 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time GeoAI for High-resolution Mapping and Segmentation of Arctic Permafrost Features
Jun 08, 2023
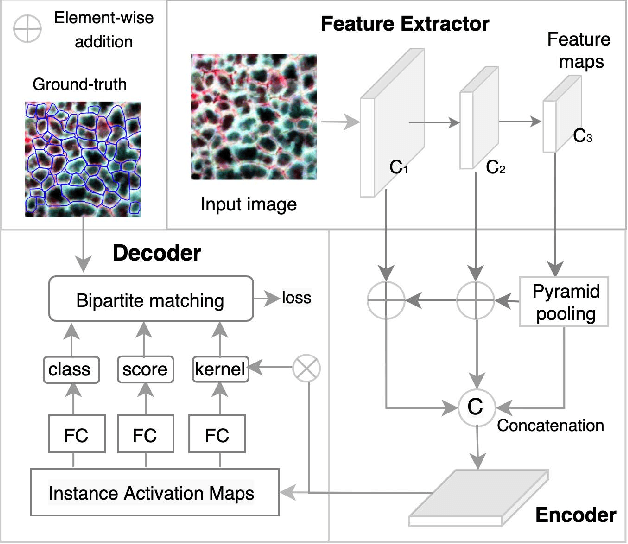
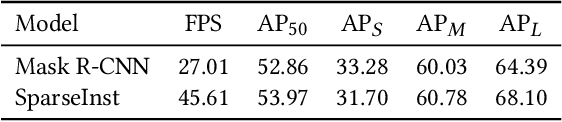
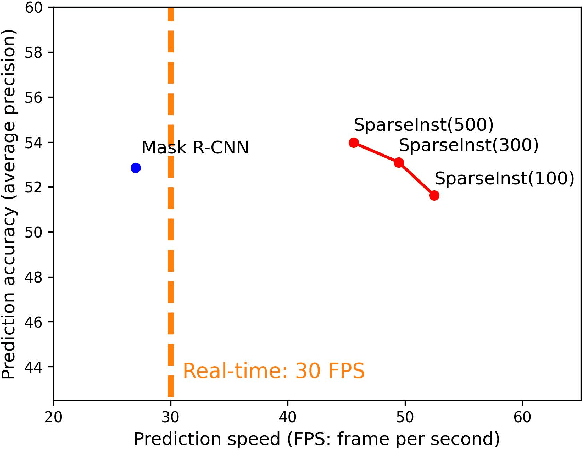

This paper introduces a real-time GeoAI workflow for large-scale image analysis and the segmentation of Arctic permafrost features at a fine-granularity. Very high-resolution (0.5m) commercial imagery is used in this analysis. To achieve real-time prediction, our workflow employs a lightweight, deep learning-based instance segmentation model, SparseInst, which introduces and uses Instance Activation Maps to accurately locate the position of objects within the image scene. Experimental results show that the model can achieve better accuracy of prediction at a much faster inference speed than the popular Mask-RCNN model.
SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation
Jul 03, 2023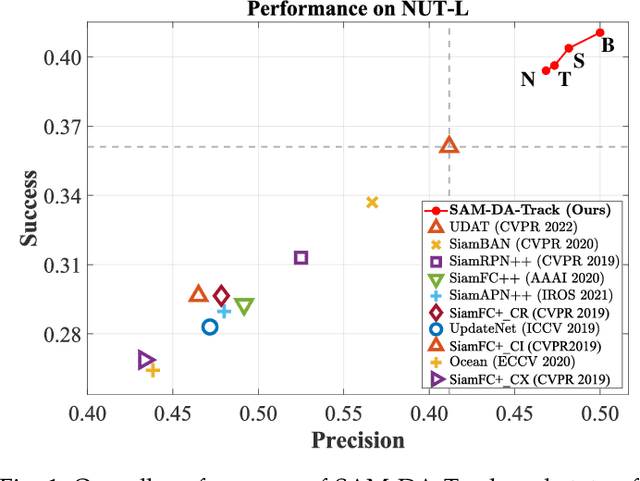

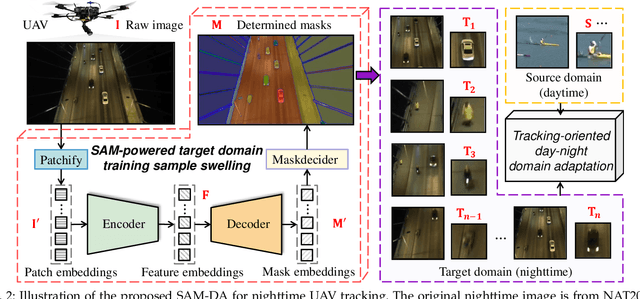

Domain adaptation (DA) has demonstrated significant promise for real-time nighttime unmanned aerial vehicle (UAV) tracking. However, the state-of-the-art (SOTA) DA still lacks the potential object with accurate pixel-level location and boundary to generate the high-quality target domain training sample. This key issue constrains the transfer learning of the real-time daytime SOTA trackers for challenging nighttime UAV tracking. Recently, the notable Segment Anything Model (SAM) has achieved remarkable zero-shot generalization ability to discover abundant potential objects due to its huge data-driven training approach. To solve the aforementioned issue, this work proposes a novel SAM-powered DA framework for real-time nighttime UAV tracking, i.e., SAM-DA. Specifically, an innovative SAM-powered target domain training sample swelling is designed to determine enormous high-quality target domain training samples from every single raw nighttime image. This novel one-to-many method significantly expands the high-quality target domain training sample for DA. Comprehensive experiments on extensive nighttime UAV videos prove the robustness and domain adaptability of SAM-DA for nighttime UAV tracking. Especially, compared to the SOTA DA, SAM-DA can achieve better performance with fewer raw nighttime images, i.e., the fewer-better training. This economized training approach facilitates the quick validation and deployment of algorithms for UAVs. The code is available at https://github.com/vision4robotics/SAM-DA.
Structured Network Pruning by Measuring Filter-wise Interactions
Jul 03, 2023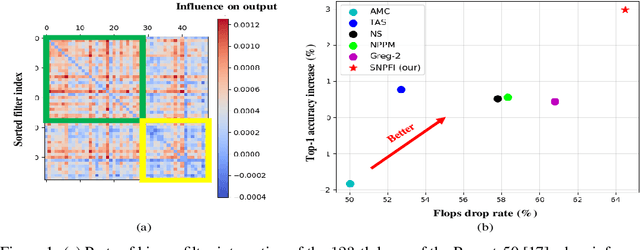
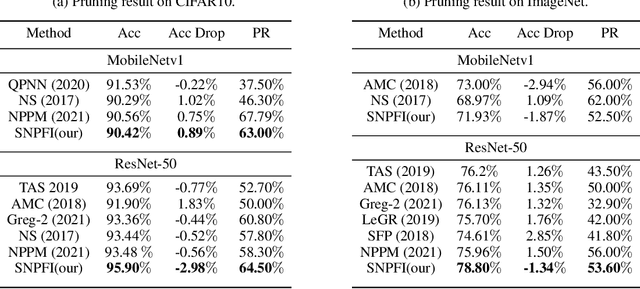
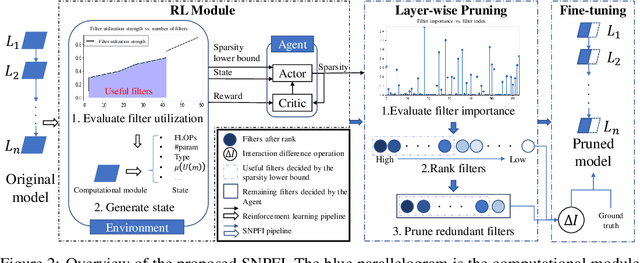
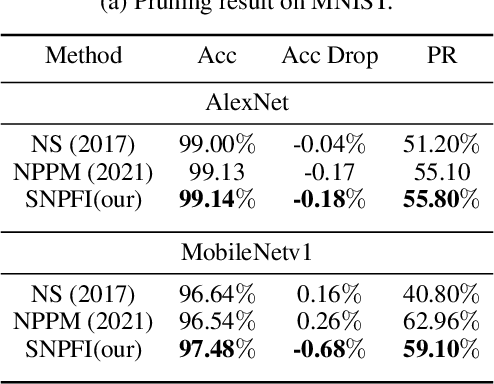
Structured network pruning is a practical approach to reduce computation cost directly while retaining the CNNs' generalization performance in real applications. However, identifying redundant filters is a core problem in structured network pruning, and current redundancy criteria only focus on individual filters' attributes. When pruning sparsity increases, these redundancy criteria are not effective or efficient enough. Since the filter-wise interaction also contributes to the CNN's prediction accuracy, we integrate the filter-wise interaction into the redundancy criterion. In our criterion, we introduce the filter importance and filter utilization strength to reflect the decision ability of individual and multiple filters. Utilizing this new redundancy criterion, we propose a structured network pruning approach SNPFI (Structured Network Pruning by measuring Filter-wise Interaction). During the pruning, the SNPFI can automatically assign the proper sparsity based on the filter utilization strength and eliminate the useless filters by filter importance. After the pruning, the SNPFI can recover pruned model's performance effectively without iterative training by minimizing the interaction difference. We empirically demonstrate the effectiveness of the SNPFI with several commonly used CNN models, including AlexNet, MobileNetv1, and ResNet-50, on various image classification datasets, including MNIST, CIFAR-10, and ImageNet. For all experimental CNN models, nearly 60% of computation is reduced in a network compression while the classification accuracy remains.
Fixing confirmation bias in feature attribution methods via semantic match
Jul 03, 2023
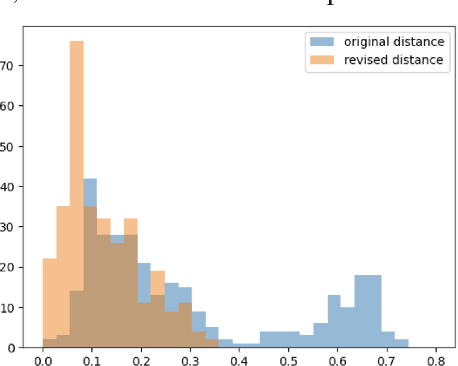
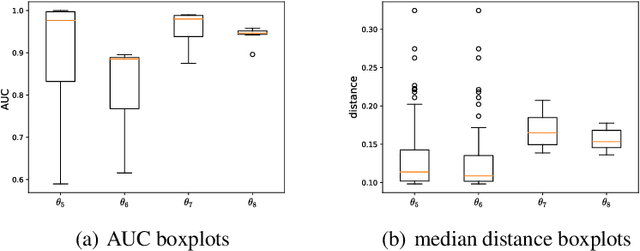
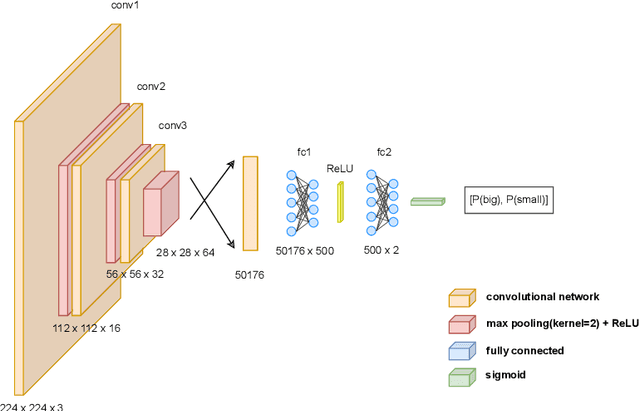
Feature attribution methods have become a staple method to disentangle the complex behavior of black box models. Despite their success, some scholars have argued that such methods suffer from a serious flaw: they do not allow a reliable interpretation in terms of human concepts. Simply put, visualizing an array of feature contributions is not enough for humans to conclude something about a model's internal representations, and confirmation bias can trick users into false beliefs about model behavior. We argue that a structured approach is required to test whether our hypotheses on the model are confirmed by the feature attributions. This is what we call the "semantic match" between human concepts and (sub-symbolic) explanations. Building on the conceptual framework put forward in Cin\`a et al. [2023], we propose a structured approach to evaluate semantic match in practice. We showcase the procedure in a suite of experiments spanning tabular and image data, and show how the assessment of semantic match can give insight into both desirable (e.g., focusing on an object relevant for prediction) and undesirable model behaviors (e.g., focusing on a spurious correlation). We couple our experimental results with an analysis on the metrics to measure semantic match, and argue that this approach constitutes the first step towards resolving the issue of confirmation bias in XAI.
Task-Specific Alignment and Multiple Level Transformer for Few-Shot Action Recognition
Jul 05, 2023
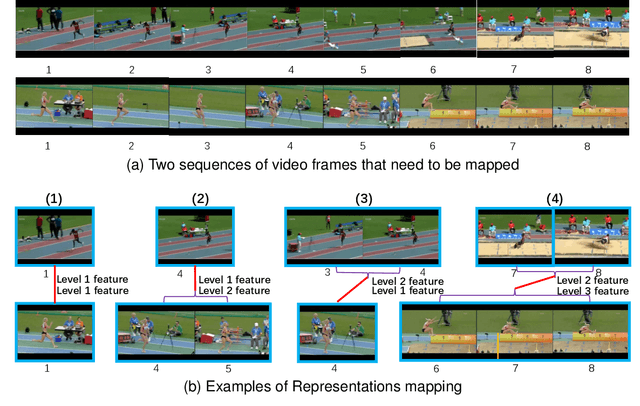
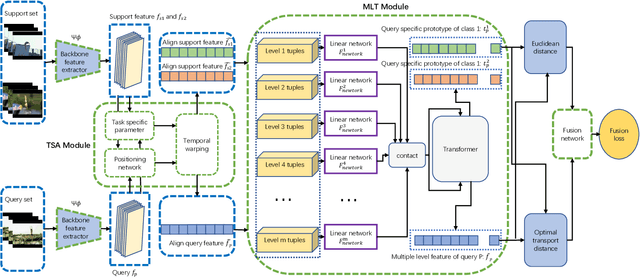
In the research field of few-shot learning, the main difference between image-based and video-based is the additional temporal dimension for videos. In recent years, many approaches for few-shot action recognition have followed the metric-based methods, especially, since some works use the Transformer to get the cross-attention feature of the videos or the enhanced prototype, and the results are competitive. However, they do not mine enough information from the Transformer because they only focus on the feature of a single level. In our paper, we have addressed this problem. We propose an end-to-end method named "Task-Specific Alignment and Multiple Level Transformer Network (TSA-MLT)". In our model, the Multiple Level Transformer focuses on the multiple-level feature of the support video and query video. Especially before Multiple Level Transformer, we use task-specific TSA to filter unimportant or misleading frames as a pre-processing. Furthermore, we adopt a fusion loss using two kinds of distance, the first is L2 sequence distance, which focuses on temporal order alignment. The second one is Optimal transport distance, which focuses on measuring the gap between the appearance and semantics of the videos. Using a simple fusion network, we fuse the two distances element-wise, then use the cross-entropy loss as our fusion loss. Extensive experiments show our method achieves state-of-the-art results on the HMDB51 and UCF101 datasets and a competitive result on the benchmark of Kinetics and something-2-something V2 datasets. Our code will be available at the URL: https://github.com/cofly2014/tsa-mlt.git
Self-Supervised Pre-Training for Deep Image Prior-Based Robust PET Image Denoising
Feb 27, 2023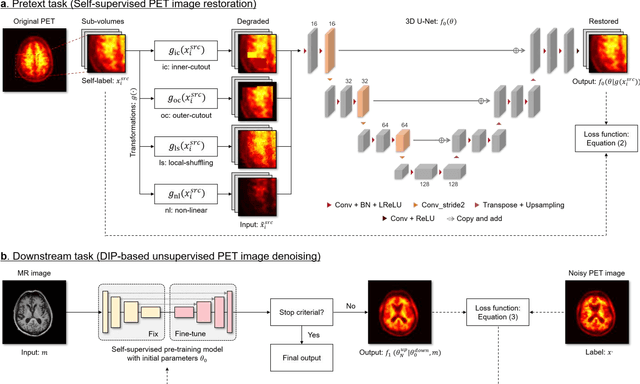
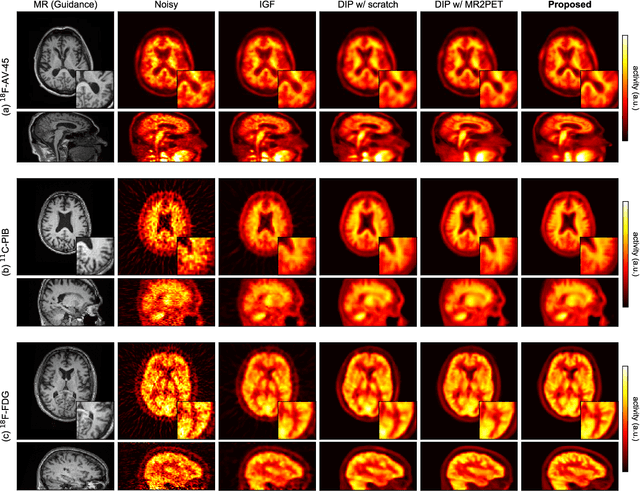
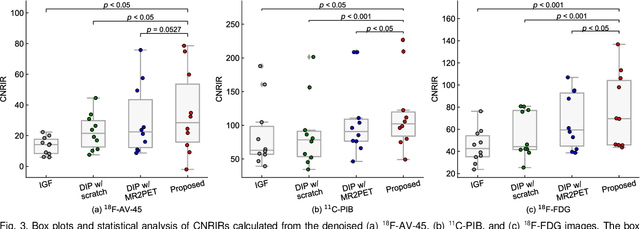

Deep image prior (DIP) has been successfully applied to positron emission tomography (PET) image restoration, enabling represent implicit prior using only convolutional neural network architecture without training dataset, whereas the general supervised approach requires massive low- and high-quality PET image pairs. To answer the increased need for PET imaging with DIP, it is indispensable to improve the performance of the underlying DIP itself. Here, we propose a self-supervised pre-training model to improve the DIP-based PET image denoising performance. Our proposed pre-training model acquires transferable and generalizable visual representations from only unlabeled PET images by restoring various degraded PET images in a self-supervised approach. We evaluated the proposed method using clinical brain PET data with various radioactive tracers ($^{18}$F-florbetapir, $^{11}$C-Pittsburgh compound-B, $^{18}$F-fluoro-2-deoxy-D-glucose, and $^{15}$O-CO$_{2}$) acquired from different PET scanners. The proposed method using the self-supervised pre-training model achieved robust and state-of-the-art denoising performance while retaining spatial details and quantification accuracy compared to other unsupervised methods and pre-training model. These results highlight the potential that the proposed method is particularly effective against rare diseases and probes and helps reduce the scan time or the radiotracer dose without affecting the patients.
A Neural Collapse Perspective on Feature Evolution in Graph Neural Networks
Jul 04, 2023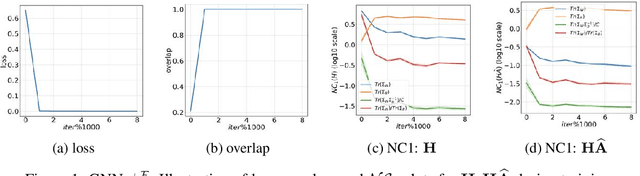
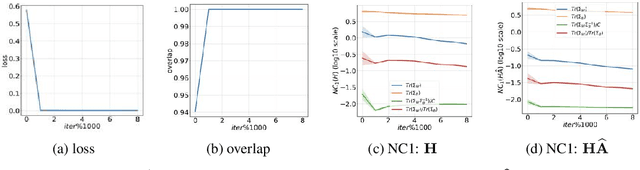
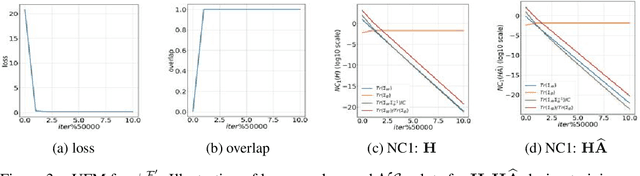
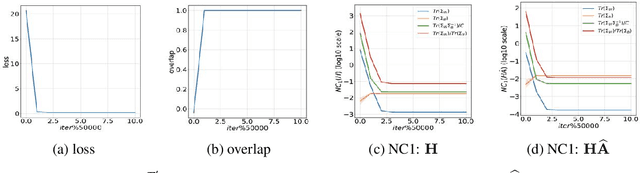
Graph neural networks (GNNs) have become increasingly popular for classification tasks on graph-structured data. Yet, the interplay between graph topology and feature evolution in GNNs is not well understood. In this paper, we focus on node-wise classification, illustrated with community detection on stochastic block model graphs, and explore the feature evolution through the lens of the "Neural Collapse" (NC) phenomenon. When training instance-wise deep classifiers (e.g. for image classification) beyond the zero training error point, NC demonstrates a reduction in the deepest features' within-class variability and an increased alignment of their class means to certain symmetric structures. We start with an empirical study that shows that a decrease in within-class variability is also prevalent in the node-wise classification setting, however, not to the extent observed in the instance-wise case. Then, we theoretically study this distinction. Specifically, we show that even an "optimistic" mathematical model requires that the graphs obey a strict structural condition in order to possess a minimizer with exact collapse. Interestingly, this condition is viable also for heterophilic graphs and relates to recent empirical studies on settings with improved GNNs' generalization. Furthermore, by studying the gradient dynamics of the theoretical model, we provide reasoning for the partial collapse observed empirically. Finally, we present a study on the evolution of within- and between-class feature variability across layers of a well-trained GNN and contrast the behavior with spectral methods.
Disentanglement in a GAN for Unconditional Speech Synthesis
Jul 04, 2023
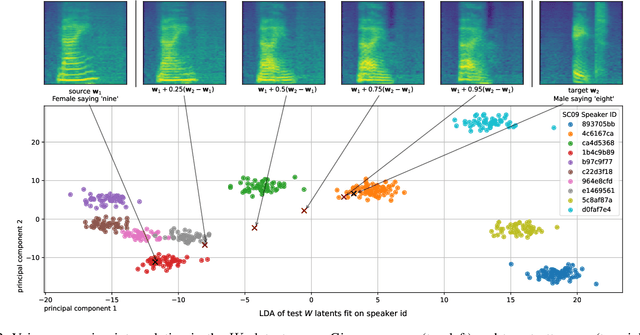
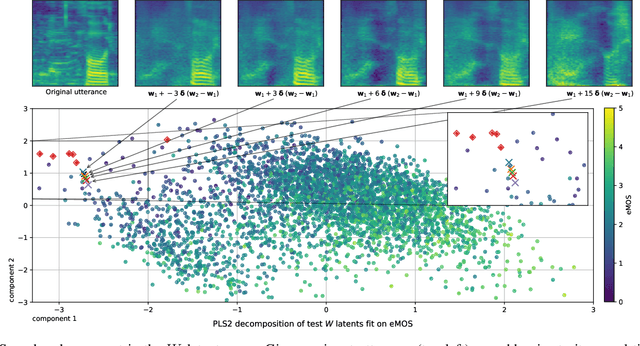
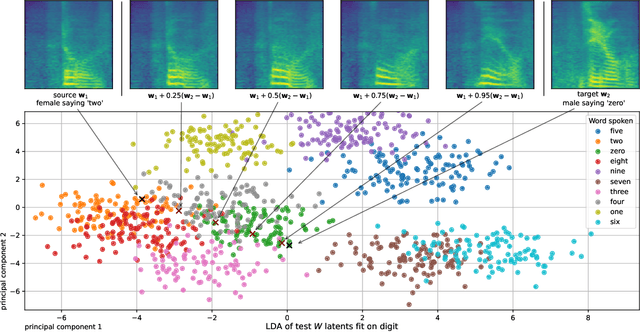
Can we develop a model that can synthesize realistic speech directly from a latent space, without explicit conditioning? Despite several efforts over the last decade, previous adversarial and diffusion-based approaches still struggle to achieve this, even on small-vocabulary datasets. To address this, we propose AudioStyleGAN (ASGAN) -- a generative adversarial network for unconditional speech synthesis tailored to learn a disentangled latent space. Building upon the StyleGAN family of image synthesis models, ASGAN maps sampled noise to a disentangled latent vector which is then mapped to a sequence of audio features so that signal aliasing is suppressed at every layer. To successfully train ASGAN, we introduce a number of new techniques, including a modification to adaptive discriminator augmentation which probabilistically skips discriminator updates. We apply it on the small-vocabulary Google Speech Commands digits dataset, where it achieves state-of-the-art results in unconditional speech synthesis. It is also substantially faster than existing top-performing diffusion models. We confirm that ASGAN's latent space is disentangled: we demonstrate how simple linear operations in the space can be used to perform several tasks unseen during training. Specifically, we perform evaluations in voice conversion, speech enhancement, speaker verification, and keyword classification. Our work indicates that GANs are still highly competitive in the unconditional speech synthesis landscape, and that disentangled latent spaces can be used to aid generalization to unseen tasks. Code, models, samples: https://github.com/RF5/simple-asgan/
Improving CLIP Training with Language Rewrites
May 31, 2023
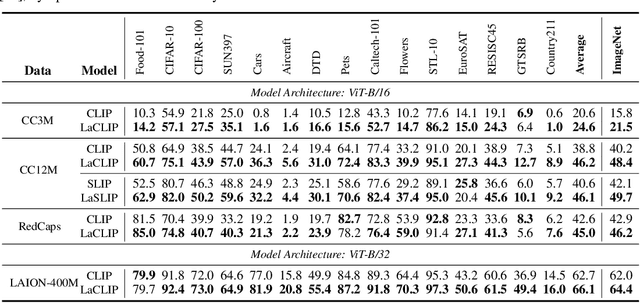

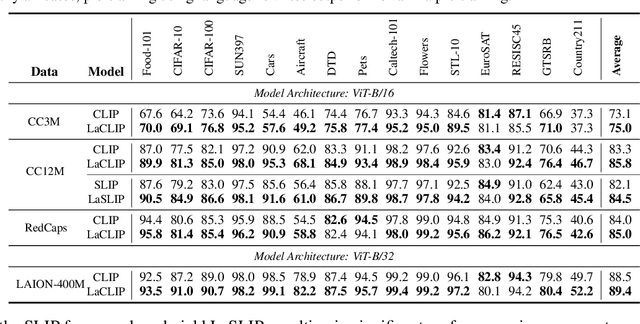
Contrastive Language-Image Pre-training (CLIP) stands as one of the most effective and scalable methods for training transferable vision models using paired image and text data. CLIP models are trained using contrastive loss, which typically relies on data augmentations to prevent overfitting and shortcuts. However, in the CLIP training paradigm, data augmentations are exclusively applied to image inputs, while language inputs remain unchanged throughout the entire training process, limiting the exposure of diverse texts to the same image. In this paper, we introduce Language augmented CLIP (LaCLIP), a simple yet highly effective approach to enhance CLIP training through language rewrites. Leveraging the in-context learning capability of large language models, we rewrite the text descriptions associated with each image. These rewritten texts exhibit diversity in sentence structure and vocabulary while preserving the original key concepts and meanings. During training, LaCLIP randomly selects either the original texts or the rewritten versions as text augmentations for each image. Extensive experiments on CC3M, CC12M, RedCaps and LAION-400M datasets show that CLIP pre-training with language rewrites significantly improves the transfer performance without computation or memory overhead during training. Specifically for ImageNet zero-shot accuracy, LaCLIP outperforms CLIP by 8.2% on CC12M and 2.4% on LAION-400M. Code is available at https://github.com/LijieFan/LaCLIP.
TD-GEM: Text-Driven Garment Editing Mapper
May 29, 2023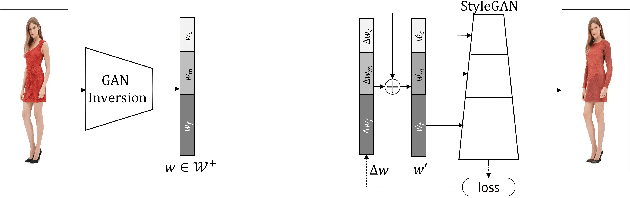

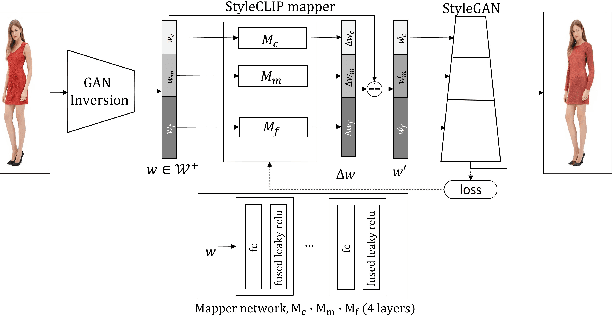
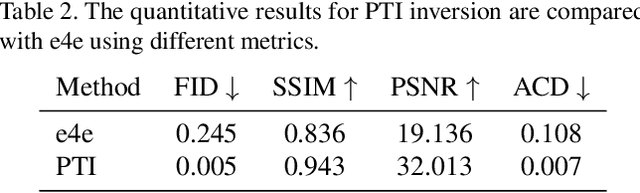
Language-based fashion image editing allows users to try out variations of desired garments through provided text prompts. Inspired by research on manipulating latent representations in StyleCLIP and HairCLIP, we focus on these latent spaces for editing fashion items of full-body human datasets. Currently, there is a gap in handling fashion image editing due to the complexity of garment shapes and textures and the diversity of human poses. In this paper, we propose an editing optimizer scheme method called Text-Driven Garment Editing Mapper (TD-GEM), aiming to edit fashion items in a disentangled way. To this end, we initially obtain a latent representation of an image through generative adversarial network inversions such as Encoder for Editing (e4e) or Pivotal Tuning Inversion (PTI) for more accurate results. An optimization-based Contrasive Language-Image Pre-training (CLIP) is then utilized to guide the latent representation of a fashion image in the direction of a target attribute expressed in terms of a text prompt. Our TD-GEM manipulates the image accurately according to the target attribute, while other parts of the image are kept untouched. In the experiments, we evaluate TD-GEM on two different attributes (i.e., "color" and "sleeve length"), which effectively generates realistic images compared to the recent manipulation schemes.