 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiMask: Leveraging Epipolar Distance Based Masks in Cross-Attention for Satellite Image Matching
Mar 23, 2026The deep-learning based image matching networks can now handle significantly larger variations in viewpoints and illuminations while providing matched pairs of pixels with sub-pixel precision. These networks have been trained with ground-based image datasets and, implicitly, their performance is optimized for the pinhole camera geometry. Consequently, you get suboptimal performance when such networks are used to match satellite images since those images are synthesized as a moving satellite camera records one line at a time of the points on the ground. In this paper, we present EpiMask, a semi-dense image matching network for satellite images that (1) Incorporates patch-wise affine approximations to the camera modeling geometry; (2) Uses an epipolar distance-based attention mask to restrict cross-attention to geometrically plausible regions; and (3) That fine-tunes a foundational pretrained image encoder for robust feature extraction. Experiments on the SatDepth dataset demonstrate up to 30% improvement in matching accuracy compared to re-trained ground-based models.
SatDepth: A Novel Dataset for Satellite Image Matching
Mar 17, 2025


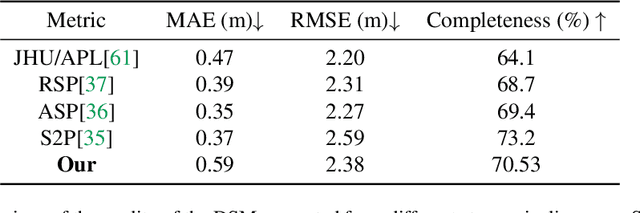
Recent advances in deep-learning based methods for image matching have demonstrated their superiority over traditional algorithms, enabling correspondence estimation in challenging scenes with significant differences in viewing angles, illumination and weather conditions. However, the existing datasets, learning frameworks, and evaluation metrics for the deep-learning based methods are limited to ground-based images recorded with pinhole cameras and have not been explored for satellite images. In this paper, we present ``SatDepth'', a novel dataset that provides dense ground-truth correspondences for training image matching frameworks meant specifically for satellite images. Satellites capture images from various viewing angles and tracks through multiple revisits over a region. To manage this variability, we propose a dataset balancing strategy through a novel image rotation augmentation procedure. This procedure allows for the discovery of corresponding pixels even in the presence of large rotational differences between the images. We benchmark four existing image matching frameworks using our dataset and carry out an ablation study that confirms that the models trained with our dataset with rotation augmentation outperform (up to 40% increase in precision) the models trained with other datasets, especially when there exist large rotational differences between the images.
An Aligned Multi-Temporal Multi-Resolution Satellite Image Dataset for Change Detection Research
Feb 27, 2023This paper presents an aligned multi-temporal and multi-resolution satellite image dataset for research in change detection. We expect our dataset to be useful to researchers who want to fuse information from multiple satellites for detecting changes on the surface of the earth that may not be fully visible in any single satellite. The dataset we present was created by augmenting the SpaceNet-7 dataset with temporally parallel stacks of Landsat and Sentinel images. The SpaceNet-7 dataset consists of time-sequenced Planet images recorded over 101 AOIs (Areas-of-Interest). In our dataset, for each of the 60 AOIs that are meant for training, we augment the Planet datacube with temporally parallel datacubes of Landsat and Sentinel images. The temporal alignments between the high-res Planet images, on the one hand, and the Landsat and Sentinel images, on the other, are approximate since the temporal resolution for the Planet images is one month -- each image being a mosaic of the best data collected over a month. Whenever we have a choice regarding which Landsat and Sentinel images to pair up with the Planet images, we have chosen those that had the least cloud cover. A particularly important feature of our dataset is that the high-res and the low-res images are spatially aligned together with our MuRA framework presented in this paper. Foundational to the alignment calculation is the modeling of inter-satellite misalignment errors with polynomials as in NASA's AROP algorithm. We have named our dataset MuRA-T for the MuRA framework that is used for aligning the cross-satellite images and "T" for the temporal dimension in the dataset.