 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discovering Class-Specific GAN Controls for Semantic Image Synthesis
Dec 02, 2022
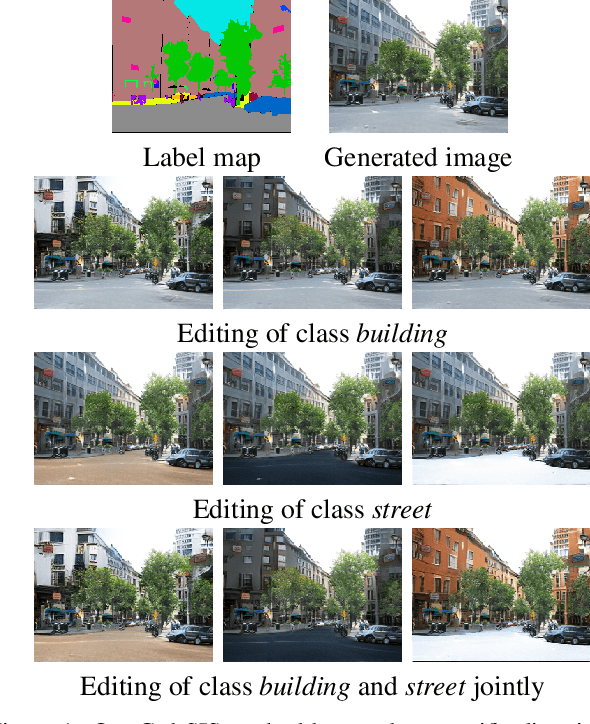

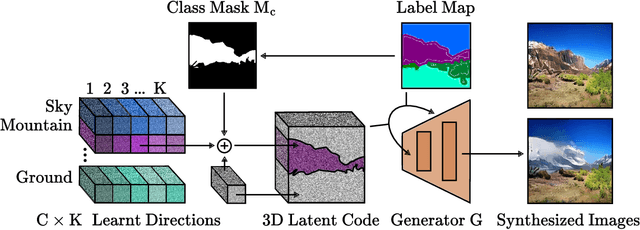
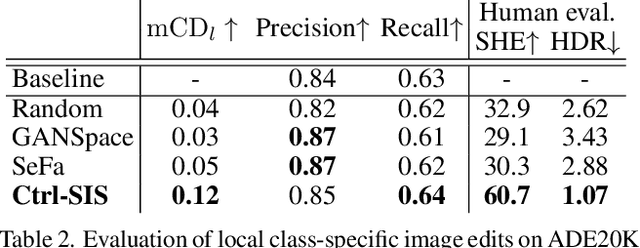
Prior work has extensively studied the latent space structure of GANs for unconditional image synthesis, enabling global editing of generated images by the unsupervised discovery of interpretable latent directions. However, the discovery of latent directions for conditional GANs for semantic image synthesis (SIS) has remained unexplored. In this work, we specifically focus on addressing this gap. We propose a novel optimization method for finding spatially disentangled class-specific directions in the latent space of pretrained SIS models. We show that the latent directions found by our method can effectively control the local appearance of semantic classes, e.g., changing their internal structure, texture or color independently from each other. Visual inspection and quantitative evaluation of the discovered GAN controls on various datasets demonstrate that our method discovers a diverse set of unique and semantically meaningful latent directions for class-specific edits.
DeAR: Debiasing Vision-Language Models with Additive Residuals
Mar 18, 2023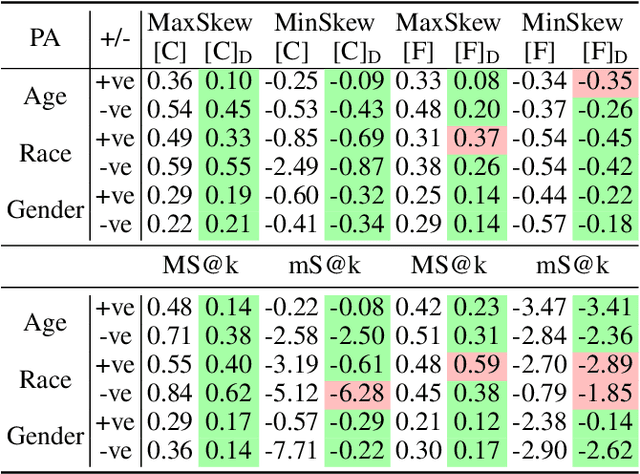
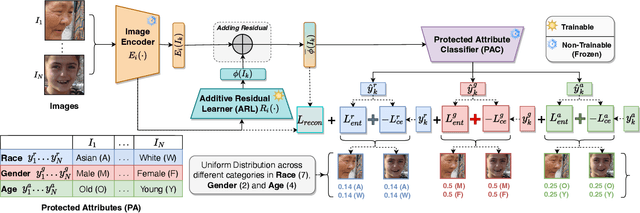
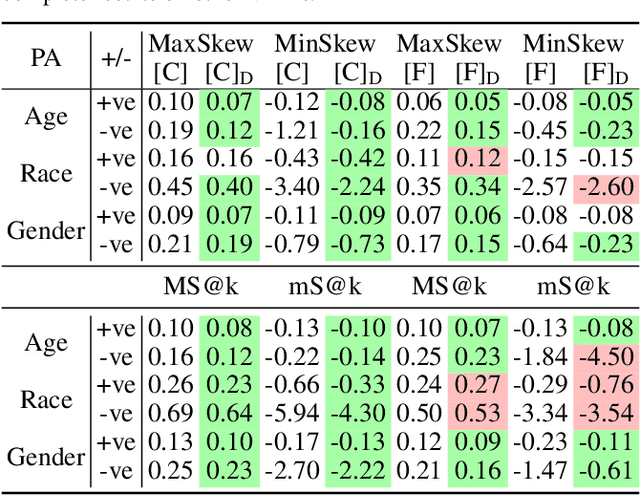
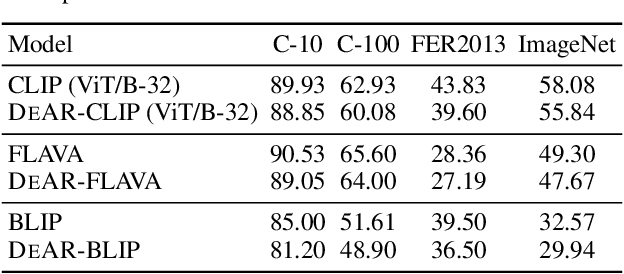
Large pre-trained vision-language models (VLMs) reduce the time for developing predictive models for various vision-grounded language downstream tasks by providing rich, adaptable image and text representations. However, these models suffer from societal biases owing to the skewed distribution of various identity groups in the training data. These biases manifest as the skewed similarity between the representations for specific text concepts and images of people of different identity groups and, therefore, limit the usefulness of such models in real-world high-stakes applications. In this work, we present DeAR (Debiasing with Additive Residuals), a novel debiasing method that learns additive residual image representations to offset the original representations, ensuring fair output representations. In doing so, it reduces the ability of the representations to distinguish between the different identity groups. Further, we observe that the current fairness tests are performed on limited face image datasets that fail to indicate why a specific text concept should/should not apply to them. To bridge this gap and better evaluate DeAR, we introduce the Protected Attribute Tag Association (PATA) dataset - a new context-based bias benchmarking dataset for evaluating the fairness of large pre-trained VLMs. Additionally, PATA provides visual context for a diverse human population in different scenarios with both positive and negative connotations. Experimental results for fairness and zero-shot performance preservation using multiple datasets demonstrate the efficacy of our framework.
Towards Tumour Graph Learning for Survival Prediction in Head & Neck Cancer Patients
Apr 17, 2023With nearly one million new cases diagnosed worldwide in 2020, head \& neck cancer is a deadly and common malignity. There are challenges to decision making and treatment of such cancer, due to lesions in multiple locations and outcome variability between patients. Therefore, automated segmentation and prognosis estimation approaches can help ensure each patient gets the most effective treatment. This paper presents a framework to perform these functions on arbitrary field of view (FoV) PET and CT registered scans, thus approaching tasks 1 and 2 of the HECKTOR 2022 challenge as team \texttt{VokCow}. The method consists of three stages: localization, segmentation and survival prediction. First, the scans with arbitrary FoV are cropped to the head and neck region and a u-shaped convolutional neural network (CNN) is trained to segment the region of interest. Then, using the obtained regions, another CNN is combined with a support vector machine classifier to obtain the semantic segmentation of the tumours, which results in an aggregated Dice score of 0.57 in task 1. Finally, survival prediction is approached with an ensemble of Weibull accelerated failure times model and deep learning methods. In addition to patient health record data, we explore whether processing graphs of image patches centred at the tumours via graph convolutions can improve the prognostic predictions. A concordance index of 0.64 was achieved in the test set, ranking 6th in the challenge leaderboard for this task.
Learning How To Robustly Estimate Camera Pose in Endoscopic Videos
Apr 17, 2023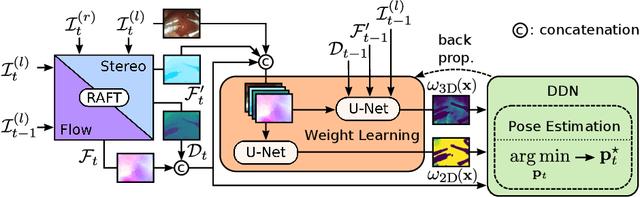

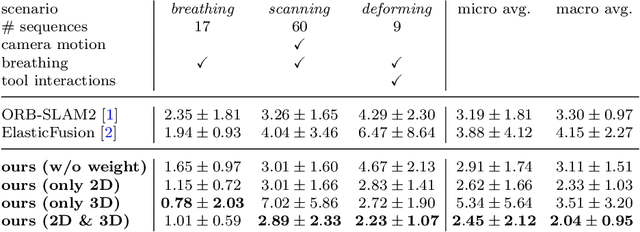
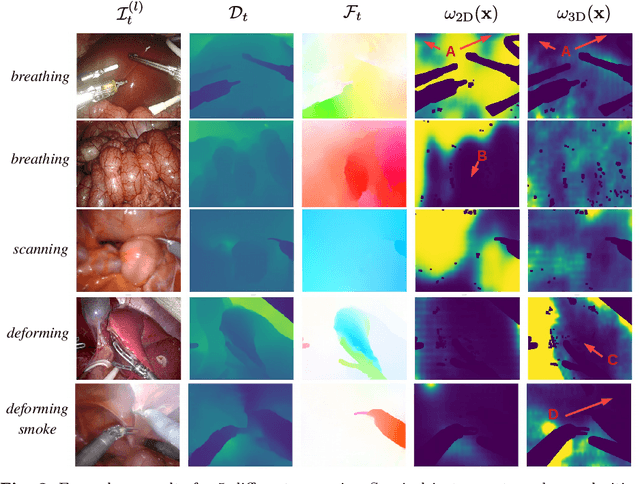
Purpose: Surgical scene understanding plays a critical role in the technology stack of tomorrow's intervention-assisting systems in endoscopic surgeries. For this, tracking the endoscope pose is a key component, but remains challenging due to illumination conditions, deforming tissues and the breathing motion of organs. Method: We propose a solution for stereo endoscopes that estimates depth and optical flow to minimize two geometric losses for camera pose estimation. Most importantly, we introduce two learned adaptive per-pixel weight mappings that balance contributions according to the input image content. To do so, we train a Deep Declarative Network to take advantage of the expressiveness of deep-learning and the robustness of a novel geometric-based optimization approach. We validate our approach on the publicly available SCARED dataset and introduce a new in-vivo dataset, StereoMIS, which includes a wider spectrum of typically observed surgical settings. Results: Our method outperforms state-of-the-art methods on average and more importantly, in difficult scenarios where tissue deformations and breathing motion are visible. We observed that our proposed weight mappings attenuate the contribution of pixels on ambiguous regions of the images, such as deforming tissues. Conclusion: We demonstrate the effectiveness of our solution to robustly estimate the camera pose in challenging endoscopic surgical scenes. Our contributions can be used to improve related tasks like simultaneous localization and mapping (SLAM) or 3D reconstruction, therefore advancing surgical scene understanding in minimally-invasive surgery.
Alzheimers Disease Diagnosis using Machine Learning: A Review
Apr 17, 2023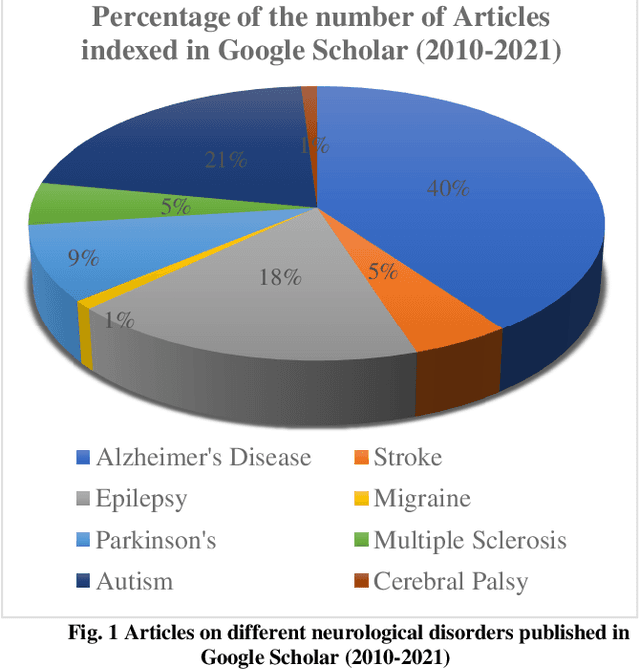
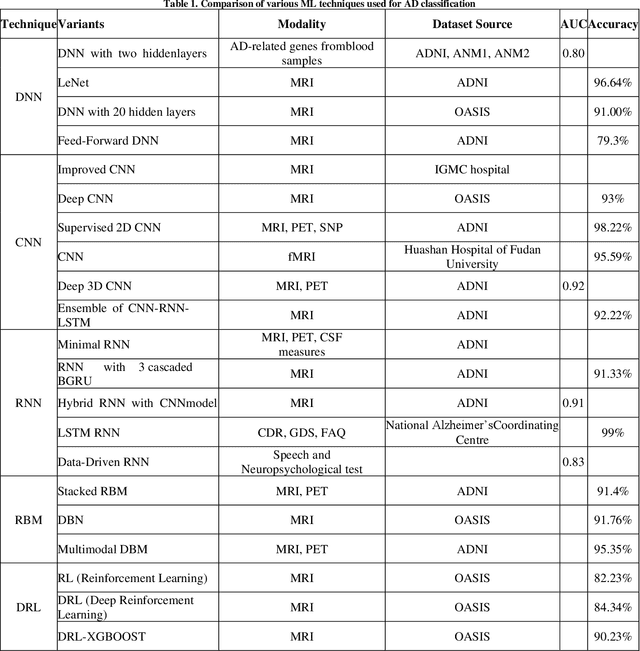
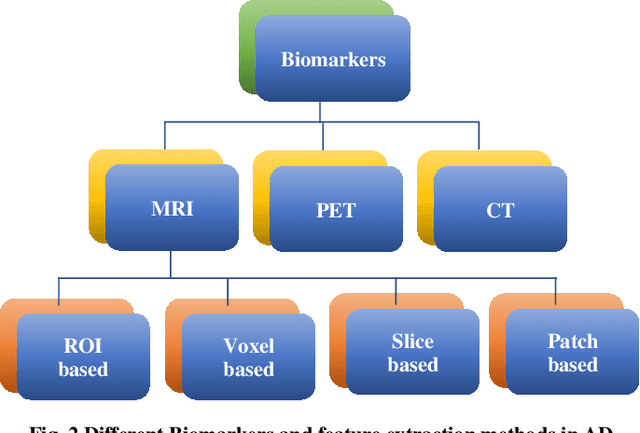
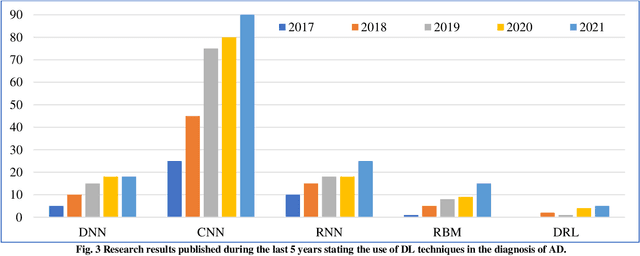
Alzheimers Disease AD is an acute neuro disease that degenerates the brain cells and thus leads to memory loss progressively. It is a fatal brain disease that mostly affects the elderly. It steers the decline of cognitive and biological functions of the brain and shrinks the brain successively, which in turn is known as Atrophy. For an accurate diagnosis of Alzheimers disease, cutting edge methods like machine learning are essential. Recently, machine learning has gained a lot of attention and popularity in the medical industry. As the illness progresses, those with Alzheimers have a far more difficult time doing even the most basic tasks, and in the worst case, their brain completely stops functioning. A persons likelihood of having early-stage Alzheimers disease may be determined using the ML method. In this analysis, papers on Alzheimers disease diagnosis based on deep learning techniques and reinforcement learning between 2008 and 2023 found in google scholar were studied. Sixty relevant papers obtained after the search was considered for this study. These papers were analysed based on the biomarkers of AD and the machine-learning techniques used. The analysis shows that deep learning methods have an immense ability to extract features and classify AD with good accuracy. The DRL methods have not been used much in the field of image processing. The comparison results of deep learning and reinforcement learning illustrate that the scope of Deep Reinforcement Learning DRL in dementia detection needs to be explored.
* 10 pages and 3 figures
Optimizing Prompts for Text-to-Image Generation
Dec 19, 2022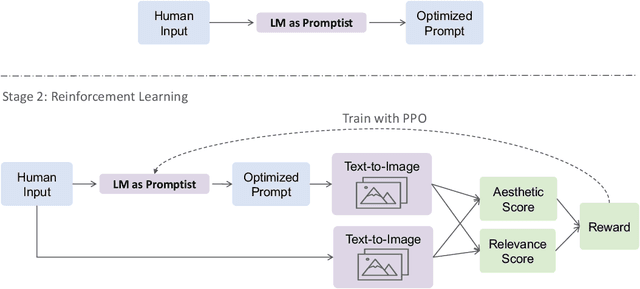
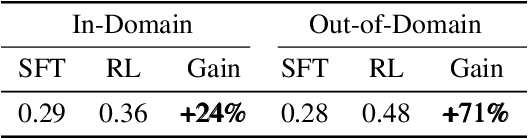
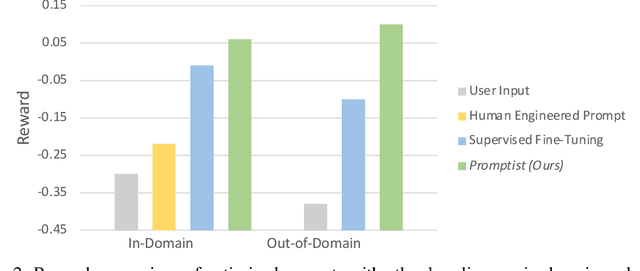

Well-designed prompts can guide text-to-image models to generate amazing images. However, the performant prompts are often model-specific and misaligned with user input. Instead of laborious human engineering, we propose prompt adaptation, a general framework that automatically adapts original user input to model-preferred prompts. Specifically, we first perform supervised fine-tuning with a pretrained language model on a small collection of manually engineered prompts. Then we use reinforcement learning to explore better prompts. We define a reward function that encourages the policy to generate more aesthetically pleasing images while preserving the original user intentions. Experimental results on Stable Diffusion show that our method outperforms manual prompt engineering in terms of both automatic metrics and human preference ratings. Moreover, reinforcement learning further boosts performance, especially on out-of-domain prompts. The pretrained checkpoints are available at https://aka.ms/promptist. The demo can be found at https://aka.ms/promptist-demo.
Training End-to-End Unrolled Iterative Neural Networks for SPECT Image Reconstruction
Jan 23, 2023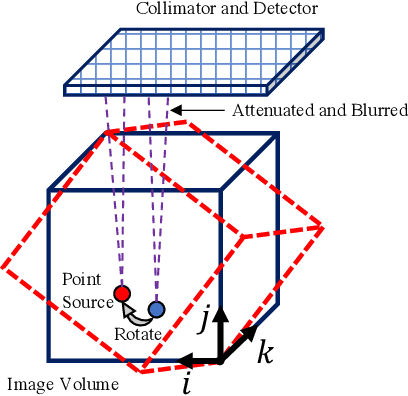
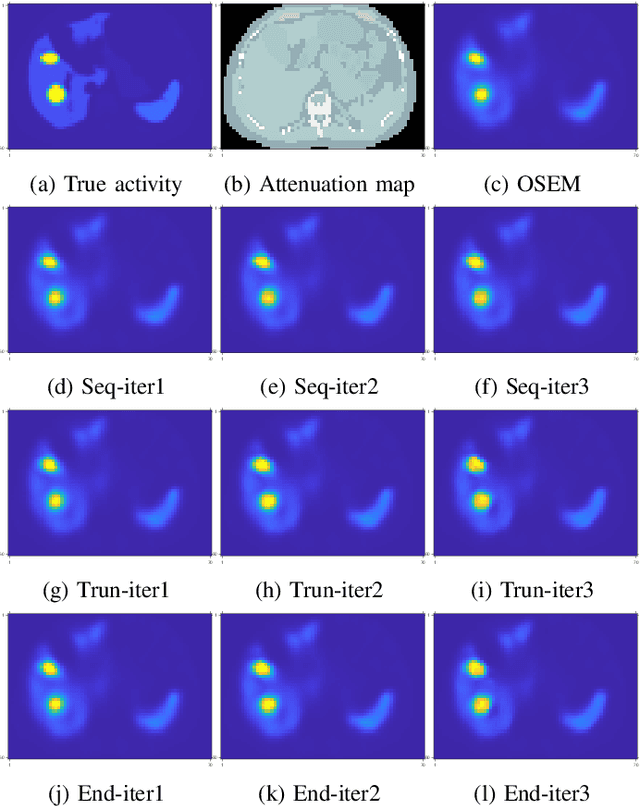
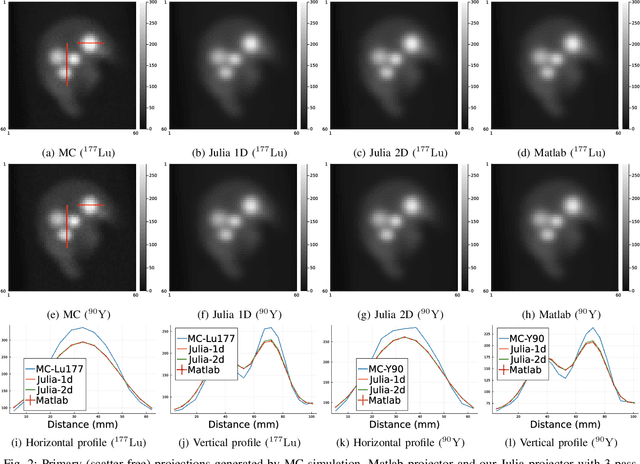
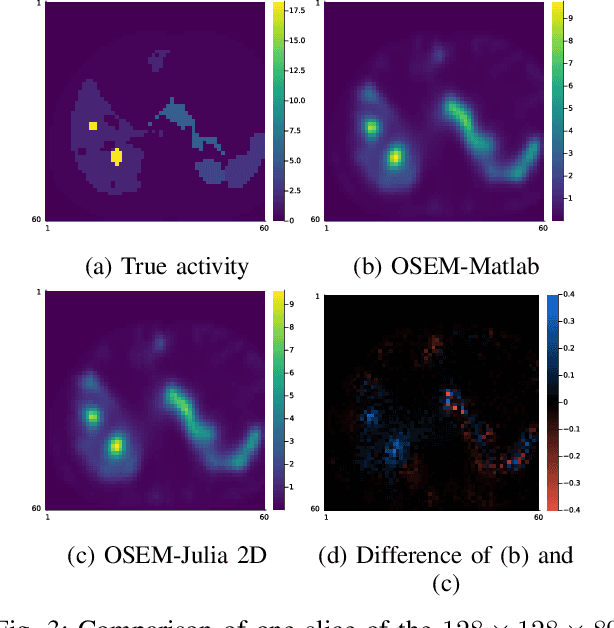
Training end-to-end unrolled iterative neural networks for SPECT image reconstruction requires a memory-efficient forward-backward projector for efficient backpropagation. This paper describes an open-source, high performance Julia implementation of a SPECT forward-backward projector that supports memory-efficient backpropagation with an exact adjoint. Our Julia projector uses only ~5% of the memory of an existing Matlab-based projector. We compare unrolling a CNN-regularized expectation-maximization (EM) algorithm with end-to-end training using our Julia projector with other training methods such as gradient truncation (ignoring gradients involving the projector) and sequential training, using XCAT phantoms and virtual patient (VP) phantoms generated from SIMIND Monte Carlo (MC) simulations. Simulation results with two different radionuclides (90Y and 177Lu) show that: 1) For 177Lu XCAT phantoms and 90Y VP phantoms, training unrolled EM algorithm in end-to-end fashion with our Julia projector yields the best reconstruction quality compared to other training methods and OSEM, both qualitatively and quantitatively. For VP phantoms with 177Lu radionuclide, the reconstructed images using end-to-end training are in higher quality than using sequential training and OSEM, but are comparable with using gradient truncation. We also find there exists a trade-off between computational cost and reconstruction accuracy for different training methods. End-to-end training has the highest accuracy because the correct gradient is used in backpropagation; sequential training yields worse reconstruction accuracy, but is significantly faster and uses much less memory.
Real-Time Helmet Violation Detection Using YOLOv5 and Ensemble Learning
Apr 14, 2023
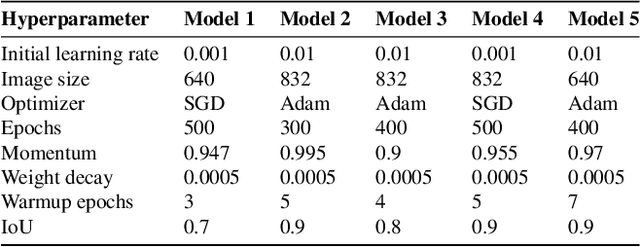


The proper enforcement of motorcycle helmet regulations is crucial for ensuring the safety of motorbike passengers and riders, as roadway cyclists and passengers are not likely to abide by these regulations if no proper enforcement systems are instituted. This paper presents the development and evaluation of a real-time YOLOv5 Deep Learning (DL) model for detecting riders and passengers on motorbikes, identifying whether the detected person is wearing a helmet. We trained the model on 100 videos recorded at 10 fps, each for 20 seconds. Our study demonstrated the applicability of DL models to accurately detect helmet regulation violators even in challenging lighting and weather conditions. We employed several data augmentation techniques in the study to ensure the training data is diverse enough to help build a robust model. The proposed model was tested on 100 test videos and produced an mAP score of 0.5267, ranking 11th on the AI City Track 5 public leaderboard. The use of deep learning techniques for image classification tasks, such as identifying helmet-wearing riders, has enormous potential for improving road safety. The study shows the potential of deep learning models for application in smart cities and enforcing traffic regulations and can be deployed in real-time for city-wide monitoring.
Personalized Federated Learning with Local Attention
Apr 14, 2023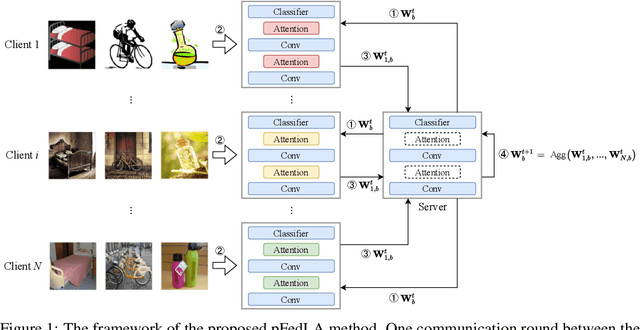
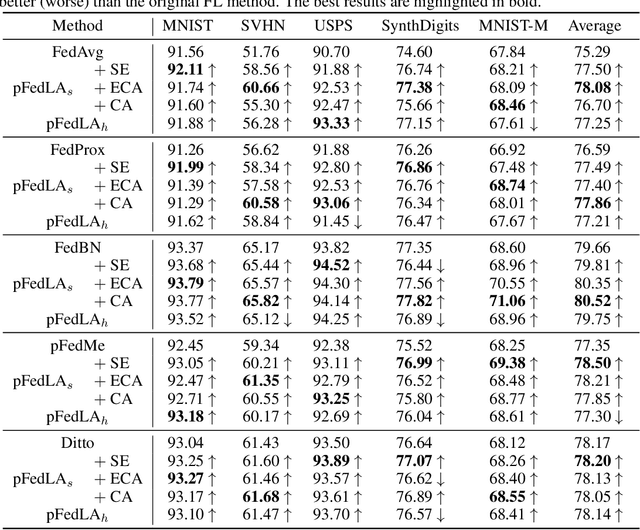
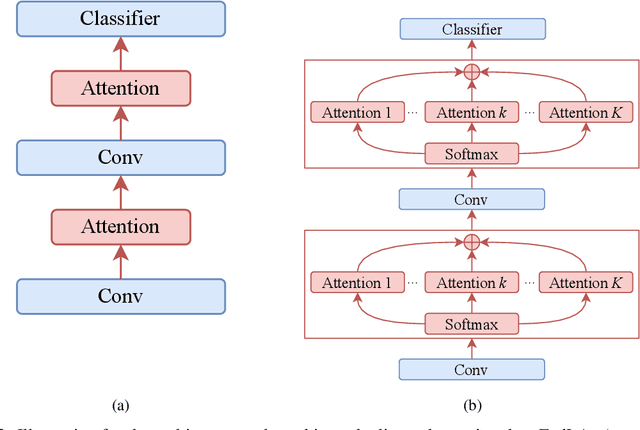
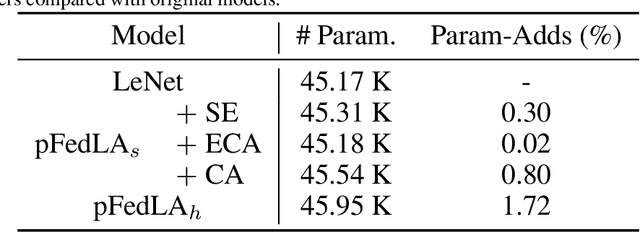
Federated Learning (FL) aims to learn a single global model that enables the central server to help the model training in local clients without accessing their local data. The key challenge of FL is the heterogeneity of local data in different clients, such as heterogeneous label distribution and feature shift, which could lead to significant performance degradation of the learned models. Although many studies have been proposed to address the heterogeneous label distribution problem, few studies attempt to explore the feature shift issue. To address this issue, we propose a simple yet effective algorithm, namely \textbf{p}ersonalized \textbf{Fed}erated learning with \textbf{L}ocal \textbf{A}ttention (pFedLA), by incorporating the attention mechanism into personalized models of clients while keeping the attention blocks client-specific. Specifically, two modules are proposed in pFedLA, i.e., the personalized single attention module and the personalized hybrid attention module. In addition, the proposed pFedLA method is quite flexible and general as it can be incorporated into any FL method to improve their performance without introducing additional communication costs. Extensive experiments demonstrate that the proposed pFedLA method can boost the performance of state-of-the-art FL methods on different tasks such as image classification and object detection tasks.
CoMaL: Conditional Maximum Likelihood Approach to Self-supervised Domain Adaptation in Long-tail Semantic Segmentation
Apr 14, 2023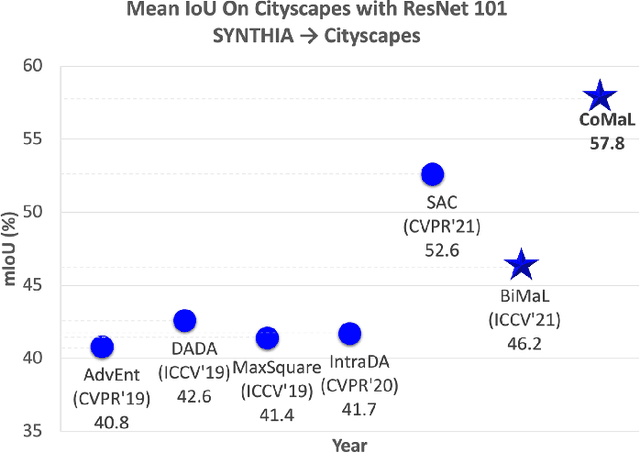
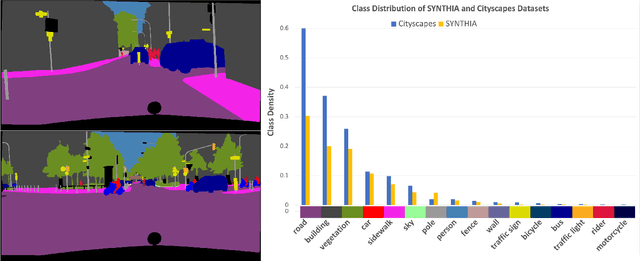

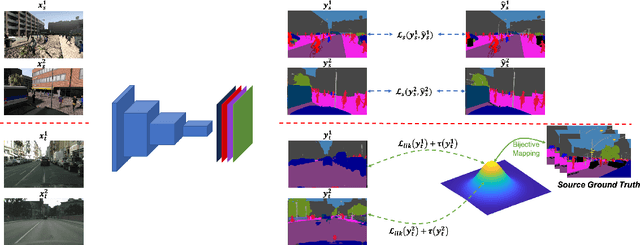
The research in self-supervised domain adaptation in semantic segmentation has recently received considerable attention. Although GAN-based methods have become one of the most popular approaches to domain adaptation, they have suffered from some limitations. They are insufficient to model both global and local structures of a given image, especially in small regions of tail classes. Moreover, they perform bad on the tail classes containing limited number of pixels or less training samples. In order to address these issues, we present a new self-supervised domain adaptation approach to tackle long-tail semantic segmentation in this paper. Firstly, a new metric is introduced to formulate long-tail domain adaptation in the segmentation problem. Secondly, a new Conditional Maximum Likelihood (CoMaL) approach in an autoregressive framework is presented to solve the problem of long-tail domain adaptation. Although other segmentation methods work under the pixel independence assumption, the long-tailed pixel distributions in CoMaL are generally solved in the context of structural dependency, as that is more realistic. Finally, the proposed method is evaluated on popular large-scale semantic segmentation benchmarks, i.e., "SYNTHIA to Cityscapes" and "GTA to Cityscapes", and outperforms the prior methods by a large margin in both the standard and the proposed evaluation protocols.