 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contrastive Pre-trained Foundation Model for Deciphering Imaging Noisomics across Modalities
Jan 21, 2026Characterizing imaging noise is notoriously data-intensive and device-dependent, as modern sensors entangle physical signals with complex algorithmic artifacts. Current paradigms struggle to disentangle these factors without massive supervised datasets, often reducing noise to mere interference rather than an information resource. Here, we introduce "Noisomics", a framework shifting the focus from suppression to systematic noise decoding via the Contrastive Pre-trained (CoP) Foundation Model. By leveraging the manifold hypothesis and synthetic noise genome, CoP employs contrastive learning to disentangle semantic signals from stochastic perturbations. Crucially, CoP breaks traditional deep learning scaling laws, achieving superior performance with only 100 training samples, outperforming supervised baselines trained on 100,000 samples, thereby reducing data and computational dependency by three orders of magnitude. Extensive benchmarking across 12 diverse out-of-domain datasets confirms its robust zero-shot generalization, demonstrating a 63.8% reduction in estimation error and an 85.1% improvement in the coefficient of determination compared to the conventional training strategy. We demonstrate CoP's utility across scales: from deciphering non-linear hardware-noise interplay in consumer photography to optimizing photon-efficient protocols for deep-tissue microscopy. By decoding noise as a multi-parametric footprint, our work redefines stochastic degradation as a vital information resource, empowering precise imaging diagnostics without prior device calibration.
Registration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023



Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.
A Dataset-free Self-supervised Disentangled Learning Method for Adaptive Infrared and Visible Images Super-resolution Fusion
Dec 06, 2021
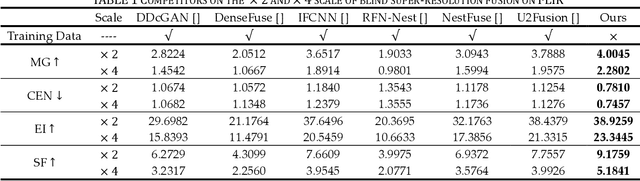
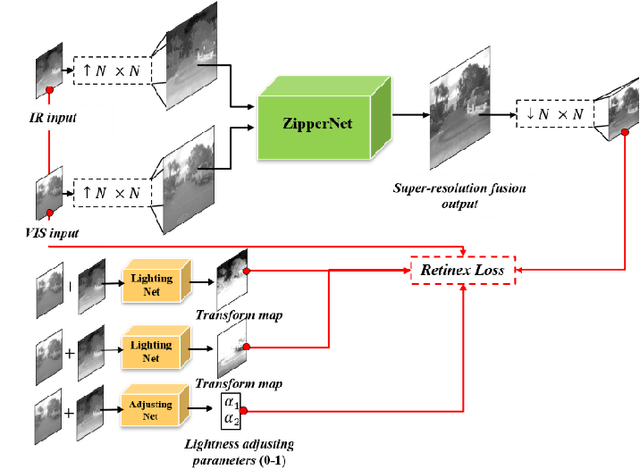
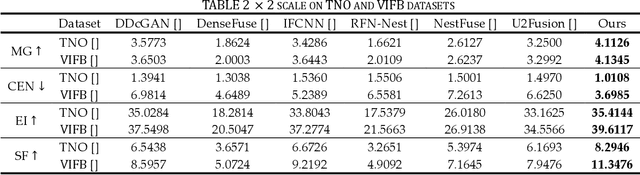
This study proposes a novel general dataset-free self-supervised learning framework based-on physical model named self-supervised disentangled learning (SDL), and proposes a novel method named Deep Retinex fusion (DRF) which applies SDL framework with generative networks and Retinex theory in infrared and visible images super-resolution fusion. Meanwhile, a generative dual-path fusion network ZipperNet and adaptive fusion loss function Retinex loss are designed for effectively high-quality fusion. The core idea of DRF (based-on SDL) consists of two parts: one is generating components which are disentangled from physical model using generative networks; the other is loss functions which are designed based-on physical relation, and generated components are combined by loss functions in training phase. Furthermore, in order to verify the effectiveness of our proposed DRF, qualitative and quantitative comparisons compared with six state-of-the-art methods are performed on three different infrared and visible datasets. Our code will be open source available soon at https://github.com/GuYuanjie/Deep-Retinex-fusion.
Deep Fusion Prior for Multi-Focus Image Super Resolution Fusion
Oct 12, 2021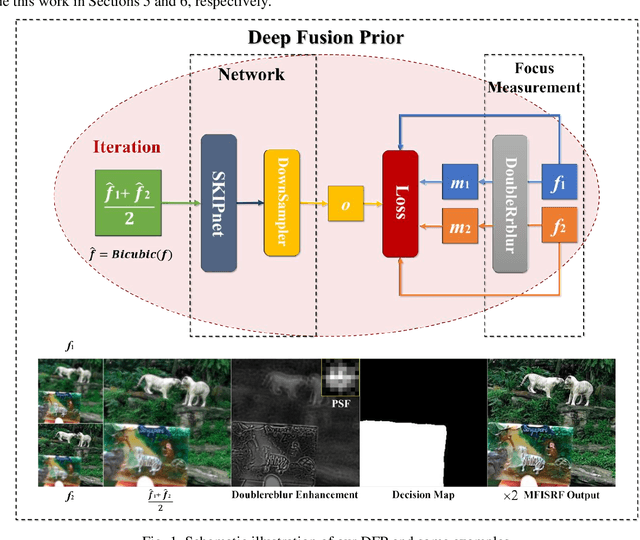
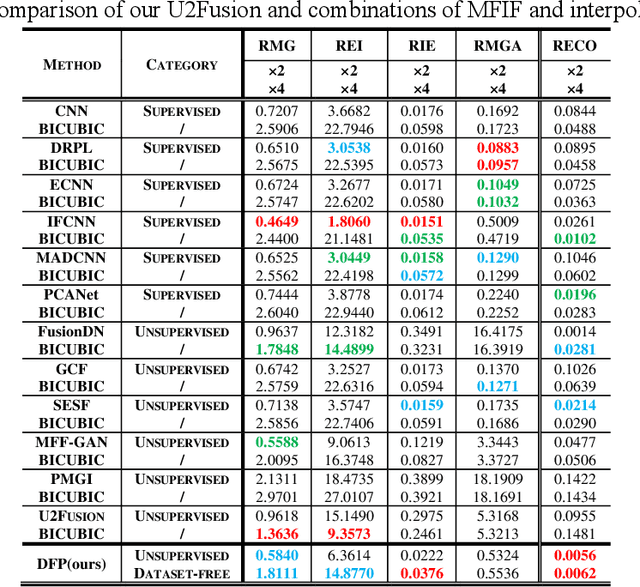
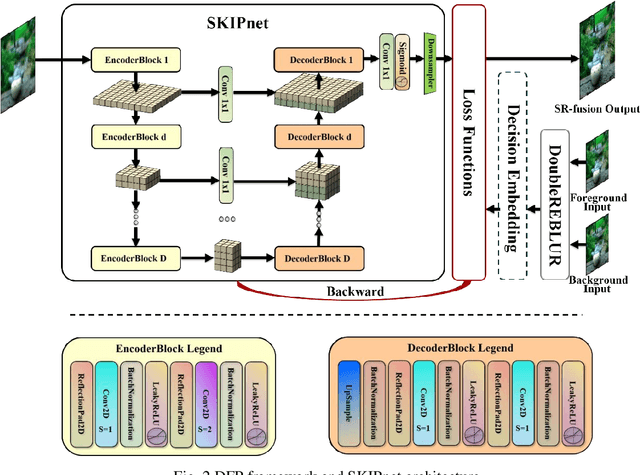
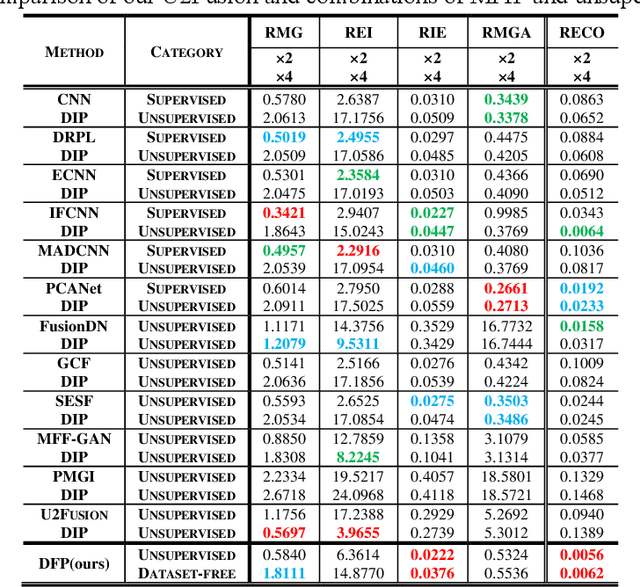
This paper unifies the multi-focus images fusion (MFIF) and blind super resolution (SR) problems as the multi-focus image super resolution fusion (MFISRF) task, and proposes a novel unified dataset-free unsupervised framework named deep fusion prior (DFP) to address such MFISRF task. DFP consists of SKIPnet network, DoubleReblur focus measurement tactic, decision embedding module and loss functions. In particular, DFP can obtain MFISRF only from two low-resolution inputs without any extent dataset; SKIPnet implementing unsupervised learning via deep image prior is an end-to-end generated network acting as the engine of DFP; DoubleReblur is used to determine the primary decision map without learning but based on estimated PSF and Gaussian kernels convolution; decision embedding module optimizes the decision map via learning; and DFP losses composed of content loss, joint gradient loss and gradient limit loss can obtain high-quality MFISRF results robustly. Experiments have proved that our proposed DFP approaches and even outperforms those state-of-art MFIF and SR method combinations. Additionally, DFP is a general framework, thus its networks and focus measurement tactics can be continuously updated to further improve the MFISRF performance. DFP codes are open source and will be available soon at http://github.com/GuYuanjie/DeepFusionPrior.