 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DreamBooth3D: Subject-Driven Text-to-3D Generation
Mar 27, 2023

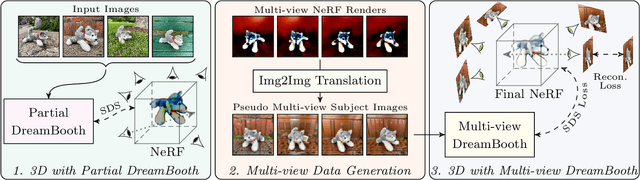


We present DreamBooth3D, an approach to personalize text-to-3D generative models from as few as 3-6 casually captured images of a subject. Our approach combines recent advances in personalizing text-to-image models (DreamBooth) with text-to-3D generation (DreamFusion). We find that naively combining these methods fails to yield satisfactory subject-specific 3D assets due to personalized text-to-image models overfitting to the input viewpoints of the subject. We overcome this through a 3-stage optimization strategy where we jointly leverage the 3D consistency of neural radiance fields together with the personalization capability of text-to-image models. Our method can produce high-quality, subject-specific 3D assets with text-driven modifications such as novel poses, colors and attributes that are not seen in any of the input images of the subject.
High-fidelity Pseudo-labels for Boosting Weakly-Supervised Segmentation
Apr 05, 2023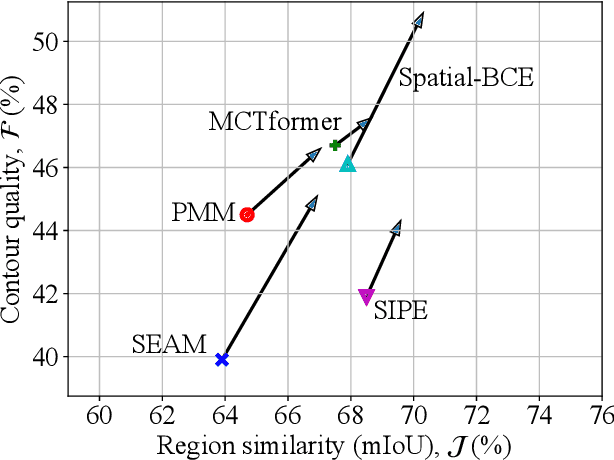



The task of image-level weakly-supervised semantic segmentation (WSSS) has gained popularity in recent years, as it reduces the vast data annotation cost for training segmentation models. The typical approach for WSSS involves training an image classification network using global average pooling (GAP) on convolutional feature maps. This enables the estimation of object locations based on class activation maps (CAMs), which identify the importance of image regions. The CAMs are then used to generate pseudo-labels, in the form of segmentation masks, to supervise a segmentation model in the absence of pixel-level ground truth. In case of the SEAM baseline, a previous work proposed to improve CAM learning in two ways: (1) Importance sampling, which is a substitute for GAP, and (2) the feature similarity loss, which utilizes a heuristic that object contours almost exclusively align with color edges in images. In this work, we propose a different probabilistic interpretation of CAMs for these techniques, rendering the likelihood more appropriate than the multinomial posterior. As a result, we propose an add-on method that can boost essentially any previous WSSS method, improving both the region similarity and contour quality of all implemented state-of-the-art baselines. This is demonstrated on a wide variety of baselines on the PASCAL VOC dataset. Experiments on the MS COCO dataset show that performance gains can also be achieved in a large-scale setting. Our code is available at https://github.com/arvijj/hfpl.
Training-Free Layout Control with Cross-Attention Guidance
Apr 06, 2023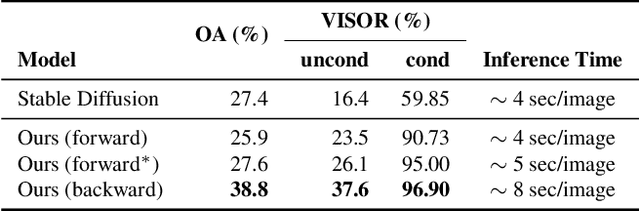
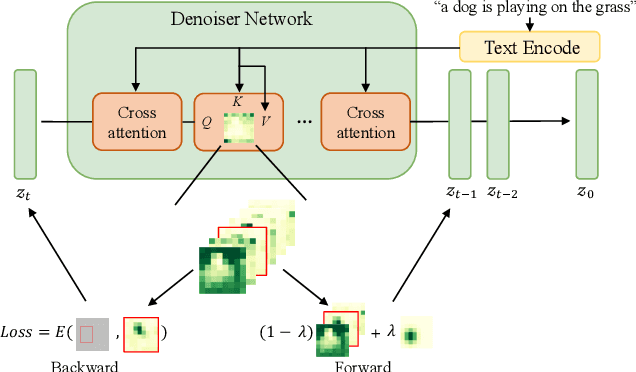
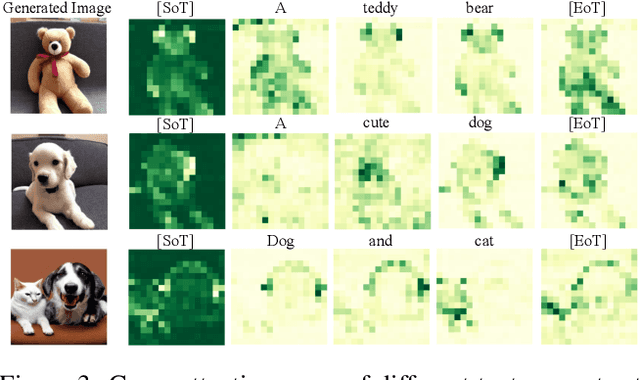
Recent diffusion-based generators can produce high-quality images based only on textual prompts. However, they do not correctly interpret instructions that specify the spatial layout of the composition. We propose a simple approach that can achieve robust layout control without requiring training or fine-tuning the image generator. Our technique, which we call layout guidance, manipulates the cross-attention layers that the model uses to interface textual and visual information and steers the reconstruction in the desired direction given, e.g., a user-specified layout. In order to determine how to best guide attention, we study the role of different attention maps when generating images and experiment with two alternative strategies, forward and backward guidance. We evaluate our method quantitatively and qualitatively with several experiments, validating its effectiveness. We further demonstrate its versatility by extending layout guidance to the task of editing the layout and context of a given real image.
Learning to search for and detect objects in foveal images using deep learning
Apr 12, 2023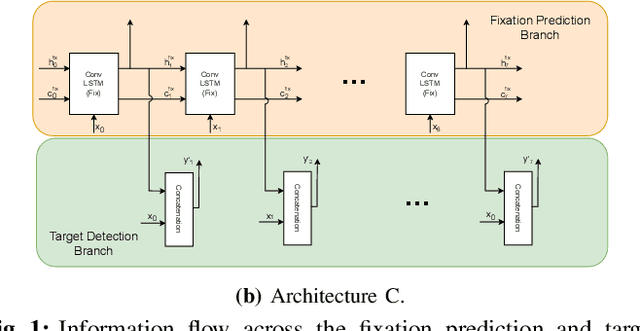
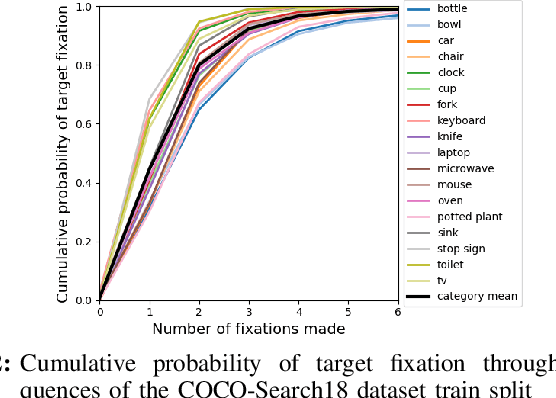
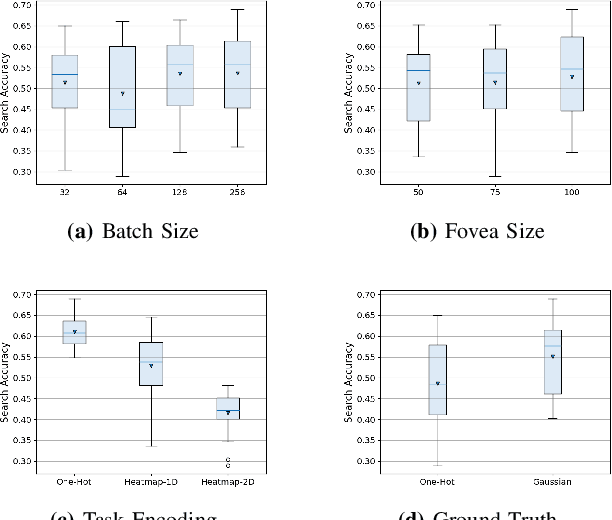
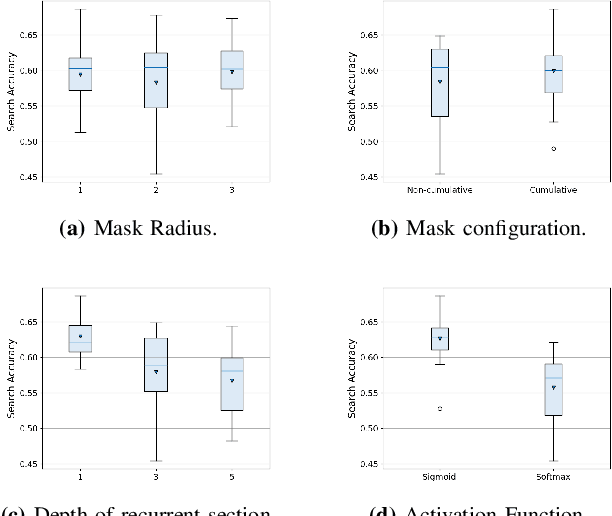
The human visual system processes images with varied degrees of resolution, with the fovea, a small portion of the retina, capturing the highest acuity region, which gradually declines toward the field of view's periphery. However, the majority of existing object localization methods rely on images acquired by image sensors with space-invariant resolution, ignoring biological attention mechanisms. As a region of interest pooling, this study employs a fixation prediction model that emulates human objective-guided attention of searching for a given class in an image. The foveated pictures at each fixation point are then classified to determine whether the target is present or absent in the scene. Throughout this two-stage pipeline method, we investigate the varying results obtained by utilizing high-level or panoptic features and provide a ground-truth label function for fixation sequences that is smoother, considering in a better way the spatial structure of the problem. Finally, we present a novel dual task model capable of performing fixation prediction and detection simultaneously, allowing knowledge transfer between the two tasks. We conclude that, due to the complementary nature of both tasks, the training process benefited from the sharing of knowledge, resulting in an improvement in performance when compared to the previous approach's baseline scores.
TR0N: Translator Networks for 0-Shot Plug-and-Play Conditional Generation
Apr 26, 2023
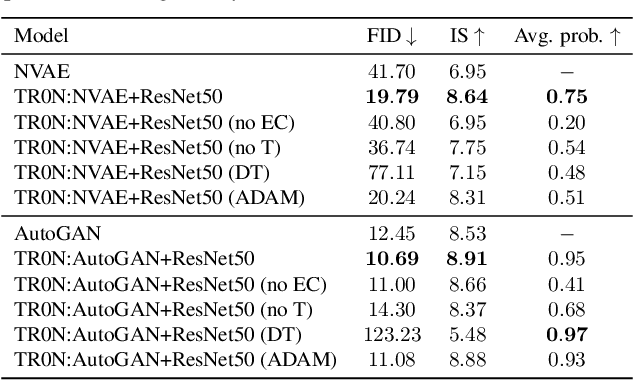
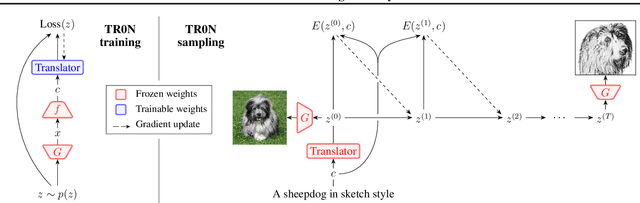

We propose TR0N, a highly general framework to turn pre-trained unconditional generative models, such as GANs and VAEs, into conditional models. The conditioning can be highly arbitrary, and requires only a pre-trained auxiliary model. For example, we show how to turn unconditional models into class-conditional ones with the help of a classifier, and also into text-to-image models by leveraging CLIP. TR0N learns a lightweight stochastic mapping which "translates" between the space of conditions and the latent space of the generative model, in such a way that the generated latent corresponds to a data sample satisfying the desired condition. The translated latent samples are then further improved upon through Langevin dynamics, enabling us to obtain higher-quality data samples. TR0N requires no training data nor fine-tuning, yet can achieve a zero-shot FID of 10.9 on MS-COCO, outperforming competing alternatives not only on this metric, but also in sampling speed -- all while retaining a much higher level of generality. Our code is available at https://github.com/layer6ai-labs/tr0n.
Modeling the Trade-off of Privacy Preservation and Activity Recognition on Low-Resolution Images
Mar 18, 2023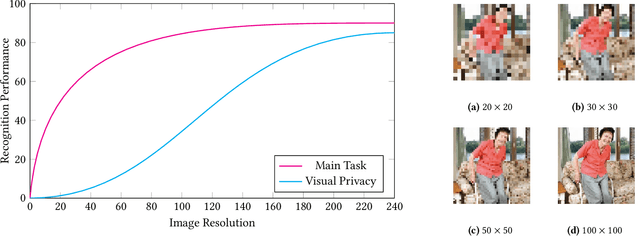
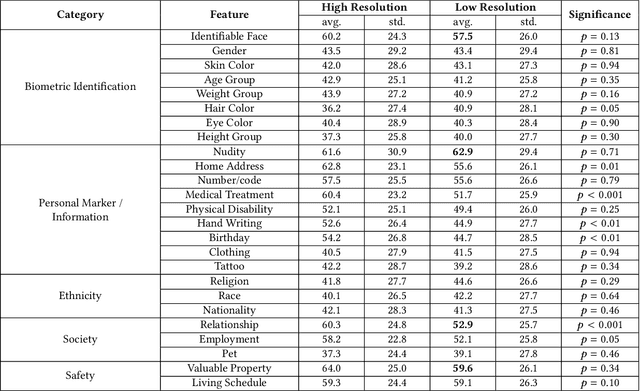
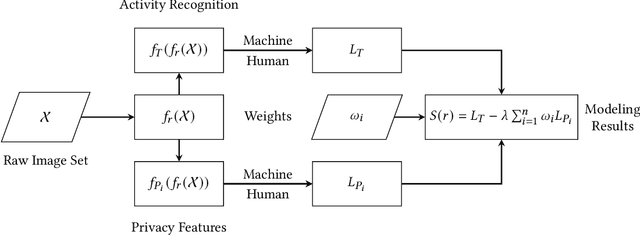
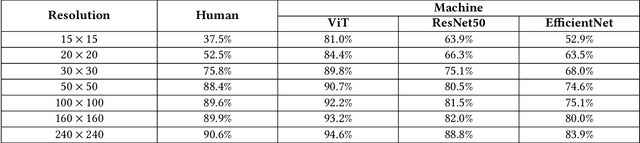
A computer vision system using low-resolution image sensors can provide intelligent services (e.g., activity recognition) but preserve unnecessary visual privacy information from the hardware level. However, preserving visual privacy and enabling accurate machine recognition have adversarial needs on image resolution. Modeling the trade-off of privacy preservation and machine recognition performance can guide future privacy-preserving computer vision systems using low-resolution image sensors. In this paper, using the at-home activity of daily livings (ADLs) as the scenario, we first obtained the most important visual privacy features through a user survey. Then we quantified and analyzed the effects of image resolution on human and machine recognition performance in activity recognition and privacy awareness tasks. We also investigated how modern image super-resolution techniques influence these effects. Based on the results, we proposed a method for modeling the trade-off of privacy preservation and activity recognition on low-resolution images.
Learning Similarity between Scene Graphs and Images with Transformers
Apr 02, 2023
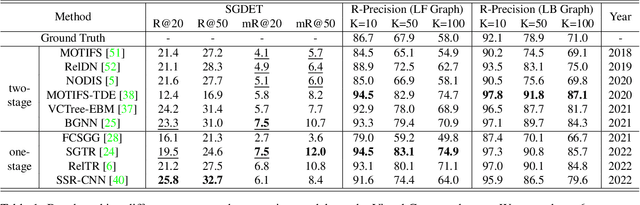
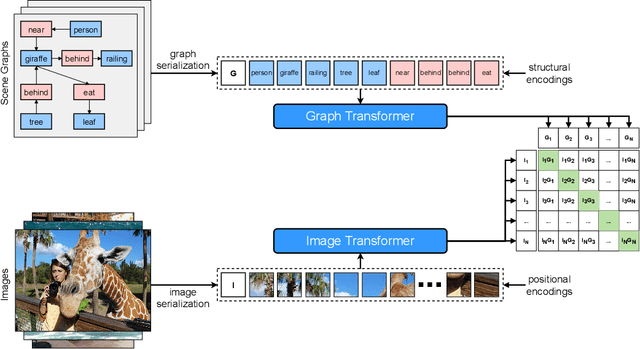

Scene graph generation is conventionally evaluated by (mean) Recall@K, which measures the ratio of correctly predicted triplets that appear in the ground truth. However, such triplet-oriented metrics cannot capture the global semantic information of scene graphs, and measure the similarity between images and generated scene graphs. The usability of scene graphs is therefore limited in downstream tasks. To address this issue, a framework that can measure the similarity of scene graphs and images is urgently required. Motivated by the successful application of Contrastive Language-Image Pre-training (CLIP), we propose a novel contrastive learning framework consisting of a graph Transformer and an image Transformer to align scene graphs and their corresponding images in the shared latent space. To enable the graph Transformer to comprehend the scene graph structure and extract representative features, we introduce a graph serialization technique that transforms a scene graph into a sequence with structural encoding. Based on our framework, we introduce R-Precision measuring image retrieval accuracy as a new evaluation metric for scene graph generation and establish new benchmarks for the Visual Genome and Open Images datasets. A series of experiments are further conducted to demonstrate the effectiveness of the graph Transformer, which shows great potential as a scene graph encoder.
TEGLO: High Fidelity Canonical Texture Mapping from Single-View Images
Mar 24, 2023
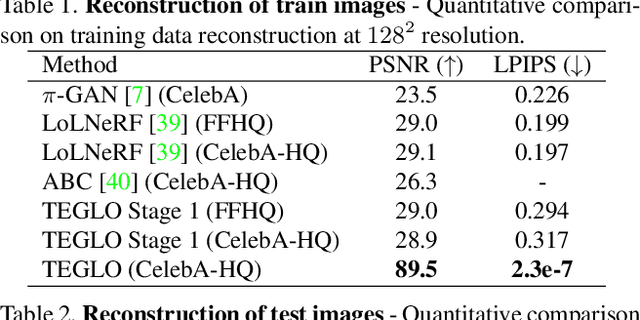
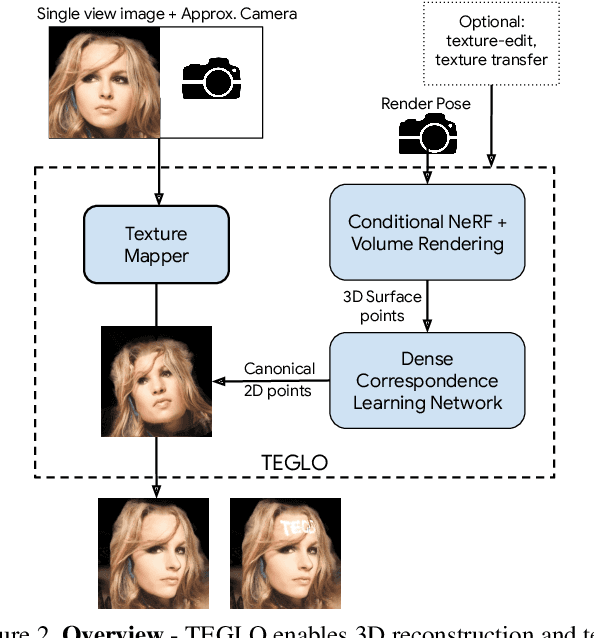

Recent work in Neural Fields (NFs) learn 3D representations from class-specific single view image collections. However, they are unable to reconstruct the input data preserving high-frequency details. Further, these methods do not disentangle appearance from geometry and hence are not suitable for tasks such as texture transfer and editing. In this work, we propose TEGLO (Textured EG3D-GLO) for learning 3D representations from single view in-the-wild image collections for a given class of objects. We accomplish this by training a conditional Neural Radiance Field (NeRF) without any explicit 3D supervision. We equip our method with editing capabilities by creating a dense correspondence mapping to a 2D canonical space. We demonstrate that such mapping enables texture transfer and texture editing without requiring meshes with shared topology. Our key insight is that by mapping the input image pixels onto the texture space we can achieve near perfect reconstruction (>= 74 dB PSNR at 1024^2 resolution). Our formulation allows for high quality 3D consistent novel view synthesis with high-frequency details at megapixel image resolution.
Learning Visibility Field for Detailed 3D Human Reconstruction and Relighting
Apr 24, 2023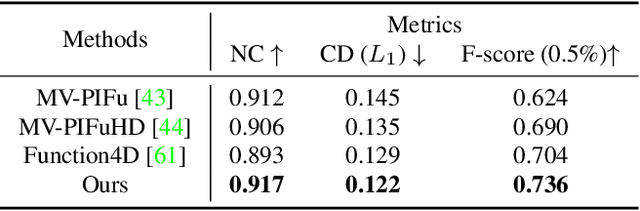

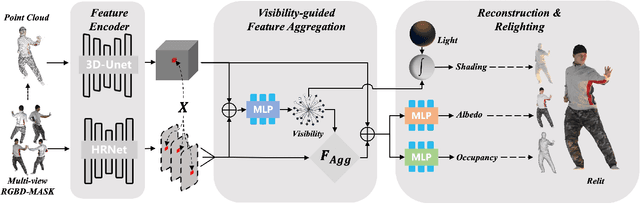
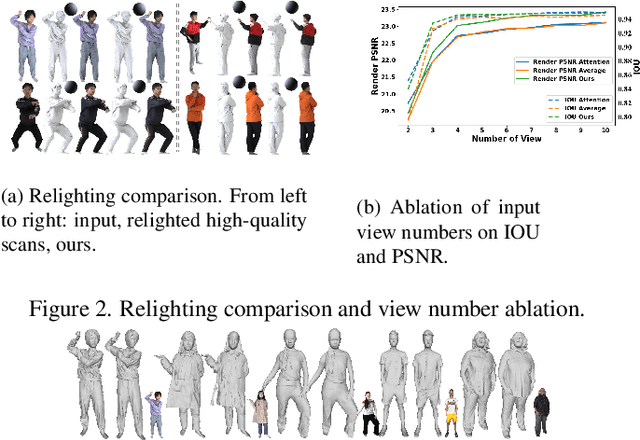
Detailed 3D reconstruction and photo-realistic relighting of digital humans are essential for various applications. To this end, we propose a novel sparse-view 3d human reconstruction framework that closely incorporates the occupancy field and albedo field with an additional visibility field--it not only resolves occlusion ambiguity in multiview feature aggregation, but can also be used to evaluate light attenuation for self-shadowed relighting. To enhance its training viability and efficiency, we discretize visibility onto a fixed set of sample directions and supply it with coupled geometric 3D depth feature and local 2D image feature. We further propose a novel rendering-inspired loss, namely TransferLoss, to implicitly enforce the alignment between visibility and occupancy field, enabling end-to-end joint training. Results and extensive experiments demonstrate the effectiveness of the proposed method, as it surpasses state-of-the-art in terms of reconstruction accuracy while achieving comparably accurate relighting to ray-traced ground truth.
Non-Linear Phase-Retrieval Algorithms for X-ray Propagation-Based Phase-Contrast Tomography
Apr 29, 2023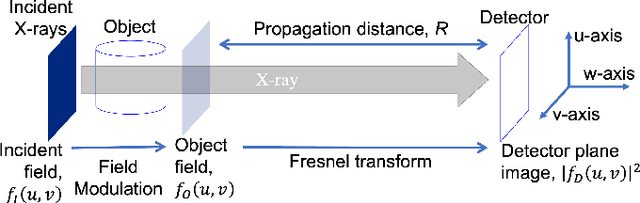

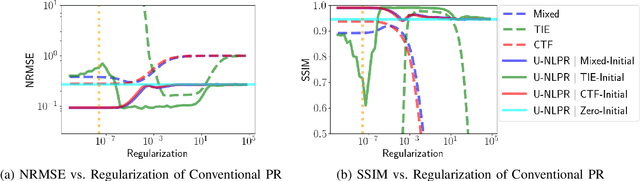

X-ray phase-contrast tomography (XPCT) is widely used for high-contrast 3D micron-scale imaging using nearly monochromatic X-rays at synchrotron beamlines. XPCT enables an order of magnitude improvement in image contrast of the reconstructed material interfaces with low X-ray absorption contrast. The dominant approaches to 3D reconstruction using XPCT relies on the use of phase-retrieval algorithms that make one or more limiting approximations for the experimental configuration and material properties. Since many experimental scenarios violate such approximations, the resulting reconstructions contain blur, artifacts, or other quantitative inaccuracies. Our solution to this problem is to formulate new iterative non-linear phase-retrieval (NLPR) algorithms that avoid such limiting approximations. Compared to the widely used state-of-the-art approaches, we show that our proposed algorithms result in sharp and quantitatively accurate reconstruction with reduced artifacts. Unlike existing NLPR algorithms, our approaches avoid the laborious manual tuning of regularization hyper-parameters while still achieving the stated goals. As an alternative to regularization, we propose explicit constraints on the material properties to constrain the solution space and solve the phase-retrieval problem. These constraints are easily user-configurable since they follow directly from the imaged object's dimensions and material properties.