 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Annotations for Multi-modal Greeting Cards Dataset
Dec 01, 2022
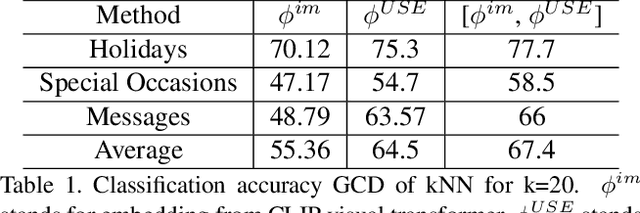
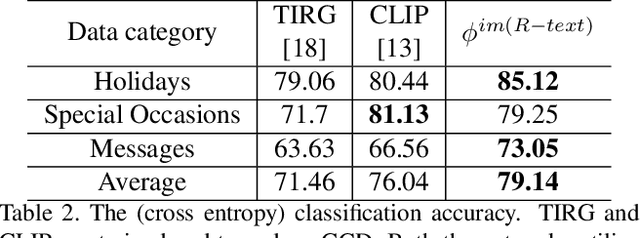
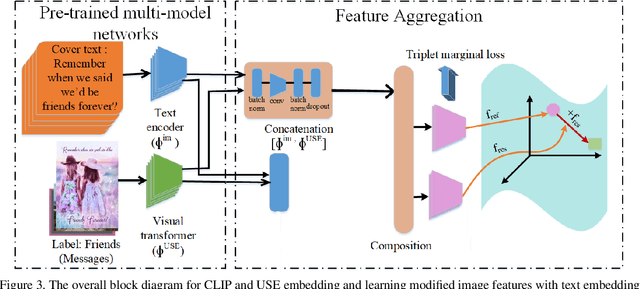

In recent years, there is a growing number of pre-trained models trained on a large corpus of data and yielding good performance on various tasks such as classifying multimodal datasets. These models have shown good performance on natural images but are not fully explored for scarce abstract concepts in images. In this work, we introduce an image/text-based dataset called Greeting Cards. Dataset (GCD) that has abstract visual concepts. In our work, we propose to aggregate features from pretrained images and text embeddings to learn abstract visual concepts from GCD. This allows us to learn the text-modified image features, which combine complementary and redundant information from the multi-modal data streams into a single, meaningful feature. Secondly, the captions for the GCD dataset are computed with the pretrained CLIP-based image captioning model. Finally, we also demonstrate that the proposed the dataset is also useful for generating greeting card images using pre-trained text-to-image generation model.
Artifact Removal in Histopathology Images
Nov 29, 2022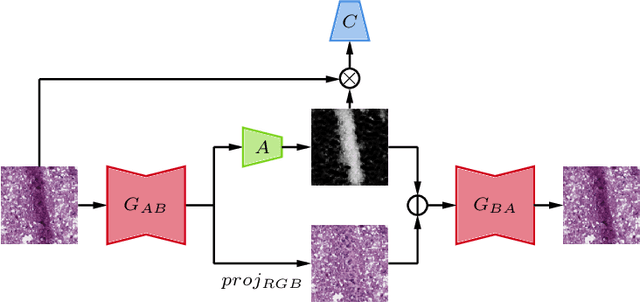

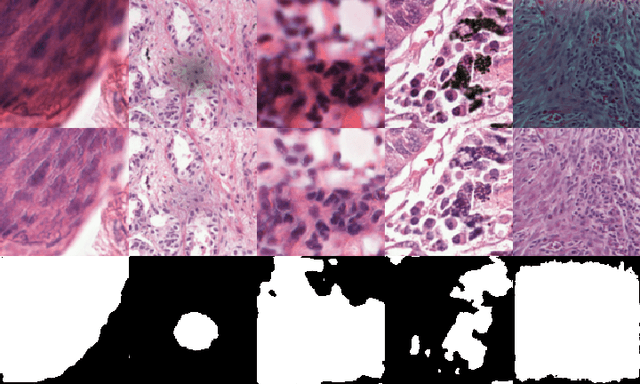

In the clinical setting of histopathology, whole-slide image (WSI) artifacts frequently arise, distorting regions of interest, and having a pernicious impact on WSI analysis. Image-to-image translation networks such as CycleGANs are in principle capable of learning an artifact removal function from unpaired data. However, we identify a surjection problem with artifact removal, and propose an weakly-supervised extension to CycleGAN to address this. We assemble a pan-cancer dataset comprising artifact and clean tiles from the TCGA database. Promising results highlight the soundness of our method.
Domain-Adaptive 3D Medical Image Synthesis: An Efficient Unsupervised Approach
Jul 02, 2022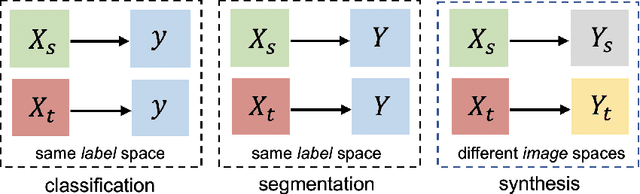

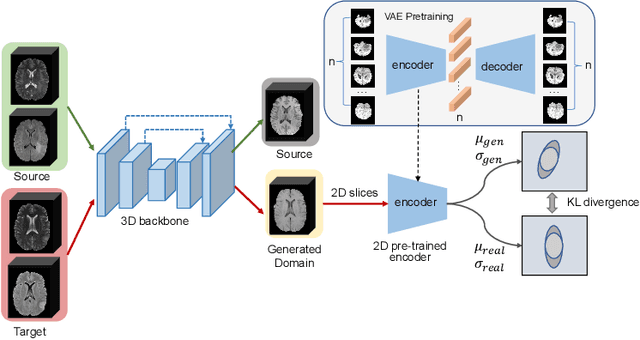
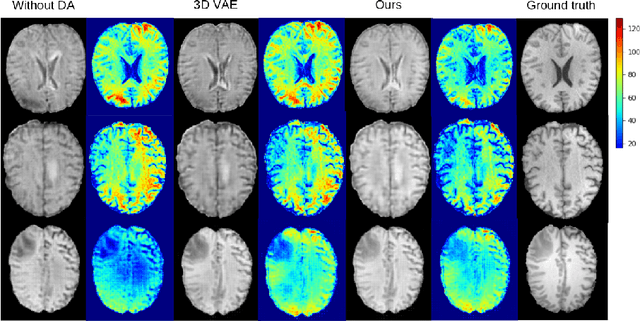
Medical image synthesis has attracted increasing attention because it could generate missing image data, improving diagnosis and benefits many downstream tasks. However, so far the developed synthesis model is not adaptive to unseen data distribution that presents domain shift, limiting its applicability in clinical routine. This work focuses on exploring domain adaptation (DA) of 3D image-to-image synthesis models. First, we highlight the technical difference in DA between classification, segmentation and synthesis models. Second, we present a novel efficient adaptation approach based on 2D variational autoencoder which approximates 3D distributions. Third, we present empirical studies on the effect of the amount of adaptation data and the key hyper-parameters. Our results show that the proposed approach can significantly improve the synthesis accuracy on unseen domains in a 3D setting. The code is publicly available at https://github.com/WinstonHuTiger/2D_VAE_UDA_for_3D_sythesis
A Multi-Scale Framework for Out-of-Distribution Detection in Dermoscopic Images
Jan 18, 2023The automatic detection of skin diseases via dermoscopic images can improve the efficiency in diagnosis and help doctors make more accurate judgments. However, conventional skin disease recognition systems may produce high confidence for out-of-distribution (OOD) data, which may become a major security vulnerability in practical applications. In this paper, we propose a multi-scale detection framework to detect out-of-distribution skin disease image data to ensure the robustness of the system. Our framework extracts features from different layers of the neural network. In the early layers, rectified activation is used to make the output features closer to the well-behaved distribution, and then an one-class SVM is trained to detect OOD data; in the penultimate layer, an adapted Gram matrix is used to calculate the features after rectified activation, and finally the layer with the best performance is chosen to compute a normality score. Experiments show that the proposed framework achieves superior performance when compared with other state-of-the-art methods in the task of skin disease recognition.
EAA-Net: Rethinking the Autoencoder Architecture with Intra-class Features for Medical Image Segmentation
Aug 19, 2022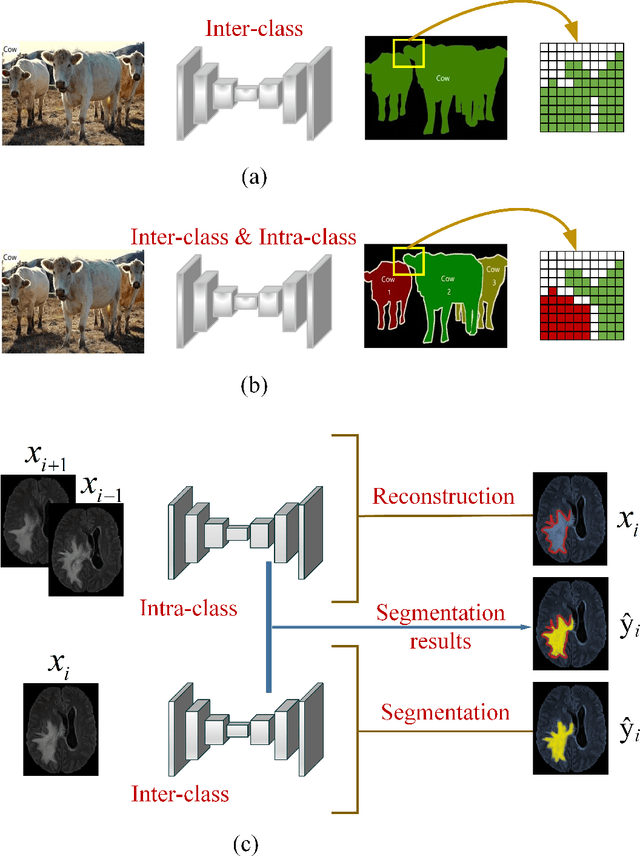
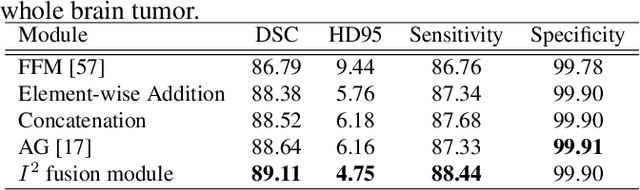
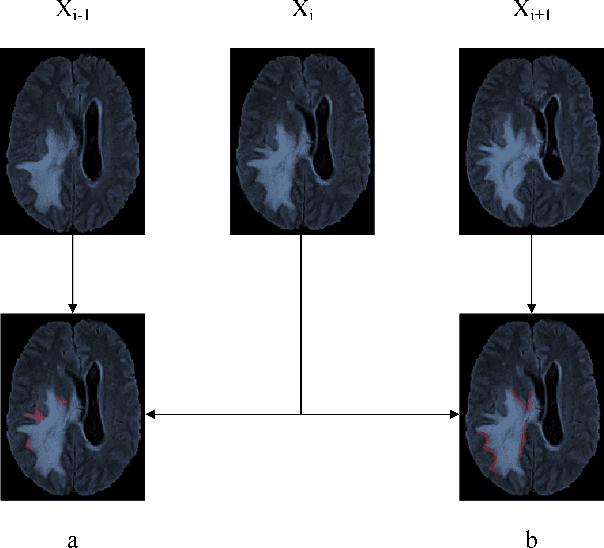
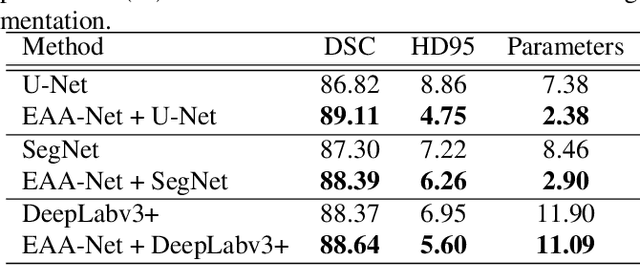
Automatic image segmentation technology is critical to the visual analysis. The autoencoder architecture has satisfying performance in various image segmentation tasks. However, autoencoders based on convolutional neural networks (CNN) seem to encounter a bottleneck in improving the accuracy of semantic segmentation. Increasing the inter-class distance between foreground and background is an inherent characteristic of the segmentation network. However, segmentation networks pay too much attention to the main visual difference between foreground and background, and ignores the detailed edge information, which leads to a reduction in the accuracy of edge segmentation. In this paper, we propose a light-weight end-to-end segmentation framework based on multi-task learning, termed Edge Attention autoencoder Network (EAA-Net), to improve edge segmentation ability. Our approach not only utilizes the segmentation network to obtain inter-class features, but also applies the reconstruction network to extract intra-class features among the foregrounds. We further design a intra-class and inter-class features fusion module -- I2 fusion module. The I2 fusion module is used to merge intra-class and inter-class features, and use a soft attention mechanism to remove invalid background information. Experimental results show that our method performs well in medical image segmentation tasks. EAA-Net is easy to implement and has small calculation cost.
DCCF: Deep Comprehensible Color Filter Learning Framework for High-Resolution Image Harmonization
Jul 13, 2022

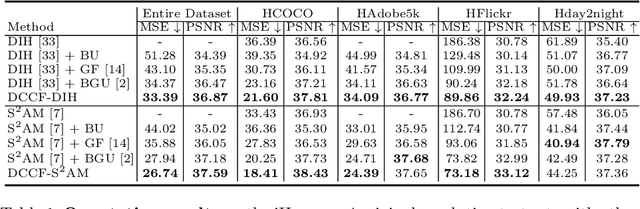
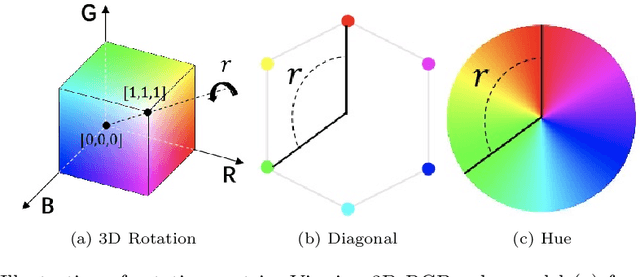
Image color harmonization algorithm aims to automatically match the color distribution of foreground and background images captured in different conditions. Previous deep learning based models neglect two issues that are critical for practical applications, namely high resolution (HR) image processing and model comprehensibility. In this paper, we propose a novel Deep Comprehensible Color Filter (DCCF) learning framework for high-resolution image harmonization. Specifically, DCCF first downsamples the original input image to its low-resolution (LR) counter-part, then learns four human comprehensible neural filters (i.e. hue, saturation, value and attentive rendering filters) in an end-to-end manner, finally applies these filters to the original input image to get the harmonized result. Benefiting from the comprehensible neural filters, we could provide a simple yet efficient handler for users to cooperate with deep model to get the desired results with very little effort when necessary. Extensive experiments demonstrate the effectiveness of DCCF learning framework and it outperforms state-of-the-art post-processing method on iHarmony4 dataset on images' full-resolutions by achieving 7.63% and 1.69% relative improvements on MSE and PSNR respectively.
The most general manner to injectively align true and predicted segments
Dec 27, 2022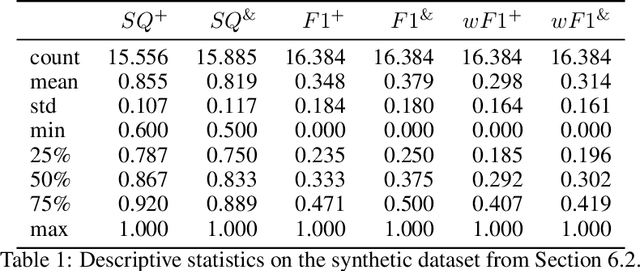
Kirilov et al (2019) develop a metric, called Panoptic Quality (PQ), to evaluate image segmentation methods. The metric is based on a confusion table, and compares a predicted to a ground truth segmentation. The only non straightforward part in this comparison is to align the segments in the two segmentations. A metric only works well if that alignment is a partial bijection. Kirilov et al (2019) list 3 desirable properties for a definition of alignment: it should be simple, interpretable and effectively computable. There are many definitions guaranteeing a partial bijection and these 3 properties. We present the weakest: one that is both sufficient and necessary to guarantee that the alignment is a partial bijection. This new condition is effectively computable and natural. It simply says that the number of correctly predicted elements (in image segmentation, the pixels) should be larger than the number of missed, and larger than the number of spurious elements. This is strictly weaker than the proposal in Kirilov et al (2019). In formulas, instead of |TP|> |FN\textbar| + |FP|, the weaker condition requires that |TP|> |FN| and |TP| > |FP|. We evaluate the new alignment condition theoretically and empirically.
Images Speak in Images: A Generalist Painter for In-Context Visual Learning
Dec 05, 2022
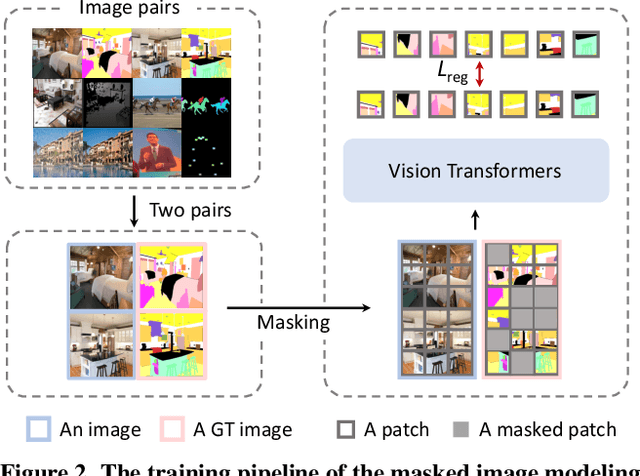


In-context learning, as a new paradigm in NLP, allows the model to rapidly adapt to various tasks with only a handful of prompts and examples. But in computer vision, the difficulties for in-context learning lie in that tasks vary significantly in the output representations, thus it is unclear how to define the general-purpose task prompts that the vision model can understand and transfer to out-of-domain tasks. In this work, we present Painter, a generalist model which addresses these obstacles with an "image"-centric solution, that is, to redefine the output of core vision tasks as images, and specify task prompts as also images. With this idea, our training process is extremely simple, which performs standard masked image modeling on the stitch of input and output image pairs. This makes the model capable of performing tasks conditioned on visible image patches. Thus, during inference, we can adopt a pair of input and output images from the same task as the input condition, to indicate which task to perform. Without bells and whistles, our generalist Painter can achieve competitive performance compared to well-established task-specific models, on seven representative vision tasks ranging from high-level visual understanding to low-level image processing. Painter significantly outperforms recent generalist models on several challenging tasks. Surprisingly, our model shows capabilities of completing out-of-domain tasks, which do not exist in the training data, such as open-category keypoint detection and object segmentation, validating the powerful task transferability of in-context learning.
Deep Learning Provides Rapid Screen for Breast Cancer Metastasis with Sentinel Lymph Nodes
Jan 14, 2023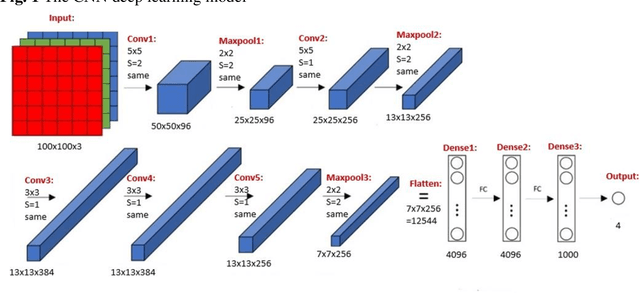
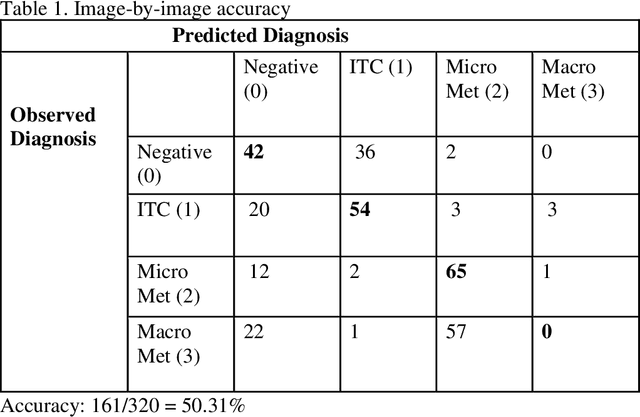
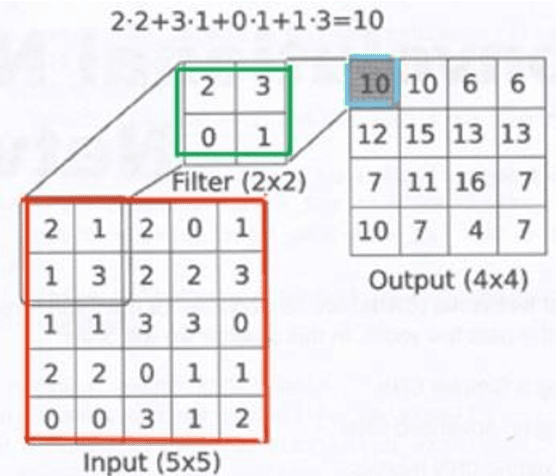
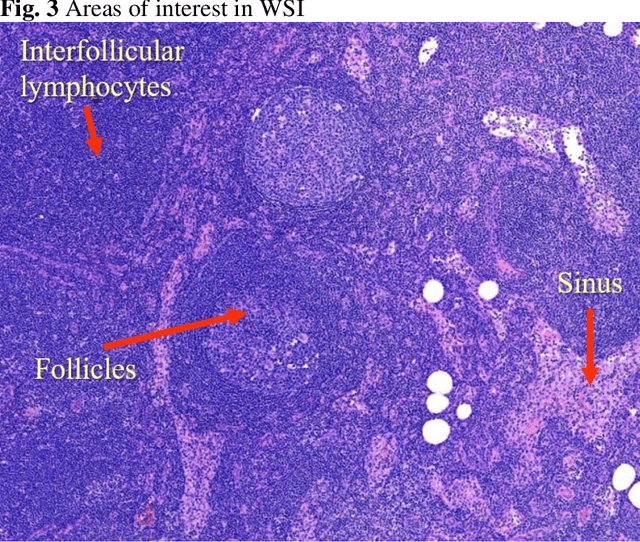
Deep learning has been shown to be useful to detect breast cancer metastases by analyzing whole slide images of sentinel lymph nodes. However, it requires extensive scanning and analysis of all the lymph nodes slides for each case. Our deep learning study focuses on breast cancer screening with only a small set of image patches from any sentinel lymph node, positive or negative for metastasis, to detect changes in tumor environment and not in the tumor itself. We design a convolutional neural network in the Python language to build a diagnostic model for this purpose. The excellent results from this preliminary study provided a proof of concept for incorporating automated metastatic screen into the digital pathology workflow to augment the pathologists' productivity. Our approach is unique since it provides a very rapid screen rather than an exhaustive search for tumor in all fields of all sentinel lymph nodes.
Augmenting Ego-Vehicle for Traffic Near-Miss and Accident Classification Dataset using Manipulating Conditional Style Translation
Jan 06, 2023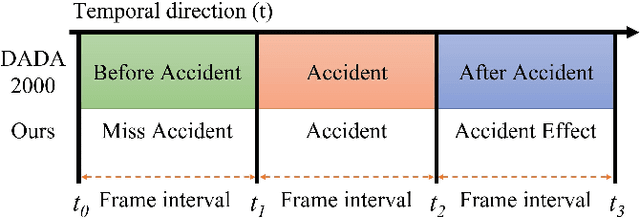
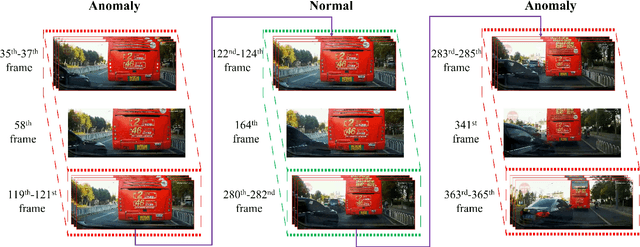

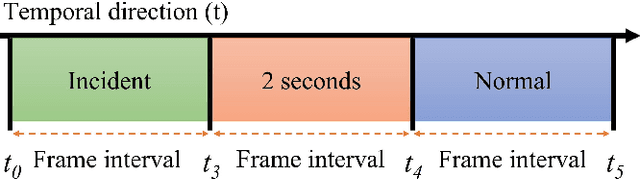
To develop the advanced self-driving systems, many researchers are focusing to alert all possible traffic risk cases from closed-circuit television (CCTV) and dashboard-mounted cameras. Most of these methods focused on identifying frame-by-frame in which an anomaly has occurred, but they are unrealized, which road traffic participant can cause ego-vehicle leading into collision because of available annotation dataset only to detect anomaly on traffic video. Near-miss is one type of accident and can be defined as a narrowly avoided accident. However, there is no difference between accident and near-miss at the time before the accident happened, so our contribution is to redefine the accident definition and re-annotate the accident inconsistency on DADA-2000 dataset together with near-miss. By extending the start and end time of accident duration, our annotation can precisely cover all ego-motions during an incident and consistently classify all possible traffic risk accidents including near-miss to give more critical information for real-world driving assistance systems. The proposed method integrates two different components: conditional style translation (CST) and separable 3-dimensional convolutional neural network (S3D). CST architecture is derived by unsupervised image-to-image translation networks (UNIT) used for augmenting the re-annotation DADA-2000 dataset to increase the number of traffic risk accident videos and to generalize the performance of video classification model on different types of conditions while S3D is useful for video classification to prove dataset re-annotation consistency. In evaluation, the proposed method achieved a significant improvement result by 10.25% positive margin from the baseline model for accuracy on cross-validation analysis.
* 8 pages, conference