 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Study on the Use of Edge TPUs for Eye Fundus Image Segmentation
Jul 26, 2022
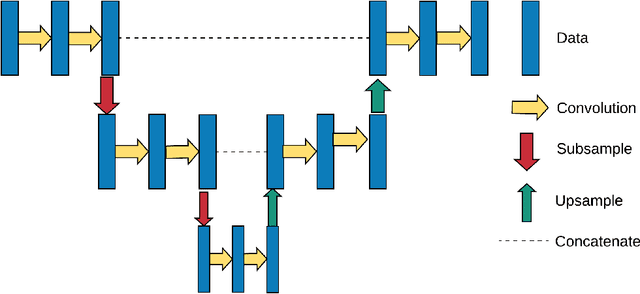

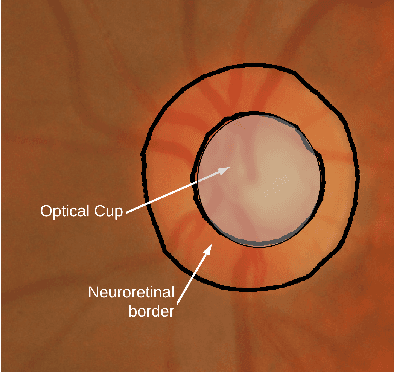
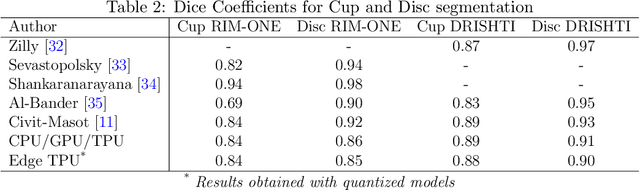
Medical image segmentation can be implemented using Deep Learning methods with fast and efficient segmentation networks. Single-board computers (SBCs) are difficult to use to train deep networks due to their memory and processing limitations. Specific hardware such as Google's Edge TPU makes them suitable for real time predictions using complex pre-trained networks. In this work, we study the performance of two SBCs, with and without hardware acceleration for fundus image segmentation, though the conclusions of this study can be applied to the segmentation by deep neural networks of other types of medical images. To test the benefits of hardware acceleration, we use networks and datasets from a previous published work and generalize them by testing with a dataset with ultrasound thyroid images. We measure prediction times in both SBCs and compare them with a cloud based TPU system. The results show the feasibility of Machine Learning accelerated SBCs for optic disc and cup segmentation obtaining times below 25 milliseconds per image using Edge TPUs.
* Preprint of paper published in Engineering Applications of Artificial Intelligence
Annealed Score-Based Diffusion Model for MR Motion Artifact Reduction
Jan 08, 2023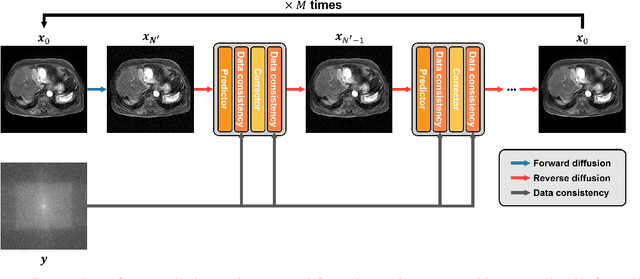
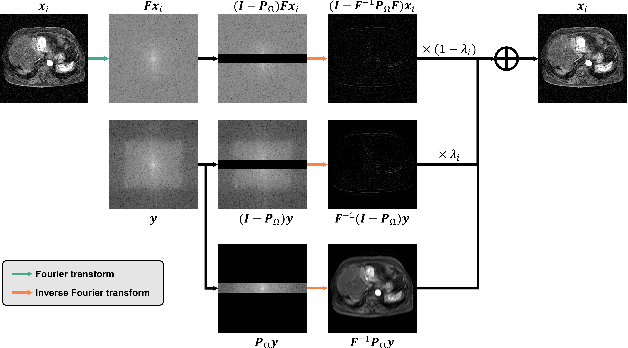
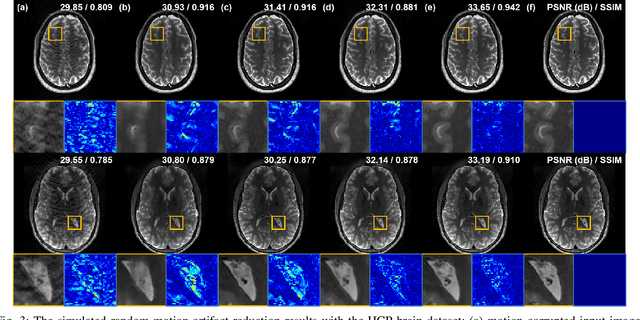
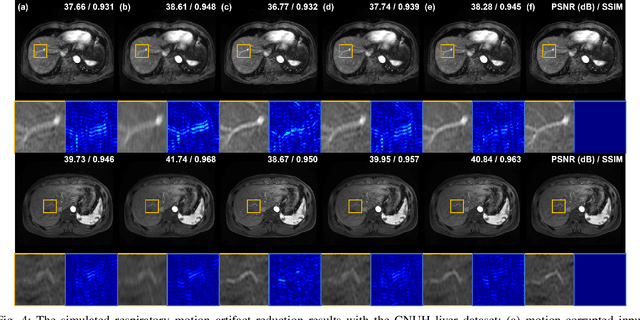
Motion artifact reduction is one of the important research topics in MR imaging, as the motion artifact degrades image quality and makes diagnosis difficult. Recently, many deep learning approaches have been studied for motion artifact reduction. Unfortunately, most existing models are trained in a supervised manner, requiring paired motion-corrupted and motion-free images, or are based on a strict motion-corruption model, which limits their use for real-world situations. To address this issue, here we present an annealed score-based diffusion model for MRI motion artifact reduction. Specifically, we train a score-based model using only motion-free images, and then motion artifacts are removed by applying forward and reverse diffusion processes repeatedly to gradually impose a low-frequency data consistency. Experimental results verify that the proposed method successfully reduces both simulated and in vivo motion artifacts, outperforming the state-of-the-art deep learning methods.
Reference-based and No-reference Metrics to Evaluate Explanation Methods of AI -- CNNs in Image Classification Tasks
Dec 23, 2022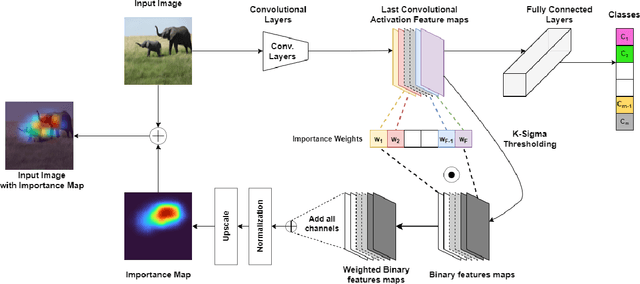
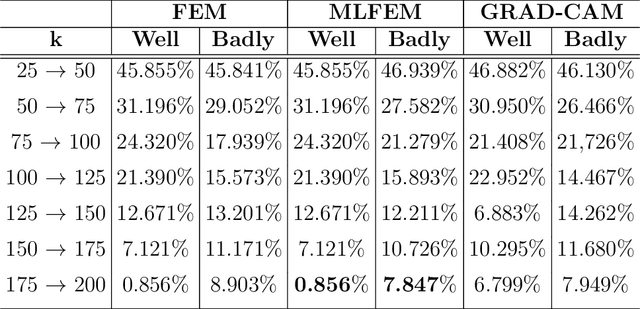

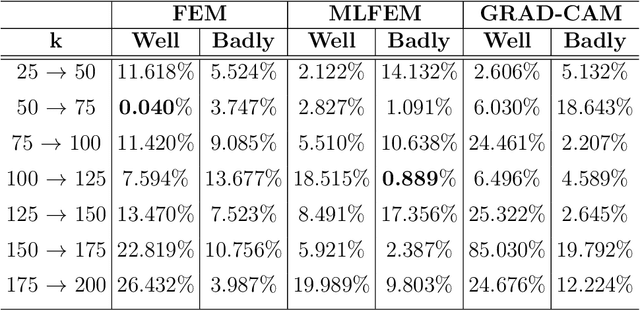
The most popular methods in AI-machine learning paradigm are mainly black boxes. This is why explanation of AI decisions is of emergency. Although dedicated explanation tools have been massively developed, the evaluation of their quality remains an open research question. In this paper, we the generalize the methodologies of evaluation of post-hoc explainers of CNNs' decisions in visual classification tasks with reference and no-reference based metrics. We apply them on our previously developed explainers (FEM, MLFEM), and popular Grad-CAM. The reference-based metrics are Pearson correlation coefficient and Similarity computed between the explanation map and its ground truth represented by a Gaze Fixation Density Map obtained with a psycho-visual experiment. As a no-reference metric we use stability metric, proposed by Alvarez-Melis and Jaakkola. We study its behaviour, consensus with reference-based metrics and show that in case of several kind of degradation on input images, this metric is in agreement with reference-based ones. Therefore it can be used for evaluation of the quality of explainers when the ground truth is not available.
Are metrics measuring what they should? An evaluation of image captioning task metrics
Jul 04, 2022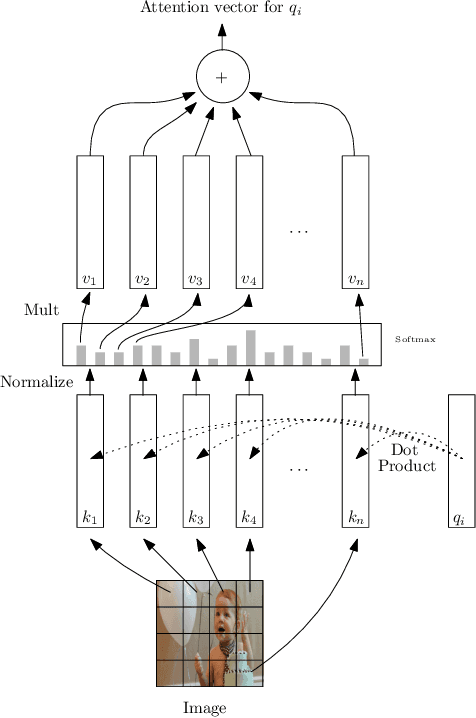
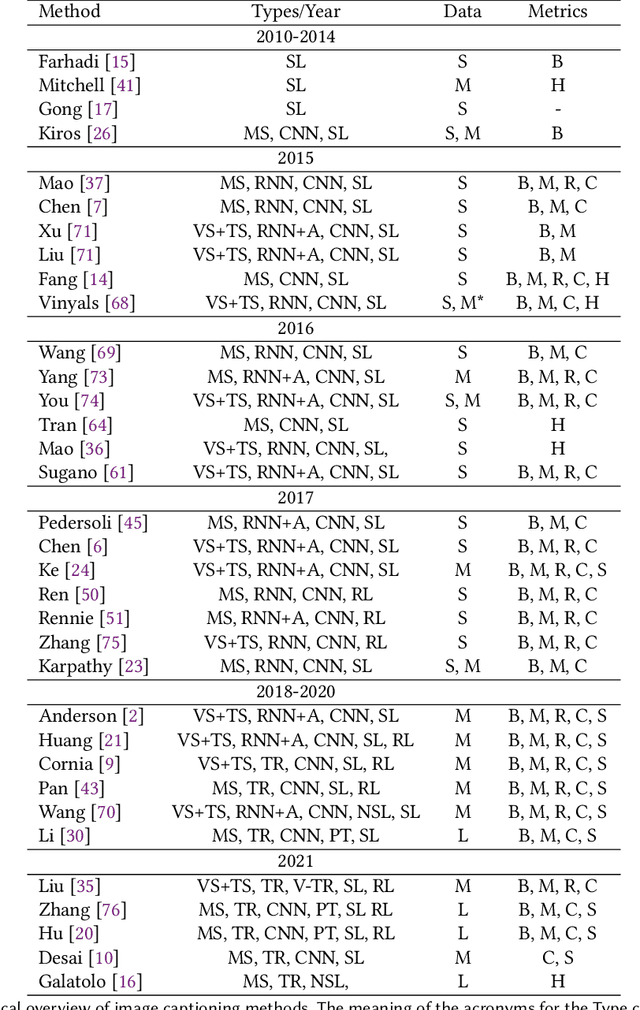
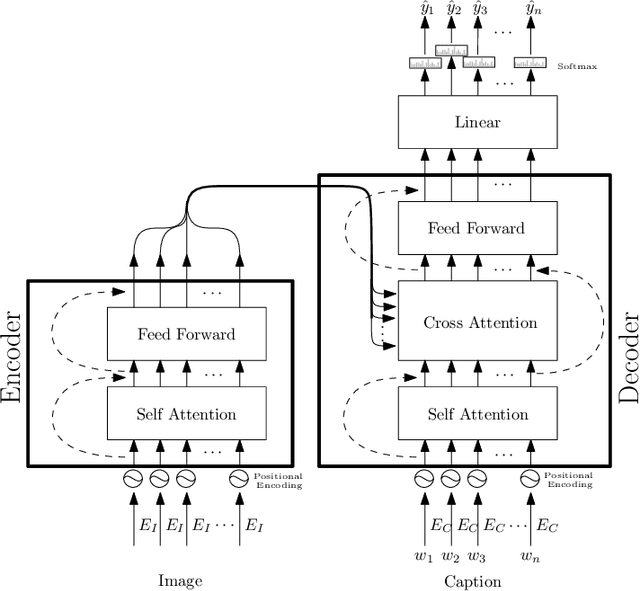
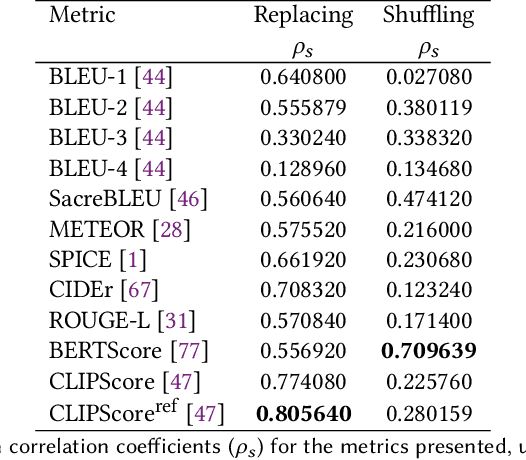
Image Captioning is a current research task to describe the image content using the objects and their relationships in the scene. To tackle this task, two important research areas are used, artificial vision, and natural language processing. In Image Captioning, as in any computational intelligence task, the performance metrics are crucial for knowing how well (or bad) a method performs. In recent years, it has been observed that classical metrics based on n-grams are insufficient to capture the semantics and the critical meaning to describe the content in an image. Looking to measure how well or not the set of current and more recent metrics are doing, in this manuscript, we present an evaluation of several kinds of Image Captioning metrics and a comparison between them using the well-known MS COCO dataset. For this, we designed two scenarios; 1) a set of artificially build captions with several quality, and 2) a comparison of some state-of-the-art Image Captioning methods. We tried to answer the questions: Are the current metrics helping to produce high quality captions? How do actual metrics compare to each other? What are the metrics really measuring?
Deep Image Retrieval is not Robust to Label Noise
May 23, 2022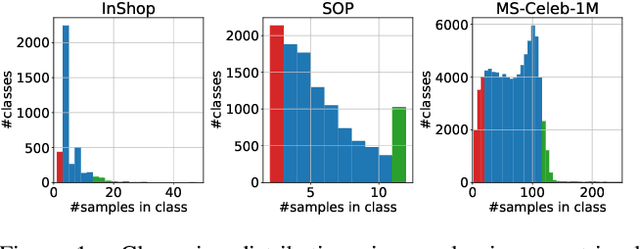
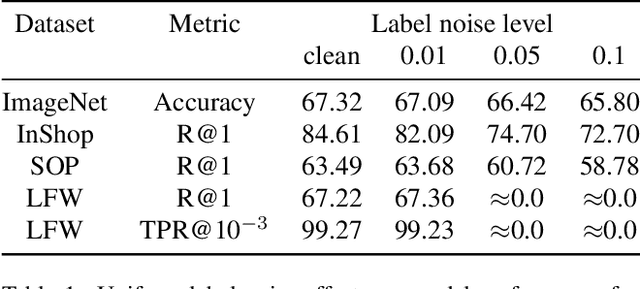
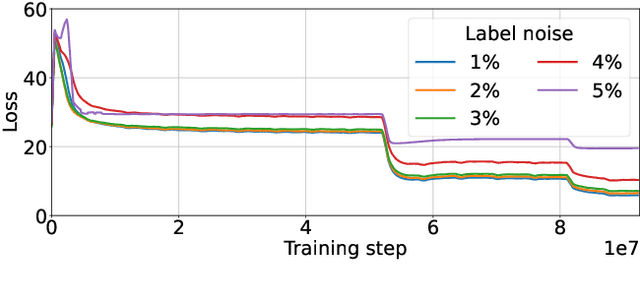
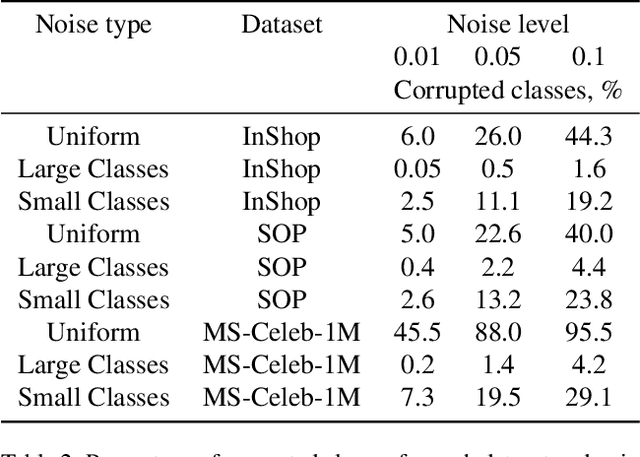
Large-scale datasets are essential for the success of deep learning in image retrieval. However, manual assessment errors and semi-supervised annotation techniques can lead to label noise even in popular datasets. As previous works primarily studied annotation quality in image classification tasks, it is still unclear how label noise affects deep learning approaches to image retrieval. In this work, we show that image retrieval methods are less robust to label noise than image classification ones. Furthermore, we, for the first time, investigate different types of label noise specific to image retrieval tasks and study their effect on model performance.
Robust Deep Ensemble Method for Real-world Image Denoising
Jun 08, 2022

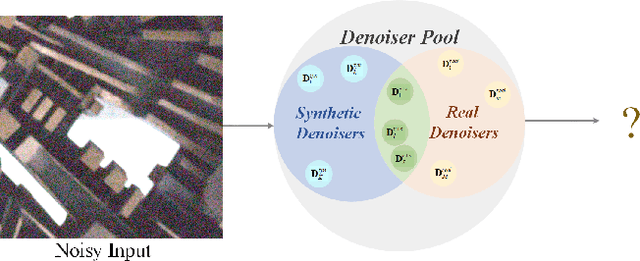
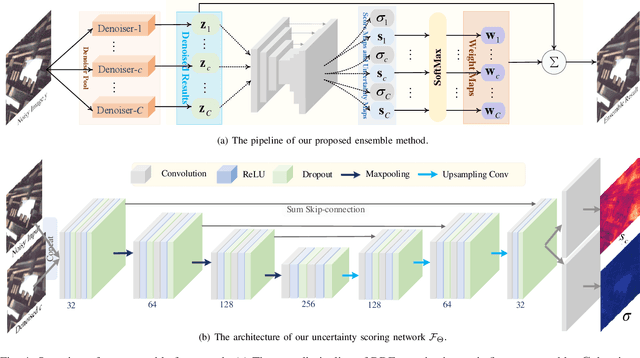
Recently, deep learning-based image denoising methods have achieved promising performance on test data with the same distribution as training set, where various denoising models based on synthetic or collected real-world training data have been learned. However, when handling real-world noisy images, the denoising performance is still limited. In this paper, we propose a simple yet effective Bayesian deep ensemble (BDE) method for real-world image denoising, where several representative deep denoisers pre-trained with various training data settings can be fused to improve robustness. The foundation of BDE is that real-world image noises are highly signal-dependent, and heterogeneous noises in a real-world noisy image can be separately handled by different denoisers. In particular, we take well-trained CBDNet, NBNet, HINet, Uformer and GMSNet into denoiser pool, and a U-Net is adopted to predict pixel-wise weighting maps to fuse these denoisers. Instead of solely learning pixel-wise weighting maps, Bayesian deep learning strategy is introduced to predict weighting uncertainty as well as weighting map, by which prediction variance can be modeled for improving robustness on real-world noisy images. Extensive experiments have shown that real-world noises can be better removed by fusing existing denoisers instead of training a big denoiser with expensive cost. On DND dataset, our BDE achieves +0.28~dB PSNR gain over the state-of-the-art denoising method. Moreover, we note that our BDE denoiser based on different Gaussian noise levels outperforms state-of-the-art CBDNet when applying to real-world noisy images. Furthermore, our BDE can be extended to other image restoration tasks, and achieves +0.30dB, +0.18dB and +0.12dB PSNR gains on benchmark datasets for image deblurring, image deraining and single image super-resolution, respectively.
Sky-image-based solar forecasting using deep learning with multi-location data: training models locally, globally or via transfer learning?
Nov 03, 2022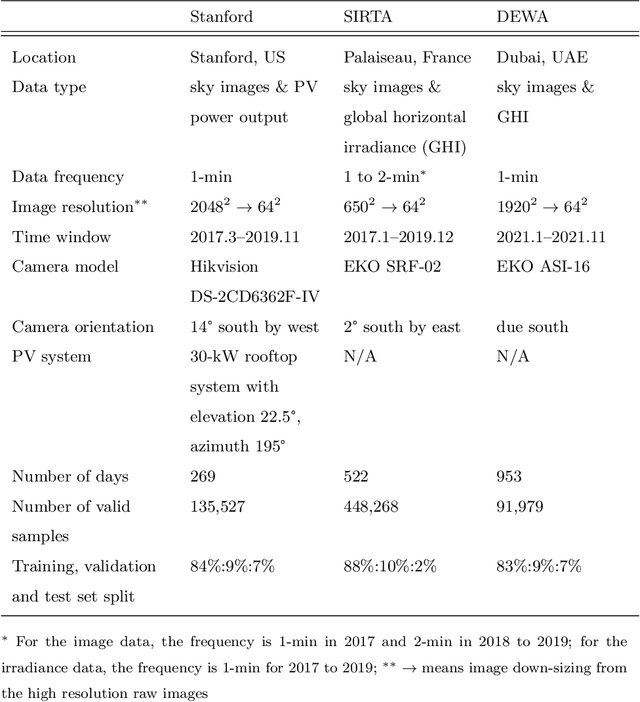

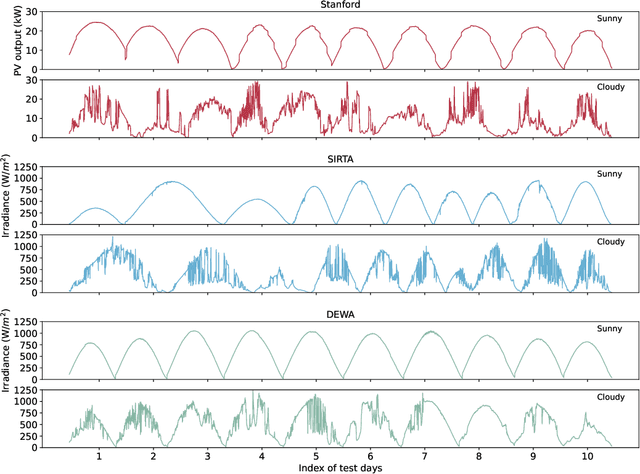
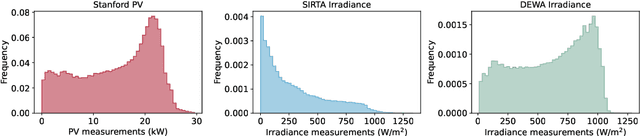
Solar forecasting from ground-based sky images using deep learning models has shown great promise in reducing the uncertainty in solar power generation. One of the biggest challenges for training deep learning models is the availability of labeled datasets. With more and more sky image datasets open sourced in recent years, the development of accurate and reliable solar forecasting methods has seen a huge growth in potential. In this study, we explore three different training strategies for deep-learning-based solar forecasting models by leveraging three heterogeneous datasets collected around the world with drastically different climate patterns. Specifically, we compare the performance of models trained individually based on local datasets (local models) and models trained jointly based on the fusion of multiple datasets from different locations (global models), and we further examine the knowledge transfer from pre-trained solar forecasting models to a new dataset of interest (transfer learning models). The results suggest that the local models work well when deployed locally, but significant errors are observed for the scale of the prediction when applied offsite. The global model can adapt well to individual locations, while the possible increase in training efforts need to be taken into account. Pre-training models on a large and diversified source dataset and transferring to a local target dataset generally achieves superior performance over the other two training strategies. Transfer learning brings the most benefits when there are limited local data. With 80% less training data, it can achieve 1% improvement over the local baseline model trained using the entire dataset. Therefore, we call on the efforts from the solar forecasting community to contribute to a global dataset containing a massive amount of imagery and displaying diversified samples with a range of sky conditions.
GR-GAN: Gradual Refinement Text-to-image Generation
May 23, 2022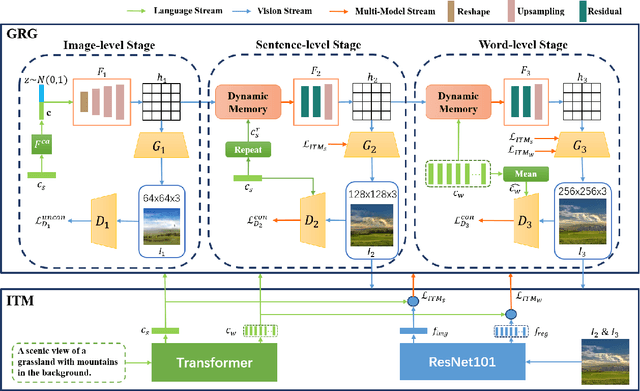
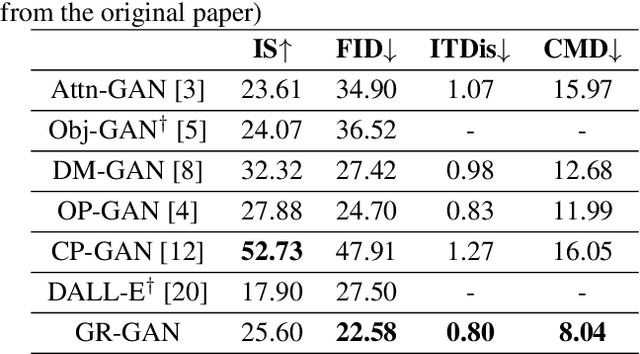

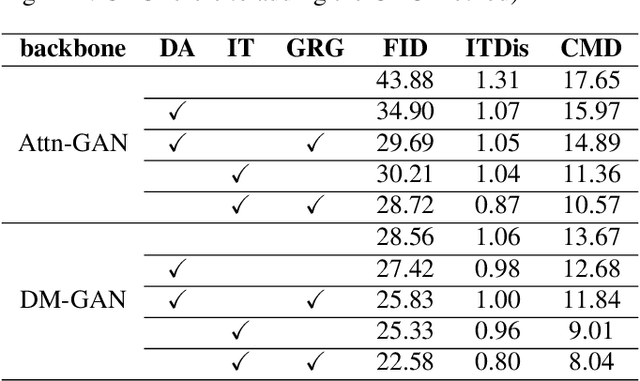
A good Text-to-Image model should not only generate high quality images, but also ensure the consistency between the text and the generated image. Previous models failed to simultaneously fix both sides well. This paper proposes a Gradual Refinement Generative Adversarial Network (GR-GAN) to alleviates the problem efficiently. A GRG module is designed to generate images from low resolution to high resolution with the corresponding text constraints from coarse granularity (sentence) to fine granularity (word) stage by stage, a ITM module is designed to provide image-text matching losses at both sentence-image level and word-region level for corresponding stages. We also introduce a new metric Cross-Model Distance (CMD) for simultaneously evaluating image quality and image-text consistency. Experimental results show GR-GAN significant outperform previous models, and achieve new state-of-the-art on both FID and CMD. A detailed analysis demonstrates the efficiency of different generation stages in GR-GAN.
GRIT: Faster and Better Image captioning Transformer Using Dual Visual Features
Jul 20, 2022

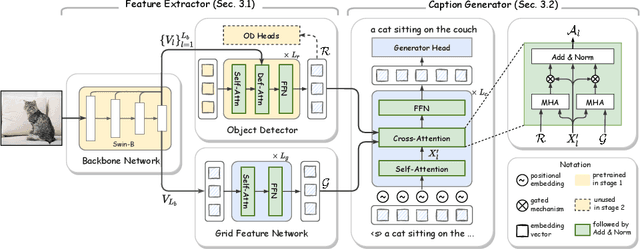

Current state-of-the-art methods for image captioning employ region-based features, as they provide object-level information that is essential to describe the content of images; they are usually extracted by an object detector such as Faster R-CNN. However, they have several issues, such as lack of contextual information, the risk of inaccurate detection, and the high computational cost. The first two could be resolved by additionally using grid-based features. However, how to extract and fuse these two types of features is uncharted. This paper proposes a Transformer-only neural architecture, dubbed GRIT (Grid- and Region-based Image captioning Transformer), that effectively utilizes the two visual features to generate better captions. GRIT replaces the CNN-based detector employed in previous methods with a DETR-based one, making it computationally faster. Moreover, its monolithic design consisting only of Transformers enables end-to-end training of the model. This innovative design and the integration of the dual visual features bring about significant performance improvement. The experimental results on several image captioning benchmarks show that GRIT outperforms previous methods in inference accuracy and speed.
Environment Semantics Aided Wireless Communications: A Case Study of mmWave Beam Prediction and Blockage Prediction
Jan 14, 2023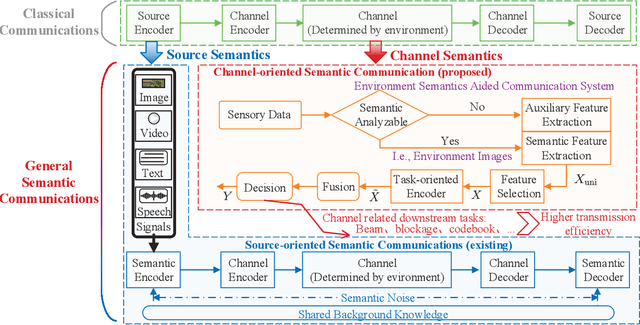
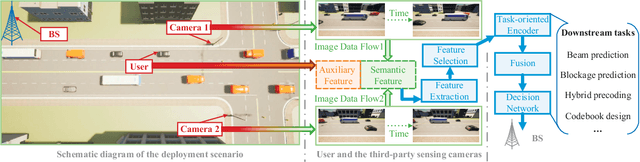
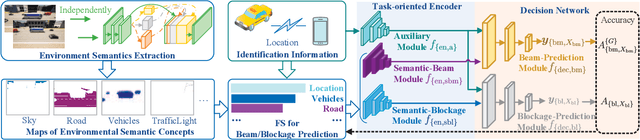

In this paper, we propose an environment semantics aided wireless communication framework to reduce the transmission latency and improve the transmission reliability, where semantic information is extracted from environment image data, selectively encoded based on its task-relevance, and then fused to make decisions for channel related tasks. As a case study, we develop an environment semantics aided network architecture for mmWave communication systems, which is composed of a semantic feature extraction network, a feature selection algorithm, a task-oriented encoder, and a decision network. With images taken from street cameras and user's identification information as the inputs, the environment semantics aided network architecture is trained to predict the optimal beam index and the blockage state for the base station. It is seen that without pilot training or the costly beam scans, the environment semantics aided network architecture can realize extremely efficient beam prediction and timely blockage prediction, thus meeting requirements for ultra-reliable and low-latency communications (URLLCs). Simulation results demonstrate that compared with existing works, the proposed environment semantics aided network architecture can reduce system overheads such as storage space and computational cost while achieving satisfactory prediction accuracy and protecting user privacy.