 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Network Pruning by Measuring Filter-wise Interactions
Jul 03, 2023



Structured network pruning is a practical approach to reduce computation cost directly while retaining the CNNs' generalization performance in real applications. However, identifying redundant filters is a core problem in structured network pruning, and current redundancy criteria only focus on individual filters' attributes. When pruning sparsity increases, these redundancy criteria are not effective or efficient enough. Since the filter-wise interaction also contributes to the CNN's prediction accuracy, we integrate the filter-wise interaction into the redundancy criterion. In our criterion, we introduce the filter importance and filter utilization strength to reflect the decision ability of individual and multiple filters. Utilizing this new redundancy criterion, we propose a structured network pruning approach SNPFI (Structured Network Pruning by measuring Filter-wise Interaction). During the pruning, the SNPFI can automatically assign the proper sparsity based on the filter utilization strength and eliminate the useless filters by filter importance. After the pruning, the SNPFI can recover pruned model's performance effectively without iterative training by minimizing the interaction difference. We empirically demonstrate the effectiveness of the SNPFI with several commonly used CNN models, including AlexNet, MobileNetv1, and ResNet-50, on various image classification datasets, including MNIST, CIFAR-10, and ImageNet. For all experimental CNN models, nearly 60% of computation is reduced in a network compression while the classification accuracy remains.
Automated Model Compression by Jointly Applied Pruning and Quantization
Nov 12, 2020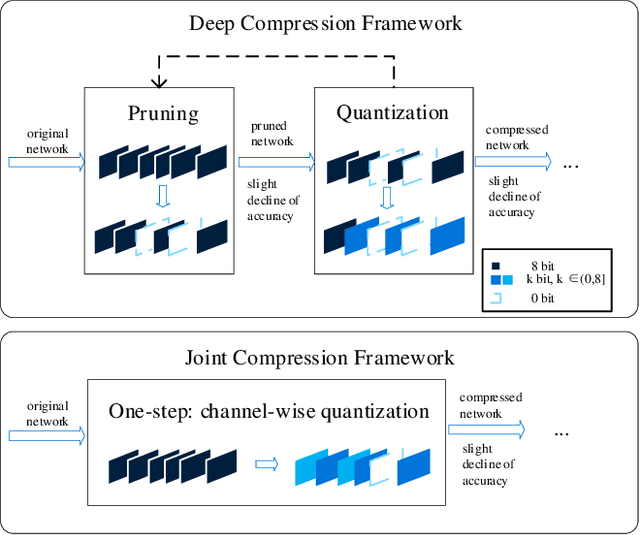
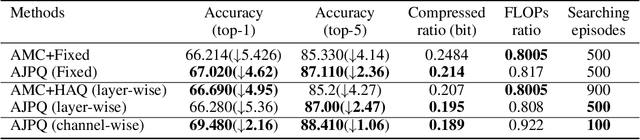
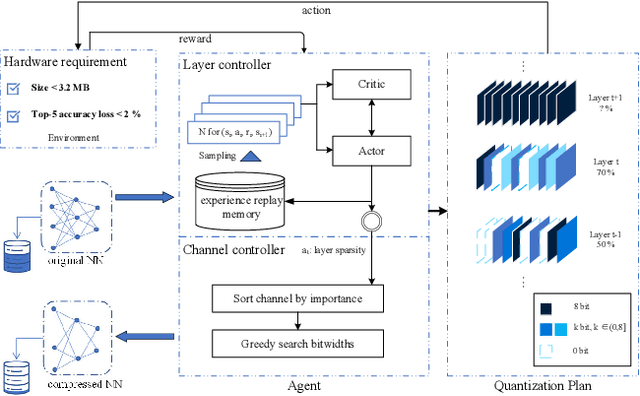
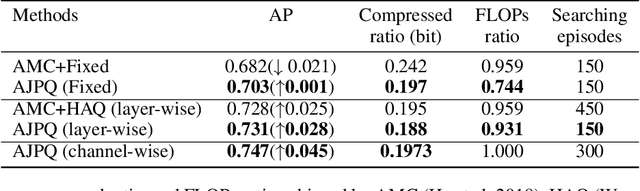
In the traditional deep compression framework, iteratively performing network pruning and quantization can reduce the model size and computation cost to meet the deployment requirements. However, such a step-wise application of pruning and quantization may lead to suboptimal solutions and unnecessary time consumption. In this paper, we tackle this issue by integrating network pruning and quantization as a unified joint compression problem and then use AutoML to automatically solve it. We find the pruning process can be regarded as the channel-wise quantization with 0 bit. Thus, the separate two-step pruning and quantization can be simplified as the one-step quantization with mixed precision. This unification not only simplifies the compression pipeline but also avoids the compression divergence. To implement this idea, we propose the automated model compression by jointly applied pruning and quantization (AJPQ). AJPQ is designed with a hierarchical architecture: the layer controller controls the layer sparsity, and the channel controller decides the bit-width for each kernel. Following the same importance criterion, the layer controller and the channel controller collaboratively decide the compression strategy. With the help of reinforcement learning, our one-step compression is automatically achieved. Compared with the state-of-the-art automated compression methods, our method obtains a better accuracy while reducing the storage considerably. For fixed precision quantization, AJPQ can reduce more than five times model size and two times computation with a slight performance increase for Skynet in remote sensing object detection. When mixed-precision is allowed, AJPQ can reduce five times model size with only 1.06% top-5 accuracy decline for MobileNet in the classification task.