 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 08, 2023
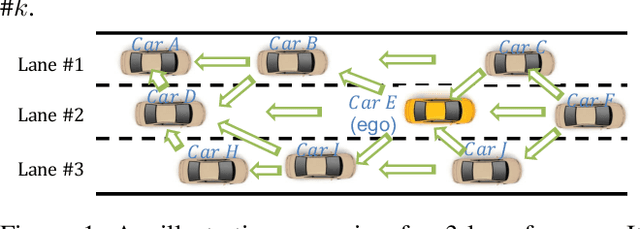

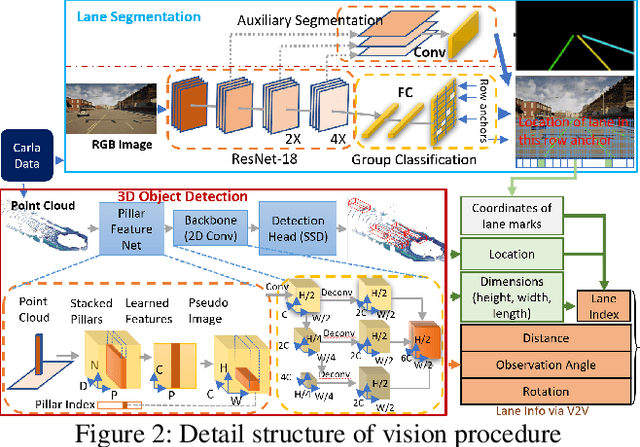
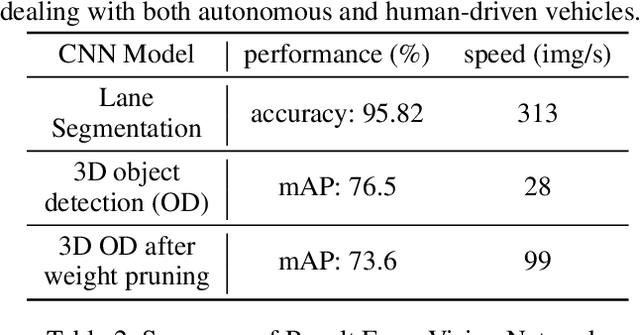
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
Spatiotemporal Deformation Perception for Fisheye Video Rectification
Feb 08, 2023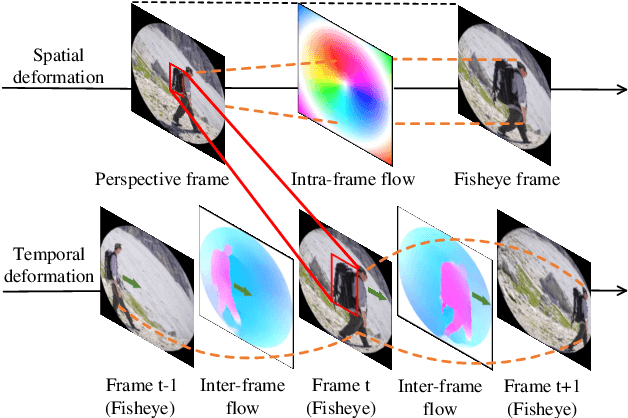
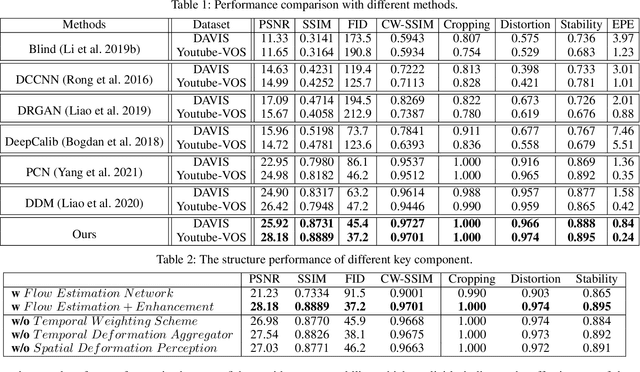
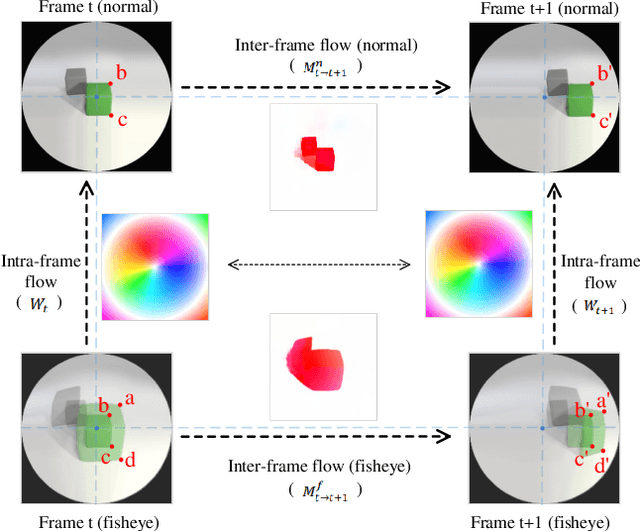
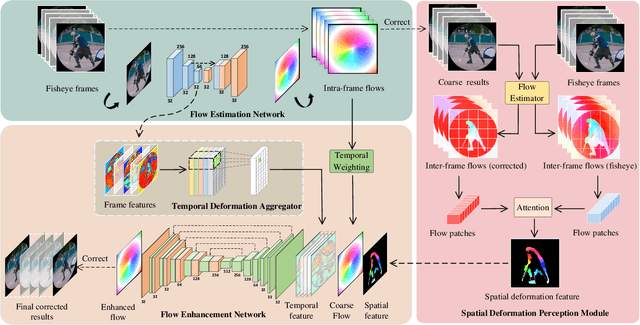
Although the distortion correction of fisheye images has been extensively studied, the correction of fisheye videos is still an elusive challenge. For different frames of the fisheye video, the existing image correction methods ignore the correlation of sequences, resulting in temporal jitter in the corrected video. To solve this problem, we propose a temporal weighting scheme to get a plausible global optical flow, which mitigates the jitter effect by progressively reducing the weight of frames. Subsequently, we observe that the inter-frame optical flow of the video is facilitated to perceive the local spatial deformation of the fisheye video. Therefore, we derive the spatial deformation through the flows of fisheye and distorted-free videos, thereby enhancing the local accuracy of the predicted result. However, the independent correction for each frame disrupts the temporal correlation. Due to the property of fisheye video, a distorted moving object may be able to find its distorted-free pattern at another moment. To this end, a temporal deformation aggregator is designed to reconstruct the deformation correlation between frames and provide a reliable global feature. Our method achieves an end-to-end correction and demonstrates superiority in correction quality and stability compared with the SOTA correction methods.
Robustness to Spurious Correlations Improves Semantic Out-of-Distribution Detection
Feb 08, 2023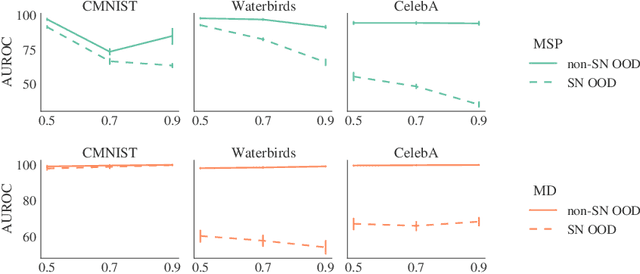
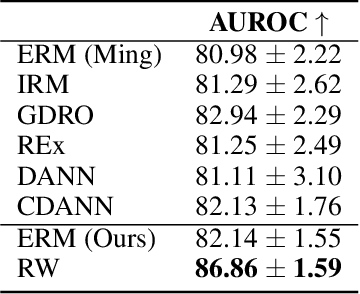
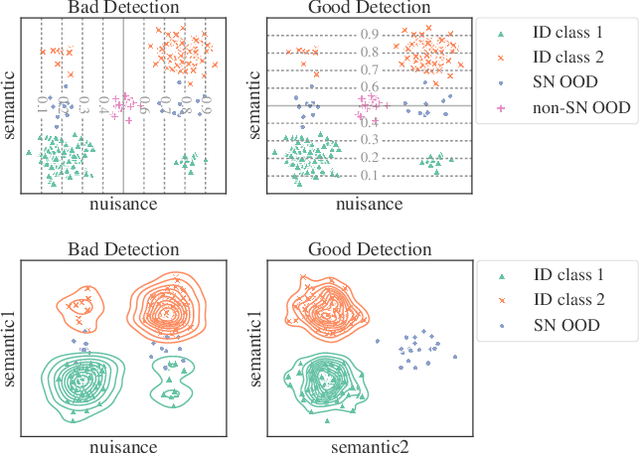
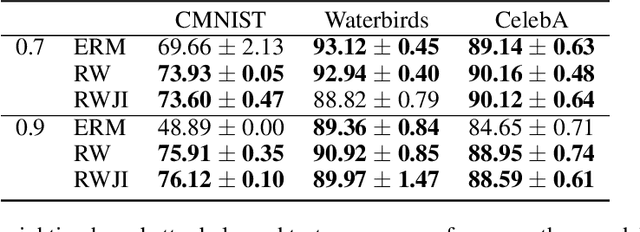
Methods which utilize the outputs or feature representations of predictive models have emerged as promising approaches for out-of-distribution (OOD) detection of image inputs. However, these methods struggle to detect OOD inputs that share nuisance values (e.g. background) with in-distribution inputs. The detection of shared-nuisance out-of-distribution (SN-OOD) inputs is particularly relevant in real-world applications, as anomalies and in-distribution inputs tend to be captured in the same settings during deployment. In this work, we provide a possible explanation for SN-OOD detection failures and propose nuisance-aware OOD detection to address them. Nuisance-aware OOD detection substitutes a classifier trained via empirical risk minimization and cross-entropy loss with one that 1. is trained under a distribution where the nuisance-label relationship is broken and 2. yields representations that are independent of the nuisance under this distribution, both marginally and conditioned on the label. We can train a classifier to achieve these objectives using Nuisance-Randomized Distillation (NuRD), an algorithm developed for OOD generalization under spurious correlations. Output- and feature-based nuisance-aware OOD detection perform substantially better than their original counterparts, succeeding even when detection based on domain generalization algorithms fails to improve performance.
Inference Time Evidences of Adversarial Attacks for Forensic on Transformers
Jan 31, 2023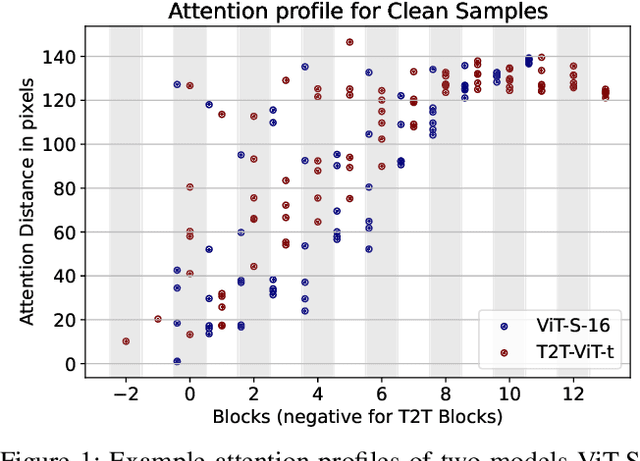
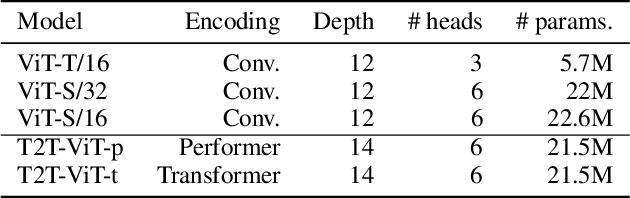
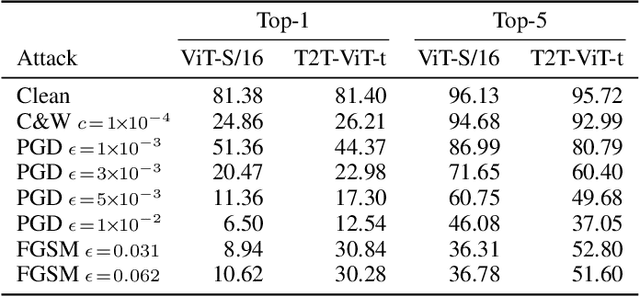
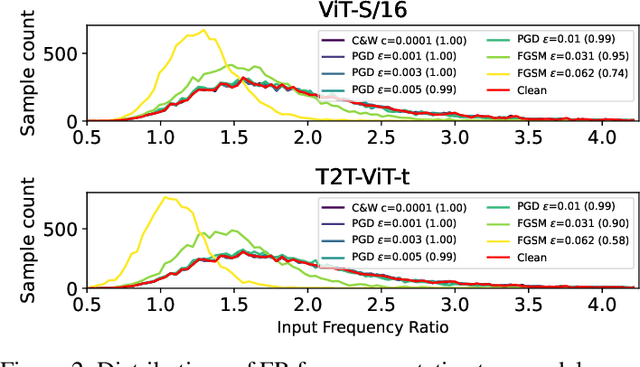
Vision Transformers (ViTs) are becoming a very popular paradigm for vision tasks as they achieve state-of-the-art performance on image classification. However, although early works implied that this network structure had increased robustness against adversarial attacks, some works argue ViTs are still vulnerable. This paper presents our first attempt toward detecting adversarial attacks during inference time using the network's input and outputs as well as latent features. We design four quantifications (or derivatives) of input, output, and latent vectors of ViT-based models that provide a signature of the inference, which could be beneficial for the attack detection, and empirically study their behavior over clean samples and adversarial samples. The results demonstrate that the quantifications from input (images) and output (posterior probabilities) are promising for distinguishing clean and adversarial samples, while latent vectors offer less discriminative power, though they give some insights on how adversarial perturbations work.
What does a platypus look like? Generating customized prompts for zero-shot image classification
Sep 07, 2022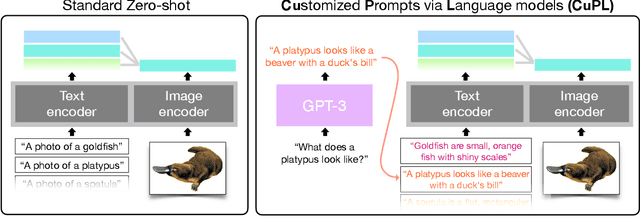
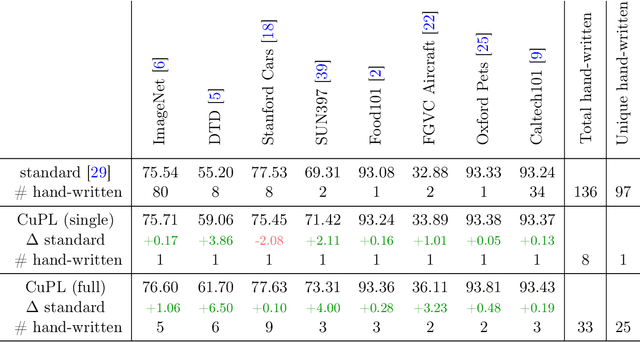
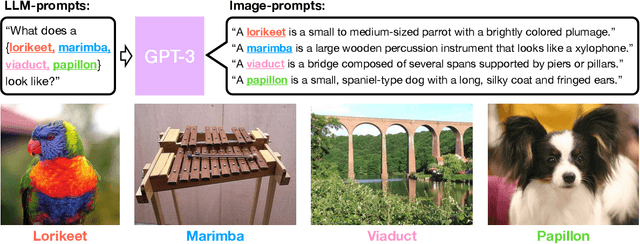
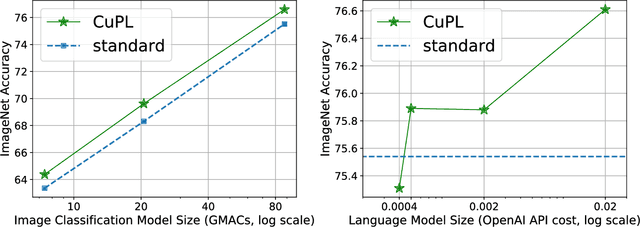
Open vocabulary models are a promising new paradigm for image classification. Unlike traditional classification models, open vocabulary models classify among any arbitrary set of categories specified with natural language during inference. This natural language, called "prompts", typically consists of a set of hand-written templates (e.g., "a photo of a {}") which are completed with each of the category names. This work introduces a simple method to generate higher accuracy prompts, without using explicit knowledge of the image domain and with far fewer hand-constructed sentences. To achieve this, we combine open vocabulary models with large language models (LLMs) to create Customized Prompts via Language models (CuPL, pronounced "couple"). In particular, we leverage the knowledge contained in LLMs in order to generate many descriptive sentences that are customized for each object category. We find that this straightforward and general approach improves accuracy on a range of zero-shot image classification benchmarks, including over one percentage point gain on ImageNet. Finally, this method requires no additional training and remains completely zero-shot. Code is available at https://github.com/sarahpratt/CuPL.
MEW-UNet: Multi-axis representation learning in frequency domain for medical image segmentation
Oct 25, 2022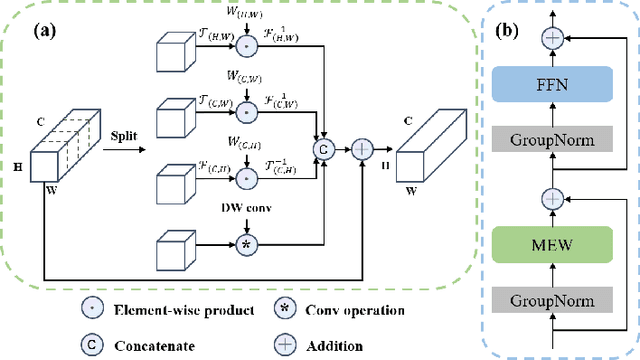
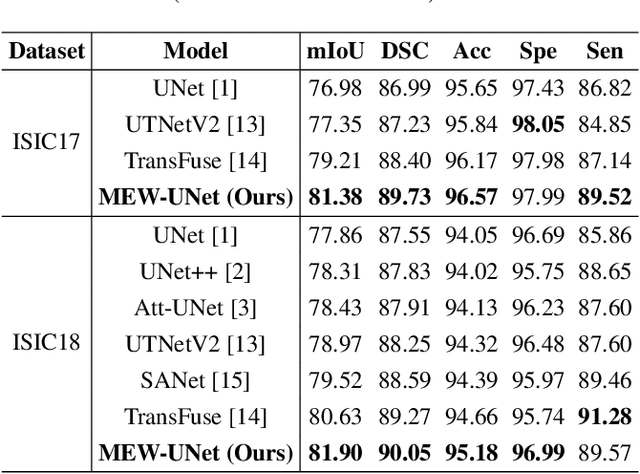
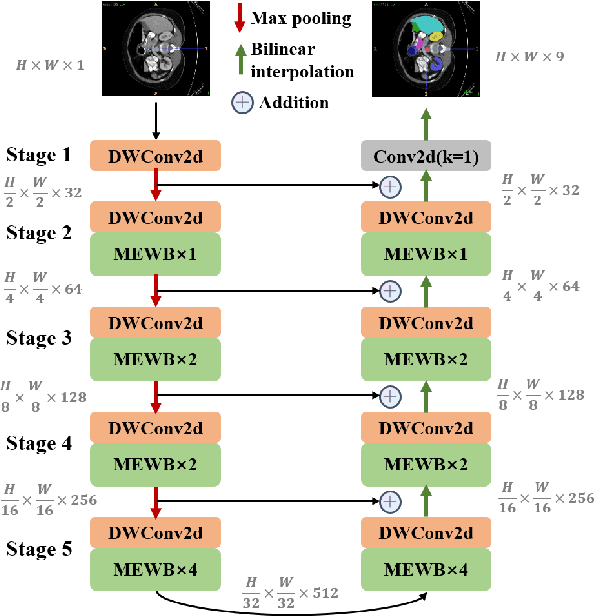
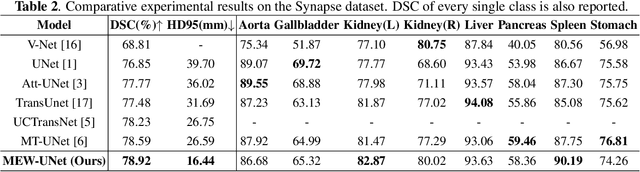
Recently, Visual Transformer (ViT) has been widely used in various fields of computer vision due to applying self-attention mechanism in the spatial domain to modeling global knowledge. Especially in medical image segmentation (MIS), many works are devoted to combining ViT and CNN, and even some works directly utilize pure ViT-based models. However, recent works improved models in the aspect of spatial domain while ignoring the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) for MIS based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input feature and assigns the external weight in the frequency domain, which is generated by our Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets and achieve state-of-the-art performances. In particular, on the Synapse dataset, our method outperforms MT-UNet by 10.15mm in terms of HD95. Code is available at https://github.com/JCruan519/MEW-UNet.
Self-Supervised 2D/3D Registration for X-Ray to CT Image Fusion
Oct 14, 2022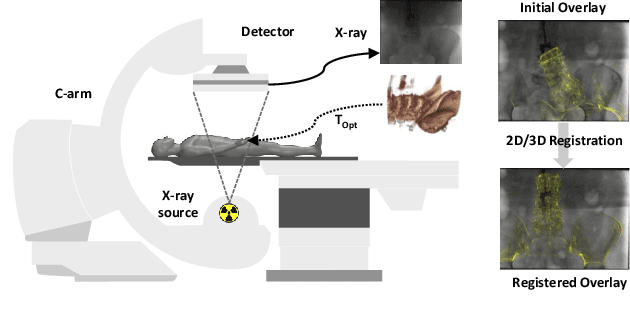

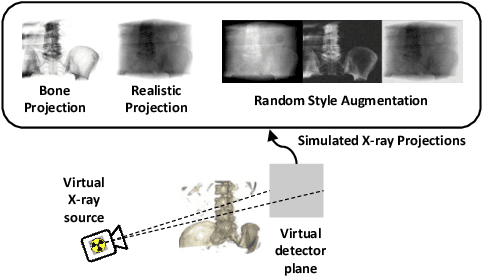

Deep Learning-based 2D/3D registration enables fast, robust, and accurate X-ray to CT image fusion when large annotated paired datasets are available for training. However, the need for paired CT volume and X-ray images with ground truth registration limits the applicability in interventional scenarios. An alternative is to use simulated X-ray projections from CT volumes, thus removing the need for paired annotated datasets. Deep Neural Networks trained exclusively on simulated X-ray projections can perform significantly worse on real X-ray images due to the domain gap. We propose a self-supervised 2D/3D registration framework combining simulated training with unsupervised feature and pixel space domain adaptation to overcome the domain gap and eliminate the need for paired annotated datasets. Our framework achieves a registration accuracy of 1.83$\pm$1.16 mm with a high success ratio of 90.1% on real X-ray images showing a 23.9% increase in success ratio compared to reference annotation-free algorithms.
Foundation Models for Natural Language Processing -- Pre-trained Language Models Integrating Media
Feb 16, 2023This open access book provides a comprehensive overview of the state of the art in research and applications of Foundation Models and is intended for readers familiar with basic Natural Language Processing (NLP) concepts. Over the recent years, a revolutionary new paradigm has been developed for training models for NLP. These models are first pre-trained on large collections of text documents to acquire general syntactic knowledge and semantic information. Then, they are fine-tuned for specific tasks, which they can often solve with superhuman accuracy. When the models are large enough, they can be instructed by prompts to solve new tasks without any fine-tuning. Moreover, they can be applied to a wide range of different media and problem domains, ranging from image and video processing to robot control learning. Because they provide a blueprint for solving many tasks in artificial intelligence, they have been called Foundation Models. After a brief introduction to basic NLP models the main pre-trained language models BERT, GPT and sequence-to-sequence transformer are described, as well as the concepts of self-attention and context-sensitive embedding. Then, different approaches to improving these models are discussed, such as expanding the pre-training criteria, increasing the length of input texts, or including extra knowledge. An overview of the best-performing models for about twenty application areas is then presented, e.g., question answering, translation, story generation, dialog systems, generating images from text, etc. For each application area, the strengths and weaknesses of current models are discussed, and an outlook on further developments is given. In addition, links are provided to freely available program code. A concluding chapter summarizes the economic opportunities, mitigation of risks, and potential developments of AI.
MOC-AE: An Anatomically-Pathological-Based model for Clinical Decision Support System of tumoural brain images
Jan 09, 2023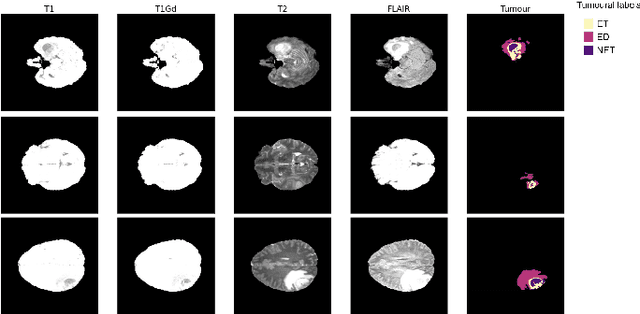
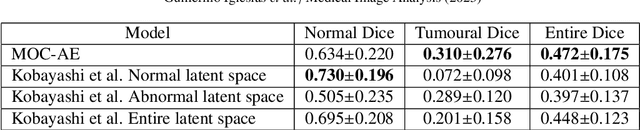
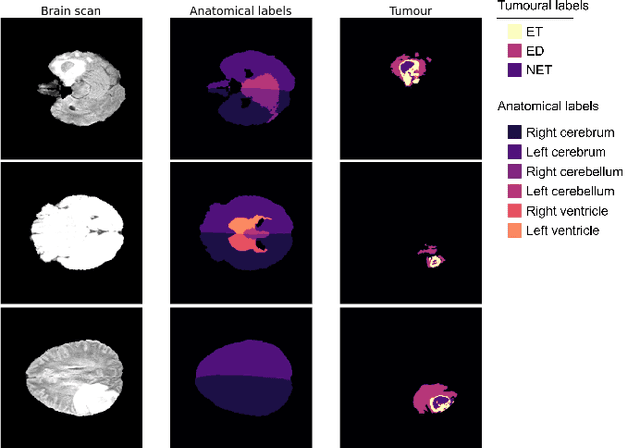
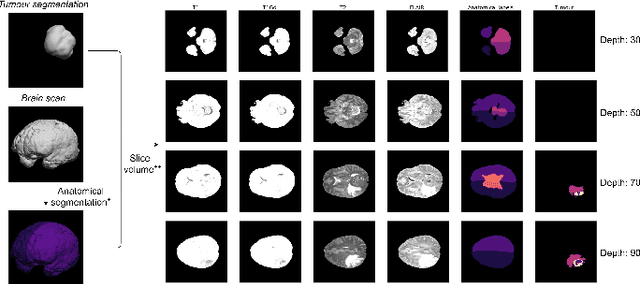
The present work proposes a Multi-Output Classification Autoencoder (MOC-AE) algorithm to extract features from brain tumour images. The proposed algorithm is able to focus on both the normal features of the patient and the pathological features present in the case, resulting in a compact and significant representation of each image. The architecture of MOC-AE combines anatomical information from the patients scan using an Autoencoder (AE) with information related to a specific pathology using a classification output with the same image descriptor. This combination of goals forces the network to maintain a balance between anatomical and pathological features of the case while maintaining the low cost of the labels being used. The results obtained are compared with those of similar studies and the strengths and limitations of each approach are discussed. The results demonstrate that the proposed algorithm is capable of achieving state-of-the-art results in terms of both the anatomical and tumor characteristics of the recommended cases.
[Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT
Feb 13, 2023![Figure 1 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table2-1.png&w=640&q=75)
Minerals are indispensable for a functioning modern society. Yet, their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials. Typically, these processes must be meticulously adapted to the precise properties of the processed particles, requiring an extensive characterization of their shapes, appearances as well as the overall material composition. Current approaches perform this analysis based on bulk segmentation and characterization of particles, and rely on rudimentary postprocessing techniques to separate touching particles. However, due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image, these approaches leave untapped potential to be leveraged. Here, we propose an instance segmentation method that is able to extract individual particles from large micro CT images taken from mineral samples embedded in an epoxy matrix. Our approach is based on the powerful nnU-Net framework, introduces a particle size normalization, makes use of a border-core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals. We demonstrate that our approach can be applied out-of-the box to a large variety of particle types, including materials and appearances that have not been part of the training set. Thus, no further manual annotations and retraining are required when applying the method to new mineral samples, enabling substantially higher scalability of experiments than existing methods. Our code and dataset are made publicly available.