 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spectral2Spectral: Image-spectral Similarity Assisted Spectral CT Deep Reconstruction without Reference
Oct 03, 2022
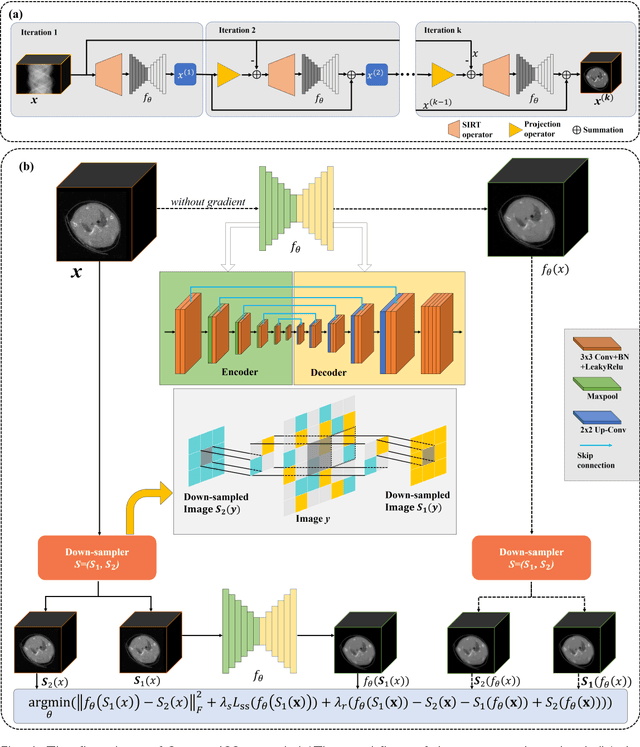
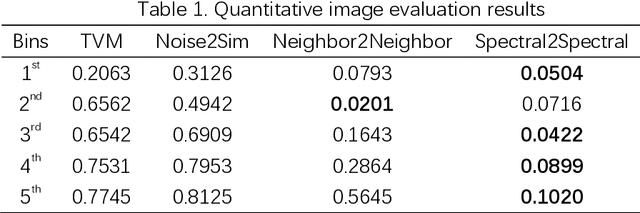

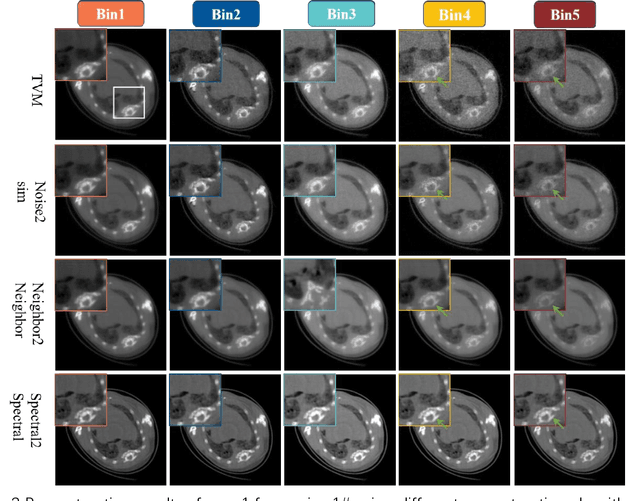
The photon-counting detector (PCD) based spectral computed tomography attracts much more attentions since it has the capability to provide more accurate identification and quantitative analysis for biomedical materials. The limited number of photons within narrow energy-bin leads to low signal-noise ratio data. The existing supervised deep reconstruction networks for CT reconstruction are difficult to address these challenges. In this paper, we propose an iterative deep reconstruction network to synergize model and data priors into a unified framework, named as Spectral2Spectral. Our Spectral2Spectral employs an unsupervised deep training strategy to obtain high-quality images from noisy data with an end-to-end fashion. The structural similarity prior within image-spectral domain is refined as a regularization term to further constrain the network training. The weights of neural network are automatically updated to capture image features and structures with iterative process. Three large-scale preclinical datasets experiments demonstrate that the Spectral2spectral reconstruct better image quality than other state-of-the-art methods.
On the Feasibility of Machine Learning Augmented Magnetic Resonance for Point-of-Care Identification of Disease
Feb 02, 2023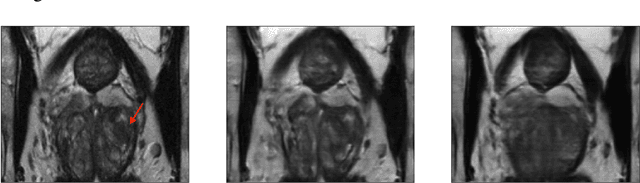

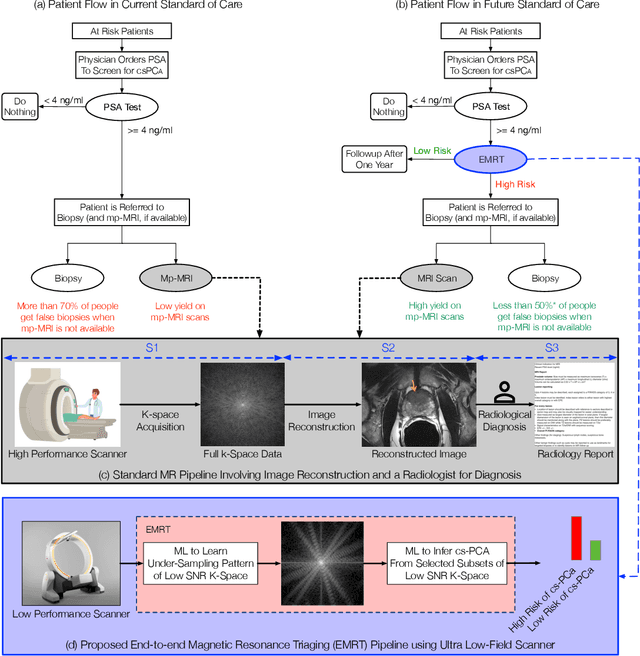

Early detection of many life-threatening diseases (e.g., prostate and breast cancer) within at-risk population can improve clinical outcomes and reduce cost of care. While numerous disease-specific "screening" tests that are closer to Point-of-Care (POC) are in use for this task, their low specificity results in unnecessary biopsies, leading to avoidable patient trauma and wasteful healthcare spending. On the other hand, despite the high accuracy of Magnetic Resonance (MR) imaging in disease diagnosis, it is not used as a POC disease identification tool because of poor accessibility. The root cause of poor accessibility of MR stems from the requirement to reconstruct high-fidelity images, as it necessitates a lengthy and complex process of acquiring large quantities of high-quality k-space measurements. In this study we explore the feasibility of an ML-augmented MR pipeline that directly infers the disease sidestepping the image reconstruction process. We hypothesise that the disease classification task can be solved using a very small tailored subset of k-space data, compared to image reconstruction. Towards that end, we propose a method that performs two tasks: 1) identifies a subset of the k-space that maximizes disease identification accuracy, and 2) infers the disease directly using the identified k-space subset, bypassing the image reconstruction step. We validate our hypothesis by measuring the performance of the proposed system across multiple diseases and anatomies. We show that comparable performance to image-based classifiers, trained on images reconstructed with full k-space data, can be achieved using small quantities of data: 8% of the data for detecting multiple abnormalities in prostate and brain scans, and 5% of the data for knee abnormalities. To better understand the proposed approach and instigate future research, we provide an extensive analysis and release code.
A Capsule Network for Hierarchical Multi-Label Image Classification
Sep 13, 2022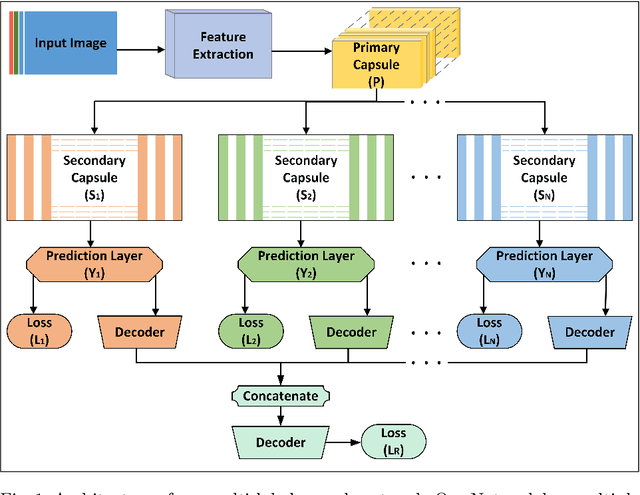
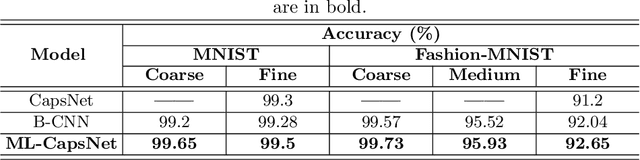
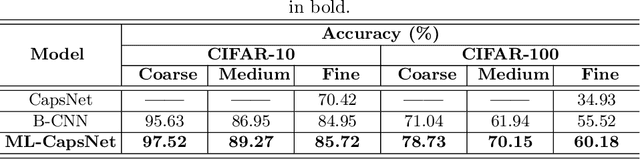
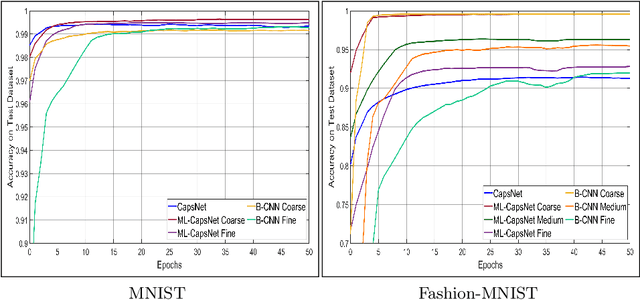
Image classification is one of the most important areas in computer vision. Hierarchical multi-label classification applies when a multi-class image classification problem is arranged into smaller ones based upon a hierarchy or taxonomy. Thus, hierarchical classification modes generally provide multiple class predictions on each instance, whereby these are expected to reflect the structure of image classes as related to one another. In this paper, we propose a multi-label capsule network (ML-CapsNet) for hierarchical classification. Our ML-CapsNet predicts multiple image classes based on a hierarchical class-label tree structure. To this end, we present a loss function that takes into account the multi-label predictions of the network. As a result, the training approach for our ML-CapsNet uses a coarse to fine paradigm while maintaining consistency with the structure in the classification levels in the label-hierarchy. We also perform experiments using widely available datasets and compare the model with alternatives elsewhere in the literature. In our experiments, our ML-CapsNet yields a margin of improvement with respect to these alternative methods.
Energy-Aware JPEG Image Compression: A Multi-Objective Approach
Sep 09, 2022
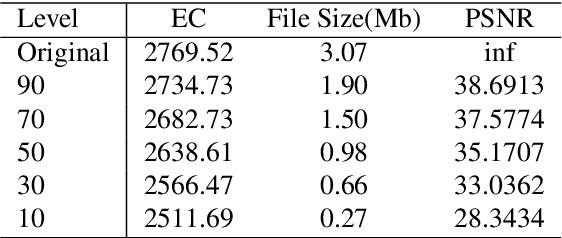
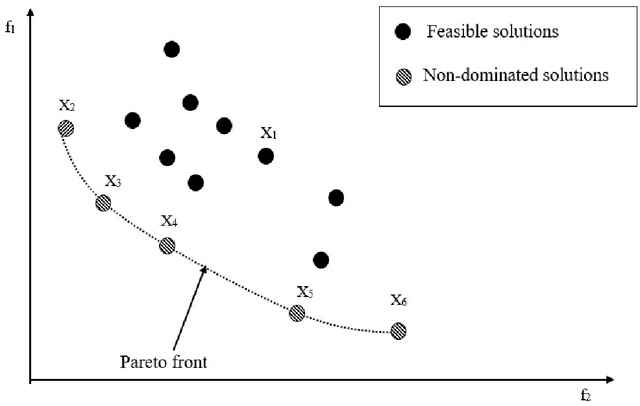
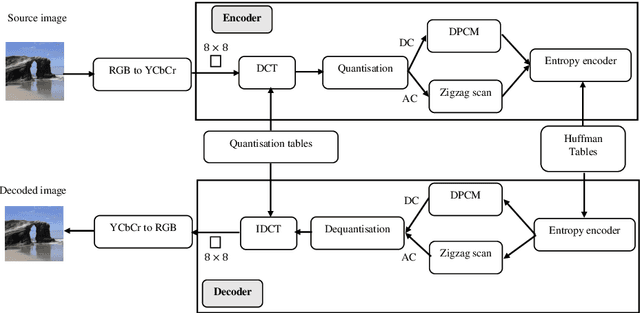
Customer satisfaction is crucially affected by energy consumption in mobile devices. One of the most energy-consuming parts of an application is images. While different images with different quality consume different amounts of energy, there are no straightforward methods to calculate the energy consumption of an operation in a typical image. This paper, first, investigates that there is a correlation between energy consumption and image quality as well as image file size. Therefore, these two can be considered as a proxy for energy consumption. Then, we propose a multi-objective strategy to enhance image quality and reduce image file size based on the quantisation tables in JPEG image compression. To this end, we have used two general multi-objective metaheuristic approaches: scalarisation and Pareto-based. Scalarisation methods find a single optimal solution based on combining different objectives, while Pareto-based techniques aim to achieve a set of solutions. In this paper, we embed our strategy into five scalarisation algorithms, including energy-aware multi-objective genetic algorithm (EnMOGA), energy-aware multi-objective particle swarm optimisation (EnMOPSO), energy-aware multi-objective differential evolution (EnMODE), energy-aware multi-objective evolutionary strategy (EnMOES), and energy-aware multi-objective pattern search (EnMOPS). Also, two Pareto-based methods, including a non-dominated sorting genetic algorithm (NSGA-II) and a reference-point-based NSGA-II (NSGA-III) are used for the embedding scheme, and two Pareto-based algorithms, EnNSGAII and EnNSGAIII, are presented. Experimental studies show that the performance of the baseline algorithm is improved by embedding the proposed strategy into metaheuristic algorithms.
Hybrid Dual Mean-Teacher Network With Double-Uncertainty Guidance for Semi-Supervised Segmentation of MRI Scans
Mar 09, 2023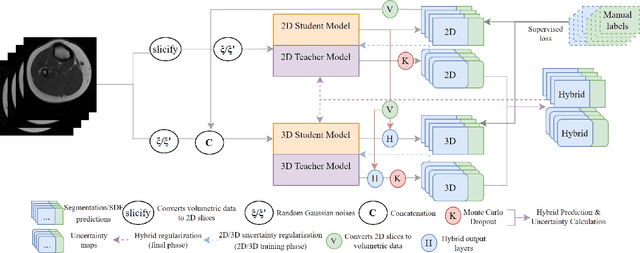
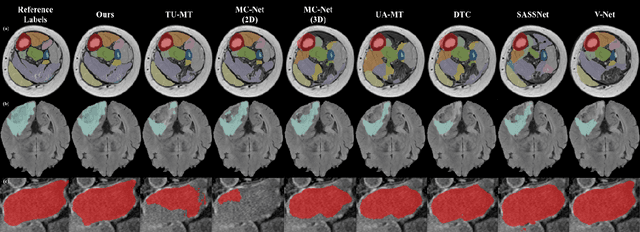
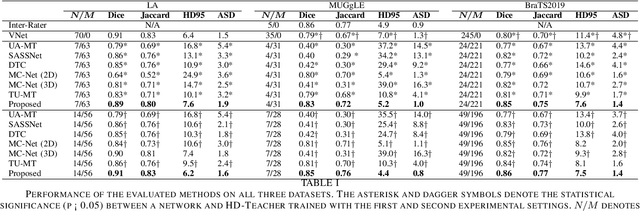
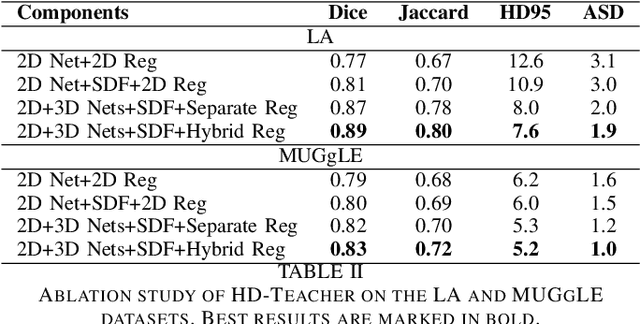
Semi-supervised learning has made significant progress in medical image segmentation. However, existing methods primarily utilize information acquired from a single dimensionality (2D/3D), resulting in sub-optimal performance on challenging data, such as magnetic resonance imaging (MRI) scans with multiple objects and highly anisotropic resolution. To address this issue, we present a Hybrid Dual Mean-Teacher (HD-Teacher) model with hybrid, semi-supervised, and multi-task learning to achieve highly effective semi-supervised segmentation. HD-Teacher employs a 2D and a 3D mean-teacher network to produce segmentation labels and signed distance fields from the hybrid information captured in both dimensionalities. This hybrid learning mechanism allows HD-Teacher to combine the `best of both worlds', utilizing features extracted from either 2D, 3D, or both dimensions to produce outputs as it sees fit. Outputs from 2D and 3D teacher models are also dynamically combined, based on their individual uncertainty scores, into a single hybrid prediction, where the hybrid uncertainty is estimated. We then propose a hybrid regularization module to encourage both student models to produce results close to the uncertainty-weighted hybrid prediction. The hybrid uncertainty suppresses unreliable knowledge in the hybrid prediction, leaving only useful information to improve network performance further. Extensive experiments of binary and multi-class segmentation conducted on three MRI datasets demonstrate the effectiveness of the proposed framework. Code is available at https://github.com/ThisGame42/Hybrid-Teacher.
R-Tuning: Regularized Prompt Tuning in Open-Set Scenarios
Mar 09, 2023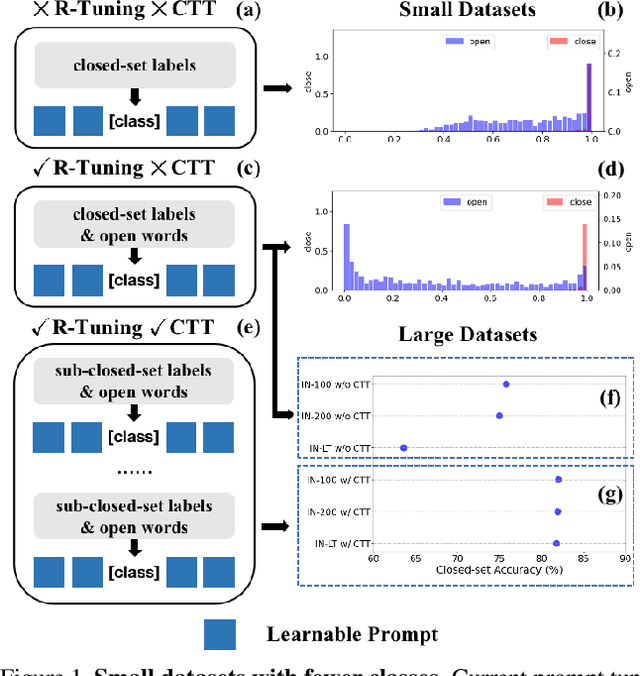
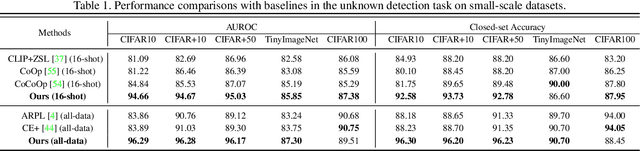
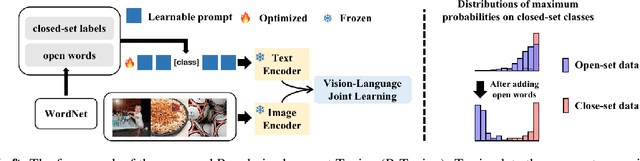
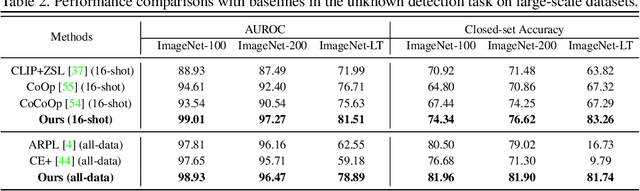
In realistic open-set scenarios where labels of a part of testing data are totally unknown, current prompt methods on vision-language (VL) models always predict the unknown classes as the downstream training classes. The exhibited label bias causes difficulty in the open set recognition (OSR), by which an image should be correctly predicted as one of the known classes or the unknown one. To learn prompts in open-set scenarios, we propose the Regularized prompt Tuning (R-Tuning) to mitigate the label bias. It introduces open words from the WordNet to extend the range of words forming the prompt texts from only closed-set label words to more. Thus, prompts are tuned in a simulated open-set scenario. Besides, inspired by the observation that classifying directly on large datasets causes a much higher false positive rate than on small datasets, we propose the Combinatorial Tuning and Testing (CTT) strategy for improving performance. CTT decomposes R-Tuning on large datasets as multiple independent group-wise tuning on fewer classes, then makes comprehensive predictions by selecting the optimal sub-prompt. For fair comparisons, we construct new baselines for OSR based on VL models, especially for prompt methods. Our method achieves the best results on datasets with various scales. Extensive ablation studies validate the effectiveness of our method.
OEKG: The Open Event Knowledge Graph
Feb 28, 2023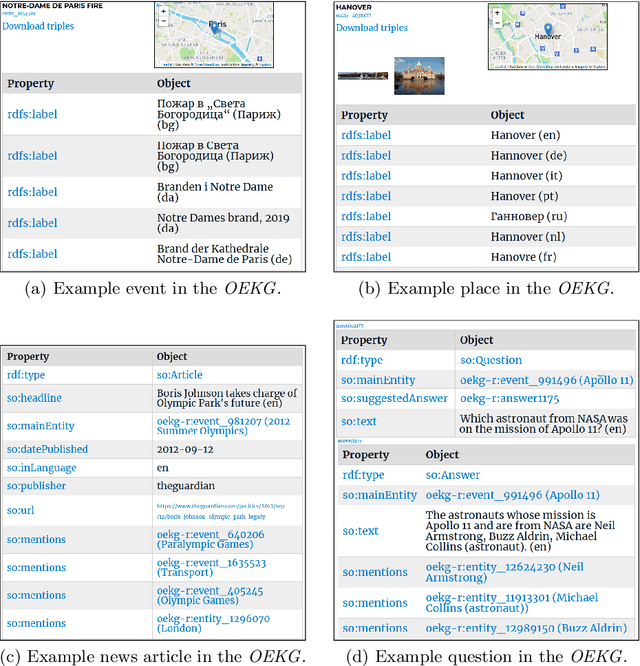
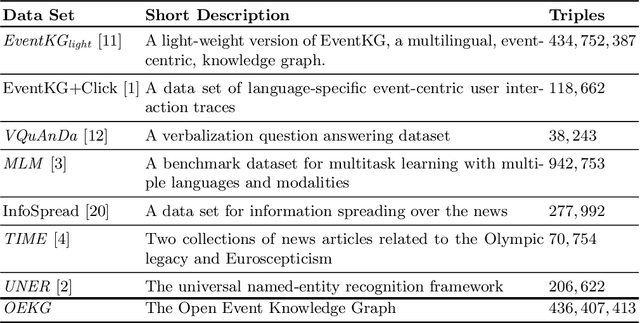
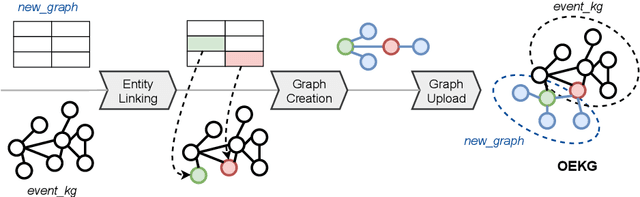

Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
Can We Use Diffusion Probabilistic Models for 3D Motion Prediction?
Feb 28, 2023
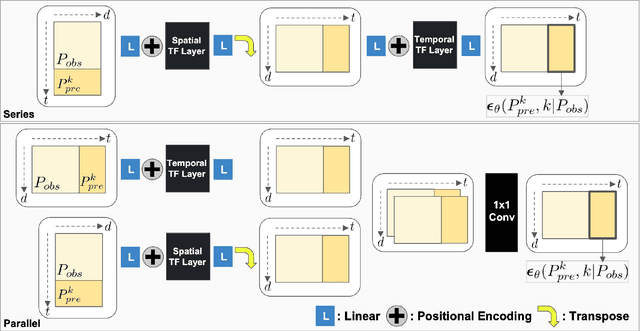
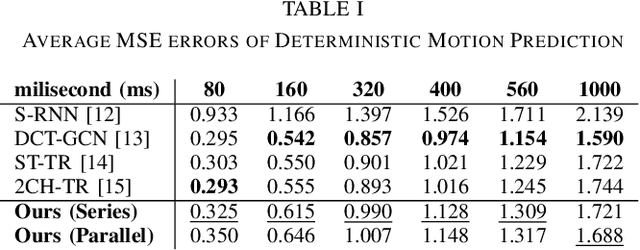
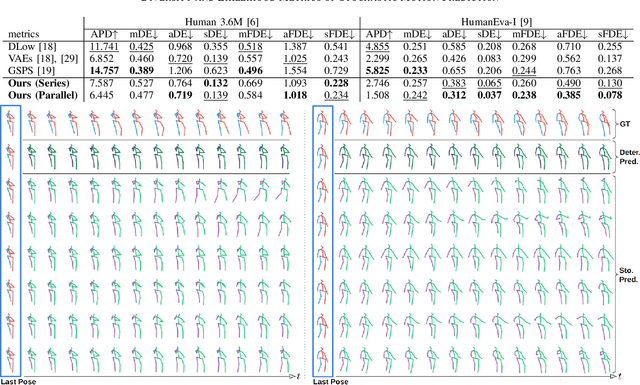
After many researchers observed fruitfulness from the recent diffusion probabilistic model, its effectiveness in image generation is actively studied these days. In this paper, our objective is to evaluate the potential of diffusion probabilistic models for 3D human motion-related tasks. To this end, this paper presents a study of employing diffusion probabilistic models to predict future 3D human motion(s) from the previously observed motion. Based on the Human 3.6M and HumanEva-I datasets, our results show that diffusion probabilistic models are competitive for both single (deterministic) and multiple (stochastic) 3D motion prediction tasks, after finishing a single training process. In addition, we find out that diffusion probabilistic models can offer an attractive compromise, since they can strike the right balance between the likelihood and diversity of the predicted future motions. Our code is publicly available on the project website: https://sites.google.com/view/diffusion-motion-prediction.
mmSense: Detecting Concealed Weapons with a Miniature Radar Sensor
Feb 28, 2023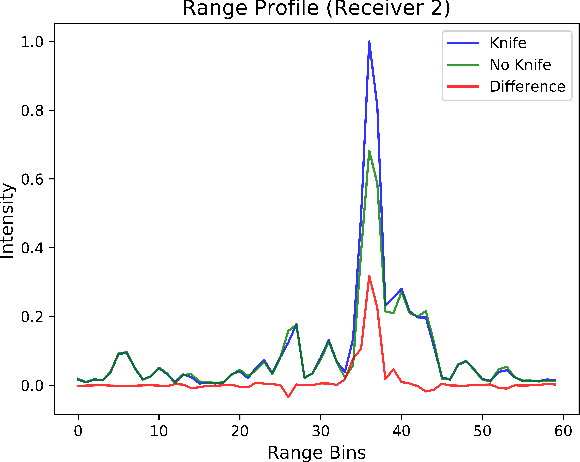
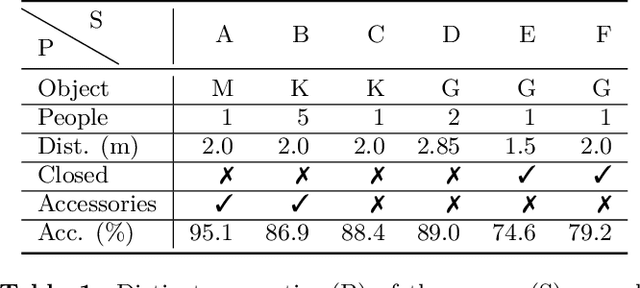
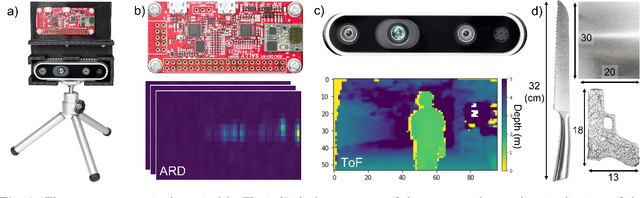
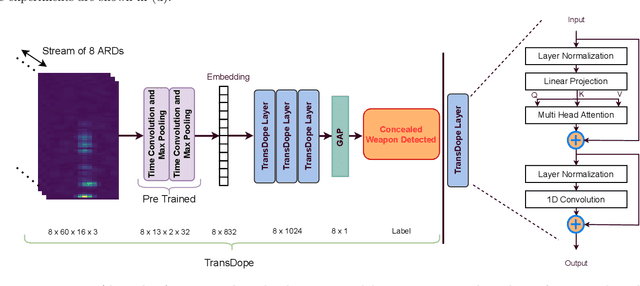
For widespread adoption, public security and surveillance systems must be accurate, portable, compact, and real-time, without impeding the privacy of the individuals being observed. Current systems broadly fall into two categories -- image-based which are accurate, but lack privacy, and RF signal-based, which preserve privacy but lack portability, compactness and accuracy. Our paper proposes mmSense, an end-to-end portable miniaturised real-time system that can accurately detect the presence of concealed metallic objects on persons in a discrete, privacy-preserving modality. mmSense features millimeter wave radar technology, provided by Google's Soli sensor for its data acquisition, and TransDope, our real-time neural network, capable of processing a single radar data frame in 19 ms. mmSense achieves high recognition rates on a diverse set of challenging scenes while running on standard laptop hardware, demonstrating a significant advancement towards creating portable, cost-effective real-time radar based surveillance systems.
CGAN-ECT: Tomography Image Reconstruction from Electrical Capacitance Measurements Using CGANs
Sep 12, 2022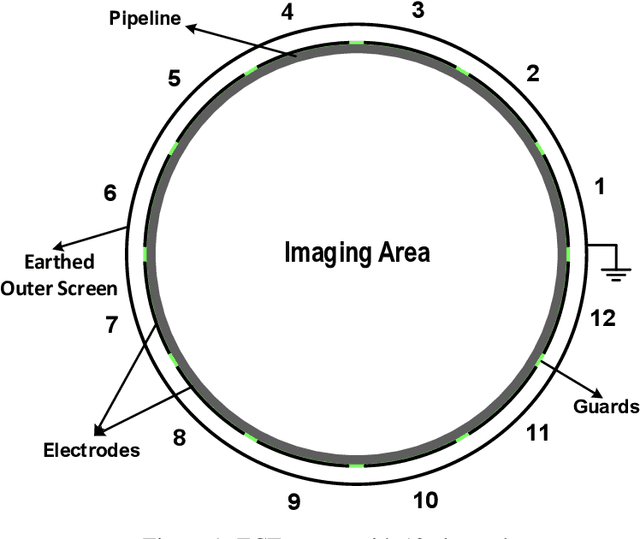
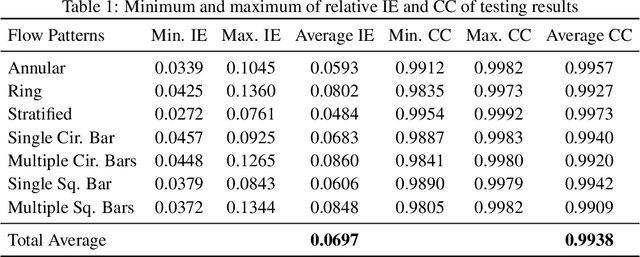
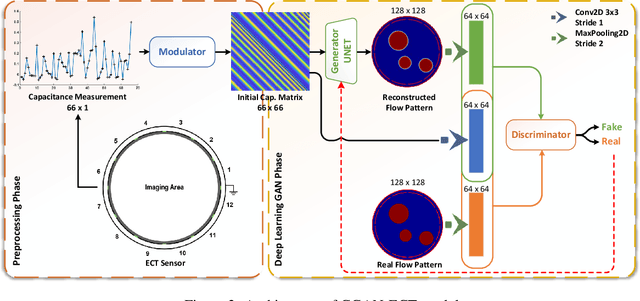
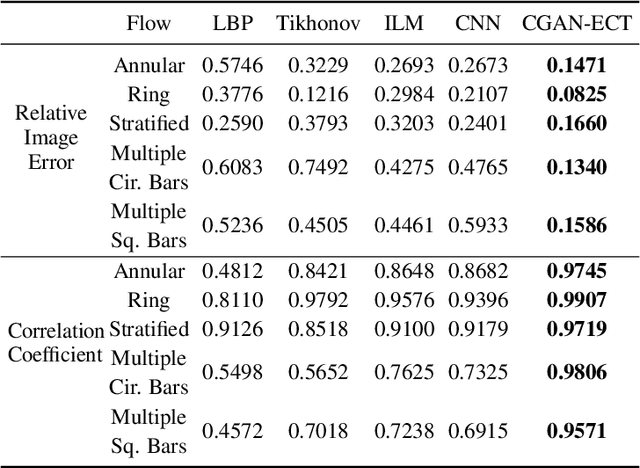
Due to the rapid growth of Electrical Capacitance Tomography (ECT) applications in several industrial fields, there is a crucial need for developing high quality, yet fast, methodologies of image reconstruction from raw capacitance measurements. Deep learning, as an effective non-linear mapping tool for complicated functions, has been going viral in many fields including electrical tomography. In this paper, we propose a Conditional Generative Adversarial Network (CGAN) model for reconstructing ECT images from capacitance measurements. The initial image of the CGAN model is constructed from the capacitance measurement. To our knowledge, this is the first time to represent the capacitance measurements in an image form. We have created a new massive ECT dataset of 320K synthetic image measurements pairs for training, and testing the proposed model. The feasibility and generalization ability of the proposed CGAN-ECT model are evaluated using testing dataset, contaminated data and flow patterns that are not exposed to the model during the training phase. The evaluation results prove that the proposed CGAN-ECT model can efficiently create more accurate ECT images than traditional and other deep learning-based image reconstruction algorithms. CGAN-ECT achieved an average image correlation coefficient of more than 99.3% and an average relative image error about 0.07.