 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROVIA: Seeing Drone Scenes from Car Perspective via Cross-View Adaptation
Apr 14, 2023



Understanding semantic scene segmentation of urban scenes captured from the Unmanned Aerial Vehicles (UAV) perspective plays a vital role in building a perception model for UAV. With the limitations of large-scale densely labeled data, semantic scene segmentation for UAV views requires a broad understanding of an object from both its top and side views. Adapting from well-annotated autonomous driving data to unlabeled UAV data is challenging due to the cross-view differences between the two data types. Our work proposes a novel Cross-View Adaptation (CROVIA) approach to effectively adapt the knowledge learned from on-road vehicle views to UAV views. First, a novel geometry-based constraint to cross-view adaptation is introduced based on the geometry correlation between views. Second, cross-view correlations from image space are effectively transferred to segmentation space without any requirement of paired on-road and UAV view data via a new Geometry-Constraint Cross-View (GeiCo) loss. Third, the multi-modal bijective networks are introduced to enforce the global structural modeling across views. Experimental results on new cross-view adaptation benchmarks introduced in this work, i.e., SYNTHIA to UAVID and GTA5 to UAVID, show the State-of-the-Art (SOTA) performance of our approach over prior adaptation methods
Fairness in Visual Clustering: A Novel Transformer Clustering Approach
Apr 14, 2023



Promoting fairness for deep clustering models in unsupervised clustering settings to reduce demographic bias is a challenging goal. This is because of the limitation of large-scale balanced data with well-annotated labels for sensitive or protected attributes. In this paper, we first evaluate demographic bias in deep clustering models from the perspective of cluster purity, which is measured by the ratio of positive samples within a cluster to their correlation degree. This measurement is adopted as an indication of demographic bias. Then, a novel loss function is introduced to encourage a purity consistency for all clusters to maintain the fairness aspect of the learned clustering model. Moreover, we present a novel attention mechanism, Cross-attention, to measure correlations between multiple clusters, strengthening faraway positive samples and improving the purity of clusters during the learning process. Experimental results on a large-scale dataset with numerous attribute settings have demonstrated the effectiveness of the proposed approach on both clustering accuracy and fairness enhancement on several sensitive attributes.
CoMaL: Conditional Maximum Likelihood Approach to Self-supervised Domain Adaptation in Long-tail Semantic Segmentation
Apr 14, 2023



The research in self-supervised domain adaptation in semantic segmentation has recently received considerable attention. Although GAN-based methods have become one of the most popular approaches to domain adaptation, they have suffered from some limitations. They are insufficient to model both global and local structures of a given image, especially in small regions of tail classes. Moreover, they perform bad on the tail classes containing limited number of pixels or less training samples. In order to address these issues, we present a new self-supervised domain adaptation approach to tackle long-tail semantic segmentation in this paper. Firstly, a new metric is introduced to formulate long-tail domain adaptation in the segmentation problem. Secondly, a new Conditional Maximum Likelihood (CoMaL) approach in an autoregressive framework is presented to solve the problem of long-tail domain adaptation. Although other segmentation methods work under the pixel independence assumption, the long-tailed pixel distributions in CoMaL are generally solved in the context of structural dependency, as that is more realistic. Finally, the proposed method is evaluated on popular large-scale semantic segmentation benchmarks, i.e., "SYNTHIA to Cityscapes" and "GTA to Cityscapes", and outperforms the prior methods by a large margin in both the standard and the proposed evaluation protocols.
Micron-BERT: BERT-based Facial Micro-Expression Recognition
Apr 06, 2023



Micro-expression recognition is one of the most challenging topics in affective computing. It aims to recognize tiny facial movements difficult for humans to perceive in a brief period, i.e., 0.25 to 0.5 seconds. Recent advances in pre-training deep Bidirectional Transformers (BERT) have significantly improved self-supervised learning tasks in computer vision. However, the standard BERT in vision problems is designed to learn only from full images or videos, and the architecture cannot accurately detect details of facial micro-expressions. This paper presents Micron-BERT ($\mu$-BERT), a novel approach to facial micro-expression recognition. The proposed method can automatically capture these movements in an unsupervised manner based on two key ideas. First, we employ Diagonal Micro-Attention (DMA) to detect tiny differences between two frames. Second, we introduce a new Patch of Interest (PoI) module to localize and highlight micro-expression interest regions and simultaneously reduce noisy backgrounds and distractions. By incorporating these components into an end-to-end deep network, the proposed $\mu$-BERT significantly outperforms all previous work in various micro-expression tasks. $\mu$-BERT can be trained on a large-scale unlabeled dataset, i.e., up to 8 million images, and achieves high accuracy on new unseen facial micro-expression datasets. Empirical experiments show $\mu$-BERT consistently outperforms state-of-the-art performance on four micro-expression benchmarks, including SAMM, CASME II, SMIC, and CASME3, by significant margins. Code will be available at \url{https://github.com/uark-cviu/Micron-BERT}
Multi-Camera Multi-Object Tracking on the Move via Single-Stage Global Association Approach
Nov 17, 2022



The development of autonomous vehicles generates a tremendous demand for a low-cost solution with a complete set of camera sensors capturing the environment around the car. It is essential for object detection and tracking to address these new challenges in multi-camera settings. In order to address these challenges, this work introduces novel Single-Stage Global Association Tracking approaches to associate one or more detection from multi-cameras with tracked objects. These approaches aim to solve fragment-tracking issues caused by inconsistent 3D object detection. Moreover, our models also improve the detection accuracy of the standard vision-based 3D object detectors in the nuScenes detection challenge. The experimental results on the nuScenes dataset demonstrate the benefits of the proposed method by outperforming prior vision-based tracking methods in multi-camera settings.
Vec2Face-v2: Unveil Human Faces from their Blackbox Features via Attention-based Network in Face Recognition
Sep 11, 2022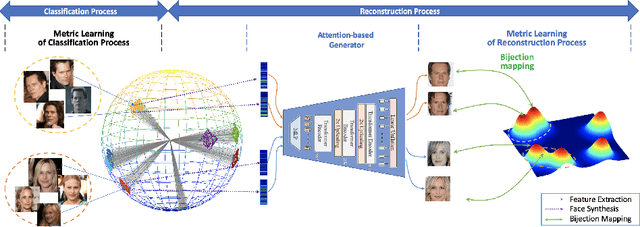

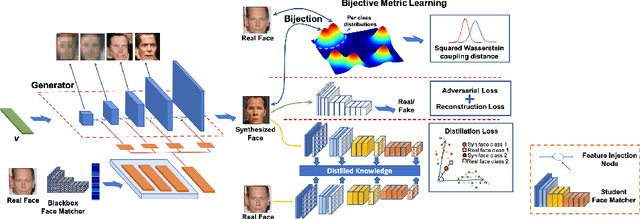
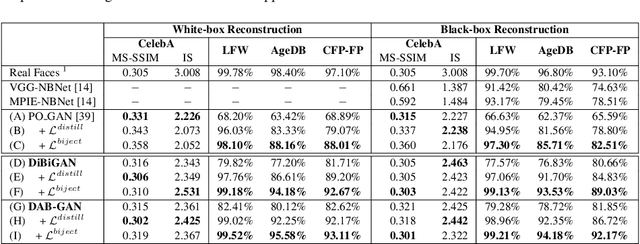
In this work, we investigate the problem of face reconstruction given a facial feature representation extracted from a blackbox face recognition engine. Indeed, it is very challenging problem in practice due to the limitations of abstracted information from the engine. We therefore introduce a new method named Attention-based Bijective Generative Adversarial Networks in a Distillation framework (DAB-GAN) to synthesize faces of a subject given his/her extracted face recognition features. Given any unconstrained unseen facial features of a subject, the DAB-GAN can reconstruct his/her faces in high definition. The DAB-GAN method includes a novel attention-based generative structure with the new defined Bijective Metrics Learning approach. The framework starts by introducing a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. The information from the blackbox face recognition engine will be optimally exploited using the global distillation process. Then an attention-based generator is presented for a highly robust generator to synthesize realistic faces with ID preservation. We have evaluated our method on the challenging face recognition databases, i.e. CelebA, LFW, AgeDB, CFP-FP, and consistently achieved the state-of-the-art results. The advancement of DAB-GAN is also proven on both image realism and ID preservation properties.
Depth Perspective-aware Multiple Object Tracking
Jul 10, 2022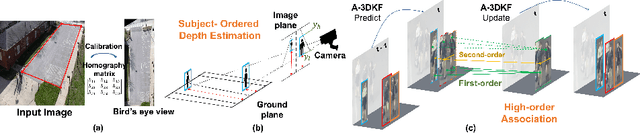
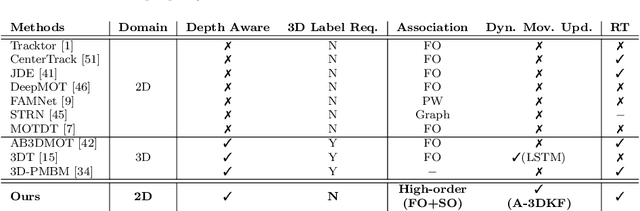
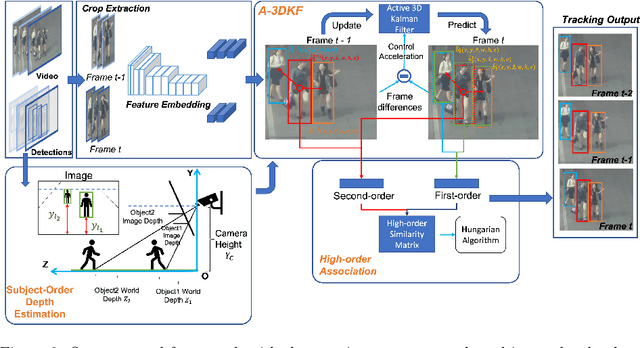
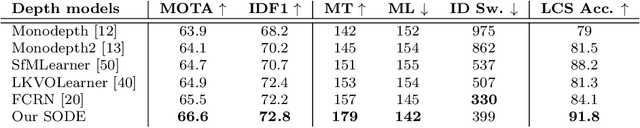
This paper aims to tackle Multiple Object Tracking (MOT), an important problem in computer vision but remains challenging due to many practical issues, especially occlusions. Indeed, we propose a new real-time Depth Perspective-aware Multiple Object Tracking (DP-MOT) approach to tackle the occlusion problem in MOT. A simple yet efficient Subject-Ordered Depth Estimation (SODE) is first proposed to automatically order the depth positions of detected subjects in a 2D scene in an unsupervised manner. Using the output from SODE, a new Active pseudo-3D Kalman filter, a simple but effective extension of Kalman filter with dynamic control variables, is then proposed to dynamically update the movement of objects. In addition, a new high-order association approach is presented in the data association step to incorporate first-order and second-order relationships between the detected objects. The proposed approach consistently achieves state-of-the-art performance compared to recent MOT methods on standard MOT benchmarks.
Multi-Camera Multiple 3D Object Tracking on the Move for Autonomous Vehicles
Apr 19, 2022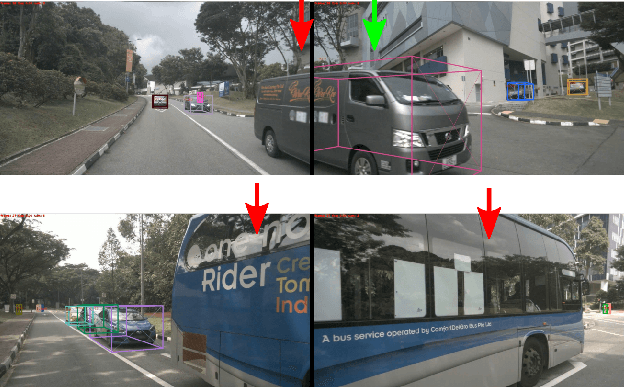
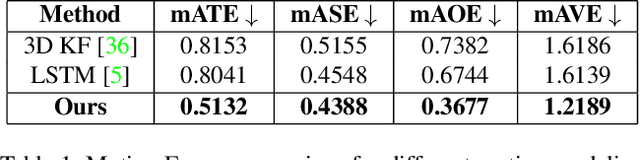
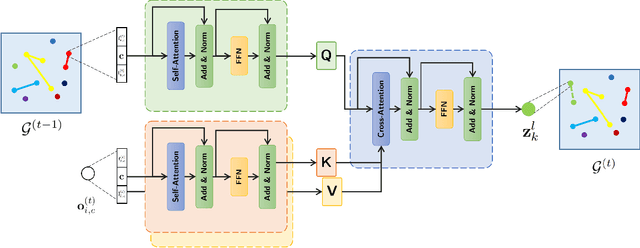
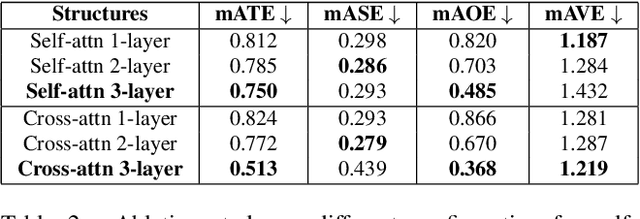
The development of autonomous vehicles provides an opportunity to have a complete set of camera sensors capturing the environment around the car. Thus, it is important for object detection and tracking to address new challenges, such as achieving consistent results across views of cameras. To address these challenges, this work presents a new Global Association Graph Model with Link Prediction approach to predict existing tracklets location and link detections with tracklets via cross-attention motion modeling and appearance re-identification. This approach aims at solving issues caused by inconsistent 3D object detection. Moreover, our model exploits to improve the detection accuracy of a standard 3D object detector in the nuScenes detection challenge. The experimental results on the nuScenes dataset demonstrate the benefits of the proposed method to produce SOTA performance on the existing vision-based tracking dataset.
DirecFormer: A Directed Attention in Transformer Approach to Robust Action Recognition
Mar 19, 2022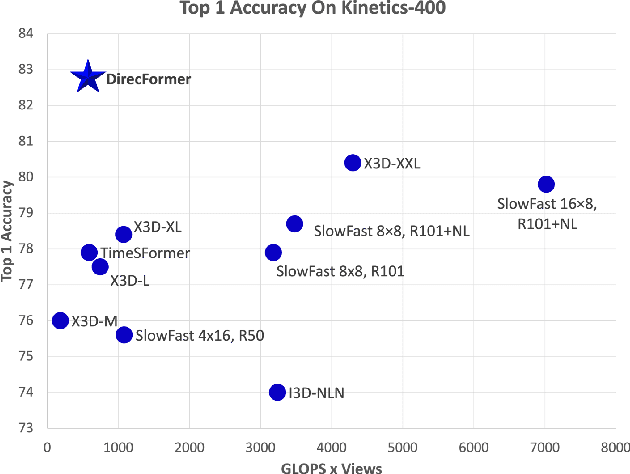
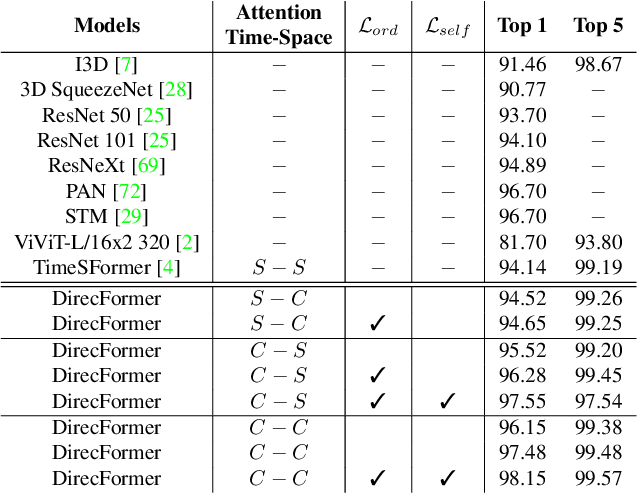
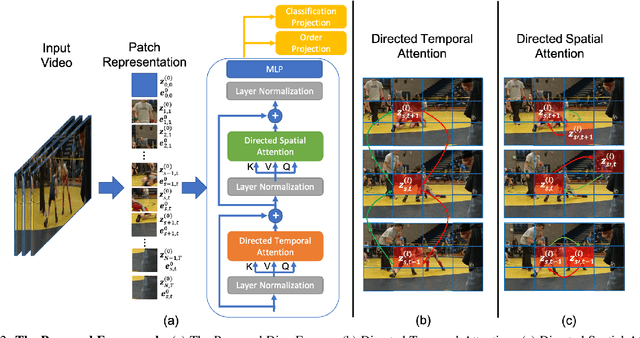
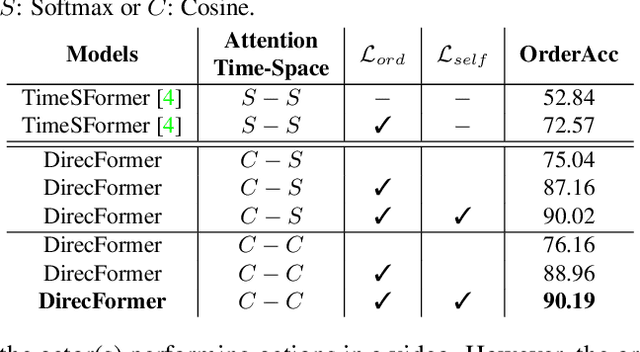
Human action recognition has recently become one of the popular research topics in the computer vision community. Various 3D-CNN based methods have been presented to tackle both the spatial and temporal dimensions in the task of video action recognition with competitive results. However, these methods have suffered some fundamental limitations such as lack of robustness and generalization, e.g., how does the temporal ordering of video frames affect the recognition results? This work presents a novel end-to-end Transformer-based Directed Attention (DirecFormer) framework for robust action recognition. The method takes a simple but novel perspective of Transformer-based approach to understand the right order of sequence actions. Therefore, the contributions of this work are three-fold. Firstly, we introduce the problem of ordered temporal learning issues to the action recognition problem. Secondly, a new Directed Attention mechanism is introduced to understand and provide attentions to human actions in the right order. Thirdly, we introduce the conditional dependency in action sequence modeling that includes orders and classes. The proposed approach consistently achieves the state-of-the-art (SOTA) results compared with the recent action recognition methods, on three standard large-scale benchmarks, i.e. Jester, Kinetics-400 and Something-Something-V2.
BiMaL: Bijective Maximum Likelihood Approach to Domain Adaptation in Semantic Scene Segmentation
Aug 06, 2021
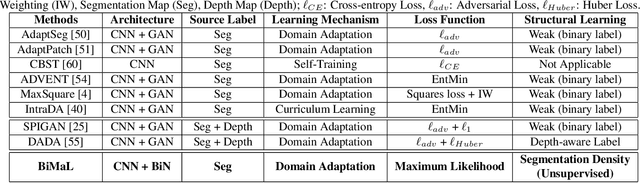
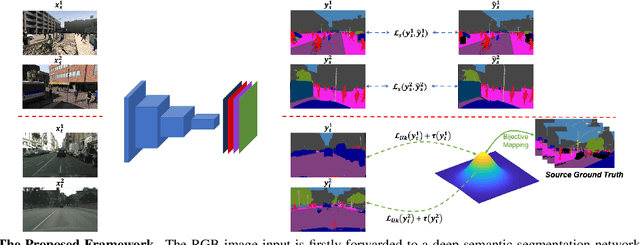
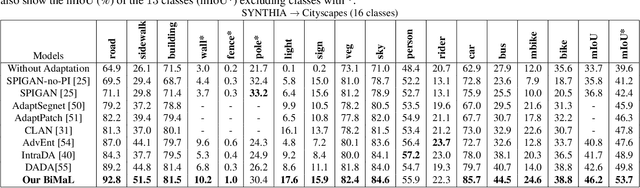
Semantic segmentation aims to predict pixel-level labels. It has become a popular task in various computer vision applications. While fully supervised segmentation methods have achieved high accuracy on large-scale vision datasets, they are unable to generalize on a new test environment or a new domain well. In this work, we first introduce a new Un-aligned Domain Score to measure the efficiency of a learned model on a new target domain in unsupervised manner. Then, we present the new Bijective Maximum Likelihood(BiMaL) loss that is a generalized form of the Adversarial Entropy Minimization without any assumption about pixel independence. We have evaluated the proposed BiMaL on two domains. The proposed BiMaL approach consistently outperforms the SOTA methods on empirical experiments on "SYNTHIA to Cityscapes", "GTA5 to Cityscapes", and "SYNTHIA to Vistas".