 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HyperThumbnail: Real-time 6K Image Rescaling with Rate-distortion Optimization
Apr 03, 2023
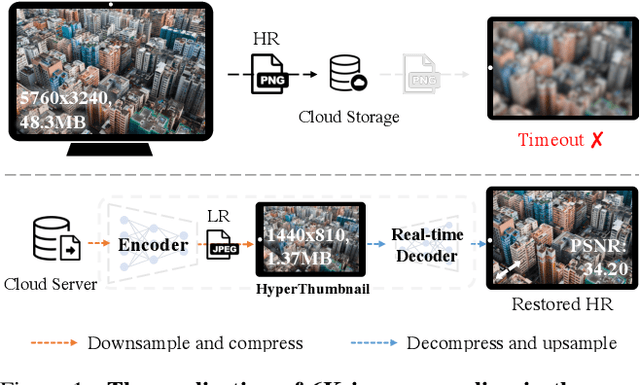
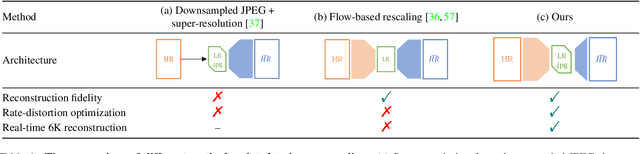
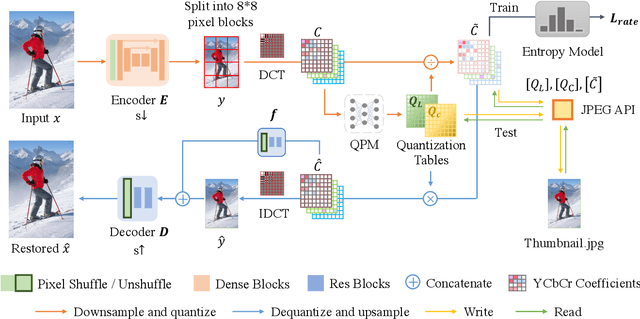
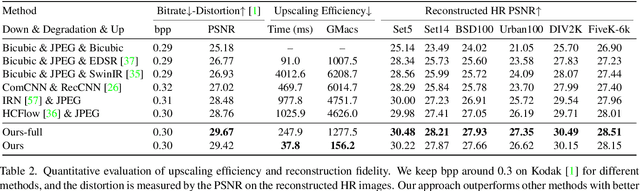
Contemporary image rescaling aims at embedding a high-resolution (HR) image into a low-resolution (LR) thumbnail image that contains embedded information for HR image reconstruction. Unlike traditional image super-resolution, this enables high-fidelity HR image restoration faithful to the original one, given the embedded information in the LR thumbnail. However, state-of-the-art image rescaling methods do not optimize the LR image file size for efficient sharing and fall short of real-time performance for ultra-high-resolution (e.g., 6K) image reconstruction. To address these two challenges, we propose a novel framework (HyperThumbnail) for real-time 6K rate-distortion-aware image rescaling. Our framework first embeds an HR image into a JPEG LR thumbnail by an encoder with our proposed quantization prediction module, which minimizes the file size of the embedding LR JPEG thumbnail while maximizing HR reconstruction quality. Then, an efficient frequency-aware decoder reconstructs a high-fidelity HR image from the LR one in real time. Extensive experiments demonstrate that our framework outperforms previous image rescaling baselines in rate-distortion performance and can perform 6K image reconstruction in real time.
Restormer-Plus for Real World Image Deraining: the Runner-up Solution to the GT-RAIN Challenge (CVPR 2023 UG2+ Track 3)
May 26, 2023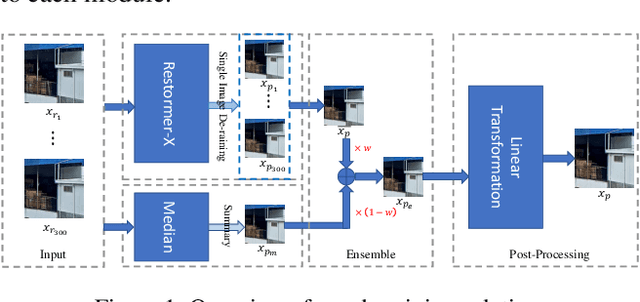

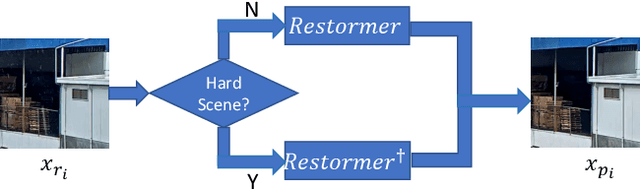

This technical report presents our Restormer-Plus approach, which was submitted to the GT-RAIN Challenge (CVPR 2023 UG$^2$+ Track 3). Details regarding the challenge are available at http://cvpr2023.ug2challenge.org/track3.html. Restormer-Plus outperformed all other submitted solutions in terms of peak signal-to-noise ratio (PSNR), and ranked 4th in terms of structural similarity (SSIM). It was officially evaluated by the competition organizers as a runner-up solution. It consists of four main modules: the single-image de-raining module (Restormer-X), the median filtering module, the weighted averaging module, and the post-processing module. Restormer-X is applied to each rainy image and built on top of Restormer. The median filtering module is used as a median operator for rainy images associated with each scene. The weighted averaging module combines the median filtering results with those of Restormer-X to alleviate overfitting caused by using only Restormer-X. Finally, the post-processing module is utilized to improve the brightness restoration. These modules make Restormer-Plus one of the state-of-the-art solutions for the GT-RAIN Challenge. Our code can be found at https://github.com/ZJLAB-AMMI/Restormer-Plus.
Registration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023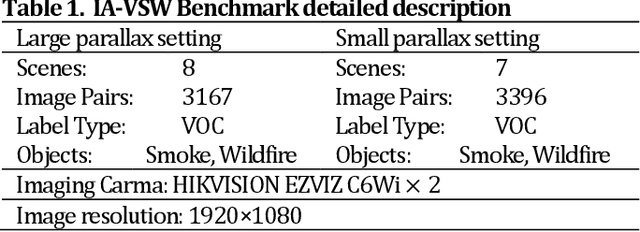
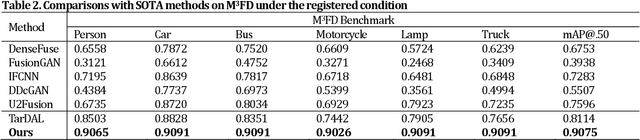

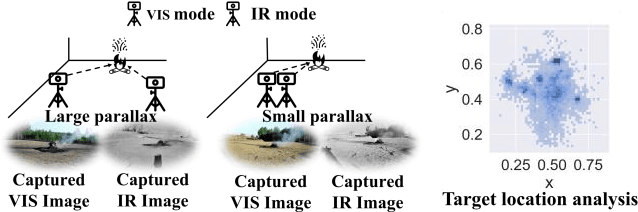
Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.
Input Augmentation with SAM: Boosting Medical Image Segmentation with Segmentation Foundation Model
Apr 22, 2023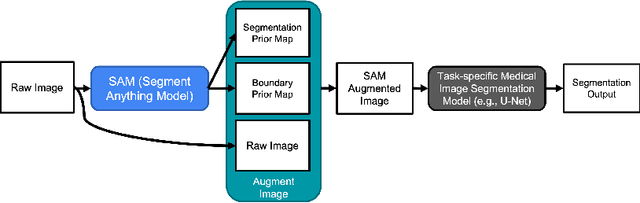
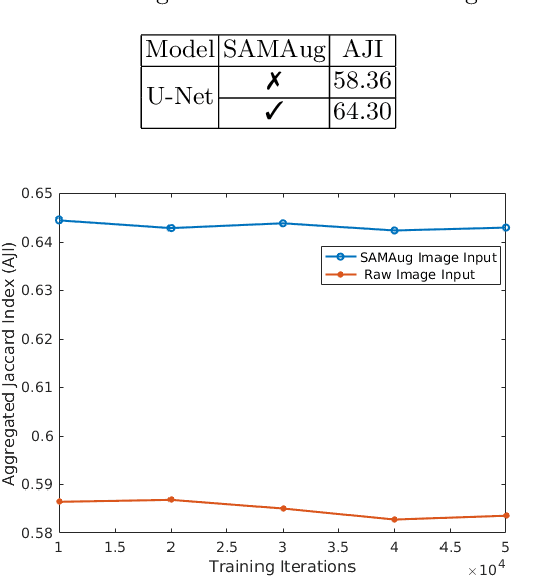
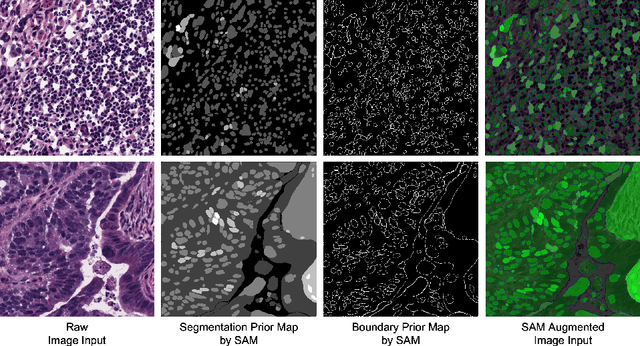
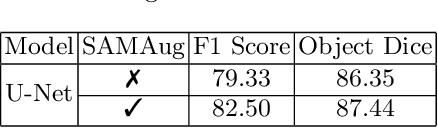
The Segment Anything Model (SAM) is a recently developed large model for general-purpose segmentation for computer vision tasks. SAM was trained using 11 million images with over 1 billion masks and can produce segmentation results for a wide range of objects in natural scene images. SAM can be viewed as a general perception model for segmentation (partitioning images into semantically meaningful regions). Thus, how to utilize such a large foundation model for medical image segmentation is an emerging research target. This paper shows that although SAM does not immediately give high-quality segmentation for medical images, its generated masks, features, and stability scores are useful for building and training better medical image segmentation models. In particular, we demonstrate how to use SAM to augment image inputs for a commonly-used medical image segmentation model (e.g., U-Net). Experiments on two datasets show the effectiveness of our proposed method.
Model Cascades for Efficient Image Search
Mar 27, 2023
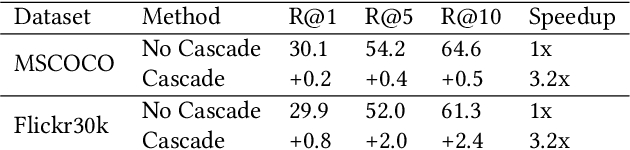
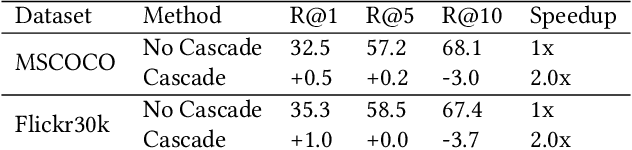
Modern neural encoders offer unprecedented text-image retrieval (TIR) accuracy. However, their high computational cost impedes an adoption to large-scale image searches. We propose a novel image ranking algorithm that uses a cascade of increasingly powerful neural encoders to progressively filter images by how well they match a given text. Our algorithm reduces lifetime TIR costs by over 3x.
Low-Light Enhancement in the Frequency Domain
Jun 29, 2023Decreased visibility, intensive noise, and biased color are the common problems existing in low-light images. These visual disturbances further reduce the performance of high-level vision tasks, such as object detection, and tracking. To address this issue, some image enhancement methods have been proposed to increase the image contrast. However, most of them are implemented only in the spatial domain, which can be severely influenced by noise signals while enhancing. Hence, in this work, we propose a novel residual recurrent multi-wavelet convolutional neural network R2-MWCNN learned in the frequency domain that can simultaneously increase the image contrast and reduce noise signals well. This end-to-end trainable network utilizes a multi-level discrete wavelet transform to divide input feature maps into distinct frequencies, resulting in a better denoise impact. A channel-wise loss function is proposed to correct the color distortion for more realistic results. Extensive experiments demonstrate that our proposed R2-MWCNN outperforms the state-of-the-art methods quantitively and qualitatively.
Detecting Images Generated by Deep Diffusion Models using their Local Intrinsic Dimensionality
Jul 18, 2023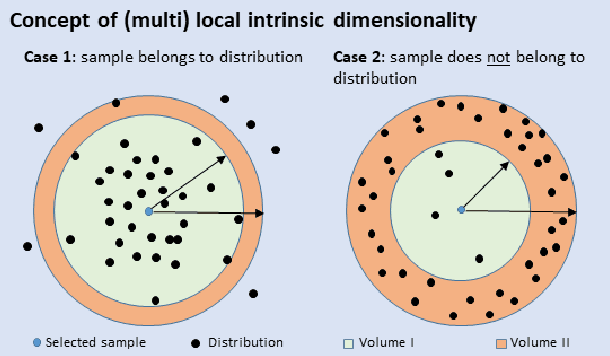
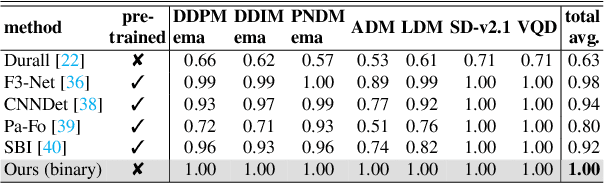
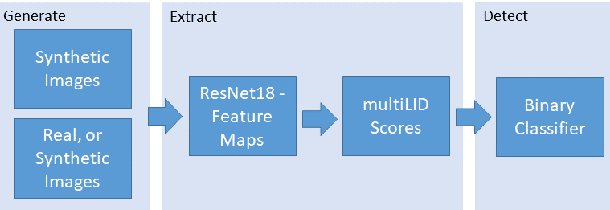
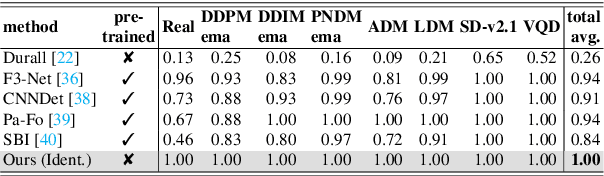
Diffusion models recently have been successfully applied for the visual synthesis of strikingly realistic appearing images. This raises strong concerns about their potential for malicious purposes. In this paper, we propose using the lightweight multi Local Intrinsic Dimensionality (multiLID), which has been originally developed in context of the detection of adversarial examples, for the automatic detection of synthetic images and the identification of the according generator networks. In contrast to many existing detection approaches, which often only work for GAN-generated images, the proposed method provides close to perfect detection results in many realistic use cases. Extensive experiments on known and newly created datasets demonstrate that the proposed multiLID approach exhibits superiority in diffusion detection and model identification. Since the empirical evaluations of recent publications on the detection of generated images are often mainly focused on the "LSUN-Bedroom" dataset, we further establish a comprehensive benchmark for the detection of diffusion-generated images, including samples from several diffusion models with different image sizes.
EsaNet: Environment Semantics Enabled Physical Layer Authentication
Jul 18, 2023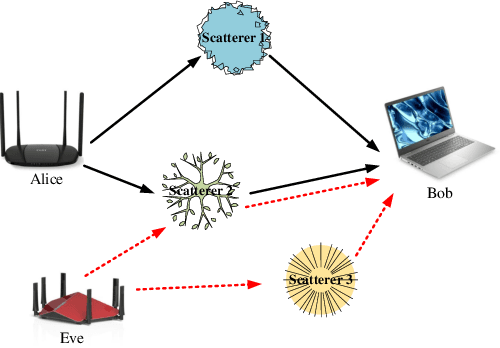
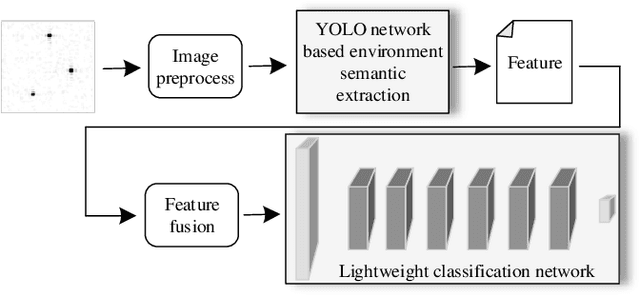
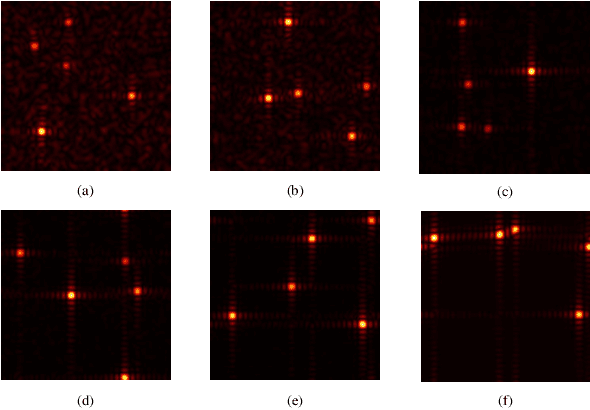
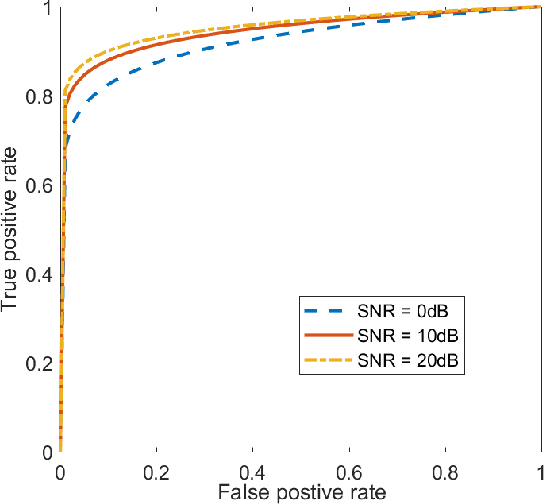
Wireless networks are vulnerable to physical layer spoofing attacks due to the wireless broadcast nature, thus, integrating communications and security (ICAS) is urgently needed for 6G endogenous security. In this letter, we propose an environment semantics enabled physical layer authentication network based on deep learning, namely EsaNet, to authenticate the spoofing from the underlying wireless protocol. Specifically, the frequency independent wireless channel fingerprint (FiFP) is extracted from the channel state information (CSI) of a massive multi-input multi-output (MIMO) system based on environment semantics knowledge. Then, we transform the received signal into a two-dimensional red green blue (RGB) image and apply the you only look once (YOLO), a single-stage object detection network, to quickly capture the FiFP. Next, a lightweight classification network is designed to distinguish the legitimate from the illegitimate users. Finally, the experimental results show that the proposed EsaNet can effectively detect physical layer spoofing attacks and is robust in time-varying wireless environments.
CG-fusion CAM: Online segmentation of laser-induced damage on large-aperture optics
Jul 18, 2023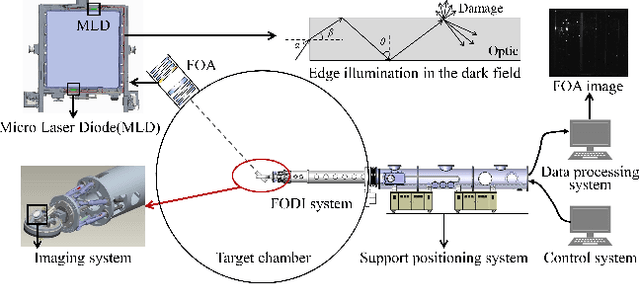

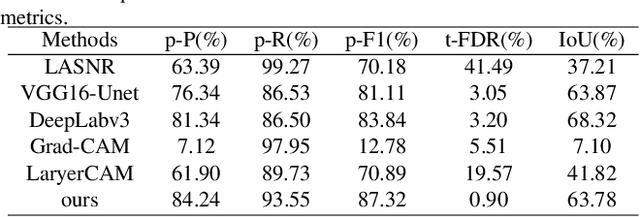
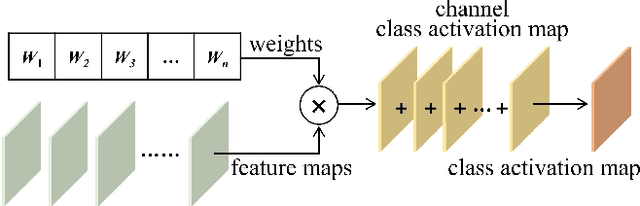
Online segmentation of laser-induced damage on large-aperture optics in high-power laser facilities is challenged by complicated damage morphology, uneven illumination and stray light interference. Fully supervised semantic segmentation algorithms have achieved state-of-the-art performance, but rely on plenty of pixel-level labels, which are time-consuming and labor-consuming to produce. LayerCAM, an advanced weakly supervised semantic segmentation algorithm, can generate pixel-accurate results using only image-level labels, but its scattered and partially under-activated class activation regions degrade segmentation performance. In this paper, we propose a weakly supervised semantic segmentation method with Continuous Gradient CAM and its nonlinear multi-scale fusion (CG-fusion CAM). The method redesigns the way of back-propagating gradients and non-linearly activates the multi-scale fused heatmaps to generate more fine-grained class activation maps with appropriate activation degree for different sizes of damage sites. Experiments on our dataset show that the proposed method can achieve segmentation performance comparable to that of fully supervised algorithms.
PixelHuman: Animatable Neural Radiance Fields from Few Images
Jul 18, 2023
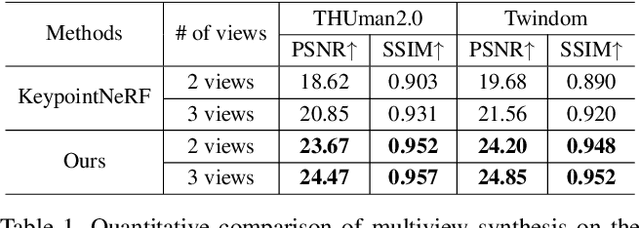
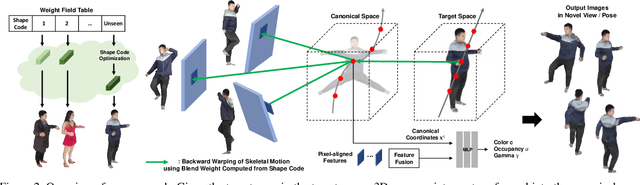
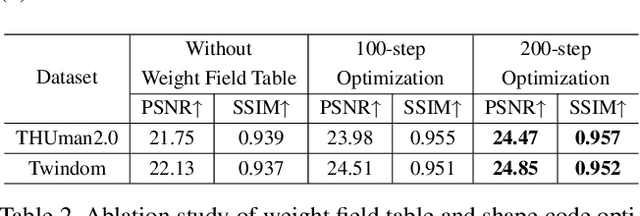
In this paper, we propose PixelHuman, a novel human rendering model that generates animatable human scenes from a few images of a person with unseen identity, views, and poses. Previous work have demonstrated reasonable performance in novel view and pose synthesis, but they rely on a large number of images to train and are trained per scene from videos, which requires significant amount of time to produce animatable scenes from unseen human images. Our method differs from existing methods in that it can generalize to any input image for animatable human synthesis. Given a random pose sequence, our method synthesizes each target scene using a neural radiance field that is conditioned on a canonical representation and pose-aware pixel-aligned features, both of which can be obtained through deformation fields learned in a data-driven manner. Our experiments show that our method achieves state-of-the-art performance in multiview and novel pose synthesis from few-shot images.