 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RSA-INR: Riemannian Shape Autoencoding via 4D Implicit Neural Representations
May 22, 2023
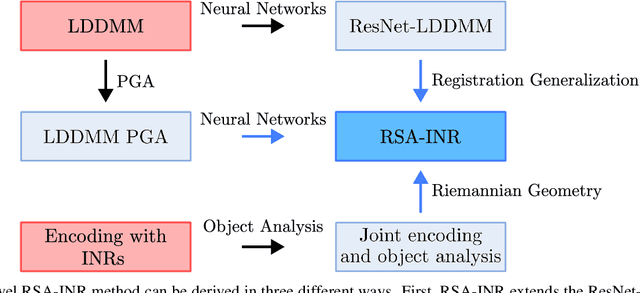

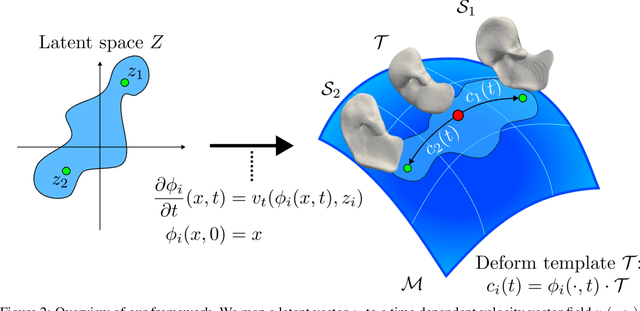
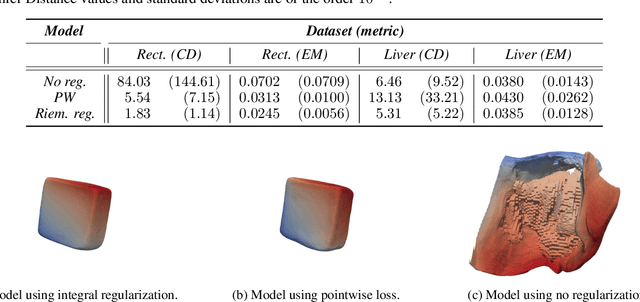
Shape encoding and shape analysis are valuable tools for comparing shapes and for dimensionality reduction. A specific framework for shape analysis is the Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework, which is capable of shape matching and dimensionality reduction. Researchers have recently introduced neural networks into this framework. However, these works can not match more than two objects simultaneously or have suboptimal performance in shape variability modeling. The latter limitation occurs as the works do not use state-of-the-art shape encoding methods. Moreover, the literature does not discuss the connection between the LDDMM Riemannian distance and the Riemannian geometry for deep learning literature. Our work aims to bridge this gap by demonstrating how LDDMM can integrate Riemannian geometry into deep learning. Furthermore, we discuss how deep learning solves and generalizes shape matching and dimensionality reduction formulations of LDDMM. We achieve both goals by designing a novel implicit encoder for shapes. This model extends a neural network-based algorithm for LDDMM-based pairwise registration, results in a nonlinear manifold PCA, and adds a Riemannian geometry aspect to deep learning models for shape variability modeling. Additionally, we demonstrate that the Riemannian geometry component improves the reconstruction procedure of the implicit encoder in terms of reconstruction quality and stability to noise. We hope our discussion paves the way to more research into how Riemannian geometry, shape/image analysis, and deep learning can be combined.
Blur Invariants for Image Recognition
Jan 18, 2023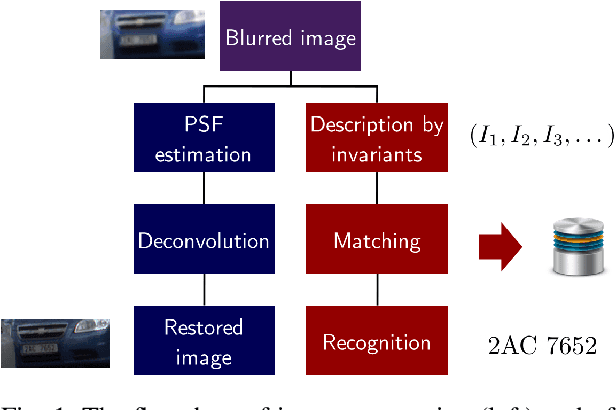

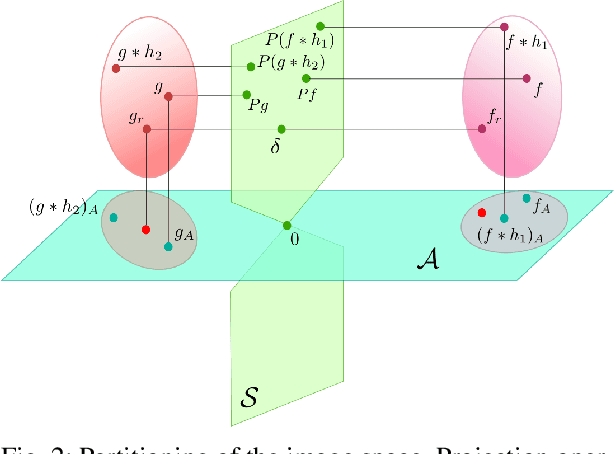
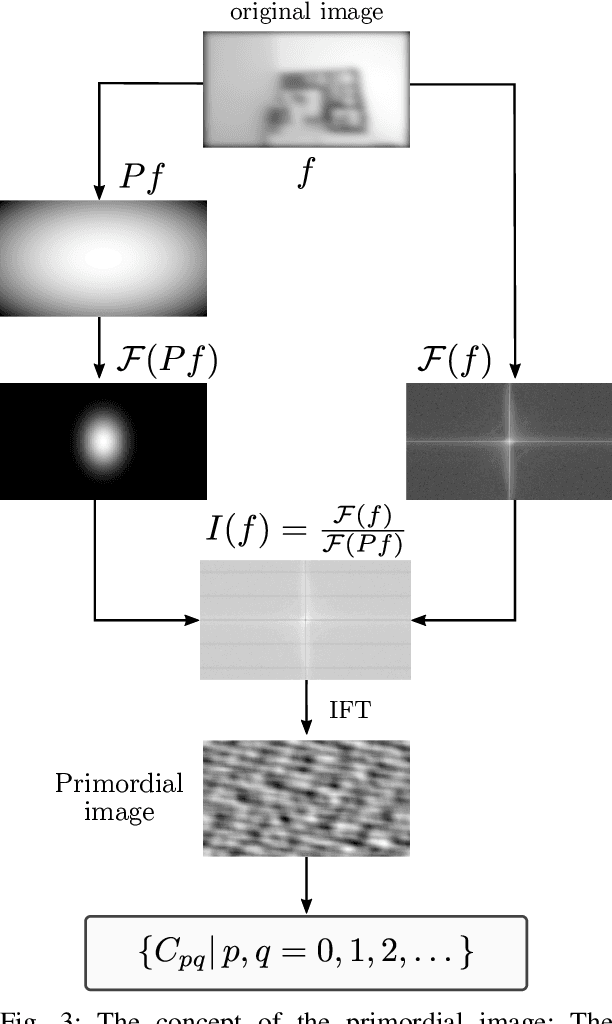
Blur is an image degradation that is difficult to remove. Invariants with respect to blur offer an alternative way of a~description and recognition of blurred images without any deblurring. In this paper, we present an original unified theory of blur invariants. Unlike all previous attempts, the new theory does not require any prior knowledge of the blur type. The invariants are constructed in the Fourier domain by means of orthogonal projection operators and moment expansion is used for efficient and stable computation. It is shown that all blur invariants published earlier are just particular cases of this approach. Experimental comparison to concurrent approaches shows the advantages of the proposed theory.
Retinal Image Restoration using Transformer and Cycle-Consistent Generative Adversarial Network
Mar 03, 2023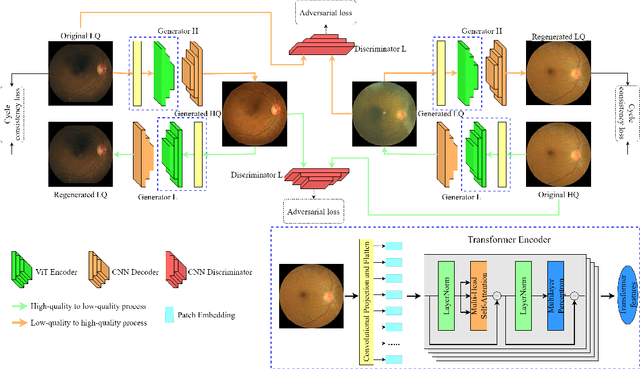

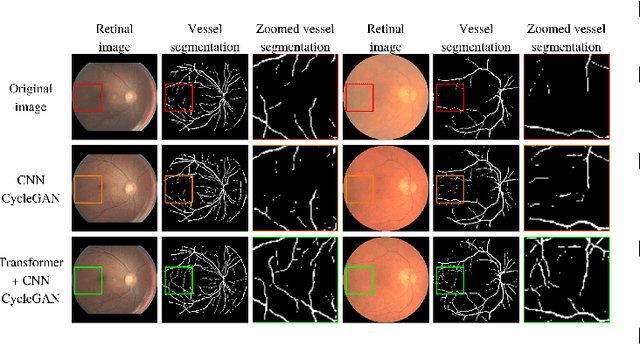
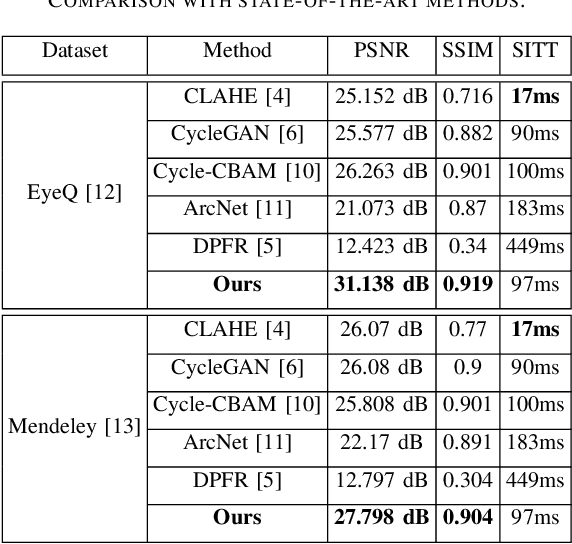
Medical imaging plays a significant role in detecting and treating various diseases. However, these images often happen to be of too poor quality, leading to decreased efficiency, extra expenses, and even incorrect diagnoses. Therefore, we propose a retinal image enhancement method using a vision transformer and convolutional neural network. It builds a cycle-consistent generative adversarial network that relies on unpaired datasets. It consists of two generators that translate images from one domain to another (e.g., low- to high-quality and vice versa), playing an adversarial game with two discriminators. Generators produce indistinguishable images for discriminators that predict the original images from generated ones. Generators are a combination of vision transformer (ViT) encoder and convolutional neural network (CNN) decoder. Discriminators include traditional CNN encoders. The resulting improved images have been tested quantitatively using such evaluation metrics as peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and qualitatively, i.e., vessel segmentation. The proposed method successfully reduces the adverse effects of blurring, noise, illumination disturbances, and color distortions while significantly preserving structural and color information. Experimental results show the superiority of the proposed method. Our testing PSNR is 31.138 dB for the first and 27.798 dB for the second dataset. Testing SSIM is 0.919 and 0.904, respectively.
M2T: Masking Transformers Twice for Faster Decoding
Apr 14, 2023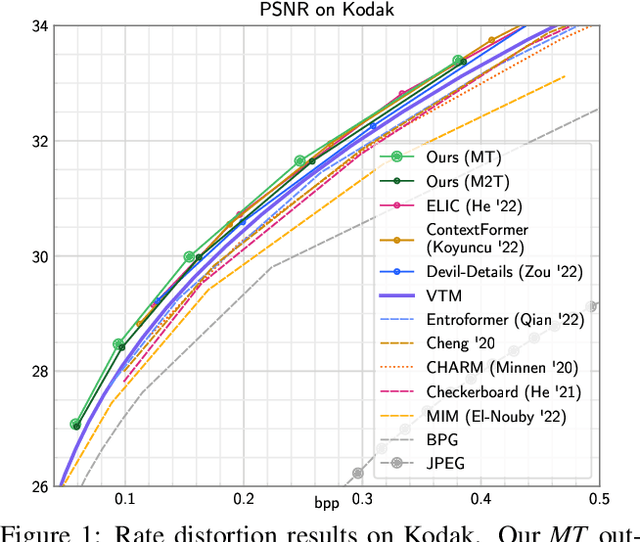

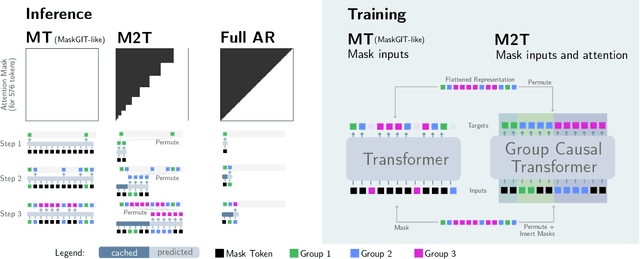
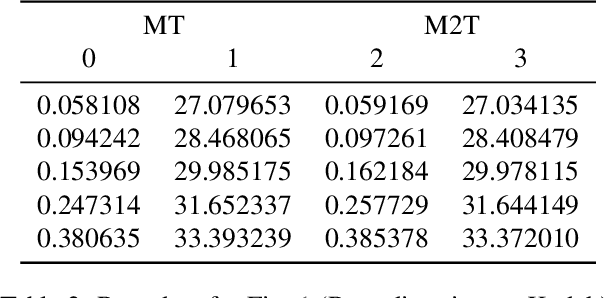
We show how bidirectional transformers trained for masked token prediction can be applied to neural image compression to achieve state-of-the-art results. Such models were previously used for image generation by progressivly sampling groups of masked tokens according to uncertainty-adaptive schedules. Unlike these works, we demonstrate that predefined, deterministic schedules perform as well or better for image compression. This insight allows us to use masked attention during training in addition to masked inputs, and activation caching during inference, to significantly speed up our models (~4 higher inference speed) at a small increase in bitrate.
Neural Voting Field for Camera-Space 3D Hand Pose Estimation
May 07, 2023
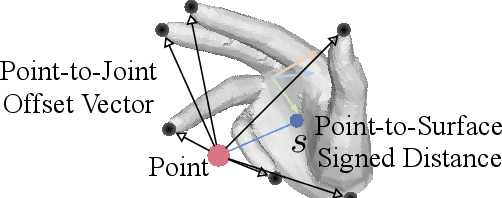
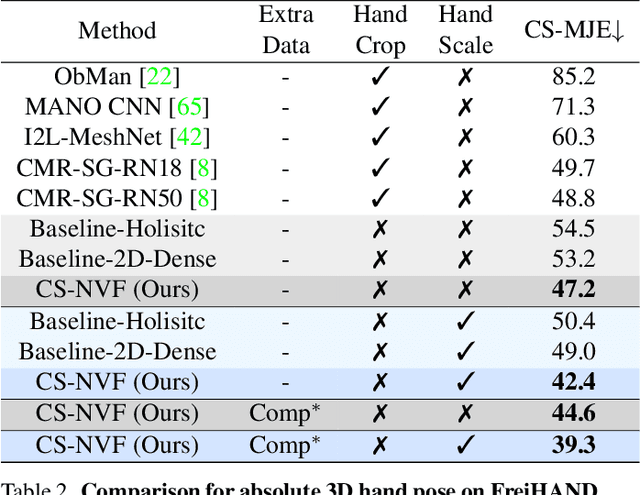
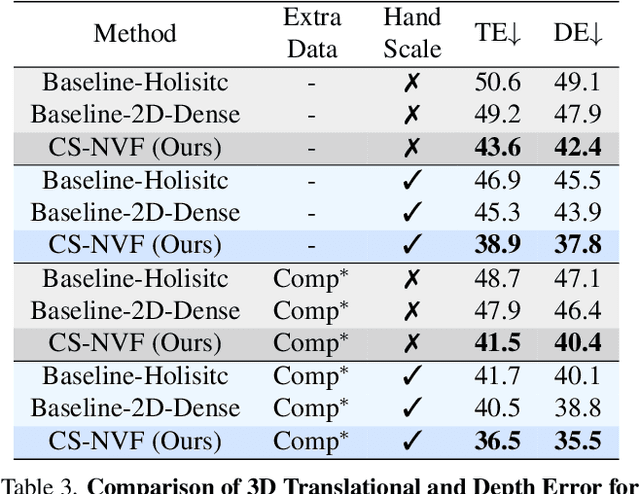
We present a unified framework for camera-space 3D hand pose estimation from a single RGB image based on 3D implicit representation. As opposed to recent works, most of which first adopt holistic or pixel-level dense regression to obtain relative 3D hand pose and then follow with complex second-stage operations for 3D global root or scale recovery, we propose a novel unified 3D dense regression scheme to estimate camera-space 3D hand pose via dense 3D point-wise voting in camera frustum. Through direct dense modeling in 3D domain inspired by Pixel-aligned Implicit Functions for 3D detailed reconstruction, our proposed Neural Voting Field (NVF) fully models 3D dense local evidence and hand global geometry, helping to alleviate common 2D-to-3D ambiguities. Specifically, for a 3D query point in camera frustum and its pixel-aligned image feature, NVF, represented by a Multi-Layer Perceptron, regresses: (i) its signed distance to the hand surface; (ii) a set of 4D offset vectors (1D voting weight and 3D directional vector to each hand joint). Following a vote-casting scheme, 4D offset vectors from near-surface points are selected to calculate the 3D hand joint coordinates by a weighted average. Experiments demonstrate that NVF outperforms existing state-of-the-art algorithms on FreiHAND dataset for camera-space 3D hand pose estimation. We also adapt NVF to the classic task of root-relative 3D hand pose estimation, for which NVF also obtains state-of-the-art results on HO3D dataset.
An Aligned Multi-Temporal Multi-Resolution Satellite Image Dataset for Change Detection Research
Feb 23, 2023
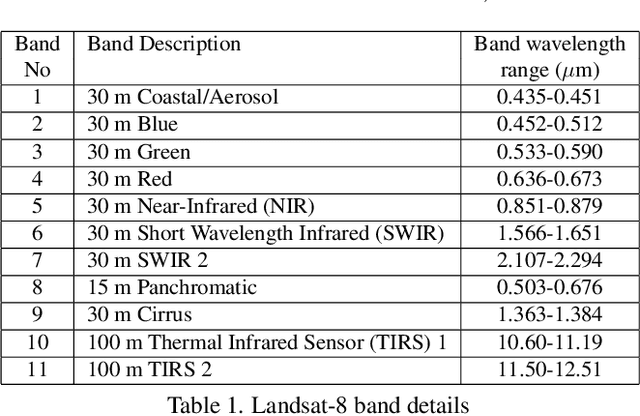
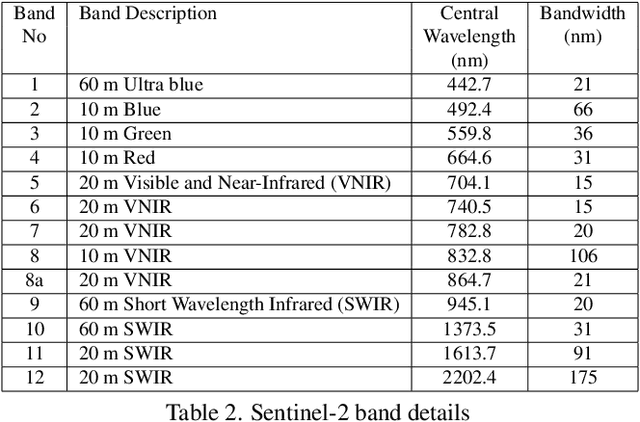
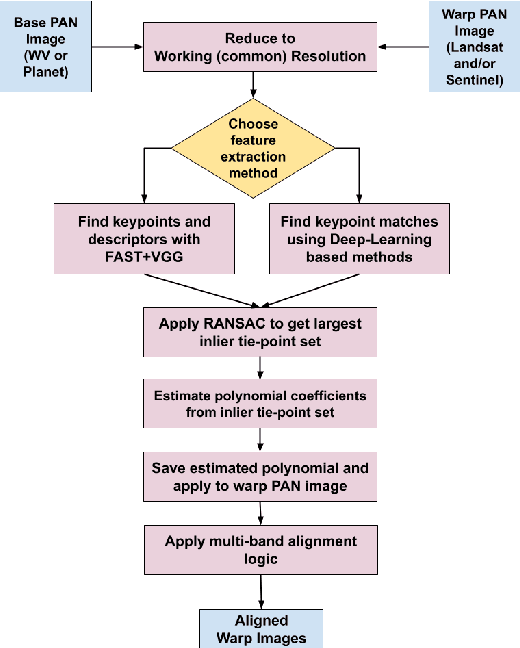
This paper presents an aligned multi-temporal and multi-resolution satellite image dataset for research in change detection. We expect our dataset to be useful to researchers who want to fuse information from multiple satellites for detecting changes on the surface of the earth that may not be fully visible in any single satellite. The dataset we present was created by augmenting the SpaceNet-7 dataset with temporally parallel stacks of Landsat and Sentinel images. The SpaceNet-7 dataset consists of time-sequenced Planet images recorded over 101 AOIs (Areas-of-Interest). In our dataset, for each of the 60 AOIs that are meant for training, we augment the Planet datacube with temporally parallel datacubes of Landsat and Sentinel images. The temporal alignments between the high-res Planet images, on the one hand, and the Landsat and Sentinel images, on the other, are approximate since the temporal resolution for the Planet images is one month -- each image being a mosaic of the best data collected over a month. Whenever we have a choice regarding which Landsat and Sentinel images to pair up with the Planet images, we have chosen those that had the least cloud cover. A particularly important feature of our dataset is that the high-res and the low-res images are spatially aligned together with our MuRA framework presented in this paper. Foundational to the alignment calculation is the modeling of inter-satellite misalignment errors with polynomials as in NASA's AROP algorithm. We have named our dataset MuRA-T for the MuRA framework that is used for aligning the cross-satellite images and "T" for the temporal dimension in the dataset.
Image-based Pose Estimation and Shape Reconstruction for Robot Manipulators and Soft, Continuum Robots via Differentiable Rendering
Feb 27, 2023
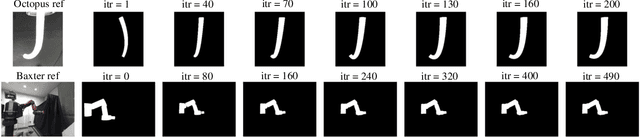
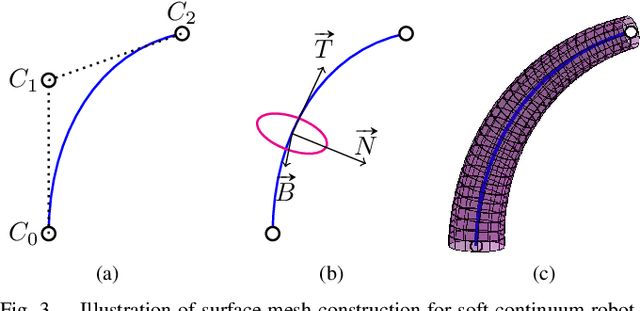
State estimation from measured data is crucial for robotic applications as autonomous systems rely on sensors to capture the motion and localize in the 3D world. Among sensors that are designed for measuring a robot's pose, or for soft robots, their shape, vision sensors are favorable because they are information-rich, easy to set up, and cost-effective. With recent advancements in computer vision, deep learning-based methods no longer require markers for identifying feature points on the robot. However, learning-based methods are data-hungry and hence not suitable for soft and prototyping robots, as building such bench-marking datasets is usually infeasible. In this work, we achieve image-based robot pose estimation and shape reconstruction from camera images. Our method requires no precise robot meshes, but rather utilizes a differentiable renderer and primitive shapes. It hence can be applied to robots for which CAD models might not be available or are crude. Our parameter estimation pipeline is fully differentiable. The robot shape and pose are estimated iteratively by back-propagating the image loss to update the parameters. We demonstrate that our method of using geometrical shape primitives can achieve high accuracy in shape reconstruction for a soft continuum robot and pose estimation for a robot manipulator.
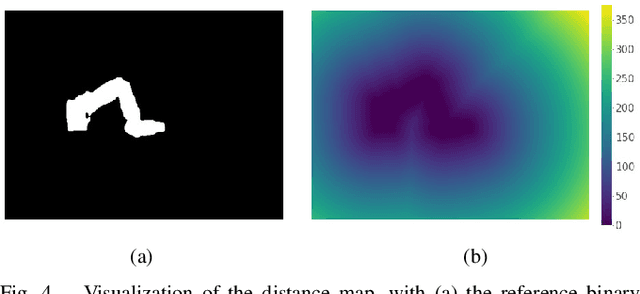
Segmentation of Aortic Vessel Tree in CT Scans with Deep Fully Convolutional Networks
May 16, 2023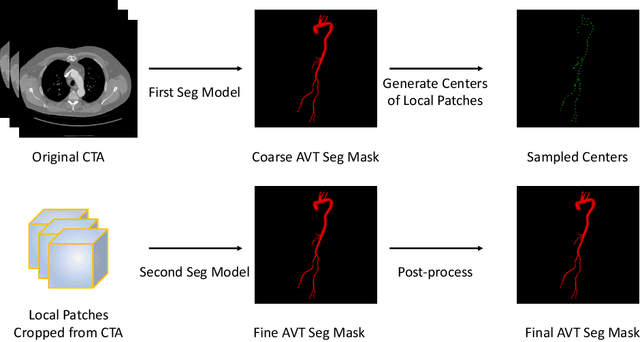
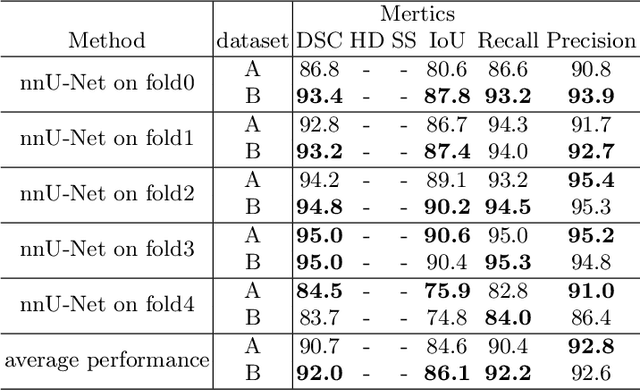
Automatic and accurate segmentation of aortic vessel tree (AVT) in computed tomography (CT) scans is crucial for early detection, diagnosis and prognosis of aortic diseases, such as aneurysms, dissections and stenosis. However, this task remains challenges, due to the complexity of aortic vessel tree and amount of CT angiography data. In this technical report, we use two-stage fully convolutional networks (FCNs) to automatically segment AVT in CTA scans from multiple centers. Specifically, we firstly adopt a 3D FCN with U-shape network architecture to segment AVT in order to produce topology attention and accelerate medical image analysis pipeline. And then another one 3D FCN is trained to segment branches of AVT along the pseudo-centerline of AVT. In the 2023 MICCAI Segmentation of the Aorta (SEG.A.) Challenge , the reported method was evaluated on the public dataset of 56 cases. The resulting Dice Similarity Coefficient (DSC) is 0.920, Jaccard Similarity Coefficient (JSC) is 0.861, Recall is 0.922, and Precision is 0.926 on a 5-fold random split of training and validation set.
Probabilistic Distance-Based Outlier Detection
May 16, 2023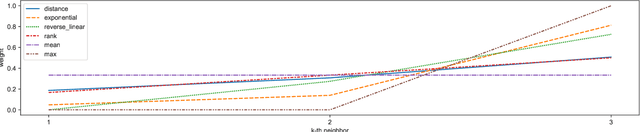
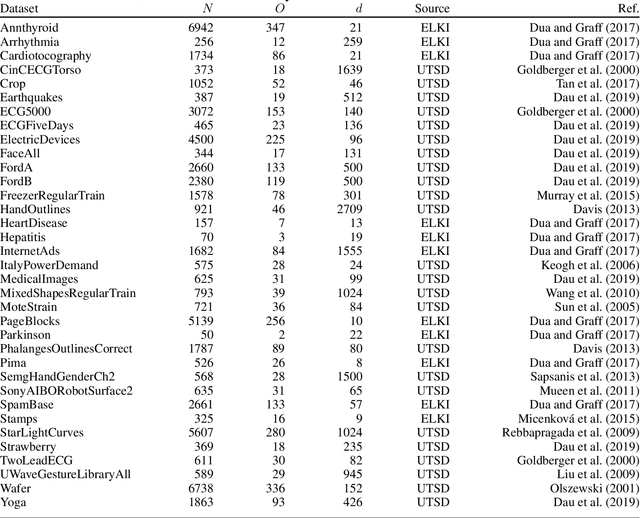
The scores of distance-based outlier detection methods are difficult to interpret, making it challenging to determine a cut-off threshold between normal and outlier data points without additional context. We describe a generic transformation of distance-based outlier scores into interpretable, probabilistic estimates. The transformation is ranking-stable and increases the contrast between normal and outlier data points. Determining distance relationships between data points is necessary to identify the nearest-neighbor relationships in the data, yet, most of the computed distances are typically discarded. We show that the distances to other data points can be used to model distance probability distributions and, subsequently, use the distributions to turn distance-based outlier scores into outlier probabilities. Our experiments show that the probabilistic transformation does not impact detection performance over numerous tabular and image benchmark datasets but results in interpretable outlier scores with increased contrast between normal and outlier samples. Our work generalizes to a wide range of distance-based outlier detection methods, and because existing distance computations are used, it adds no significant computational overhead.
Image2SSM: Reimagining Statistical Shape Models from Images with Radial Basis Functions
May 19, 2023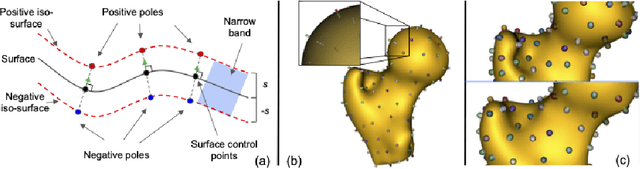
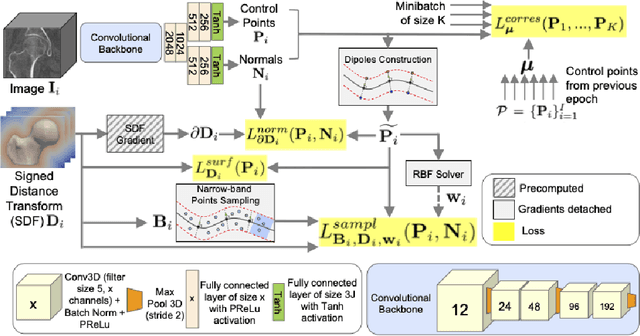
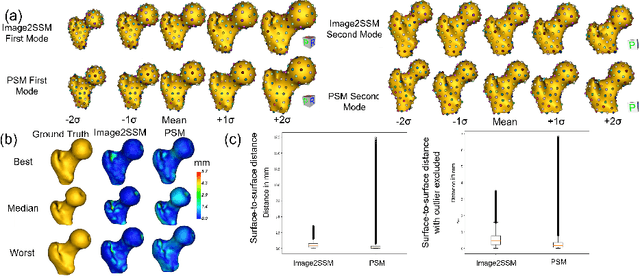
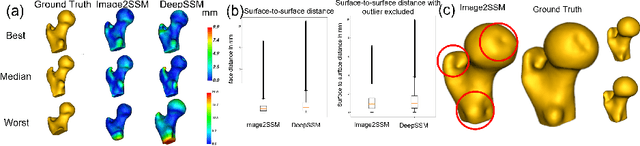
Statistical shape modeling (SSM) is an essential tool for analyzing variations in anatomical morphology. In a typical SSM pipeline, 3D anatomical images, gone through segmentation and rigid registration, are represented using lower-dimensional shape features, on which statistical analysis can be performed. Various methods for constructing compact shape representations have been proposed, but they involve laborious and costly steps. We propose Image2SSM, a novel deep-learning-based approach for SSM that leverages image-segmentation pairs to learn a radial-basis-function (RBF)-based representation of shapes directly from images. This RBF-based shape representation offers a rich self-supervised signal for the network to estimate a continuous, yet compact representation of the underlying surface that can adapt to complex geometries in a data-driven manner. Image2SSM can characterize populations of biological structures of interest by constructing statistical landmark-based shape models of ensembles of anatomical shapes while requiring minimal parameter tuning and no user assistance. Once trained, Image2SSM can be used to infer low-dimensional shape representations from new unsegmented images, paving the way toward scalable approaches for SSM, especially when dealing with large cohorts. Experiments on synthetic and real datasets show the efficacy of the proposed method compared to the state-of-art correspondence-based method for SSM.