 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Event Representations using Event Knowledge Graphs and Natural Language Processing
Mar 08, 2023


Recent work has utilised knowledge-aware approaches to natural language understanding, question answering, recommendation systems, and other tasks. These approaches rely on well-constructed and large-scale knowledge graphs that can be useful for many downstream applications and empower knowledge-aware models with commonsense reasoning. Such knowledge graphs are constructed through knowledge acquisition tasks such as relation extraction and knowledge graph completion. This work seeks to utilise and build on the growing body of work that uses findings from the field of natural language processing (NLP) to extract knowledge from text and build knowledge graphs. The focus of this research project is on how we can use transformer-based approaches to extract and contextualise event information, matching it to existing ontologies, to build a comprehensive knowledge of graph-based event representations. Specifically, sub-event extraction is used as a way of creating sub-event-aware event representations. These event representations are then further enriched through fine-grained location extraction and contextualised through the alignment of historically relevant quotes.
OEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
Building Multilingual Corpora for a Complex Named Entity Recognition and Classification Hierarchy using Wikipedia and DBpedia
Dec 14, 2022



With the ever-growing popularity of the field of NLP, the demand for datasets in low resourced-languages follows suit. Following a previously established framework, in this paper, we present the UNER dataset, a multilingual and hierarchical parallel corpus annotated for named-entities. We describe in detail the developed procedure necessary to create this type of dataset in any language available on Wikipedia with DBpedia information. The three-step procedure extracts entities from Wikipedia articles, links them to DBpedia, and maps the DBpedia sets of classes to the UNER labels. This is followed by a post-processing procedure that significantly increases the number of identified entities in the final results. The paper concludes with a statistical and qualitative analysis of the resulting dataset.
QuoteKG: A Multilingual Knowledge Graph of Quotes
Jul 19, 2022Quotes of public figures can mark turning points in history. A quote can explain its originator's actions, foreshadowing political or personal decisions and revealing character traits. Impactful quotes cross language barriers and influence the general population's reaction to specific stances, always facing the risk of being misattributed or taken out of context. The provision of a cross-lingual knowledge graph of quotes that establishes the authenticity of quotes and their contexts is of great importance to allow the exploration of the lives of important people as well as topics from the perspective of what was actually said. In this paper, we present QuoteKG, the first multilingual knowledge graph of quotes. We propose the QuoteKG creation pipeline that extracts quotes from Wikiquote, a free and collaboratively created collection of quotes in many languages, and aligns different mentions of the same quote. QuoteKG includes nearly one million quotes in $55$ languages, said by more than $69,000$ people of public interest across a wide range of topics. QuoteKG is publicly available and can be accessed via a SPARQL endpoint.
UNER: Universal Named-Entity RecognitionFramework
Oct 23, 2020


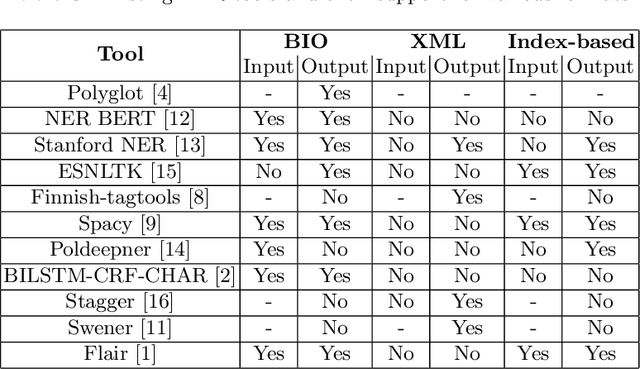
We introduce the Universal Named-Entity Recognition (UNER)framework, a 4-level classification hierarchy, and the methodology that isbeing adopted to create the first multilingual UNER corpus: the SETimesparallel corpus annotated for named-entities. First, the English SETimescorpus will be annotated using existing tools and knowledge bases. Afterevaluating the resulting annotations through crowdsourcing campaigns,they will be propagated automatically to other languages within the SE-Times corpora. Finally, as an extrinsic evaluation, the UNER multilin-gual dataset will be used to train and test available NER tools. As part offuture research directions, we aim to increase the number of languages inthe UNER corpus and to investigate possible ways of integrating UNERwith available knowledge graphs to improve named-entity recognition.