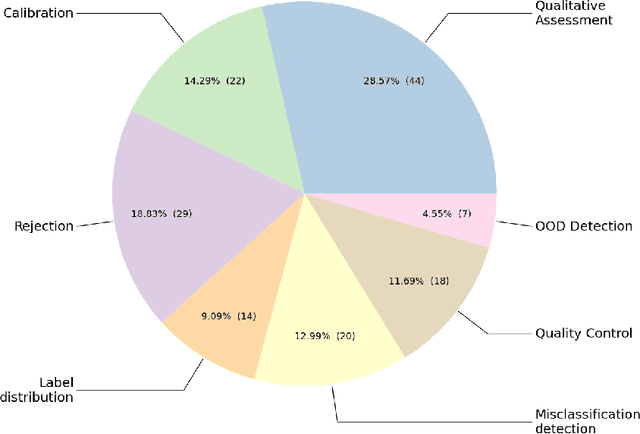

The full acceptance of Deep Learning (DL) models in the clinical field is rather low with respect to the quantity of high-performing solutions reported in the literature. Particularly, end users are reluctant to rely on the rough predictions of DL models. Uncertainty quantification methods have been proposed in the literature as a potential response to reduce the rough decision provided by the DL black box and thus increase the interpretability and the acceptability of the result by the final user. In this review, we propose an overview of the existing methods to quantify uncertainty associated to DL predictions. We focus on applications to medical image analysis, which present specific challenges due to the high dimensionality of images and their quality variability, as well as constraints associated to real-life clinical routine. We then discuss the evaluation protocols to validate the relevance of uncertainty estimates. Finally, we highlight the open challenges of uncertainty quantification in the medical field.
Quasi Non-Negative Quaternion Matrix Factorization with Application to Color Face Recognition
Nov 30, 2022
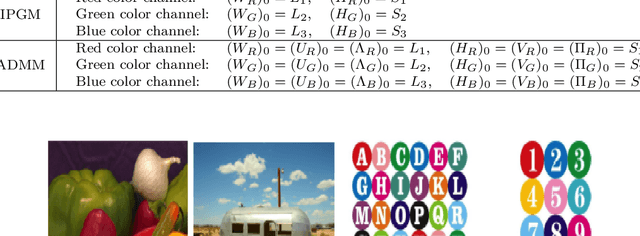


To address the non-negativity dropout problem of quaternion models, a novel quasi non-negative quaternion matrix factorization (QNQMF) model is presented for color image processing. To implement QNQMF, the quaternion projected gradient algorithm and the quaternion alternating direction method of multipliers are proposed via formulating QNQMF as the non-convex constraint quaternion optimization problems. Some properties of the proposed algorithms are studied. The numerical experiments on the color image reconstruction show that these algorithms encoded on the quaternion perform better than these algorithms encoded on the red, green and blue channels. Furthermore, we apply the proposed algorithms to the color face recognition. Numerical results indicate that the accuracy rate of face recognition on the quaternion model is better than on the red, green and blue channels of color image as well as single channel of gray level images for the same data, when large facial expressions and shooting angle variations are presented.
Semi-Supervised Semantic Segmentation Methods for UW-OCTA Diabetic Retinopathy Grade Assessment
Dec 27, 2022
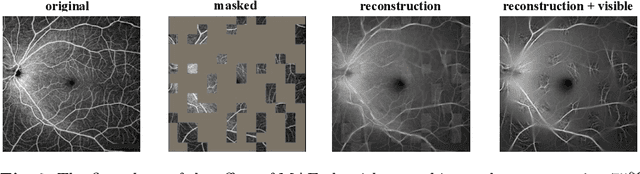

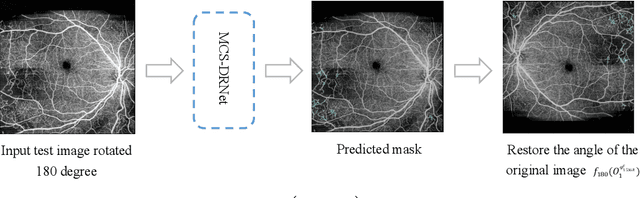
People with diabetes are more likely to develop diabetic retinopathy (DR) than healthy people. However, DR is the leading cause of blindness. At present, the diagnosis of diabetic retinopathy mainly relies on the experienced clinician to recognize the fine features in color fundus images. This is a time-consuming task. Therefore, in this paper, to promote the development of UW-OCTA DR automatic detection, we propose a novel semi-supervised semantic segmentation method for UW-OCTA DR image grade assessment. This method, first, uses the MAE algorithm to perform semi-supervised pre-training on the UW-OCTA DR grade assessment dataset to mine the supervised information in the UW-OCTA images, thereby alleviating the need for labeled data. Secondly, to more fully mine the lesion features of each region in the UW-OCTA image, this paper constructs a cross-algorithm ensemble DR tissue segmentation algorithm by deploying three algorithms with different visual feature processing strategies. The algorithm contains three sub-algorithms, namely pre-trained MAE, ConvNeXt, and SegFormer. Based on the initials of these three sub-algorithms, the algorithm can be named MCS-DRNet. Finally, we use the MCS-DRNet algorithm as an inspector to check and revise the results of the preliminary evaluation of the DR grade evaluation algorithm. The experimental results show that the mean dice similarity coefficient of MCS-DRNet v1 and v2 are 0.5161 and 0.5544, respectively. The quadratic weighted kappa of the DR grading evaluation is 0.7559. Our code will be released soon.
Towards Realistic Underwater Dataset Generation and Color Restoration
Dec 16, 2022

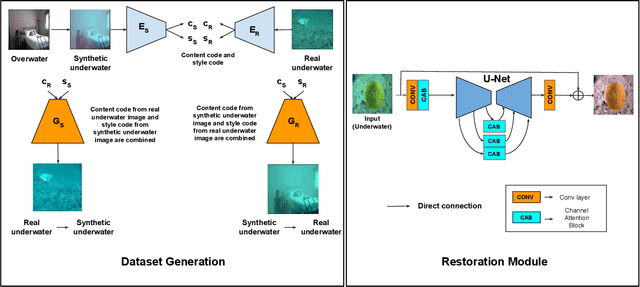
Recovery of true color from underwater images is an ill-posed problem. This is because the wide-band attenuation coefficients for the RGB color channels depend on object range, reflectance, etc. which are difficult to model. Also, there is backscattering due to suspended particles in water. Thus, most existing deep-learning based color restoration methods, which are trained on synthetic underwater datasets, do not perform well on real underwater data. This can be attributed to the fact that synthetic data cannot accurately represent real conditions. To address this issue, we use an image to image translation network to bridge the gap between the synthetic and real domains by translating images from synthetic underwater domain to real underwater domain. Using this multimodal domain adaptation technique, we create a dataset that can capture a diverse array of underwater conditions. We then train a simple but effective CNN based network on our domain adapted dataset to perform color restoration. Code and pre-trained models can be accessed at https://github.com/nehamjain10/TRUDGCR
Fake it till you make it: Learning(s) from a synthetic ImageNet clone
Dec 16, 2022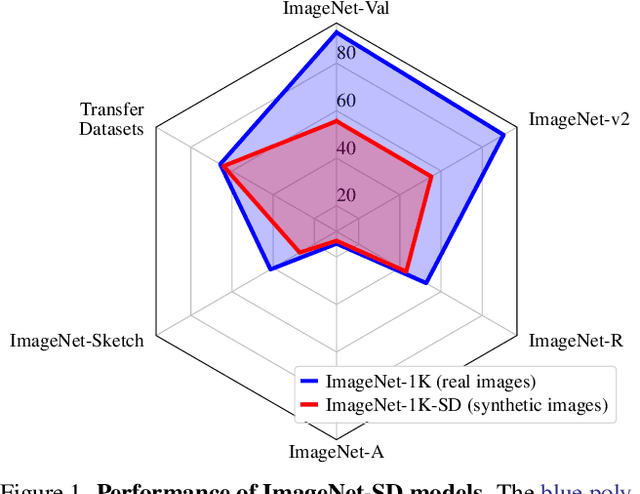

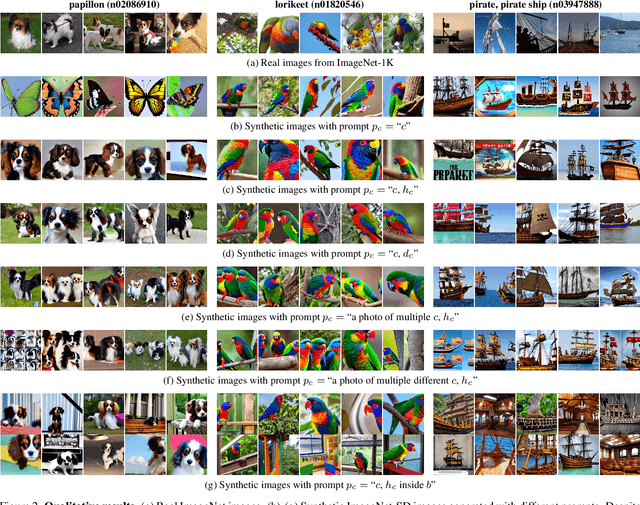
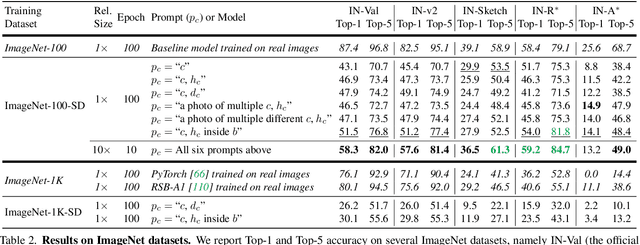
Recent large-scale image generation models such as Stable Diffusion have exhibited an impressive ability to generate fairly realistic images starting from a very simple text prompt. Could such models render real images obsolete for training image prediction models? In this paper, we answer part of this provocative question by questioning the need for real images when training models for ImageNet classification. More precisely, provided only with the class names that have been used to build the dataset, we explore the ability of Stable Diffusion to generate synthetic clones of ImageNet and measure how useful they are for training classification models from scratch. We show that with minimal and class-agnostic prompt engineering those ImageNet clones we denote as ImageNet-SD are able to close a large part of the gap between models produced by synthetic images and models trained with real images for the several standard classification benchmarks that we consider in this study. More importantly, we show that models trained on synthetic images exhibit strong generalization properties and perform on par with models trained on real data.