 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Class Anchor Margin Loss for Content-Based Image Retrieval
Jun 03, 2023
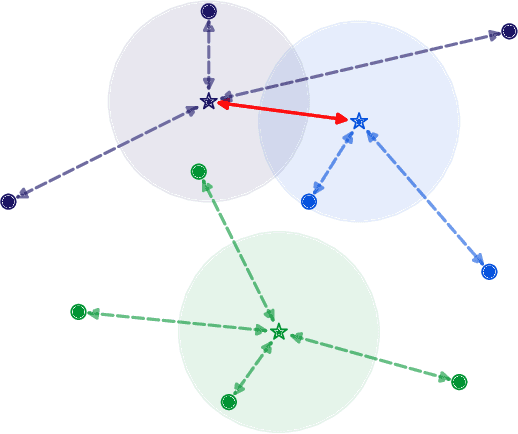
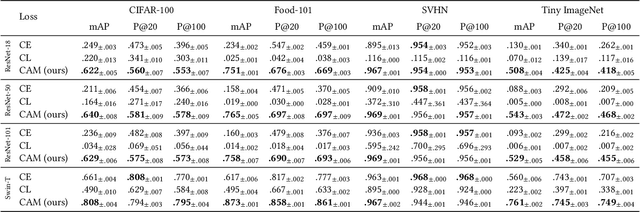
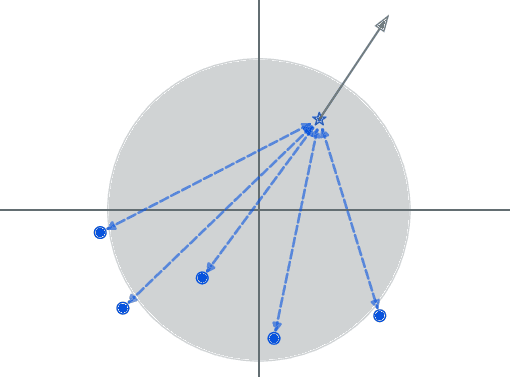
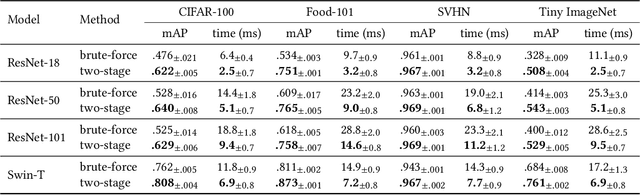
The performance of neural networks in content-based image retrieval (CBIR) is highly influenced by the chosen loss (objective) function. The majority of objective functions for neural models can be divided into metric learning and statistical learning. Metric learning approaches require a pair mining strategy that often lacks efficiency, while statistical learning approaches are not generating highly compact features due to their indirect feature optimization. To this end, we propose a novel repeller-attractor loss that falls in the metric learning paradigm, yet directly optimizes for the L2 metric without the need of generating pairs. Our loss is formed of three components. One leading objective ensures that the learned features are attracted to each designated learnable class anchor. The second loss component regulates the anchors and forces them to be separable by a margin, while the third objective ensures that the anchors do not collapse to zero. Furthermore, we develop a more efficient two-stage retrieval system by harnessing the learned class anchors during the first stage of the retrieval process, eliminating the need of comparing the query with every image in the database. We establish a set of four datasets (CIFAR-100, Food-101, SVHN, and Tiny ImageNet) and evaluate the proposed objective in the context of few-shot and full-set training on the CBIR task, by using both convolutional and transformer architectures. Compared to existing objective functions, our empirical evidence shows that the proposed objective is generating superior and more consistent results.
Video Colorization with Pre-trained Text-to-Image Diffusion Models
Jun 02, 2023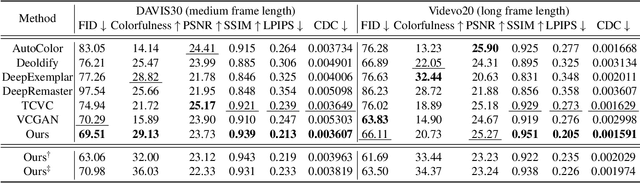
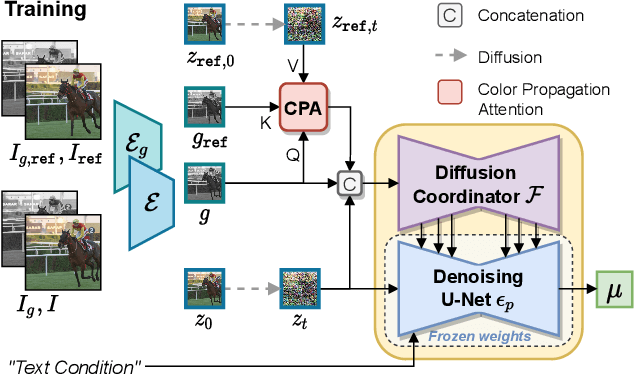
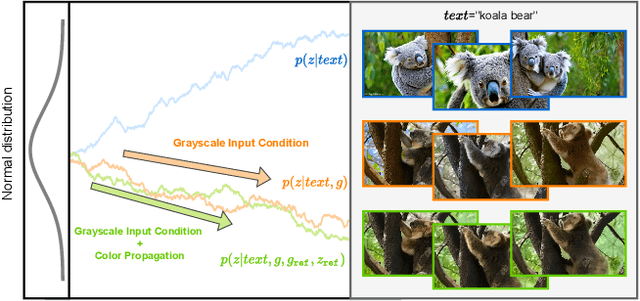

Video colorization is a challenging task that involves inferring plausible and temporally consistent colors for grayscale frames. In this paper, we present ColorDiffuser, an adaptation of a pre-trained text-to-image latent diffusion model for video colorization. With the proposed adapter-based approach, we repropose the pre-trained text-to-image model to accept input grayscale video frames, with the optional text description, for video colorization. To enhance the temporal coherence and maintain the vividness of colorization across frames, we propose two novel techniques: the Color Propagation Attention and Alternated Sampling Strategy. Color Propagation Attention enables the model to refine its colorization decision based on a reference latent frame, while Alternated Sampling Strategy captures spatiotemporal dependencies by using the next and previous adjacent latent frames alternatively as reference during the generative diffusion sampling steps. This encourages bidirectional color information propagation between adjacent video frames, leading to improved color consistency across frames. We conduct extensive experiments on benchmark datasets, and the results demonstrate the effectiveness of our proposed framework. The evaluations show that ColorDiffuser achieves state-of-the-art performance in video colorization, surpassing existing methods in terms of color fidelity, temporal consistency, and visual quality.
MaskSearch: Querying Image Masks at Scale
May 03, 2023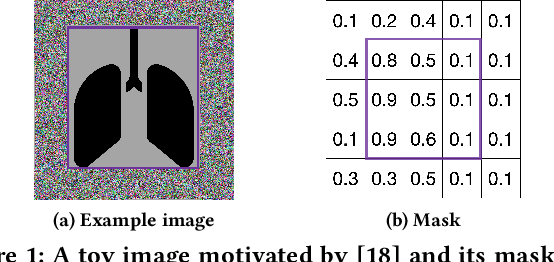


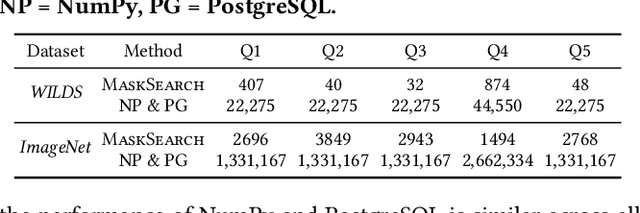
Machine learning tasks over image databases often generate masks that annotate image content (e.g., saliency maps, segmentation maps) and enable a variety of applications (e.g., determine if a model is learning spurious correlations or if an image was maliciously modified to mislead a model). While queries that retrieve examples based on mask properties are valuable to practitioners, existing systems do not support such queries efficiently. In this paper, we formalize the problem and propose a system, MaskSearch, that focuses on accelerating queries over databases of image masks. MaskSearch leverages a novel indexing technique and an efficient filter-verification query execution framework. Experiments on real-world datasets with our prototype show that MaskSearch, using indexes approximately 5% the size of the data, accelerates individual queries by up to two orders of magnitude and consistently outperforms existing methods on various multi-query workloads that simulate dataset exploration and analysis processes.
DIAMANT: Dual Image-Attention Map Encoders For Medical Image Segmentation
Apr 28, 2023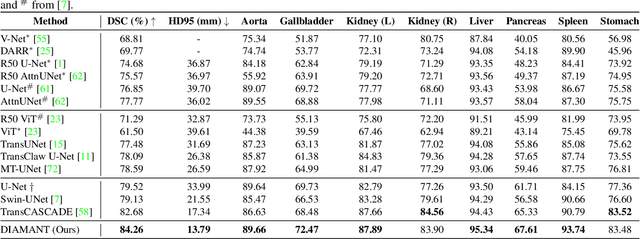
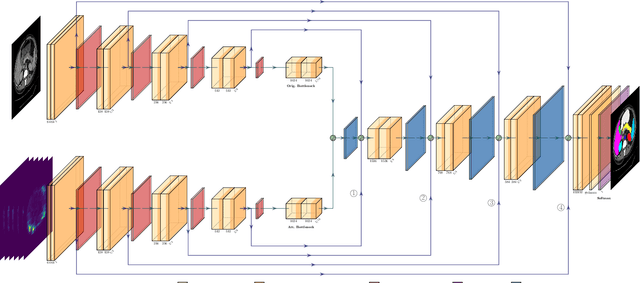
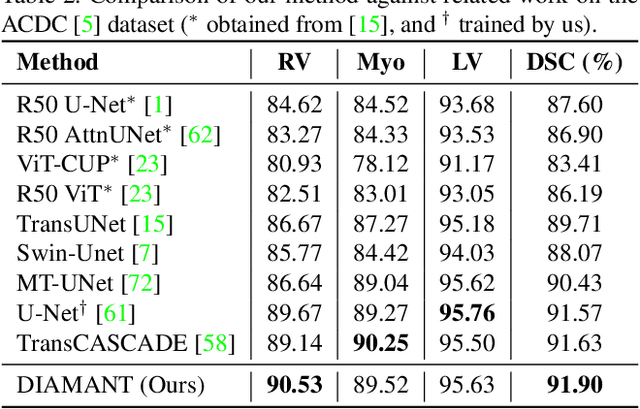
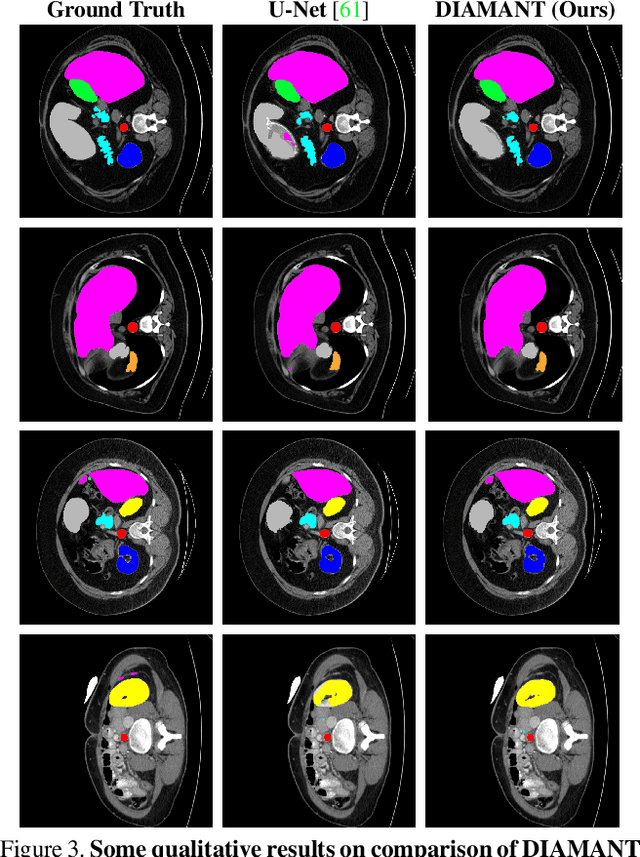
Although purely transformer-based architectures showed promising performance in many computer vision tasks, many hybrid models consisting of CNN and transformer blocks are introduced to fit more specialized tasks. Nevertheless, despite the performance gain of both pure and hybrid transformer-based architectures compared to CNNs in medical imaging segmentation, their high training cost and complexity make it challenging to use them in real scenarios. In this work, we propose simple architectures based on purely convolutional layers, and show that by just taking advantage of the attention map visualizations obtained from a self-supervised pretrained vision transformer network (e.g., DINO) one can outperform complex transformer-based networks with much less computation costs. The proposed architecture is composed of two encoder branches with the original image as input in one branch and the attention map visualizations of the same image from multiple self-attention heads from a pre-trained DINO model (as multiple channels) in the other branch. The results of our experiments on two publicly available medical imaging datasets show that the proposed pipeline outperforms U-Net and the state-of-the-art medical image segmentation models.
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
May 11, 2023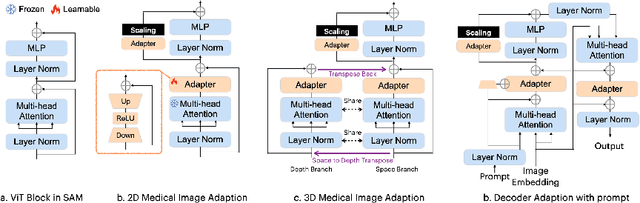
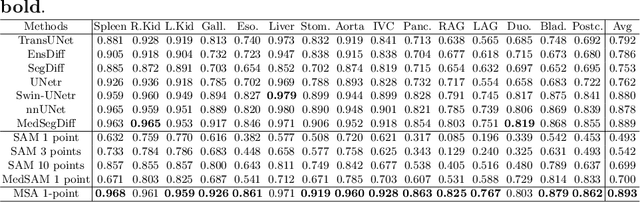
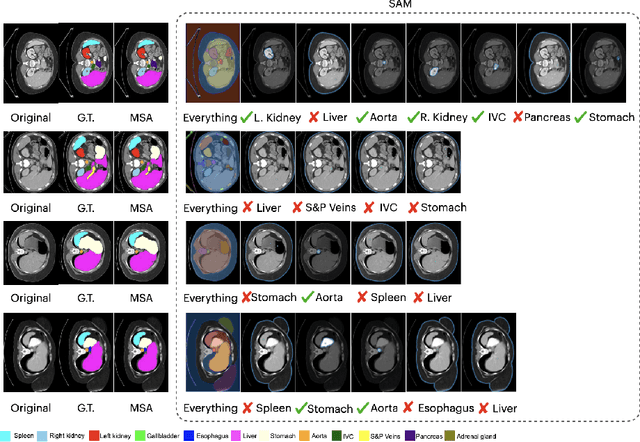
The Segment Anything Model (SAM) has recently gained popularity in the field of image segmentation. Thanks to its impressive capabilities in all-round segmentation tasks and its prompt-based interface, SAM has sparked intensive discussion within the community. It is even said by many prestigious experts that image segmentation task has been "finished" by SAM. However, medical image segmentation, although an important branch of the image segmentation family, seems not to be included in the scope of Segmenting "Anything". Many individual experiments and recent studies have shown that SAM performs subpar in medical image segmentation. A natural question is how to find the missing piece of the puzzle to extend the strong segmentation capability of SAM to medical image segmentation. In this paper, instead of fine-tuning the SAM model, we propose Med SAM Adapter, which integrates the medical specific domain knowledge to the segmentation model, by a simple yet effective adaptation technique. Although this work is still one of a few to transfer the popular NLP technique Adapter to computer vision cases, this simple implementation shows surprisingly good performance on medical image segmentation. A medical image adapted SAM, which we have dubbed Medical SAM Adapter (MSA), shows superior performance on 19 medical image segmentation tasks with various image modalities including CT, MRI, ultrasound image, fundus image, and dermoscopic images. MSA outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, such as nnUNet, TransUNet, UNetr, MedSegDiff, and also outperforms the fully fine-turned MedSAM with a considerable performance gap. Code will be released at: https://github.com/WuJunde/Medical-SAM-Adapter.
Estimation of motion blur kernel parameters using regression convolutional neural networks
Aug 02, 2023
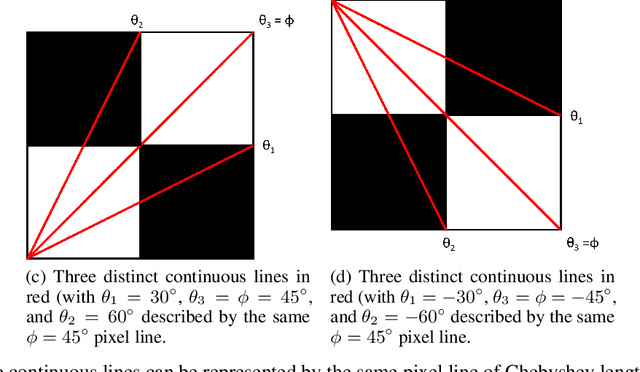
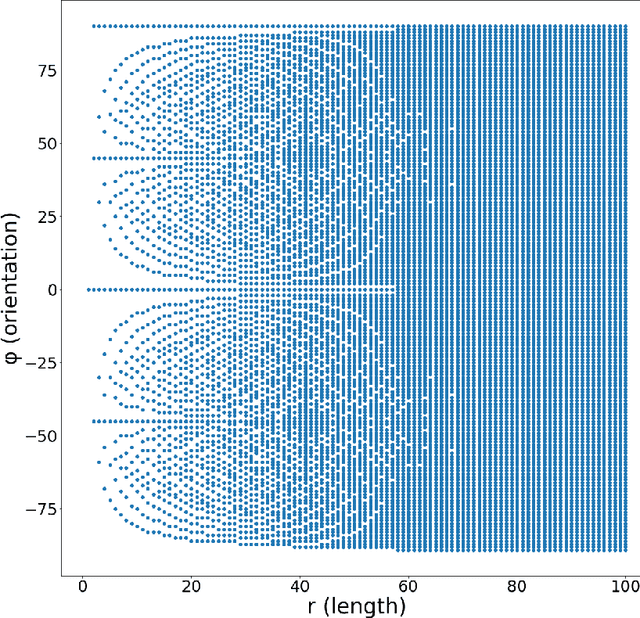
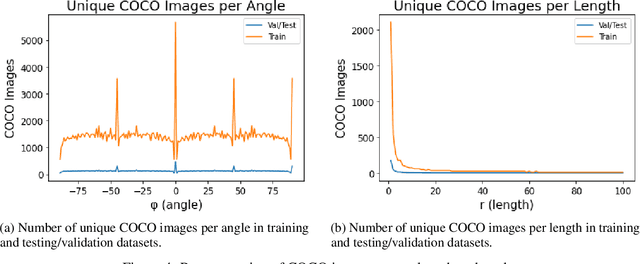
Many deblurring and blur kernel estimation methods use MAP or classification deep learning techniques to sharpen an image and predict the blur kernel. We propose a regression approach using neural networks to predict the parameters of linear motion blur kernels. These kernels can be parameterized by its length of blur and the orientation of the blur.This paper will analyze the relationship between length and angle of linear motion blur. This analysis will help establish a foundation to using regression prediction in uniformed motion blur images.
Visual and Textual Prior Guided Mask Assemble for Few-Shot Segmentation and Beyond
Aug 15, 2023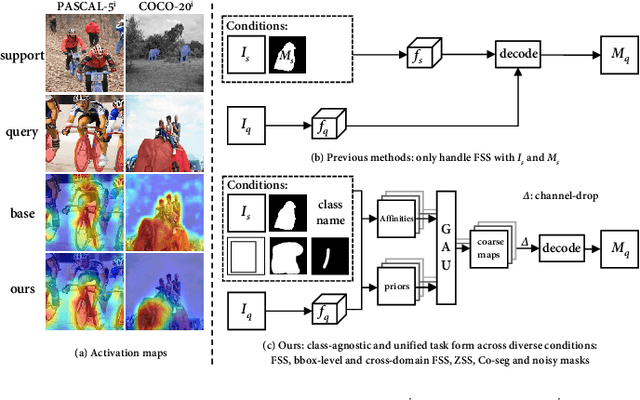
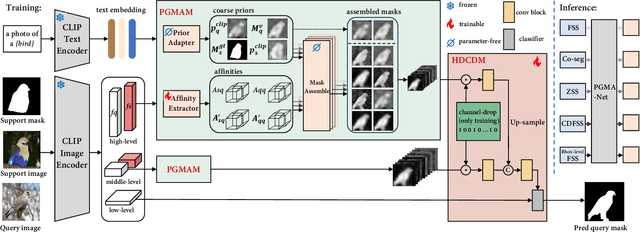
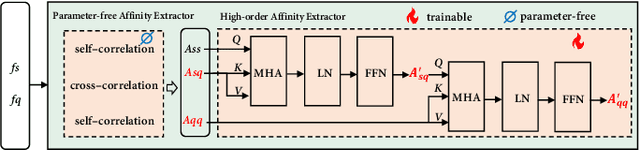
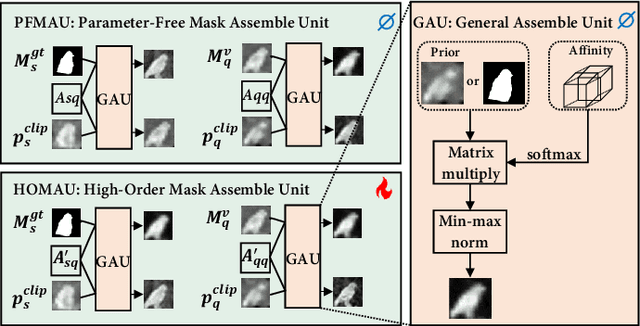
Few-shot segmentation (FSS) aims to segment the novel classes with a few annotated images. Due to CLIP's advantages of aligning visual and textual information, the integration of CLIP can enhance the generalization ability of FSS model. However, even with the CLIP model, the existing CLIP-based FSS methods are still subject to the biased prediction towards base classes, which is caused by the class-specific feature level interactions. To solve this issue, we propose a visual and textual Prior Guided Mask Assemble Network (PGMA-Net). It employs a class-agnostic mask assembly process to alleviate the bias, and formulates diverse tasks into a unified manner by assembling the prior through affinity. Specifically, the class-relevant textual and visual features are first transformed to class-agnostic prior in the form of probability map. Then, a Prior-Guided Mask Assemble Module (PGMAM) including multiple General Assemble Units (GAUs) is introduced. It considers diverse and plug-and-play interactions, such as visual-textual, inter- and intra-image, training-free, and high-order ones. Lastly, to ensure the class-agnostic ability, a Hierarchical Decoder with Channel-Drop Mechanism (HDCDM) is proposed to flexibly exploit the assembled masks and low-level features, without relying on any class-specific information. It achieves new state-of-the-art results in the FSS task, with mIoU of $77.6$ on $\text{PASCAL-}5^i$ and $59.4$ on $\text{COCO-}20^i$ in 1-shot scenario. Beyond this, we show that without extra re-training, the proposed PGMA-Net can solve bbox-level and cross-domain FSS, co-segmentation, zero-shot segmentation (ZSS) tasks, leading an any-shot segmentation framework.
GAMER-MRIL identifies Disability-Related Brain Changes in Multiple Sclerosis
Aug 15, 2023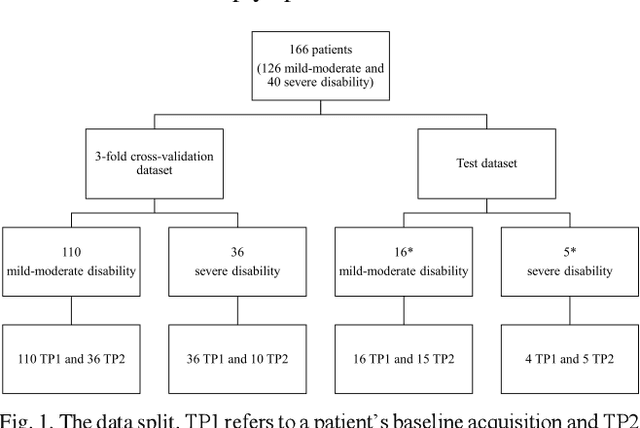
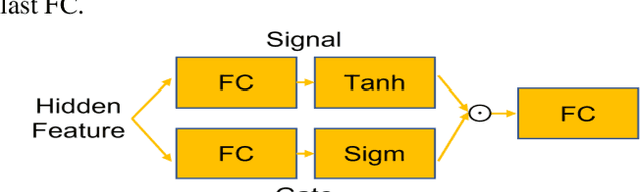
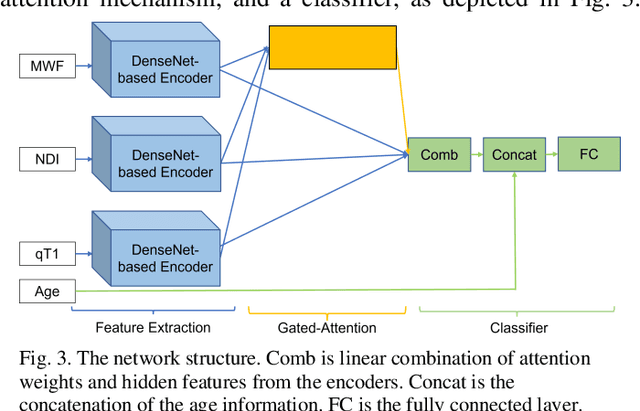
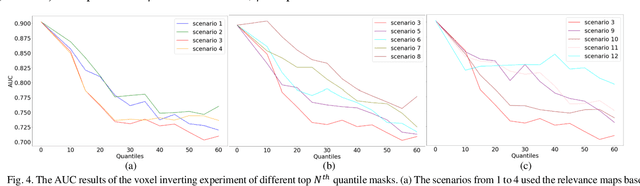
Objective: Identifying disability-related brain changes is important for multiple sclerosis (MS) patients. Currently, there is no clear understanding about which pathological features drive disability in single MS patients. In this work, we propose a novel comprehensive approach, GAMER-MRIL, leveraging whole-brain quantitative MRI (qMRI), convolutional neural network (CNN), and an interpretability method from classifying MS patients with severe disability to investigating relevant pathological brain changes. Methods: One-hundred-sixty-six MS patients underwent 3T MRI acquisitions. qMRI informative of microstructural brain properties was reconstructed, including quantitative T1 (qT1), myelin water fraction (MWF), and neurite density index (NDI). To fully utilize the qMRI, GAMER-MRIL extended a gated-attention-based CNN (GAMER-MRI), which was developed to select patch-based qMRI important for a given task/question, to the whole-brain image. To find out disability-related brain regions, GAMER-MRIL modified a structure-aware interpretability method, Layer-wise Relevance Propagation (LRP), to incorporate qMRI. Results: The test performance was AUC=0.885. qT1 was the most sensitive measure related to disability, followed by NDI. The proposed LRP approach obtained more specifically relevant regions than other interpretability methods, including the saliency map, the integrated gradients, and the original LRP. The relevant regions included the corticospinal tract, where average qT1 and NDI significantly correlated with patients' disability scores ($\rho$=-0.37 and 0.44). Conclusion: These results demonstrated that GAMER-MRIL can classify patients with severe disability using qMRI and subsequently identify brain regions potentially important to the integrity of the mobile function. Significance: GAMER-MRIL holds promise for developing biomarkers and increasing clinicians' trust in NN.
CortexMorph: fast cortical thickness estimation via diffeomorphic registration using VoxelMorph
Jul 21, 2023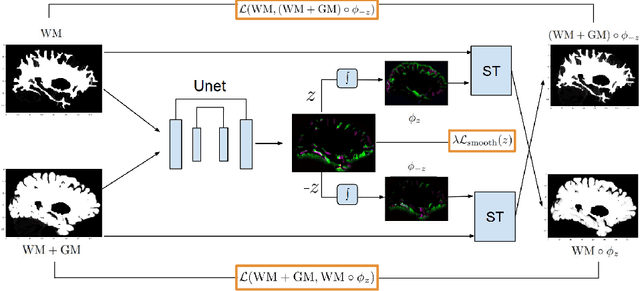
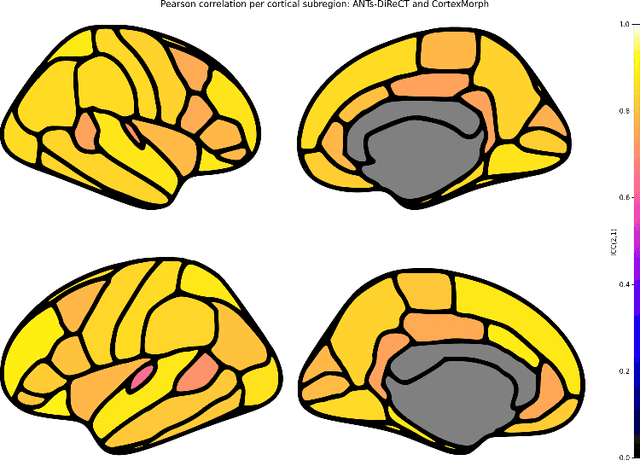
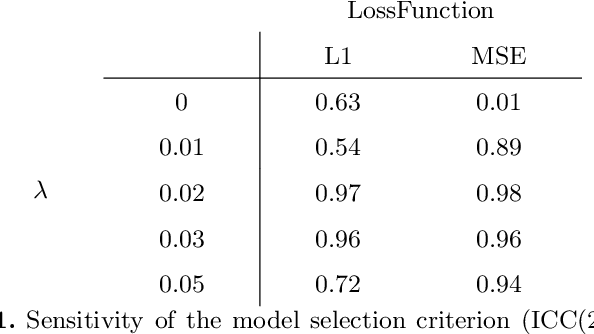
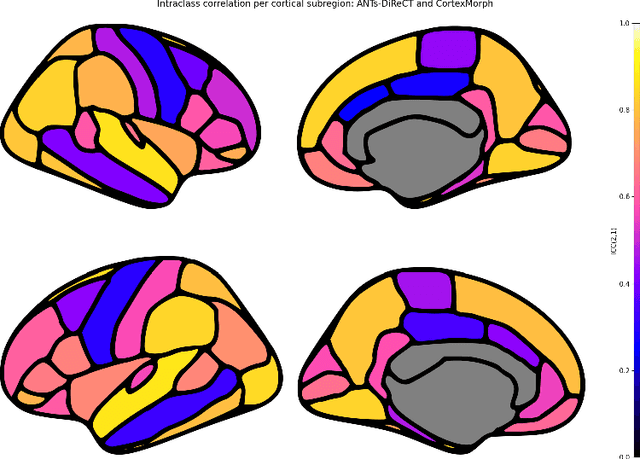
The thickness of the cortical band is linked to various neurological and psychiatric conditions, and is often estimated through surface-based methods such as Freesurfer in MRI studies. The DiReCT method, which calculates cortical thickness using a diffeomorphic deformation of the gray-white matter interface towards the pial surface, offers an alternative to surface-based methods. Recent studies using a synthetic cortical thickness phantom have demonstrated that the combination of DiReCT and deep-learning-based segmentation is more sensitive to subvoxel cortical thinning than Freesurfer. While anatomical segmentation of a T1-weighted image now takes seconds, existing implementations of DiReCT rely on iterative image registration methods which can take up to an hour per volume. On the other hand, learning-based deformable image registration methods like VoxelMorph have been shown to be faster than classical methods while improving registration accuracy. This paper proposes CortexMorph, a new method that employs unsupervised deep learning to directly regress the deformation field needed for DiReCT. By combining CortexMorph with a deep-learning-based segmentation model, it is possible to estimate region-wise thickness in seconds from a T1-weighted image, while maintaining the ability to detect cortical atrophy. We validate this claim on the OASIS-3 dataset and the synthetic cortical thickness phantom of Rusak et al.
DeepMerge: Deep Learning-Based Region-Merging for Image Segmentation
May 31, 2023

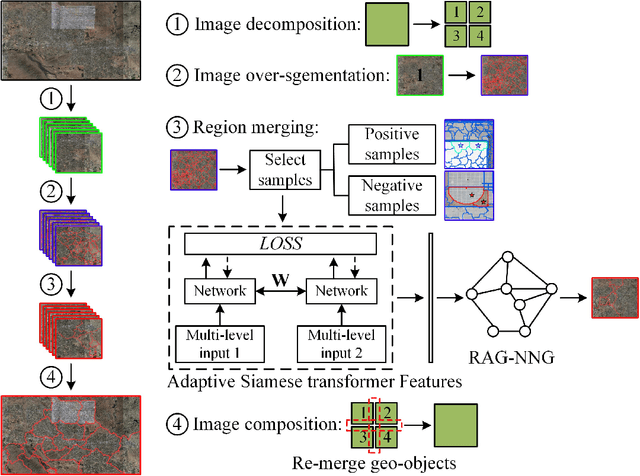
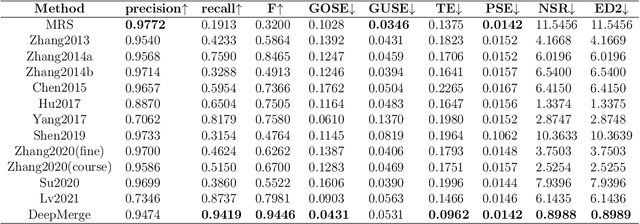
Accurate segmentation of large areas from very high spatial-resolution (VHR) remote sensing imagery remains a challenging issue in image analysis. Existing supervised and unsupervised methods both suffer from the large variance of object sizes and the difficulty in scale selection, which often result in poor segmentation accuracies. To address the above challenges, we propose a deep learning-based region-merging method (DeepMerge) to handle the segmentation in large VHR images by integrating a Transformer with a multi-level embedding module, a segment-based feature embedding module and a region-adjacency graph model. In addition, we propose a modified binary tree sampling method to generate multi-level inputs from initial segmentation results, serving as inputs for the DeepMerge model. To our best knowledge, the proposed method is the first to use deep learning to learn the similarity between adjacent segments for region-merging. The proposed DeepMerge method is validated using a remote sensing image of 0.55m resolution covering an area of 5,660 km^2 acquired from Google Earth. The experimental results show that the proposed DeepMerge with the highest F value (0.9446) and the lowest TE (0.0962) and ED2 (0.8989) is able to correctly segment objects of different sizes and outperforms all selected competing segmentation methods from both quantitative and qualitative assessments.