 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DGC-GNN: Descriptor-free Geometric-Color Graph Neural Network for 2D-3D Matching
Jun 21, 2023

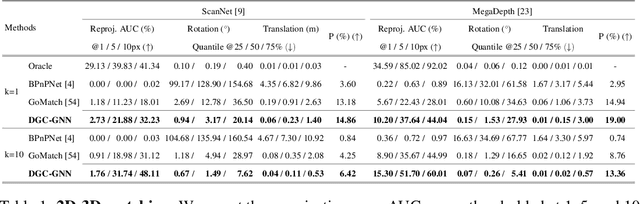


Direct matching of 2D keypoints in an input image to a 3D point cloud of the scene without requiring visual descriptors has garnered increased interest due to its lower memory requirements, inherent privacy preservation, and reduced need for expensive 3D model maintenance compared to visual descriptor-based methods. However, existing algorithms often compromise on performance, resulting in a significant deterioration compared to their descriptor-based counterparts. In this paper, we introduce DGC-GNN, a novel algorithm that employs a global-to-local Graph Neural Network (GNN) that progressively exploits geometric and color cues to represent keypoints, thereby improving matching robustness. Our global-to-local procedure encodes both Euclidean and angular relations at a coarse level, forming the geometric embedding to guide the local point matching. We evaluate DGC-GNN on both indoor and outdoor datasets, demonstrating that it not only doubles the accuracy of the state-of-the-art descriptor-free algorithm but, also, substantially narrows the performance gap between descriptor-based and descriptor-free methods. The code and trained models will be made publicly available.
Polygon Detection for Room Layout Estimation using Heterogeneous Graphs and Wireframes
Jun 21, 2023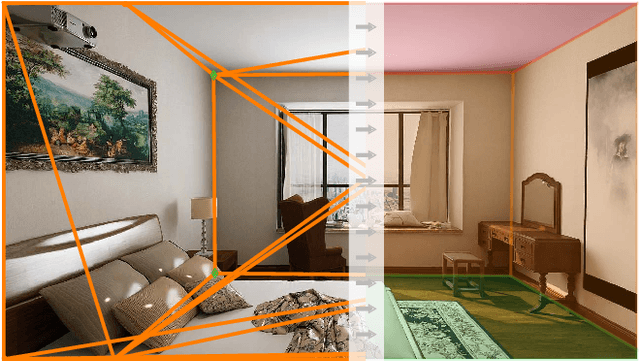
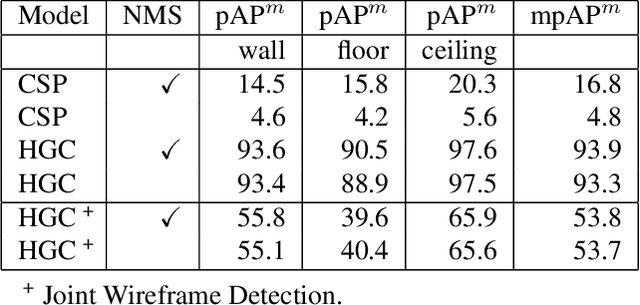
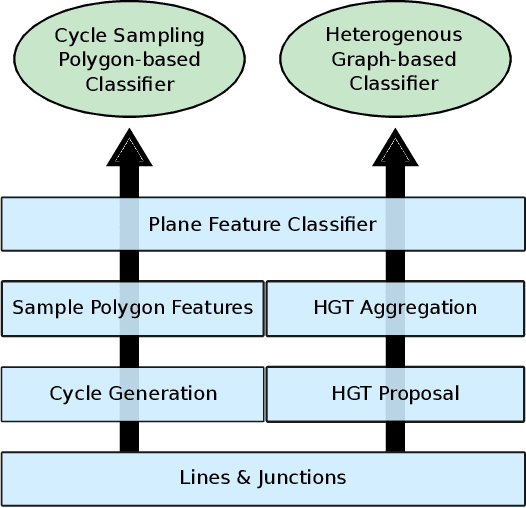

This paper presents a neural network based semantic plane detection method utilizing polygon representations. The method can for example be used to solve room layout estimations tasks. The method is built on, combines and further develops several different modules from previous research. The network takes an RGB image and estimates a wireframe as well as a feature space using an hourglass backbone. From these, line and junction features are sampled. The lines and junctions are then represented as an undirected graph, from which polygon representations of the sought planes are obtained. Two different methods for this last step are investigated, where the most promising method is built on a heterogeneous graph transformer. The final output is in all cases a projection of the semantic planes in 2D. The methods are evaluated on the Structured 3D dataset and we investigate the performance both using sampled and estimated wireframes. The experiments show the potential of the graph-based method by outperforming state of the art methods in Room Layout estimation in the 2D metrics using synthetic wireframe detections.
Training Transformers with 4-bit Integers
Jun 21, 2023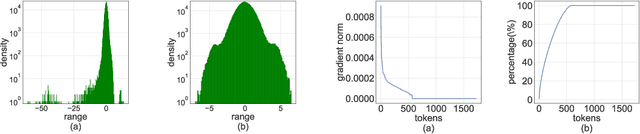
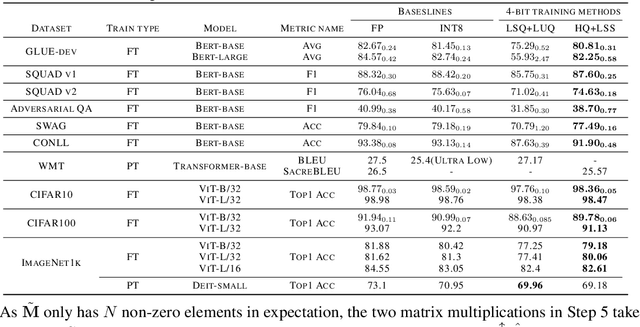
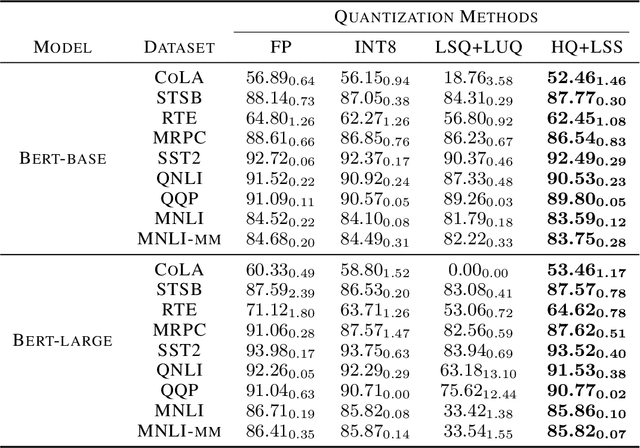
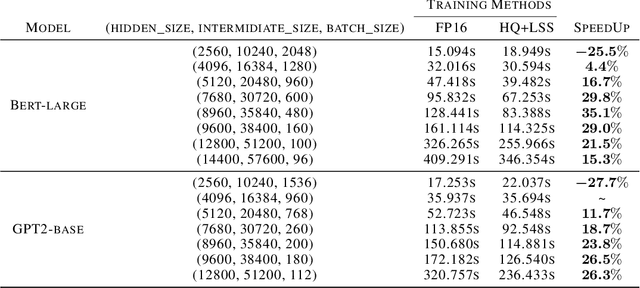
Quantizing the activation, weight, and gradient to 4-bit is promising to accelerate neural network training. However, existing 4-bit training methods require custom numerical formats which are not supported by contemporary hardware. In this work, we propose a training method for transformers with all matrix multiplications implemented with the INT4 arithmetic. Training with an ultra-low INT4 precision is challenging. To achieve this, we carefully analyze the specific structures of activation and gradients in transformers to propose dedicated quantizers for them. For forward propagation, we identify the challenge of outliers and propose a Hadamard quantizer to suppress the outliers. For backpropagation, we leverage the structural sparsity of gradients by proposing bit splitting and leverage score sampling techniques to quantize gradients accurately. Our algorithm achieves competitive accuracy on a wide range of tasks including natural language understanding, machine translation, and image classification. Unlike previous 4-bit training methods, our algorithm can be implemented on the current generation of GPUs. Our prototypical linear operator implementation is up to 2.2 times faster than the FP16 counterparts and speeds up the training by up to 35.1%.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023

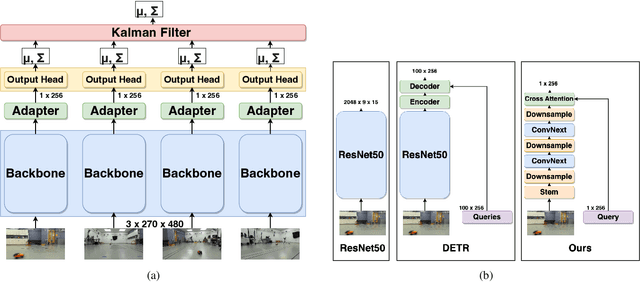
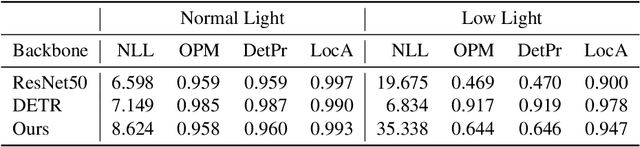
Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
ORRN: An ODE-based Recursive Registration Network for Deformable Respiratory Motion Estimation with Lung 4DCT Images
May 24, 2023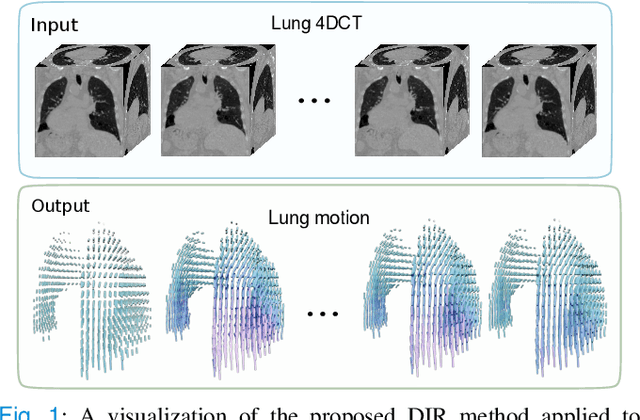
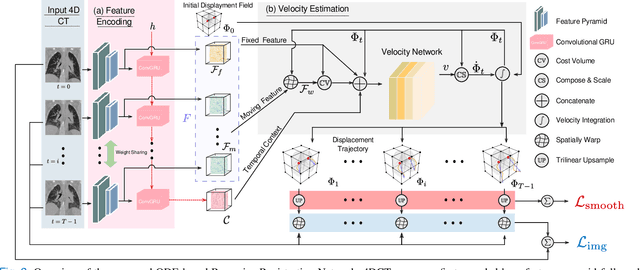
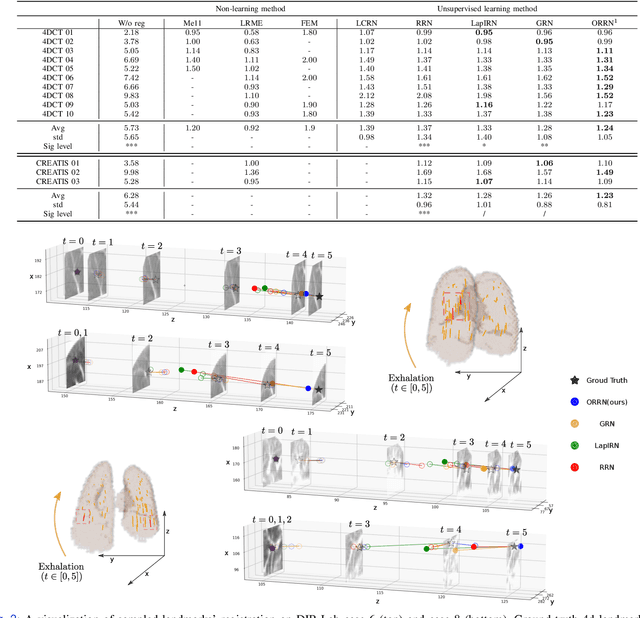
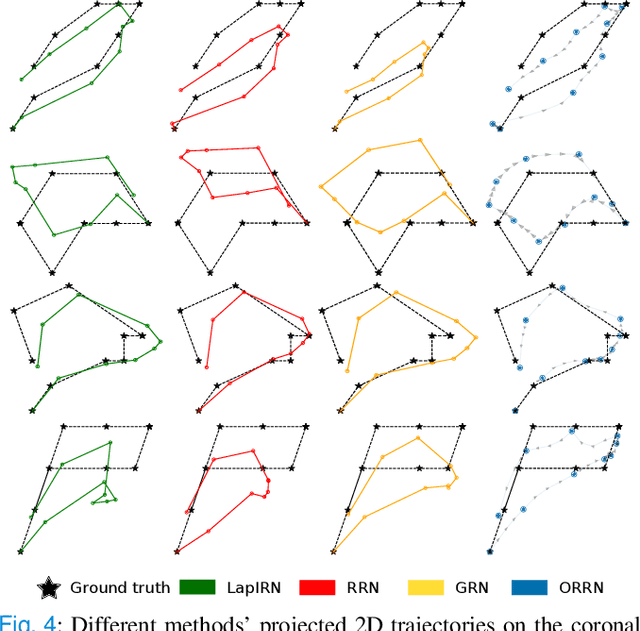
Deformable Image Registration (DIR) plays a significant role in quantifying deformation in medical data. Recent Deep Learning methods have shown promising accuracy and speedup for registering a pair of medical images. However, in 4D (3D + time) medical data, organ motion, such as respiratory motion and heart beating, can not be effectively modeled by pair-wise methods as they were optimized for image pairs but did not consider the organ motion patterns necessary when considering 4D data. This paper presents ORRN, an Ordinary Differential Equations (ODE)-based recursive image registration network. Our network learns to estimate time-varying voxel velocities for an ODE that models deformation in 4D image data. It adopts a recursive registration strategy to progressively estimate a deformation field through ODE integration of voxel velocities. We evaluate the proposed method on two publicly available lung 4DCT datasets, DIRLab and CREATIS, for two tasks: 1) registering all images to the extreme inhale image for 3D+t deformation tracking and 2) registering extreme exhale to inhale phase images. Our method outperforms other learning-based methods in both tasks, producing the smallest Target Registration Error of 1.24mm and 1.26mm, respectively. Additionally, it produces less than 0.001\% unrealistic image folding, and the computation speed is less than 1 second for each CT volume. ORRN demonstrates promising registration accuracy, deformation plausibility, and computation efficiency on group-wise and pair-wise registration tasks. It has significant implications in enabling fast and accurate respiratory motion estimation for treatment planning in radiation therapy or robot motion planning in thoracic needle insertion.
Exploring Resiliency to Natural Image Corruptions in Deep Learning using Design Diversity
Mar 15, 2023

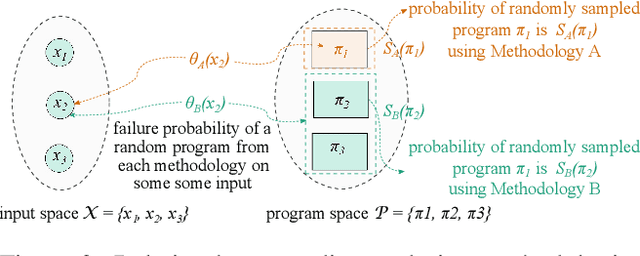
In this paper, we investigate the relationship between diversity metrics, accuracy, and resiliency to natural image corruptions of Deep Learning (DL) image classifier ensembles. We investigate the potential of an attribution-based diversity metric to improve the known accuracy-diversity trade-off of the typical prediction-based diversity. Our motivation is based on analytical studies of design diversity that have shown that a reduction of common failure modes is possible if diversity of design choices is achieved. Using ResNet50 as a comparison baseline, we evaluate the resiliency of multiple individual DL model architectures against dataset distribution shifts corresponding to natural image corruptions. We compare ensembles created with diverse model architectures trained either independently or through a Neural Architecture Search technique and evaluate the correlation of prediction-based and attribution-based diversity to the final ensemble accuracy. We evaluate a set of diversity enforcement heuristics based on negative correlation learning to assess the final ensemble resilience to natural image corruptions and inspect the resulting prediction, activation, and attribution diversity. Our key observations are: 1) model architecture is more important for resiliency than model size or model accuracy, 2) attribution-based diversity is less negatively correlated to the ensemble accuracy than prediction-based diversity, 3) a balanced loss function of individual and ensemble accuracy creates more resilient ensembles for image natural corruptions, 4) architecture diversity produces more diversity in all explored diversity metrics: predictions, attributions, and activations.
HST-MRF: Heterogeneous Swin Transformer with Multi-Receptive Field for Medical Image Segmentation
Apr 10, 2023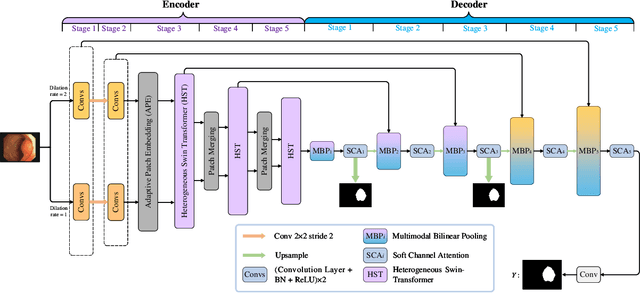
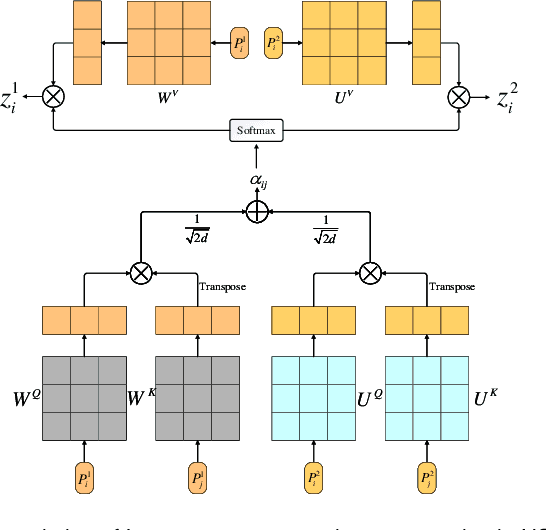
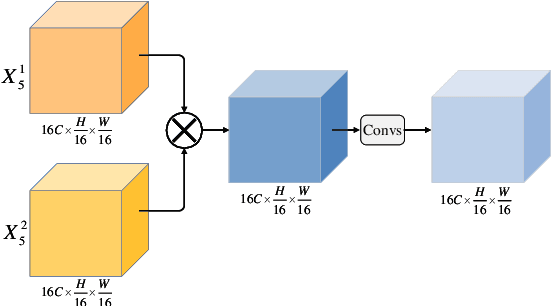
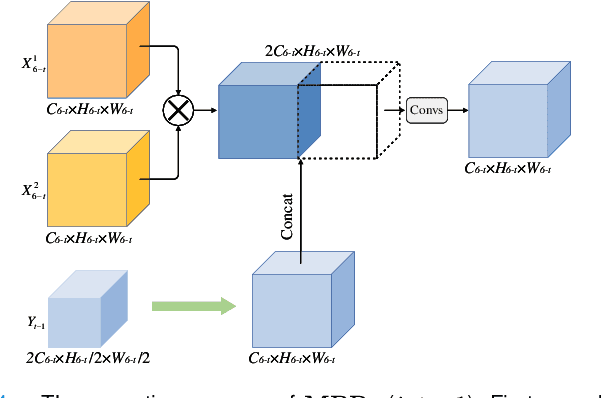
The Transformer has been successfully used in medical image segmentation due to its excellent long-range modeling capabilities. However, patch segmentation is necessary when building a Transformer class model. This process may disrupt the tissue structure in medical images, resulting in the loss of relevant information. In this study, we proposed a Heterogeneous Swin Transformer with Multi-Receptive Field (HST-MRF) model based on U-shaped networks for medical image segmentation. The main purpose is to solve the problem of loss of structural information caused by patch segmentation using transformer by fusing patch information under different receptive fields. The heterogeneous Swin Transformer (HST) is the core module, which achieves the interaction of multi-receptive field patch information through heterogeneous attention and passes it to the next stage for progressive learning. We also designed a two-stage fusion module, multimodal bilinear pooling (MBP), to assist HST in further fusing multi-receptive field information and combining low-level and high-level semantic information for accurate localization of lesion regions. In addition, we developed adaptive patch embedding (APE) and soft channel attention (SCA) modules to retain more valuable information when acquiring patch embedding and filtering channel features, respectively, thereby improving model segmentation quality. We evaluated HST-MRF on multiple datasets for polyp and skin lesion segmentation tasks. Experimental results show that our proposed method outperforms state-of-the-art models and can achieve superior performance. Furthermore, we verified the effectiveness of each module and the benefits of multi-receptive field segmentation in reducing the loss of structural information through ablation experiments.
Hyperspectral Image Analysis with Subspace Learning-based One-Class Classification
Apr 19, 2023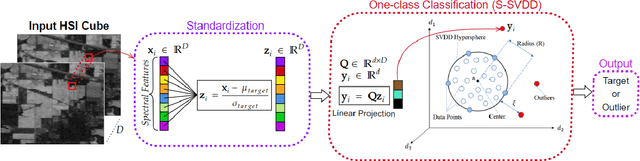

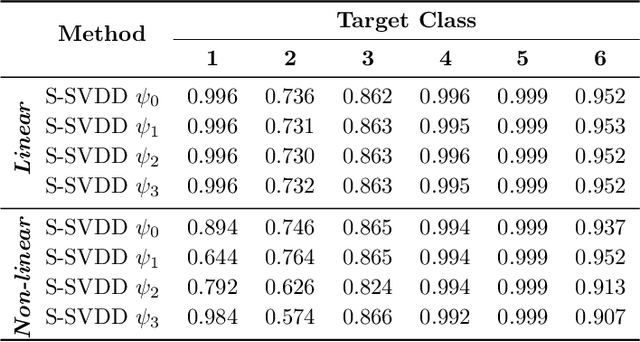
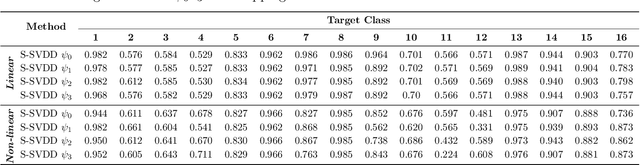
Hyperspectral image (HSI) classification is an important task in many applications, such as environmental monitoring, medical imaging, and land use/land cover (LULC) classification. Due to the significant amount of spectral information from recent HSI sensors, analyzing the acquired images is challenging using traditional Machine Learning (ML) methods. As the number of frequency bands increases, the required number of training samples increases exponentially to achieve a reasonable classification accuracy, also known as the curse of dimensionality. Therefore, separate band selection or dimensionality reduction techniques are often applied before performing any classification task over HSI data. In this study, we investigate recently proposed subspace learning methods for one-class classification (OCC). These methods map high-dimensional data to a lower-dimensional feature space that is optimized for one-class classification. In this way, there is no separate dimensionality reduction or feature selection procedure needed in the proposed classification framework. Moreover, one-class classifiers have the ability to learn a data description from the category of a single class only. Considering the imbalanced labels of the LULC classification problem and rich spectral information (high number of dimensions), the proposed classification approach is well-suited for HSI data. Overall, this is a pioneer study focusing on subspace learning-based one-class classification for HSI data. We analyze the performance of the proposed subspace learning one-class classifiers in the proposed pipeline. Our experiments validate that the proposed approach helps tackle the curse of dimensionality along with the imbalanced nature of HSI data.
Enhancement of theColor Image Compression Using a New Algorithm based on Discrete Hermite Wavelet Transform
Mar 23, 2023
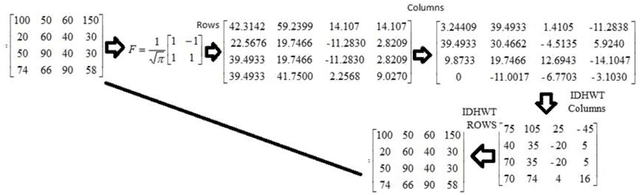
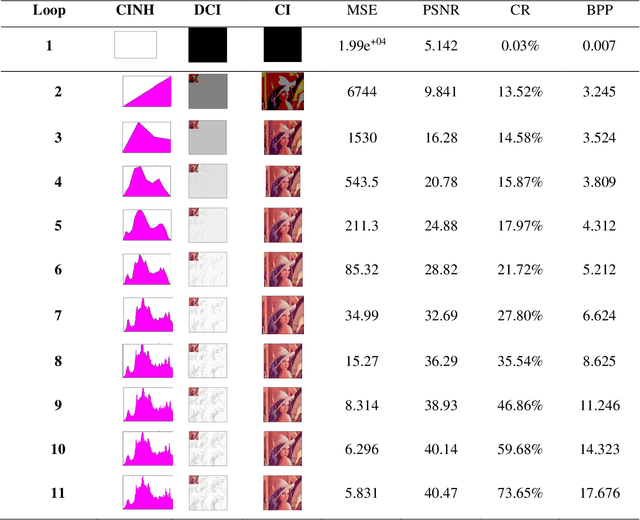
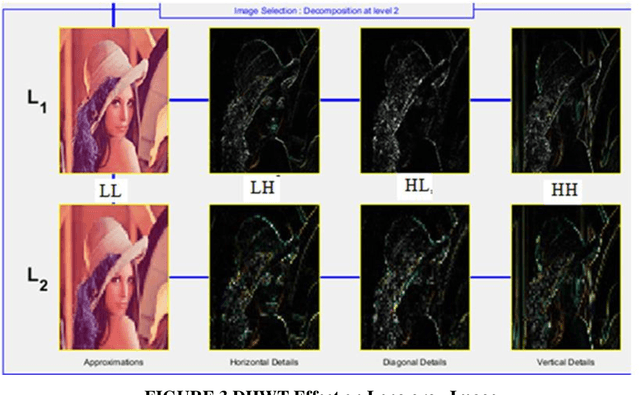
The Internet has turned the entire world into a small village;this is because it has made it possible to share millions of images and videos. However, sending and receiving a huge amount of data is considered to be a main challenge. To address this issue, a new algorithm is required to reduce image bits and represent the data in a compressed form. Nevertheless, image compression is an important application for transferring large files and images. This requires appropriate and efficient transfers in this field to achieve the task and reach the best results. In this work, we propose a new algorithm based on discrete Hermite wavelets transformation (DHWT) that shows the efficiency and quality of the color images. By compressing the color image, this method analyzes it and divides it into approximate coefficients and detail coefficients after adding the wavelets into MATLAB. With Multi-Resolution Analyses (MRA), the appropriate filter is derived, and the mathematical aspects prove to be validated by testing a new filter and performing its operation. After the decomposition of the rows and upon the process of the reconstruction, taking the inverse of the filter and dealing with the columns of the matrix, the original matrix is improved by measuring the parameters of the image to achieve the best quality of the resulting image, such as the peak signal-to-noise ratio (PSNR), compression ratio (CR), bits per pixel (BPP), and mean square error (MSE).
Prompt Performance Prediction for Generative IR
Jun 15, 2023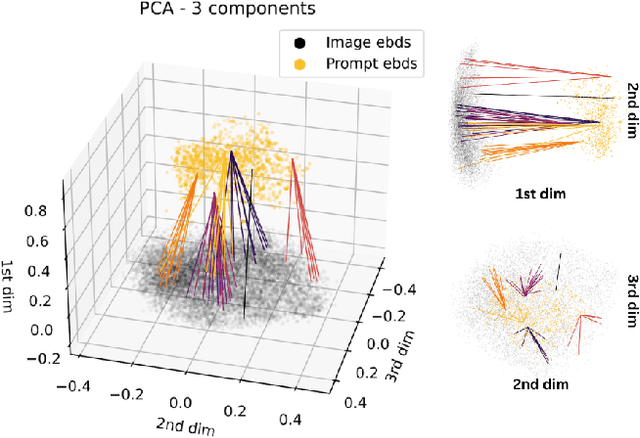

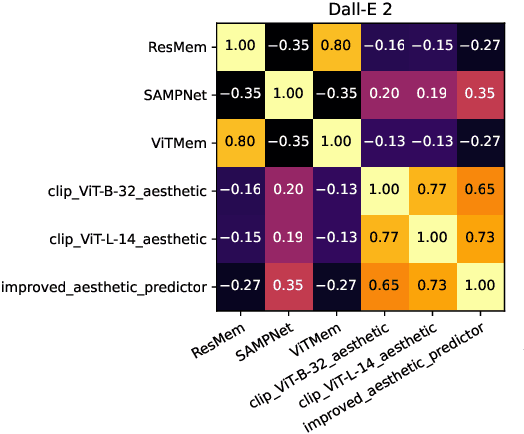
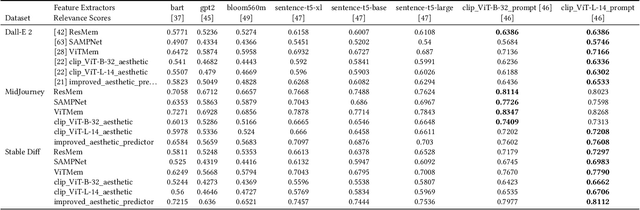
The ability to predict the performance of a query in Information Retrieval (IR) systems has been a longstanding challenge. In this paper, we introduce a novel task called "Prompt Performance Prediction" that aims to predict the performance of a query, referred to as a prompt, before obtaining the actual search results. The context of our task leverages a generative model as an IR engine to evaluate the prompts' performance on image retrieval tasks. We demonstrate the plausibility of our task by measuring the correlation coefficient between predicted and actual performance scores across three datasets containing pairs of prompts and generated images. Our results show promising performance prediction capabilities, suggesting potential applications for optimizing generative IR systems.