 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised One-Shot Learning for Automatic Segmentation of StyleGAN Images
Mar 17, 2023



We propose a framework for the automatic one-shot segmentation of synthetic images generated by a StyleGAN. Our framework is based on the observation that the multi-scale hidden features in the GAN generator hold useful semantic information that can be utilized for automatic on-the-fly segmentation of the generated images. Using these features, our framework learns to segment synthetic images using a self-supervised contrastive clustering algorithm that projects the hidden features into a compact space for per-pixel classification. This novel contrastive learner is based on using a pixel-wise swapped prediction loss for image segmentation that leads to faster learning of the feature vectors for one-shot segmentation. We have tested our implementation on a number of standard benchmarks to yield a segmentation performance that not only outperforms the semi-supervised baseline methods by an average wIoU margin of 1.02% but also improves the inference speeds by a factor of 4.5. Finally, we also show the results of using the proposed one-shot learner in implementing BagGAN, a framework for producing annotated synthetic baggage X-ray scans for threat detection. This framework was trained and tested on the PIDRay baggage benchmark to yield a performance comparable to its baseline segmenter based on manual annotations.
An Aligned Multi-Temporal Multi-Resolution Satellite Image Dataset for Change Detection Research
Feb 27, 2023This paper presents an aligned multi-temporal and multi-resolution satellite image dataset for research in change detection. We expect our dataset to be useful to researchers who want to fuse information from multiple satellites for detecting changes on the surface of the earth that may not be fully visible in any single satellite. The dataset we present was created by augmenting the SpaceNet-7 dataset with temporally parallel stacks of Landsat and Sentinel images. The SpaceNet-7 dataset consists of time-sequenced Planet images recorded over 101 AOIs (Areas-of-Interest). In our dataset, for each of the 60 AOIs that are meant for training, we augment the Planet datacube with temporally parallel datacubes of Landsat and Sentinel images. The temporal alignments between the high-res Planet images, on the one hand, and the Landsat and Sentinel images, on the other, are approximate since the temporal resolution for the Planet images is one month -- each image being a mosaic of the best data collected over a month. Whenever we have a choice regarding which Landsat and Sentinel images to pair up with the Planet images, we have chosen those that had the least cloud cover. A particularly important feature of our dataset is that the high-res and the low-res images are spatially aligned together with our MuRA framework presented in this paper. Foundational to the alignment calculation is the modeling of inter-satellite misalignment errors with polynomials as in NASA's AROP algorithm. We have named our dataset MuRA-T for the MuRA framework that is used for aligning the cross-satellite images and "T" for the temporal dimension in the dataset.
maskGRU: Tracking Small Objects in the Presence of Large Background Motions
Jan 03, 2022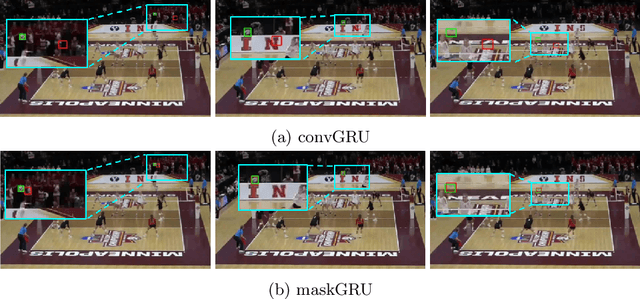
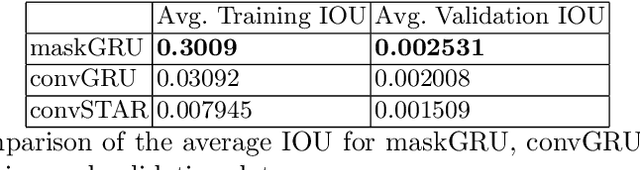
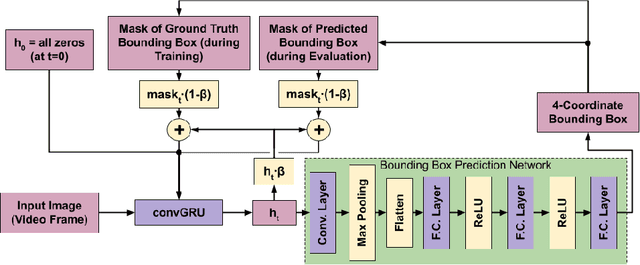
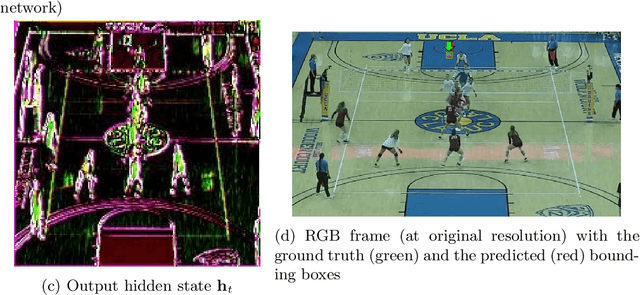
We propose a recurrent neural network-based spatio-temporal framework named maskGRU for the detection and tracking of small objects in videos. While there have been many developments in the area of object tracking in recent years, tracking a small moving object amid other moving objects and actors (such as a ball amid moving players in sports footage) continues to be a difficult task. Existing spatio-temporal networks, such as convolutional Gated Recurrent Units (convGRUs), are difficult to train and have trouble accurately tracking small objects under such conditions. To overcome these difficulties, we developed the maskGRU framework that uses a weighted sum of the internal hidden state produced by a convGRU and a 3-channel mask of the tracked object's predicted bounding box as the hidden state to be used at the next time step of the underlying convGRU. We believe the technique of incorporating a mask into the hidden state through a weighted sum has two benefits: controlling the effect of exploding gradients and introducing an attention-like mechanism into the network by indicating where in the previous video frame the object is located. Our experiments show that maskGRU outperforms convGRU at tracking objects that are small relative to the video resolution even in the presence of other moving objects.
Uncertainty, Edge, and Reverse-Attention Guided Generative Adversarial Network for Automatic Building Detection in Remotely Sensed Images
Dec 10, 2021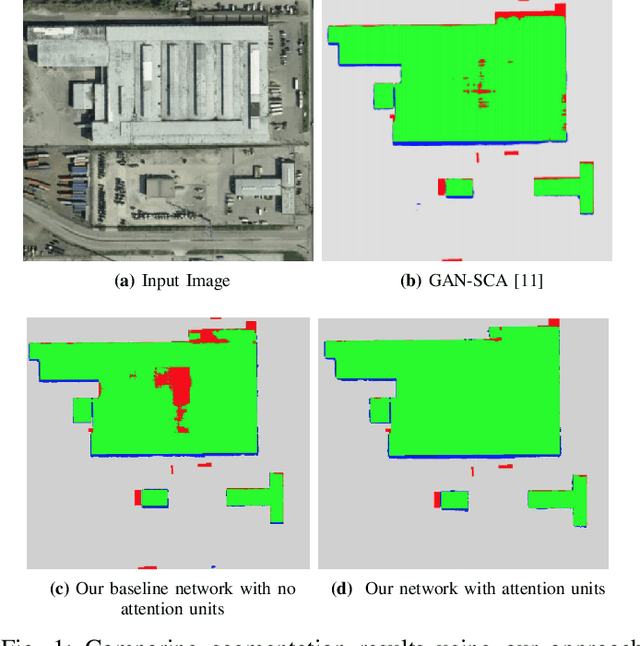

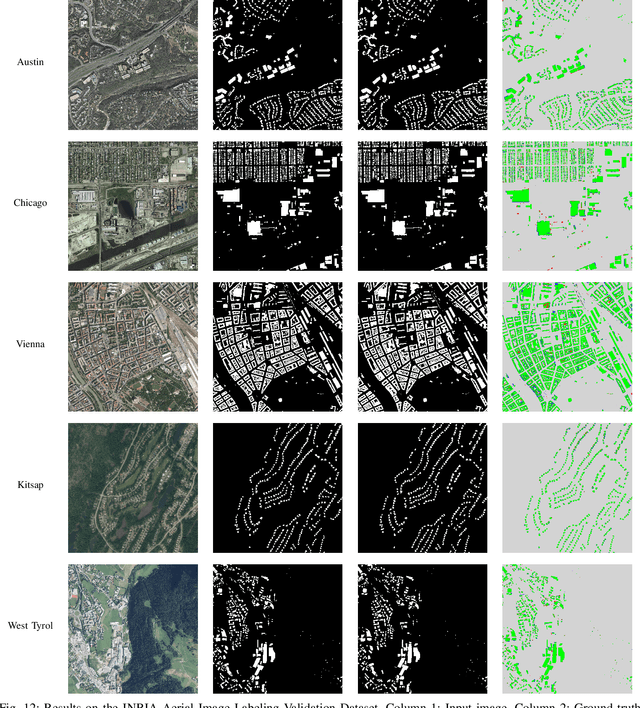
Despite recent advances in deep-learning based semantic segmentation, automatic building detection from remotely sensed imagery is still a challenging problem owing to large variability in the appearance of buildings across the globe. The errors occur mostly around the boundaries of the building footprints, in shadow areas, and when detecting buildings whose exterior surfaces have reflectivity properties that are very similar to those of the surrounding regions. To overcome these problems, we propose a generative adversarial network based segmentation framework with uncertainty attention unit and refinement module embedded in the generator. The refinement module, composed of edge and reverse attention units, is designed to refine the predicted building map. The edge attention enhances the boundary features to estimate building boundaries with greater precision, and the reverse attention allows the network to explore the features missing in the previously estimated regions. The uncertainty attention unit assists the network in resolving uncertainties in classification. As a measure of the power of our approach, as of December 4, 2021, it ranks at the second place on DeepGlobe's public leaderboard despite the fact that main focus of our approach -- refinement of the building edges -- does not align exactly with the metrics used for leaderboard rankings. Our overall F1-score on DeepGlobe's challenging dataset is 0.745. We also report improvements on the previous-best results for the challenging INRIA Validation Dataset for which our network achieves an overall IoU of 81.28% and an overall accuracy of 97.03%. Along the same lines, for the official INRIA Test Dataset, our network scores 77.86% and 96.41% in overall IoU and accuracy.
CheckSoft : A Scalable Event-Driven Software Architecture for Keeping Track of People and Things in People-Centric Spaces
Feb 21, 2021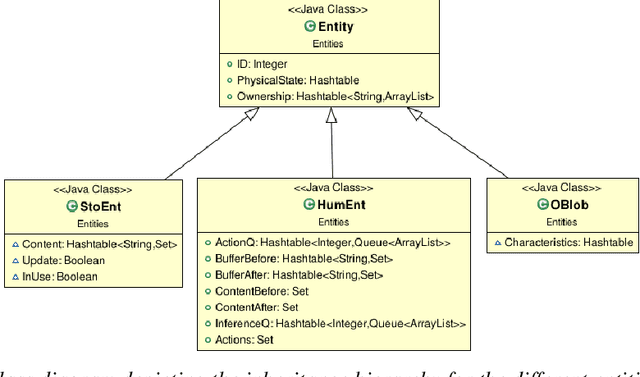
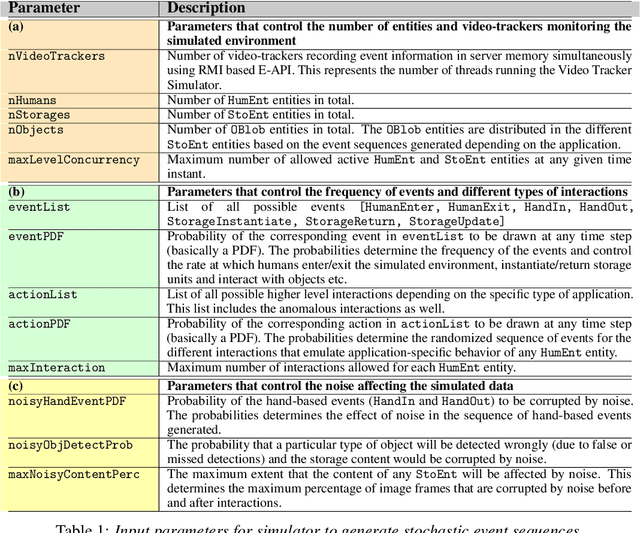
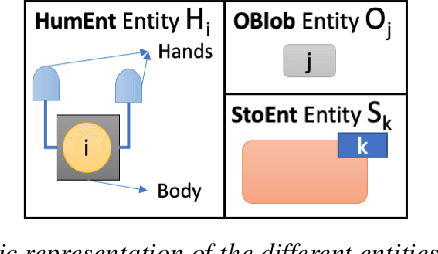
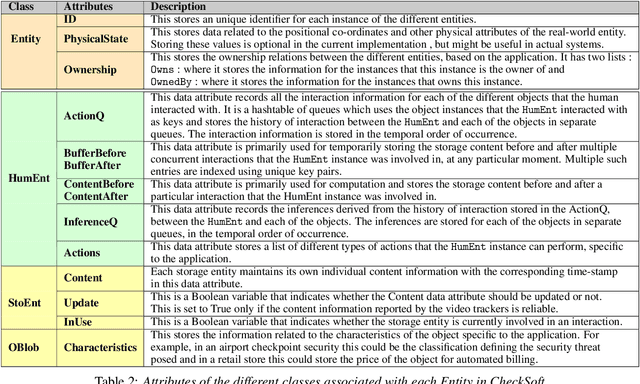
We present CheckSoft, a scalable event-driven software architecture for keeping track of people-object interactions in people-centric applications such as airport checkpoint security areas, automated retail stores, smart libraries, and so on. The architecture works off the video data generated in real time by a network of surveillance cameras. Although there are many different aspects to automating these applications, the most difficult part of the overall problem is keeping track of the interactions between the people and the objects. CheckSoft uses finite-state-machine (FSM) based logic for keeping track of such interactions which allows the system to quickly reject any false detections of the interactions by the video cameras. CheckSoft is easily scalable since the architecture is based on multi-processing in which a separate process is assigned to each human and to each "storage container" for the objects. A storage container may be a shelf on which the objects are displayed or a bin in which the objects are stored, depending on the specific application in which CheckSoft is deployed.
Semantic Labeling of Large-Area Geographic Regions Using Multi-View and Multi-Date Satellite Images, and Noisy OSM Training Labels
Aug 24, 2020



We present a novel multi-view training framework and CNN architecture for combining information from multiple overlapping satellite images and noisy training labels derived from OpenStreetMap (OSM) for semantic labeling of buildings and roads across large geographic regions (100 km$^2$). Our approach to multi-view semantic segmentation yields a 4-7% improvement in the per-class IoU scores compared to the traditional approaches that use the views independently of one another. A unique (and, perhaps, surprising) property of our system is that modifications that are added to the tail-end of the CNN for learning from the multi-view data can be discarded at the time of inference with a relatively small penalty in the overall performance. This implies that the benefits of training using multiple views are absorbed by all the layers of the network. Additionally, our approach only adds a small overhead in terms of the GPU-memory consumption even when training with as many as 32 views per scene. The system we present is end-to-end automated, which facilitates comparing the classifiers trained directly on true orthophotos vis-a-vis first training them on the off-nadir images and subsequently translating the predicted labels to geographical coordinates. With no human supervision, our IoU scores for the buildings and roads classes are 0.8 and 0.64 respectively which are better than state-of-the-art approaches that use OSM labels and that are not completely automated.
A New Stereo Benchmarking Dataset for Satellite Images
Jul 09, 2019
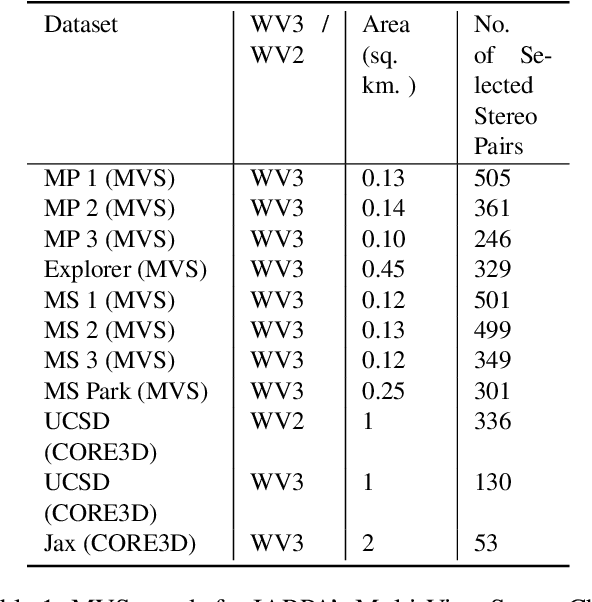

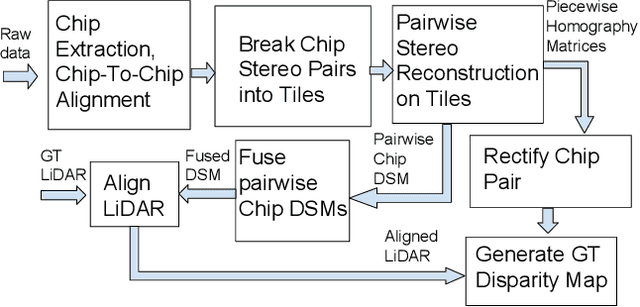
In order to facilitate further research in stereo reconstruction with multi-date satellite images, the goal of this paper is to provide a set of stereo-rectified images and the associated groundtruthed disparities for 10 AOIs (Area of Interest) drawn from two sources: 8 AOIs from IARPA's MVS Challenge dataset and 2 AOIs from the CORE3D-Public dataset. The disparities were groundtruthed by first constructing a fused DSM from the stereo pairs and by aligning 30 cm LiDAR with the fused DSM. Unlike the existing benckmarking datasets, we have also carried out a quantitative evaluation of our groundtruthed disparities using human annotated points in two of the AOIs. Additionally, the rectification accuracy in our dataset is comparable to the same in the existing state-of-the-art stereo datasets. In general, we have used the WorldView-3 (WV3) images for the dataset, the exception being the UCSD area for which we have used both WV3 and WorldView-2 (WV2) images. All of the dataset images are now in the public domain. Since multi-date satellite images frequently include images acquired in different seasons (which creates challenges in finding corresponding pairs of pixels for stereo), our dataset also includes for each image a building mask over which the disparities estimated by stereo should prove reliable. Additional metadata included in the dataset includes information about each image's acquisition date and time, the azimuth and elevation angles of the camera, and the intersection angles for the two views in a stereo pair. Also included in the dataset are both quantitative and qualitative analyses of the accuracy of the groundtruthed disparity maps. Our dataset is available for download at \url{https://engineering.purdue.edu/RVL/Database/SatStereo/index.html}
Adaptive Target Recognition: A Case Study Involving Airport Baggage Screening
Nov 30, 2018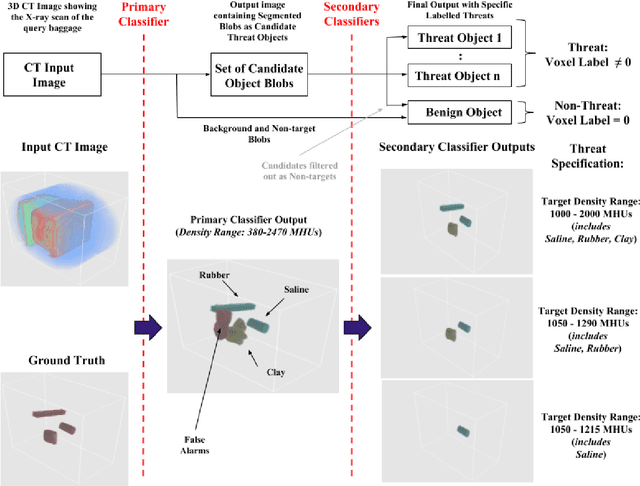
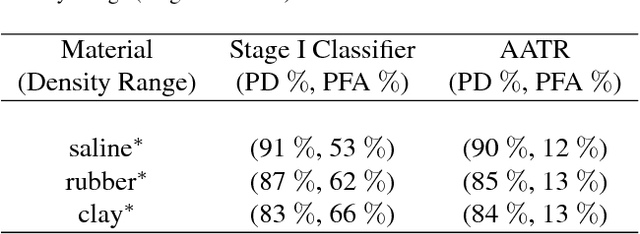
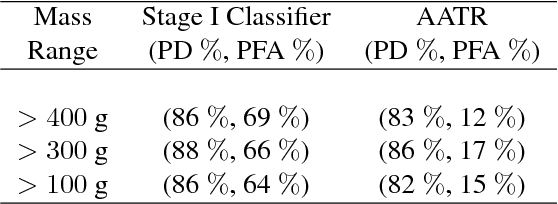
This work addresses the question whether it is possible to design a computer-vision based automatic threat recognition (ATR) system so that it can adapt to changing specifications of a threat without having to create a new ATR each time. The changes in threat specifications, which may be warranted by intelligence reports and world events, are typically regarding the physical characteristics of what constitutes a threat: its material composition, its shape, its method of concealment, etc. Here we present our design of an AATR system (Adaptive ATR) that can adapt to changing specifications in materials characterization (meaning density, as measured by its x-ray attenuation coefficient), its mass, and its thickness. Our design uses a two-stage cascaded approach, in which the first stage is characterized by a high recall rate over the entire range of possibilities for the threat parameters that are allowed to change. The purpose of the second stage is to then fine-tune the performance of the overall system for the current threat specifications. The computational effort for this fine-tuning for achieving a desired PD/PFA rate is far less than what it would take to create a new classifier with the same overall performance for the new set of threat specifications.
RMPD - A Recursive Mid-Point Displacement Algorithm for Path Planning
Feb 26, 2018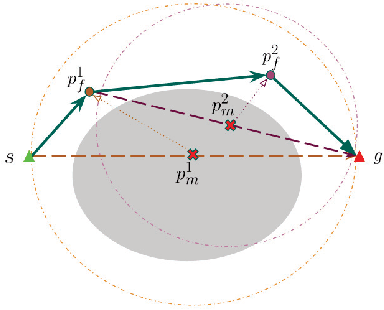
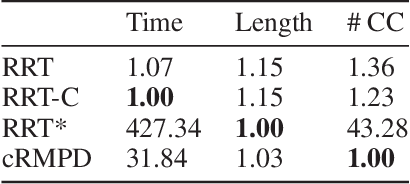
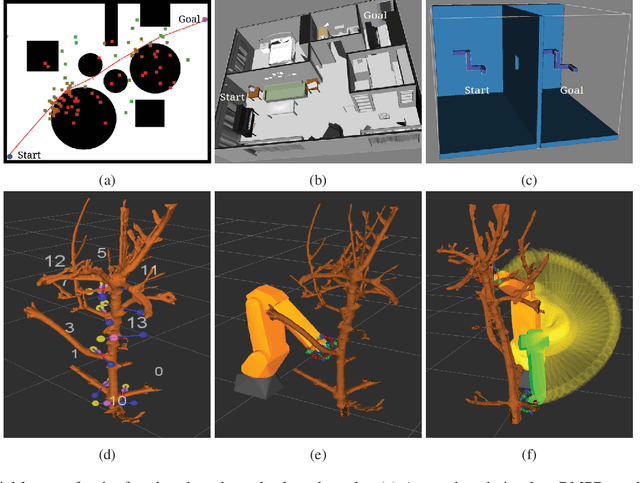
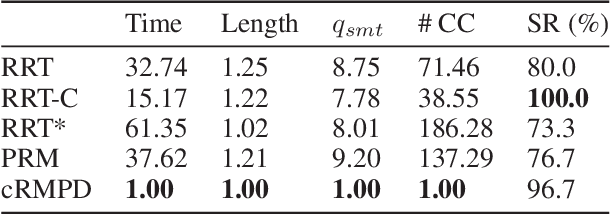
Motivated by what is required for real-time path planning, the paper starts out by presenting sRMPD, a new recursive "local" planner founded on the key notion that, unless made necessary by an obstacle, there must be no deviation from the shortest path between any two points, which would normally be a straight line path in the configuration space. Subsequently, we increase the power of sRMPD by using it as a "connect" subroutine call in a higher-level sampling-based algorithm mRMPD that is inspired by multi-RRT. As a consequence, mRMPD spawns a larger number of space exploring trees in regions of the configuration space that are characterized by a higher density of obstacles. The overall effect is a hybrid tree growing strategy with a trade-off between random exploration as made possible by multi-RRT based logic and immediate exploitation of opportunities to connect two states as made possible by sRMPD. The mRMPD planner can be biased with regard to this trade-off for solving different kinds of planning problems efficiently. Based on the test cases we have run, our experiments show that mRMPD can reduce planning time by up to 80% compared to basic RRT.