 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FedMAE: Federated Self-Supervised Learning with One-Block Masked Auto-Encoder
Mar 20, 2023

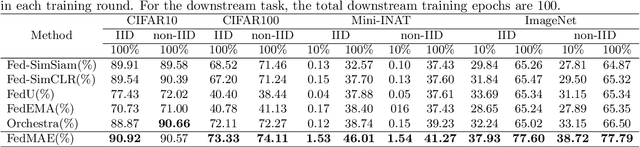
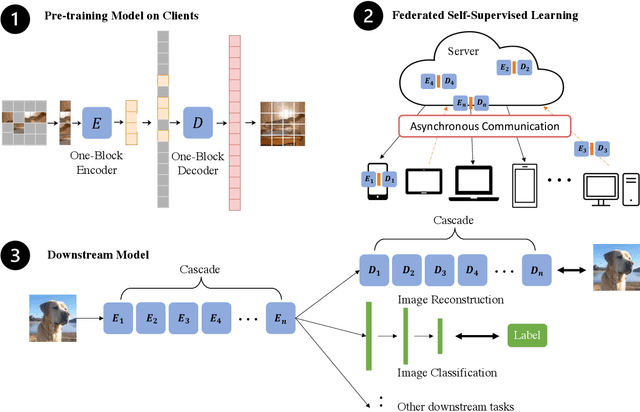

Latest federated learning (FL) methods started to focus on how to use unlabeled data in clients for training due to users' privacy concerns, high labeling costs, or lack of expertise. However, current Federated Semi-Supervised/Self-Supervised Learning (FSSL) approaches fail to learn large-scale images because of the limited computing resources of local clients. In this paper, we introduce a new framework FedMAE, which stands for Federated Masked AutoEncoder, to address the problem of how to utilize unlabeled large-scale images for FL. Specifically, FedMAE can pre-train one-block Masked AutoEncoder (MAE) using large images in lightweight client devices, and then cascades multiple pre-trained one-block MAEs in the server to build a multi-block ViT backbone for downstream tasks. Theoretical analysis and experimental results on image reconstruction and classification show that our FedMAE achieves superior performance compared to the state-of-the-art FSSL methods.
EMC2-Net: Joint Equalization and Modulation Classification based on Constellation Network
Mar 20, 2023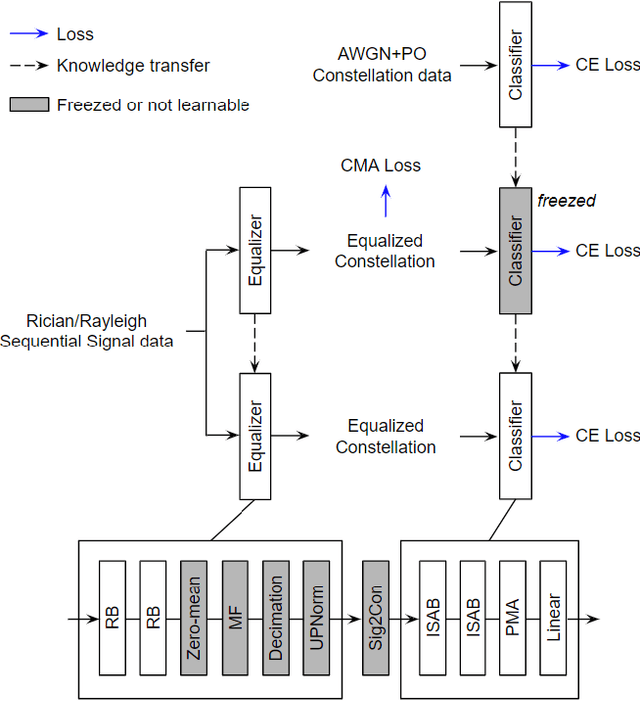
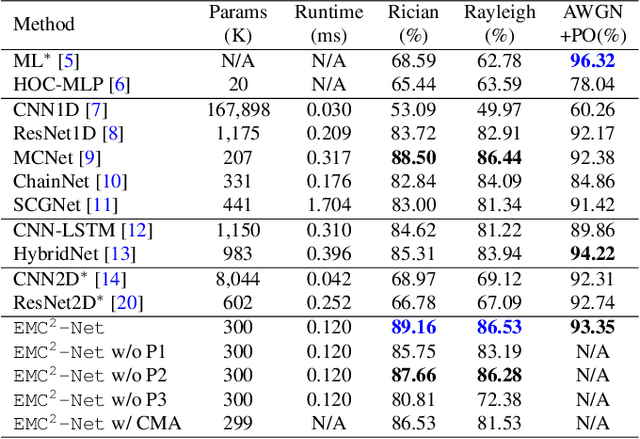
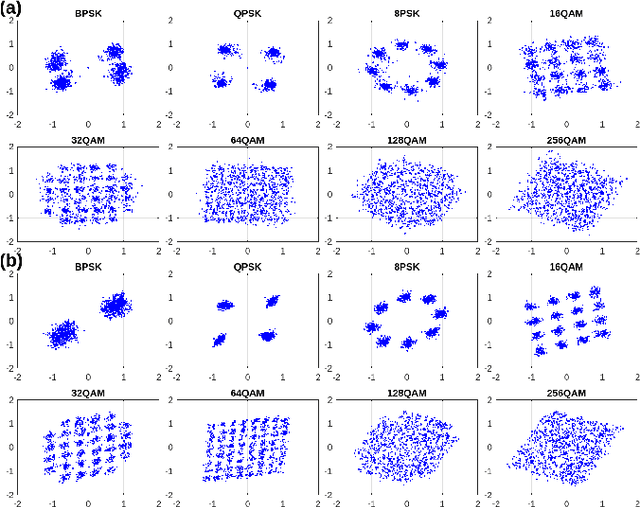
Modulation classification (MC) is the first step performed at the receiver side unless the modulation type is explicitly indicated by the transmitter. Machine learning techniques have been widely used for MC recently. In this paper, we propose a novel MC technique dubbed as Joint Equalization and Modulation Classification based on Constellation Network (EMC2-Net). Unlike prior works that considered the constellation points as an image, the proposed EMC2-Net directly uses a set of 2D constellation points to perform MC. In order to obtain clear and concrete constellation despite multipath fading channels, the proposed EMC2-Net consists of equalizer and classifier having separate and explainable roles via novel three-phase training and noise-curriculum pretraining. Numerical results with linear modulation types under different channel models show that the proposed EMC2-Net achieves the performance of state-of-the-art MC techniques with significantly less complexity.
Vision Transformer-based Feature Extraction for Generalized Zero-Shot Learning
Feb 02, 2023
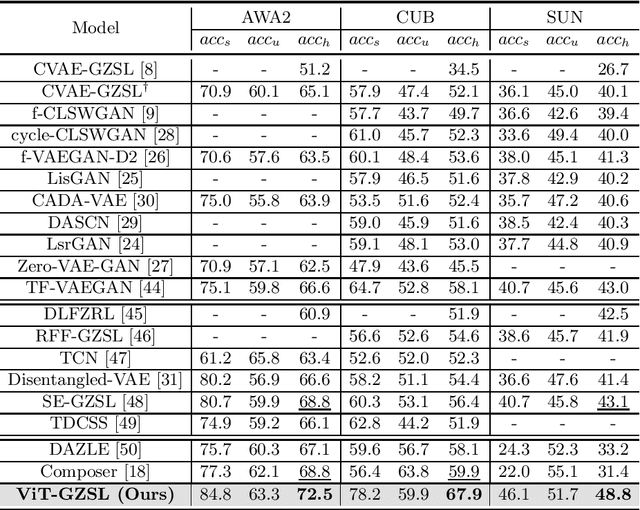
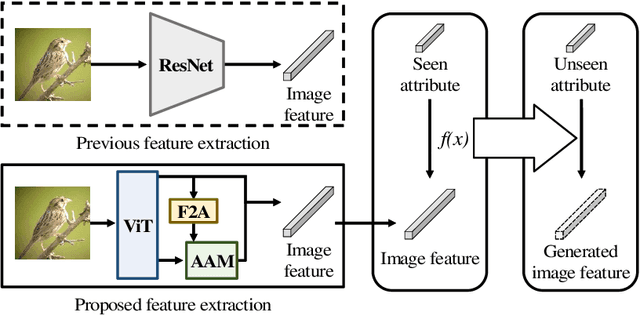

Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the image attribute. In this paper, we put forth a new GZSL approach exploiting Vision Transformer (ViT) to maximize the attribute-related information contained in the image feature. In ViT, the entire image region is processed without the degradation of the image resolution and the local image information is preserved in patch features. To fully enjoy these benefits of ViT, we exploit patch features as well as the CLS feature in extracting the attribute-related image feature. In particular, we propose a novel attention-based module, called attribute attention module (AAM), to aggregate the attribute-related information in patch features. In AAM, the correlation between each patch feature and the synthetic image attribute is used as the importance weight for each patch. From extensive experiments on benchmark datasets, we demonstrate that the proposed technique outperforms the state-of-the-art GZSL approaches by a large margin.
Lidar Line Selection with Spatially-Aware Shapley Value for Cost-Efficient Depth Completion
Mar 21, 2023

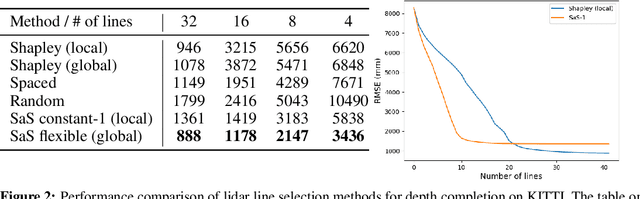
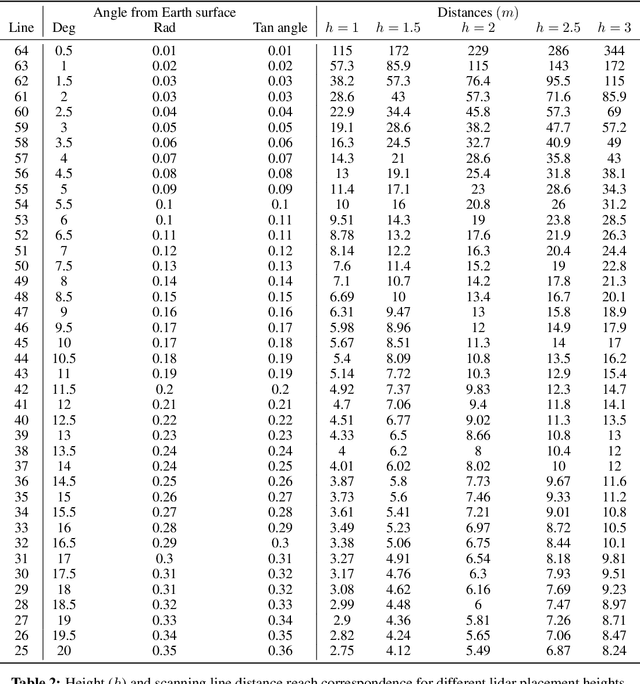
Lidar is a vital sensor for estimating the depth of a scene. Typical spinning lidars emit pulses arranged in several horizontal lines and the monetary cost of the sensor increases with the number of these lines. In this work, we present the new problem of optimizing the positioning of lidar lines to find the most effective configuration for the depth completion task. We propose a solution to reduce the number of lines while retaining the up-to-the-mark quality of depth completion. Our method consists of two components, (1) line selection based on the marginal contribution of a line computed via the Shapley value and (2) incorporating line position spread to take into account its need to arrive at image-wide depth completion. Spatially-aware Shapley values (SaS) succeed in selecting line subsets that yield a depth accuracy comparable to the full lidar input while using just half of the lines.
Explainable Image Quality Assessments in Teledermatological Photography
Sep 10, 2022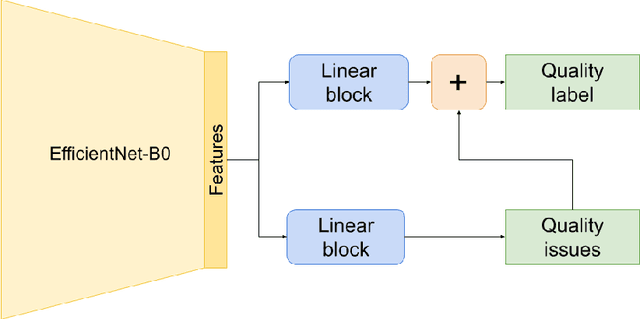
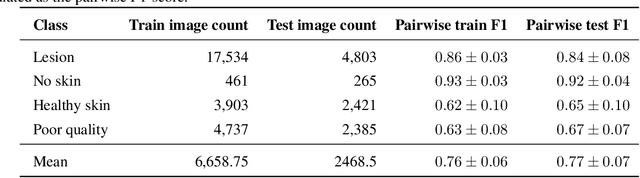
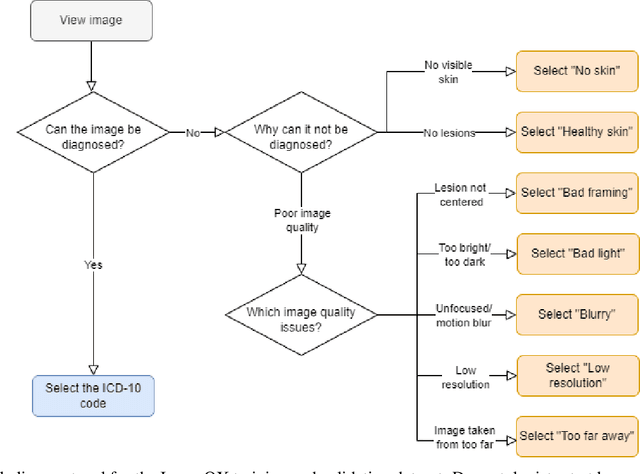
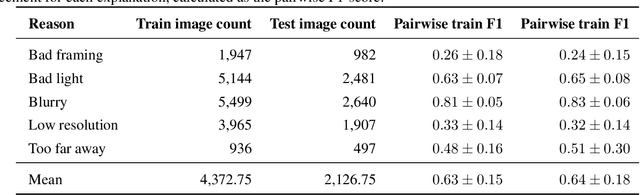
Image quality is a crucial factor in the success of teledermatological consultations. However, up to 50% of images sent by patients have quality issues, thus increasing the time to diagnosis and treatment. An automated, easily deployable, explainable method for assessing image quality is necessary to improve the current teledermatological consultation flow. We introduce ImageQX, a convolutional neural network trained for image quality assessment with a learning mechanism for identifying the most common poor image quality explanations: bad framing, bad lighting, blur, low resolution, and distance issues. ImageQX was trained on 26635 photographs and validated on 9874 photographs, each annotated with image quality labels and poor image quality explanations by up to 12 board-certified dermatologists. The photographic images were taken between 2017-2019 using a mobile skin disease tracking application accessible worldwide. Our method achieves expert-level performance for both image quality assessment and poor image quality explanation. For image quality assessment, ImageQX obtains a macro F1-score of 0.73 which places it within standard deviation of the pairwise inter-rater F1-score of 0.77. For poor image quality explanations, our method obtains F1-scores of between 0.37 and 0.70, similar to the inter-rater pairwise F1-score of between 0.24 and 0.83. Moreover, with a size of only 15 MB, ImageQX is easily deployable on mobile devices. With an image quality detection performance similar to that of dermatologists, incorporating ImageQX into the teledermatology flow can reduce the image evaluation burden on dermatologists, while at the same time reducing the time to diagnosis and treatment for patients. We introduce ImageQX, a first of its kind explainable image quality assessor which leverages domain expertise to improve the quality and efficiency of dermatological care in a virtual setting.
Graph Reasoning Transformer for Image Parsing
Sep 20, 2022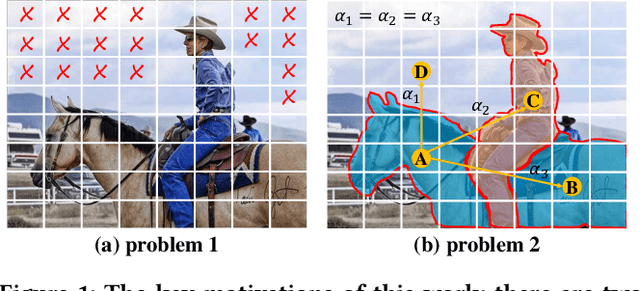
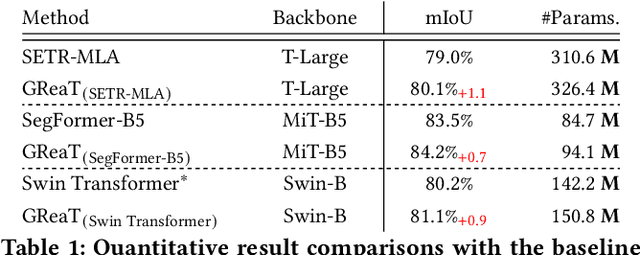
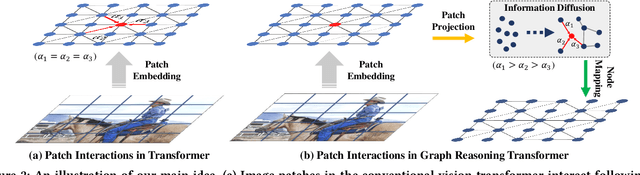
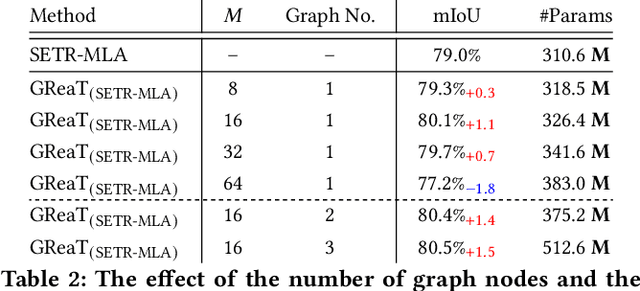
Capturing the long-range dependencies has empirically proven to be effective on a wide range of computer vision tasks. The progressive advances on this topic have been made through the employment of the transformer framework with the help of the multi-head attention mechanism. However, the attention-based image patch interaction potentially suffers from problems of redundant interactions of intra-class patches and unoriented interactions of inter-class patches. In this paper, we propose a novel Graph Reasoning Transformer (GReaT) for image parsing to enable image patches to interact following a relation reasoning pattern. Specifically, the linearly embedded image patches are first projected into the graph space, where each node represents the implicit visual center for a cluster of image patches and each edge reflects the relation weight between two adjacent nodes. After that, global relation reasoning is performed on this graph accordingly. Finally, all nodes including the relation information are mapped back into the original space for subsequent processes. Compared to the conventional transformer, GReaT has higher interaction efficiency and a more purposeful interaction pattern. Experiments are carried out on the challenging Cityscapes and ADE20K datasets. Results show that GReaT achieves consistent performance gains with slight computational overheads on the state-of-the-art transformer baselines.
Continuous Indeterminate Probability Neural Network
Mar 23, 2023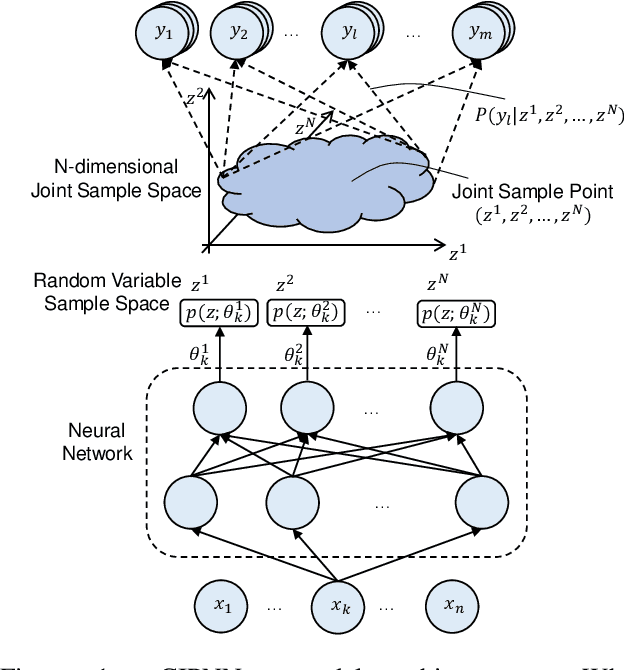
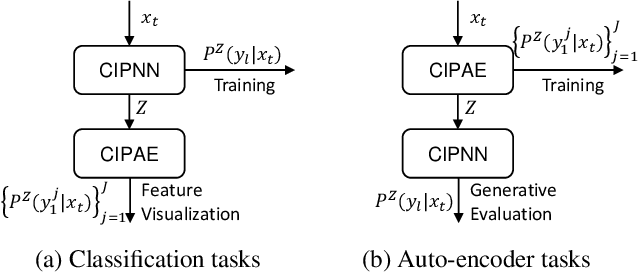


This paper introduces a general model called CIPNN - Continuous Indeterminate Probability Neural Network, and this model is based on IPNN, which is used for discrete latent random variables. Currently, posterior of continuous latent variables is regarded as intractable, with the new theory proposed by IPNN this problem can be solved. Our contributions are Four-fold. First, we derive the analytical solution of the posterior calculation of continuous latent random variables and propose a general classification model (CIPNN). Second, we propose a general auto-encoder called CIPAE - Continuous Indeterminate Probability Auto-Encoder, the decoder part is not a neural network and uses a fully probabilistic inference model for the first time. Third, we propose a new method to visualize the latent random variables, we use one of N dimensional latent variables as a decoder to reconstruct the input image, which can work even for classification tasks, in this way, we can see what each latent variable has learned. Fourth, IPNN has shown great classification capability, CIPNN has pushed this classification capability to infinity. Theoretical advantages are reflected in experimental results.
Generative Modeling with Flow-Guided Density Ratio Learning
Mar 07, 2023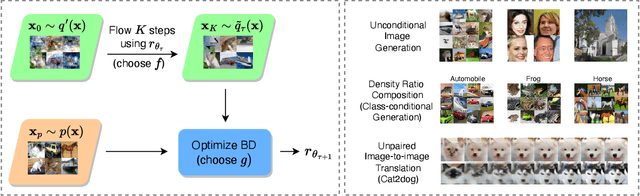

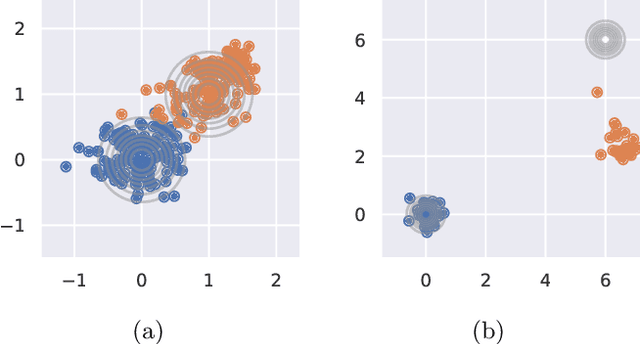
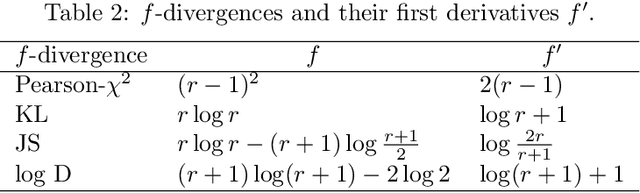
We present Flow-Guided Density Ratio Learning (FDRL), a simple and scalable approach to generative modeling which builds on the stale (time-independent) approximation of the gradient flow of entropy-regularized f-divergences introduced in DGflow. In DGflow, the intractable time-dependent density ratio is approximated by a stale estimator given by a GAN discriminator. This is sufficient in the case of sample refinement, where the source and target distributions of the flow are close to each other. However, this assumption is invalid for generation and a naive application of the stale estimator fails due to the large chasm between the two distributions. FDRL proposes to train a density ratio estimator such that it learns from progressively improving samples during the training process. We show that this simple method alleviates the density chasm problem, allowing FDRL to generate images of dimensions as high as $128\times128$, as well as outperform existing gradient flow baselines on quantitative benchmarks. We also show the flexibility of FDRL with two use cases. First, unconditional FDRL can be easily composed with external classifiers to perform class-conditional generation. Second, FDRL can be directly applied to unpaired image-to-image translation with no modifications needed to the framework. Code is publicly available at https://github.com/ajrheng/FDRL.
Pose Guided Human Image Synthesis with Partially Decoupled GAN
Oct 07, 2022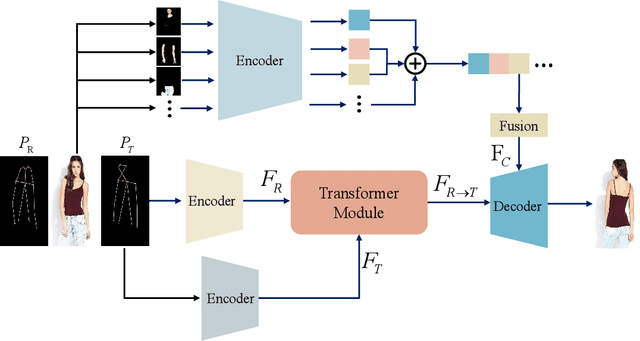
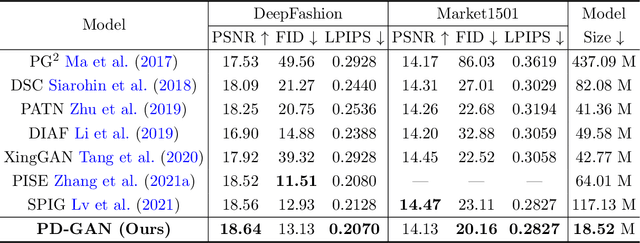
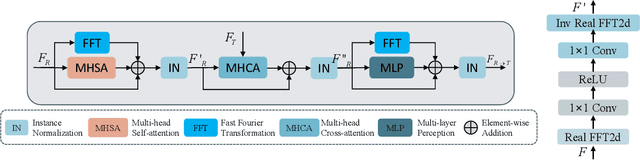

Pose Guided Human Image Synthesis (PGHIS) is a challenging task of transforming a human image from the reference pose to a target pose while preserving its style. Most existing methods encode the texture of the whole reference human image into a latent space, and then utilize a decoder to synthesize the image texture of the target pose. However, it is difficult to recover the detailed texture of the whole human image. To alleviate this problem, we propose a method by decoupling the human body into several parts (\eg, hair, face, hands, feet, \etc) and then using each of these parts to guide the synthesis of a realistic image of the person, which preserves the detailed information of the generated images. In addition, we design a multi-head attention-based module for PGHIS. Because most convolutional neural network-based methods have difficulty in modeling long-range dependency due to the convolutional operation, the long-range modeling capability of attention mechanism is more suitable than convolutional neural networks for pose transfer task, especially for sharp pose deformation. Extensive experiments on Market-1501 and DeepFashion datasets reveal that our method almost outperforms other existing state-of-the-art methods in terms of both qualitative and quantitative metrics.
Adding Conditional Control to Text-to-Image Diffusion Models
Feb 10, 2023
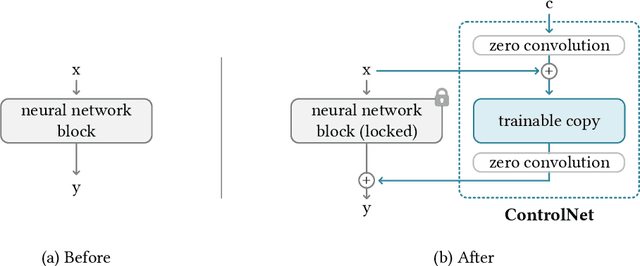
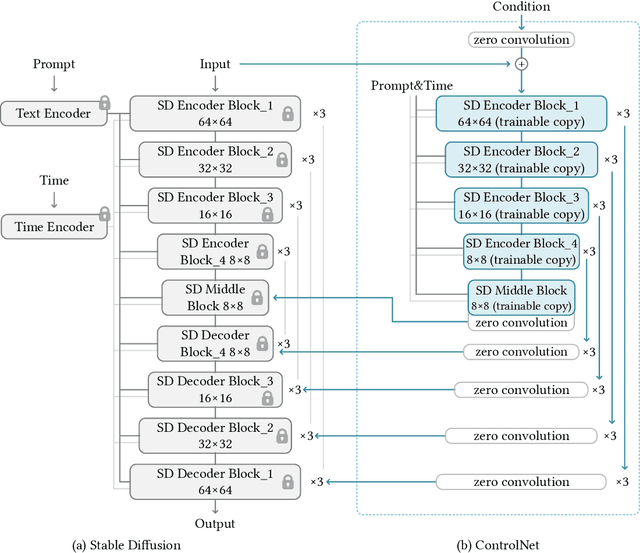

We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.