 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
Mar 22, 2024
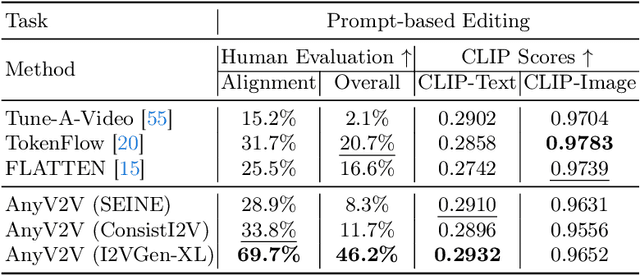
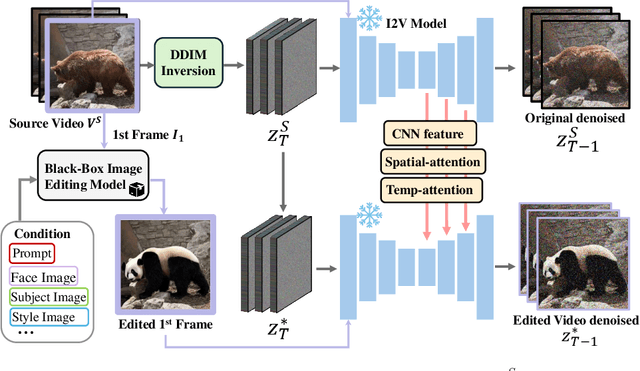
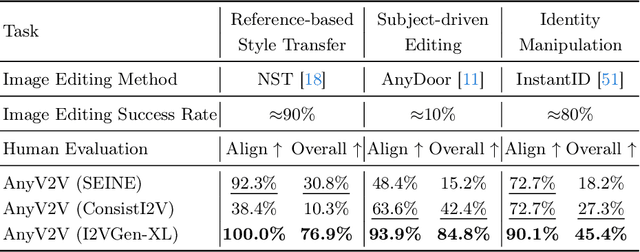

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands. In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection. In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference. On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate the fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.
Learning User Embeddings from Human Gaze for Personalised Saliency Prediction
Mar 26, 2024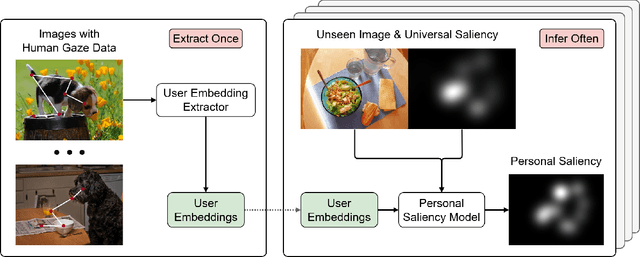
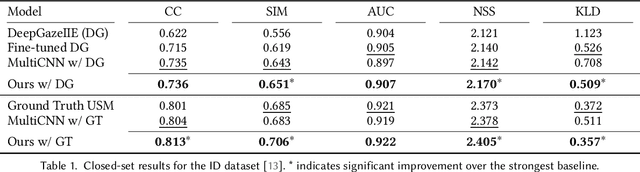
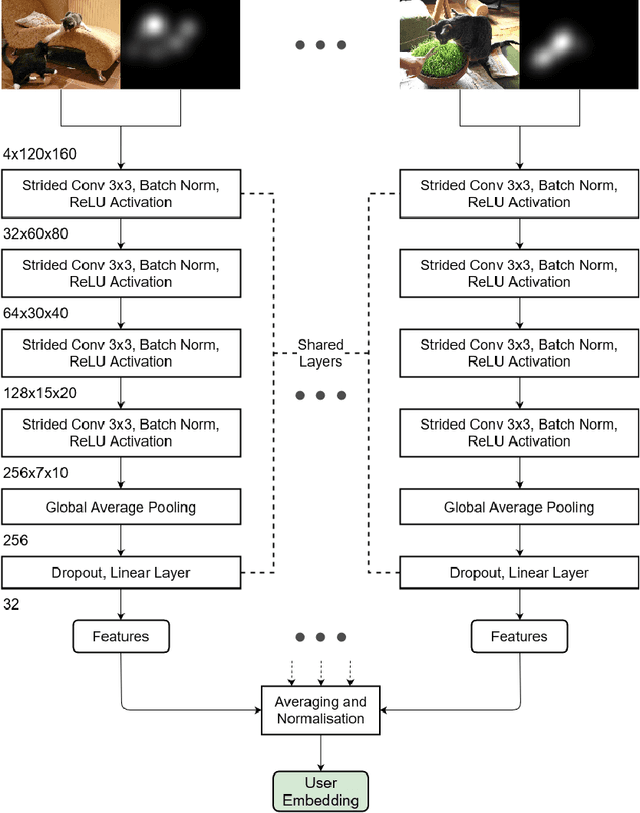
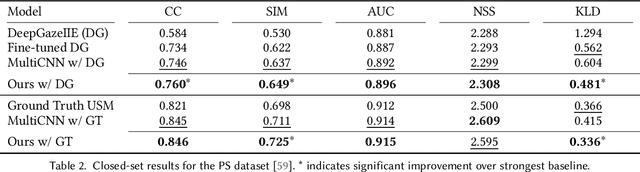
Reusable embeddings of user behaviour have shown significant performance improvements for the personalised saliency prediction task. However, prior works require explicit user characteristics and preferences as input, which are often difficult to obtain. We present a novel method to extract user embeddings from pairs of natural images and corresponding saliency maps generated from a small amount of user-specific eye tracking data. At the core of our method is a Siamese convolutional neural encoder that learns the user embeddings by contrasting the image and personal saliency map pairs of different users. Evaluations on two public saliency datasets show that the generated embeddings have high discriminative power, are effective at refining universal saliency maps to the individual users, and generalise well across users and images. Finally, based on our model's ability to encode individual user characteristics, our work points towards other applications that can benefit from reusable embeddings of gaze behaviour.
DragAPart: Learning a Part-Level Motion Prior for Articulated Objects
Mar 22, 2024We introduce DragAPart, a method that, given an image and a set of drags as input, can generate a new image of the same object in a new state, compatible with the action of the drags. Differently from prior works that focused on repositioning objects, DragAPart predicts part-level interactions, such as opening and closing a drawer. We study this problem as a proxy for learning a generalist motion model, not restricted to a specific kinematic structure or object category. To this end, we start from a pre-trained image generator and fine-tune it on a new synthetic dataset, Drag-a-Move, which we introduce. Combined with a new encoding for the drags and dataset randomization, the new model generalizes well to real images and different categories. Compared to prior motion-controlled generators, we demonstrate much better part-level motion understanding.
Comparison of No-Reference Image Quality Models via MAP Estimation in Diffusion Latents
Mar 11, 2024
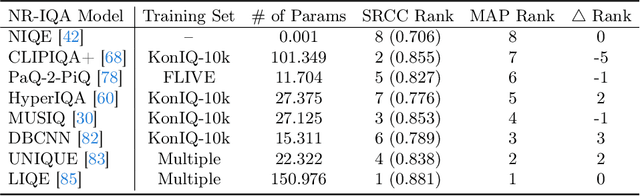


Contemporary no-reference image quality assessment (NR-IQA) models can effectively quantify the perceived image quality, with high correlations between model predictions and human perceptual scores on fixed test sets. However, little progress has been made in comparing NR-IQA models from a perceptual optimization perspective. Here, for the first time, we demonstrate that NR-IQA models can be plugged into the maximum a posteriori (MAP) estimation framework for image enhancement. This is achieved by taking the gradients in differentiable and bijective diffusion latents rather than in the raw pixel domain. Different NR-IQA models are likely to induce different enhanced images, which are ultimately subject to psychophysical testing. This leads to a new computational method for comparing NR-IQA models within the analysis-by-synthesis framework. Compared to conventional correlation-based metrics, our method provides complementary insights into the relative strengths and weaknesses of the competing NR-IQA models in the context of perceptual optimization.
A Bayesian Approach to OOD Robustness in Image Classification
Mar 12, 2024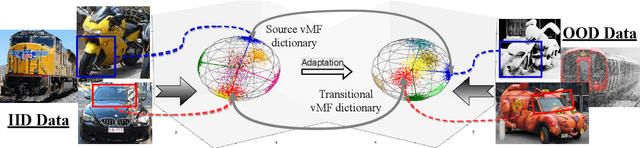
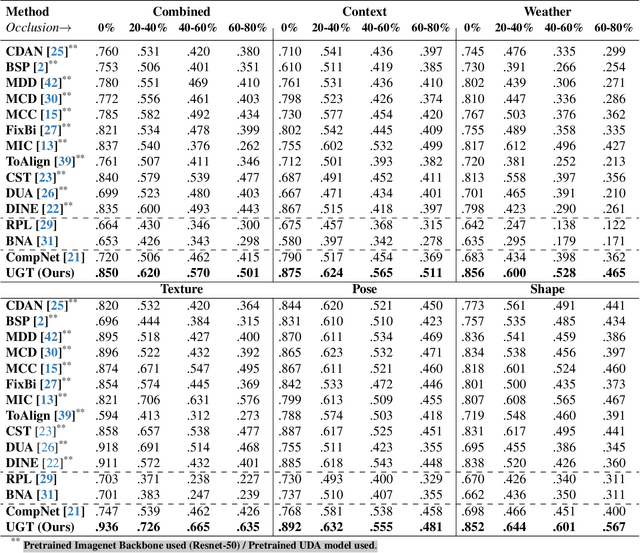
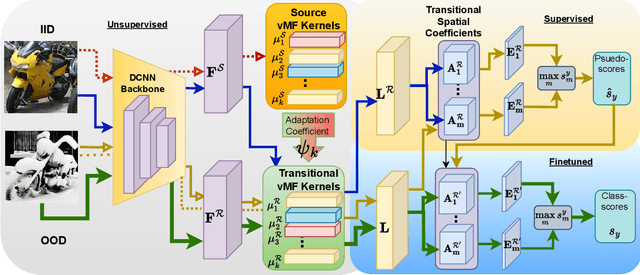
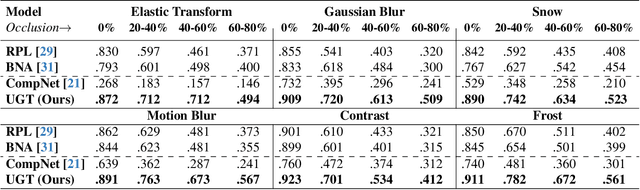
An important and unsolved problem in computer vision is to ensure that the algorithms are robust to changes in image domains. We address this problem in the scenario where we have access to images from the target domains but no annotations. Motivated by the challenges of the OOD-CV benchmark where we encounter real world Out-of-Domain (OOD) nuisances and occlusion, we introduce a novel Bayesian approach to OOD robustness for object classification. Our work extends Compositional Neural Networks (CompNets), which have been shown to be robust to occlusion but degrade badly when tested on OOD data. We exploit the fact that CompNets contain a generative head defined over feature vectors represented by von Mises-Fisher (vMF) kernels, which correspond roughly to object parts, and can be learned without supervision. We obverse that some vMF kernels are similar between different domains, while others are not. This enables us to learn a transitional dictionary of vMF kernels that are intermediate between the source and target domains and train the generative model on this dictionary using the annotations on the source domain, followed by iterative refinement. This approach, termed Unsupervised Generative Transition (UGT), performs very well in OOD scenarios even when occlusion is present. UGT is evaluated on different OOD benchmarks including the OOD-CV dataset, several popular datasets (e.g., ImageNet-C [9]), artificial image corruptions (including adding occluders), and synthetic-to-real domain transfer, and does well in all scenarios outperforming SOTA alternatives (e.g. up to 10% top-1 accuracy on Occluded OOD-CV dataset).
Generalizable Two-Branch Framework for Image Class-Incremental Learning
Mar 13, 2024Deep neural networks often severely forget previously learned knowledge when learning new knowledge. Various continual learning (CL) methods have been proposed to handle such a catastrophic forgetting issue from different perspectives and achieved substantial improvements. In this paper, a novel two-branch continual learning framework is proposed to further enhance most existing CL methods. Specifically, the main branch can be any existing CL model and the newly introduced side branch is a lightweight convolutional network. The output of each main branch block is modulated by the output of the corresponding side branch block. Such a simple two-branch model can then be easily implemented and learned with the vanilla optimization setting without whistles and bells. Extensive experiments with various settings on multiple image datasets show that the proposed framework yields consistent improvements over state-of-the-art methods.
DivCon: Divide and Conquer for Progressive Text-to-Image Generation
Mar 11, 2024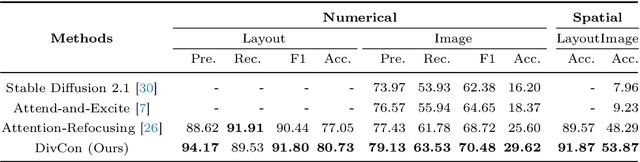

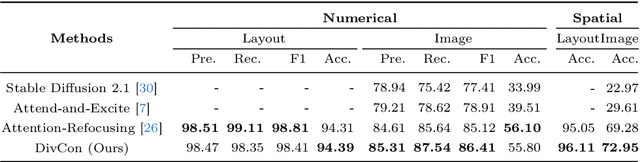
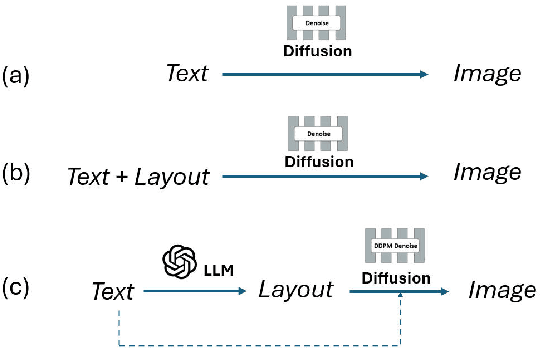
Diffusion-driven text-to-image (T2I) generation has achieved remarkable advancements. To further improve T2I models' capability in numerical and spatial reasoning, the layout is employed as an intermedium to bridge large language models and layout-based diffusion models. However, these methods still struggle with generating images from textural prompts with multiple objects and complicated spatial relationships. To tackle this challenge, we introduce a divide-and-conquer approach which decouples the T2I generation task into simple subtasks. Our approach divides the layout prediction stage into numerical \& spatial reasoning and bounding box prediction. Then, the layout-to-image generation stage is conducted in an iterative manner to reconstruct objects from easy ones to difficult ones. We conduct experiments on the HRS and NSR-1K benchmarks and our approach outperforms previous state-of-the-art models with notable margins. In addition, visual results demonstrate that our approach significantly improves the controllability and consistency in generating multiple objects from complex textural prompts.
Robust Diffusion Models for Adversarial Purification
Mar 24, 2024Diffusion models (DMs) based adversarial purification (AP) has shown to be the most powerful alternative to adversarial training (AT). However, these methods neglect the fact that pre-trained diffusion models themselves are not robust to adversarial attacks as well. Additionally, the diffusion process can easily destroy semantic information and generate a high quality image but totally different from the original input image after the reverse process, leading to degraded standard accuracy. To overcome these issues, a natural idea is to harness adversarial training strategy to retrain or fine-tune the pre-trained diffusion model, which is computationally prohibitive. We propose a novel robust reverse process with adversarial guidance, which is independent of given pre-trained DMs and avoids retraining or fine-tuning the DMs. This robust guidance can not only ensure to generate purified examples retaining more semantic content but also mitigate the accuracy-robustness trade-off of DMs for the first time, which also provides DM-based AP an efficient adaptive ability to new attacks. Extensive experiments are conducted to demonstrate that our method achieves the state-of-the-art results and exhibits generalization against different attacks.
Mars Spectrometry 2: Gas Chromatography -- Second place solution
Mar 24, 2024The Mars Spectrometry 2: Gas Chromatography challenge was sponsored by NASA and run on the DrivenData competition platform in 2022. This report describes the solution which achieved the second-best score on the competition's test dataset. The solution utilized two-dimensional, image-like representations of the competition's chromatography data samples. A number of different Convolutional Neural Network models were trained and ensembled for the final submission.
SemRoDe: Macro Adversarial Training to Learn Representations That are Robust to Word-Level Attacks
Mar 27, 2024Language models (LMs) are indispensable tools for natural language processing tasks, but their vulnerability to adversarial attacks remains a concern. While current research has explored adversarial training techniques, their improvements to defend against word-level attacks have been limited. In this work, we propose a novel approach called Semantic Robust Defence (SemRoDe), a Macro Adversarial Training strategy to enhance the robustness of LMs. Drawing inspiration from recent studies in the image domain, we investigate and later confirm that in a discrete data setting such as language, adversarial samples generated via word substitutions do indeed belong to an adversarial domain exhibiting a high Wasserstein distance from the base domain. Our method learns a robust representation that bridges these two domains. We hypothesize that if samples were not projected into an adversarial domain, but instead to a domain with minimal shift, it would improve attack robustness. We align the domains by incorporating a new distance-based objective. With this, our model is able to learn more generalized representations by aligning the model's high-level output features and therefore better handling unseen adversarial samples. This method can be generalized across word embeddings, even when they share minimal overlap at both vocabulary and word-substitution levels. To evaluate the effectiveness of our approach, we conduct experiments on BERT and RoBERTa models on three datasets. The results demonstrate promising state-of-the-art robustness.