 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BHSD: A 3D Multi-Class Brain Hemorrhage Segmentation Dataset
Aug 23, 2023
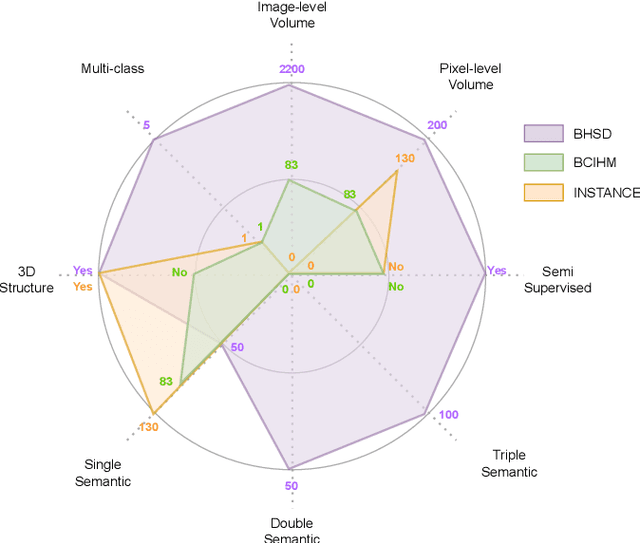
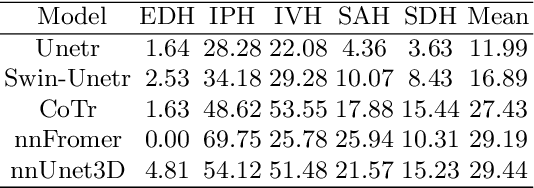
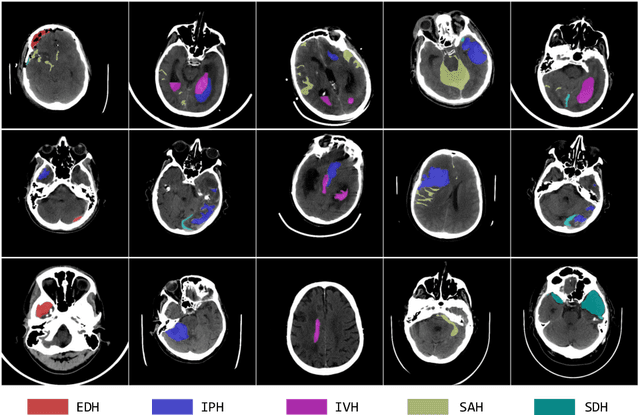
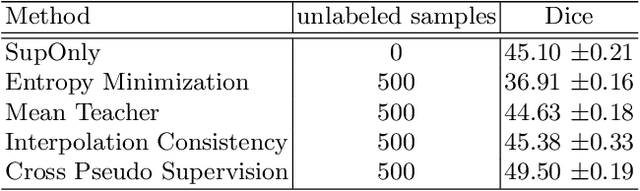
Intracranial hemorrhage (ICH) is a pathological condition characterized by bleeding inside the skull or brain, which can be attributed to various factors. Identifying, localizing and quantifying ICH has important clinical implications, in a bleed-dependent manner. While deep learning techniques are widely used in medical image segmentation and have been applied to the ICH segmentation task, existing public ICH datasets do not support the multi-class segmentation problem. To address this, we develop the Brain Hemorrhage Segmentation Dataset (BHSD), which provides a 3D multi-class ICH dataset containing 192 volumes with pixel-level annotations and 2200 volumes with slice-level annotations across five categories of ICH. To demonstrate the utility of the dataset, we formulate a series of supervised and semi-supervised ICH segmentation tasks. We provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset.
Mirror Diffusion Models
Aug 18, 2023Diffusion models have successfully been applied to generative tasks in various continuous domains. However, applying diffusion to discrete categorical data remains a non-trivial task. Moreover, generation in continuous domains often requires clipping in practice, which motivates the need for a theoretical framework for adapting diffusion to constrained domains. Inspired by the mirror Langevin algorithm for the constrained sampling problem, in this theoretical report we propose Mirror Diffusion Models (MDMs). We demonstrate MDMs in the context of simplex diffusion and propose natural extensions to popular domains such as image and text generation.
DiT: Efficient Vision Transformers with Dynamic Token Routing
Aug 11, 2023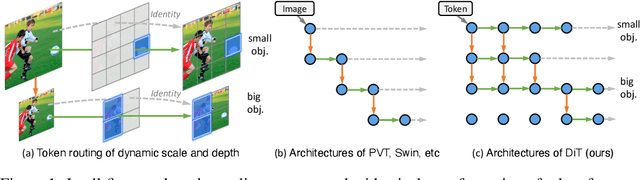
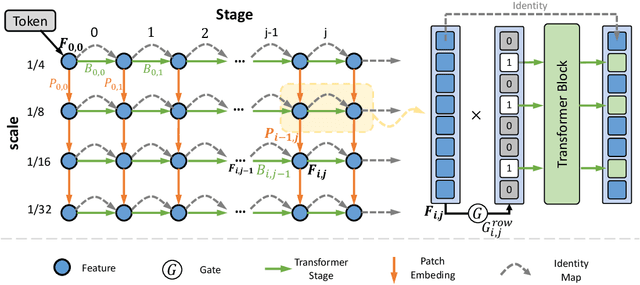
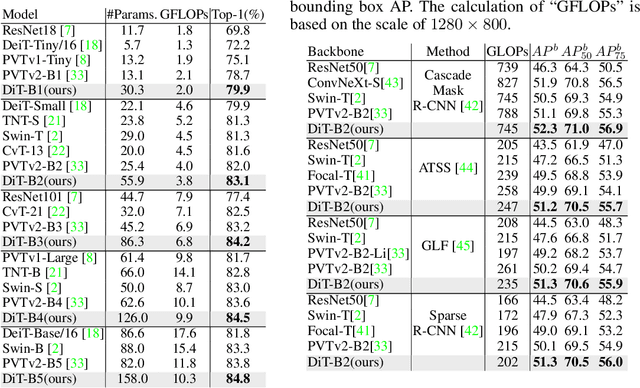
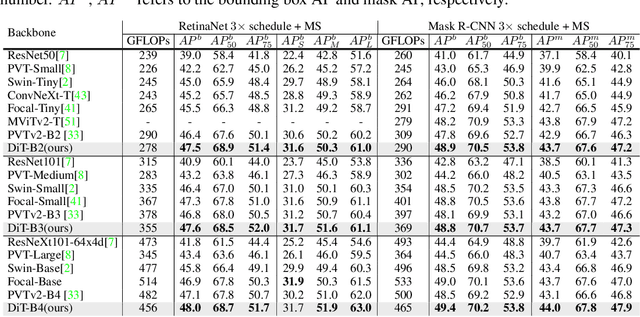
Recently, the tokens of images share the same static data flow in many dense networks. However, challenges arise from the variance among the objects in images, such as large variations in the spatial scale and difficulties of recognition for visual entities. In this paper, we propose a data-dependent token routing strategy to elaborate the routing paths of image tokens for Dynamic Vision Transformer, dubbed DiT. The proposed framework generates a data-dependent path per token, adapting to the object scales and visual discrimination of tokens. In feed-forward, the differentiable routing gates are designed to select the scaling paths and feature transformation paths for image tokens, leading to multi-path feature propagation. In this way, the impact of object scales and visual discrimination of image representation can be carefully tuned. Moreover, the computational cost can be further reduced by giving budget constraints to the routing gate and early-stopping of feature extraction. In experiments, our DiT achieves superior performance and favorable complexity/accuracy trade-offs than many SoTA methods on ImageNet classification, object detection, instance segmentation, and semantic segmentation. Particularly, the DiT-B5 obtains 84.8\% top-1 Acc on ImageNet with 10.3 GFLOPs, which is 1.0\% higher than that of the SoTA method with similar computational complexity. These extensive results demonstrate that DiT can serve as versatile backbones for various vision tasks.
Taming the Power of Diffusion Models for High-Quality Virtual Try-On with Appearance Flow
Aug 11, 2023

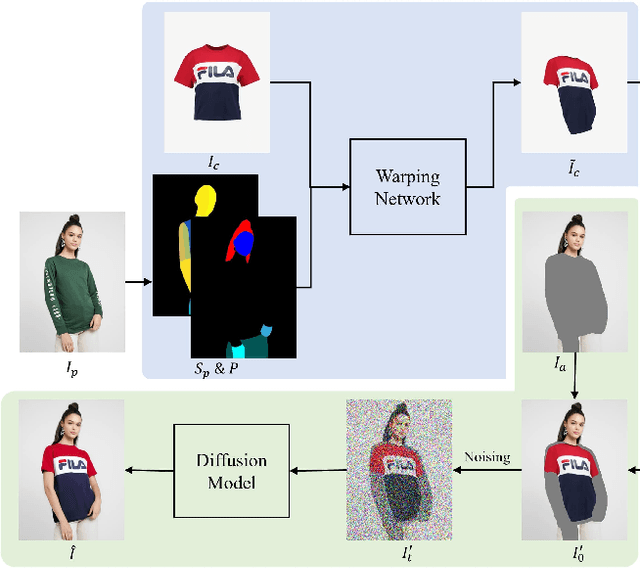
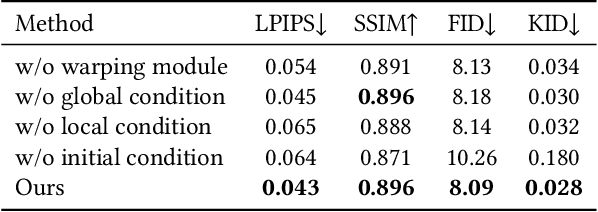
Virtual try-on is a critical image synthesis task that aims to transfer clothes from one image to another while preserving the details of both humans and clothes. While many existing methods rely on Generative Adversarial Networks (GANs) to achieve this, flaws can still occur, particularly at high resolutions. Recently, the diffusion model has emerged as a promising alternative for generating high-quality images in various applications. However, simply using clothes as a condition for guiding the diffusion model to inpaint is insufficient to maintain the details of the clothes. To overcome this challenge, we propose an exemplar-based inpainting approach that leverages a warping module to guide the diffusion model's generation effectively. The warping module performs initial processing on the clothes, which helps to preserve the local details of the clothes. We then combine the warped clothes with clothes-agnostic person image and add noise as the input of diffusion model. Additionally, the warped clothes is used as local conditions for each denoising process to ensure that the resulting output retains as much detail as possible. Our approach, namely Diffusion-based Conditional Inpainting for Virtual Try-ON (DCI-VTON), effectively utilizes the power of the diffusion model, and the incorporation of the warping module helps to produce high-quality and realistic virtual try-on results. Experimental results on VITON-HD demonstrate the effectiveness and superiority of our method.
Group-Conditional Conformal Prediction via Quantile Regression Calibration for Crop and Weed Classification
Aug 29, 2023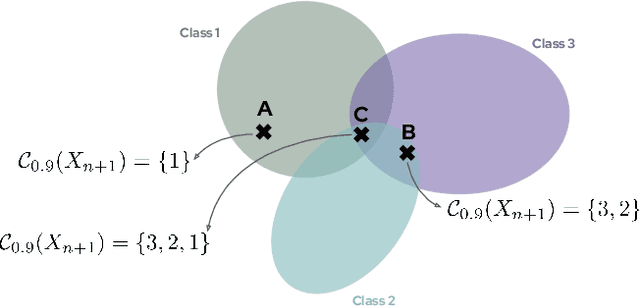

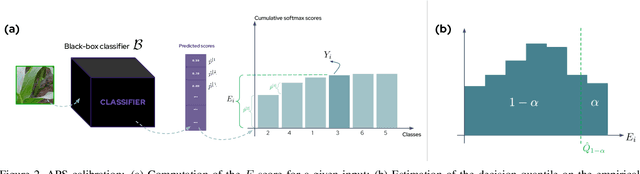
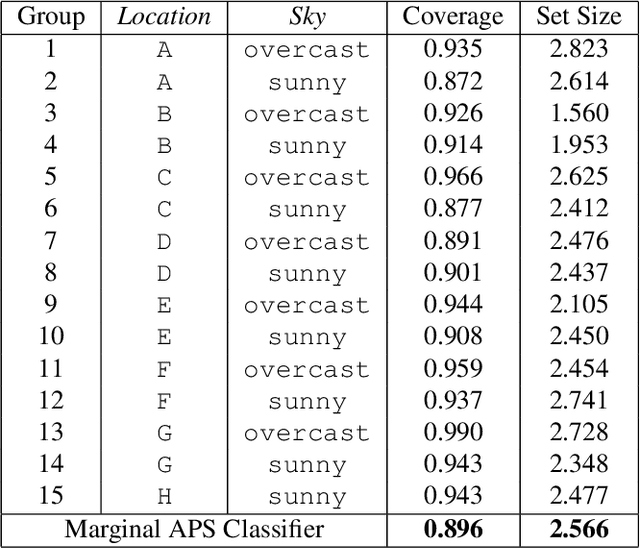
As deep learning predictive models become an integral part of a large spectrum of precision agricultural systems, a barrier to the adoption of such automated solutions is the lack of user trust in these highly complex, opaque and uncertain models. Indeed, deep neural networks are not equipped with any explicit guarantees that can be used to certify the system's performance, especially in highly varying uncontrolled environments such as the ones typically faced in computer vision for agriculture.Fortunately, certain methods developed in other communities can prove to be important for agricultural applications. This article presents the conformal prediction framework that provides valid statistical guarantees on the predictive performance of any black box prediction machine, with almost no assumptions, applied to the problem of deep visual classification of weeds and crops in real-world conditions. The framework is exposed with a focus on its practical aspects and special attention accorded to the Adaptive Prediction Sets (APS) approach that delivers marginal guarantees on the model's coverage. Marginal results are then shown to be insufficient to guarantee performance on all groups of individuals in the population as characterized by their environmental and pedo-climatic auxiliary data gathered during image acquisition.To tackle this shortcoming, group-conditional conformal approaches are presented: the ''classical'' method that consists of iteratively applying the APS procedure on all groups, and a proposed elegant reformulation and implementation of the procedure using quantile regression on group membership indicators. Empirical results showing the validity of the proposed approach are presented and compared to the marginal APS then discussed.
CEFHRI: A Communication Efficient Federated Learning Framework for Recognizing Industrial Human-Robot Interaction
Aug 29, 2023Human-robot interaction (HRI) is a rapidly growing field that encompasses social and industrial applications. Machine learning plays a vital role in industrial HRI by enhancing the adaptability and autonomy of robots in complex environments. However, data privacy is a crucial concern in the interaction between humans and robots, as companies need to protect sensitive data while machine learning algorithms require access to large datasets. Federated Learning (FL) offers a solution by enabling the distributed training of models without sharing raw data. Despite extensive research on Federated learning (FL) for tasks such as natural language processing (NLP) and image classification, the question of how to use FL for HRI remains an open research problem. The traditional FL approach involves transmitting large neural network parameter matrices between the server and clients, which can lead to high communication costs and often becomes a bottleneck in FL. This paper proposes a communication-efficient FL framework for human-robot interaction (CEFHRI) to address the challenges of data heterogeneity and communication costs. The framework leverages pre-trained models and introduces a trainable spatiotemporal adapter for video understanding tasks in HRI. Experimental results on three human-robot interaction benchmark datasets: HRI30, InHARD, and COIN demonstrate the superiority of CEFHRI over full fine-tuning in terms of communication costs. The proposed methodology provides a secure and efficient approach to HRI federated learning, particularly in industrial environments with data privacy concerns and limited communication bandwidth. Our code is available at https://github.com/umarkhalidAI/CEFHRI-Efficient-Federated-Learning.
Open Gaze: Open Source eye tracker for smartphone devices using Deep Learning
Aug 29, 2023Eye tracking has been a pivotal tool in diverse fields such as vision research, language analysis, and usability assessment. The majority of prior investigations, however, have concentrated on expansive desktop displays employing specialized, costly eye tracking hardware that lacks scalability. Remarkably little insight exists into ocular movement patterns on smartphones, despite their widespread adoption and significant usage. In this manuscript, we present an open-source implementation of a smartphone-based gaze tracker that emulates the methodology proposed by a GooglePaper (whose source code remains proprietary). Our focus is on attaining accuracy comparable to that attained through the GooglePaper's methodology, without the necessity for supplementary hardware. Through the integration of machine learning techniques, we unveil an accurate eye tracking solution that is native to smartphones. Our approach demonstrates precision akin to the state-of-the-art mobile eye trackers, which are characterized by a cost that is two orders of magnitude higher. Leveraging the vast MIT GazeCapture dataset, which is available through registration on the dataset's website, we successfully replicate crucial findings from previous studies concerning ocular motion behavior in oculomotor tasks and saliency analyses during natural image observation. Furthermore, we emphasize the applicability of smartphone-based gaze tracking in discerning reading comprehension challenges. Our findings exhibit the inherent potential to amplify eye movement research by significant proportions, accommodating participation from thousands of subjects with explicit consent. This scalability not only fosters advancements in vision research, but also extends its benefits to domains such as accessibility enhancement and healthcare applications.
End-to-end Remote Sensing Change Detection of Unregistered Bi-temporal Images for Natural Disasters
Aug 16, 2023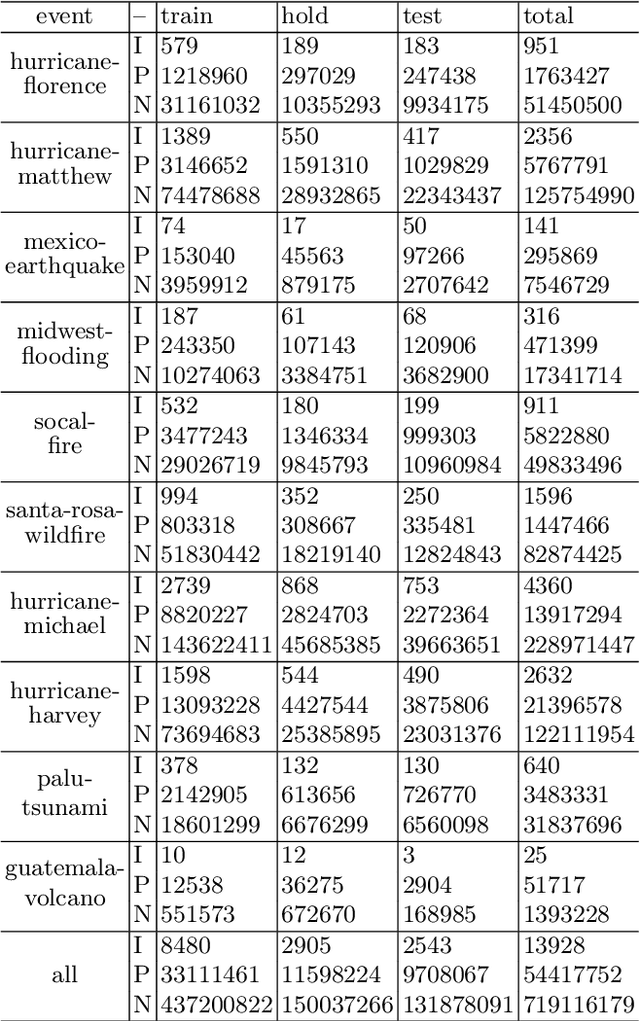
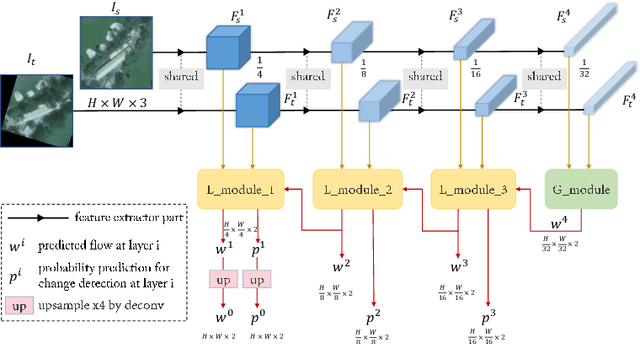
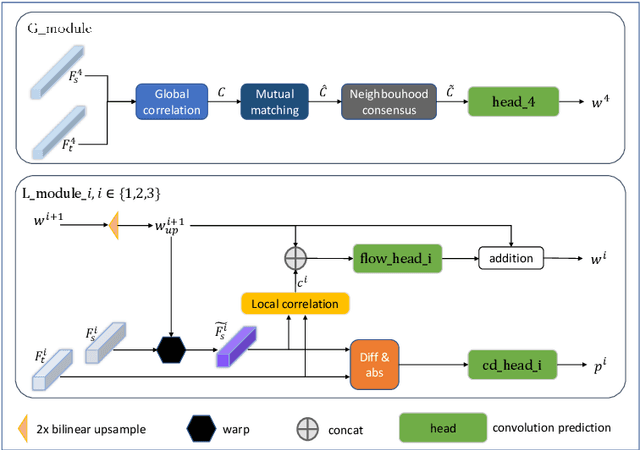

Change detection based on remote sensing images has been a prominent area of interest in the field of remote sensing. Deep networks have demonstrated significant success in detecting changes in bi-temporal remote sensing images and have found applications in various fields. Given the degradation of natural environments and the frequent occurrence of natural disasters, accurately and swiftly identifying damaged buildings in disaster-stricken areas through remote sensing images holds immense significance. This paper aims to investigate change detection specifically for natural disasters. Considering that existing public datasets used in change detection research are registered, which does not align with the practical scenario where bi-temporal images are not matched, this paper introduces an unregistered end-to-end change detection synthetic dataset called xBD-E2ECD. Furthermore, we propose an end-to-end change detection network named E2ECDNet, which takes an unregistered bi-temporal image pair as input and simultaneously generates the flow field prediction result and the change detection prediction result. It is worth noting that our E2ECDNet also supports change detection for registered image pairs, as registration can be seen as a special case of non-registration. Additionally, this paper redefines the criteria for correctly predicting a positive case and introduces neighborhood-based change detection evaluation metrics. The experimental results have demonstrated significant improvements.
RegionBLIP: A Unified Multi-modal Pre-training Framework for Holistic and Regional Comprehension
Aug 03, 2023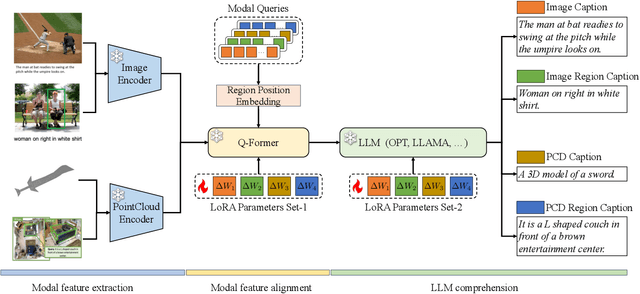
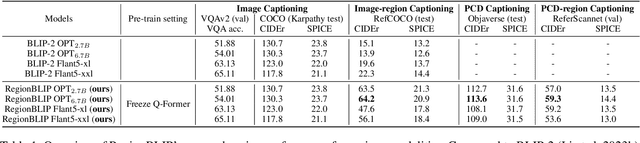


In this work, we investigate extending the comprehension of Multi-modal Large Language Models (MLLMs) to regional objects. To this end, we propose to extract features corresponding to regional objects as soft prompts for LLM, which provides a straightforward and scalable approach and eliminates the need for LLM fine-tuning. To effectively extract regional features from regular image features and irregular point cloud features, we present a novel and unified position-assisted feature extraction module. Furthermore, training an MLLM from scratch is highly time-consuming. Thus, we propose incrementally extending existing pre-trained MLLMs to comprehend more modalities and the regional objects of those modalities. Specifically, we freeze the Q-Former from BLIP-2, an impressive MLLM, and optimize the modality-specific Lora parameters in Q-Former and LLM for each newly introduced modality. The freezing of the Q-Former eliminates the need for extensive pre-training on massive image-text data. The freezed Q-Former pre-trained from massive image-text data is also beneficial for the pre-training on image-region-text data. We name our framework RegionBLIP. We pre-train RegionBLIP on image-region-text, point-cloud-text, and point-cloud-region-text data. Experimental results verify that \Ours{} can preserve the image comprehension capability of BILP-2 and further gain a comprehension of the newly introduced point cloud modality and regional objects. The Data, Code, and Pre-trained models will be available at https://github.com/mightyzau/RegionBLIP.
More for Less: Compact Convolutional Transformers Enable Robust Medical Image Classification with Limited Data
Jul 01, 2023
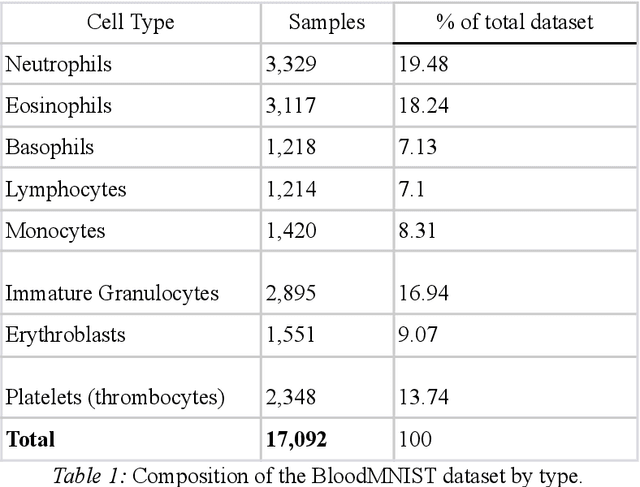
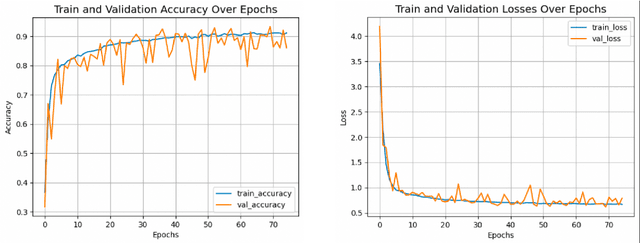
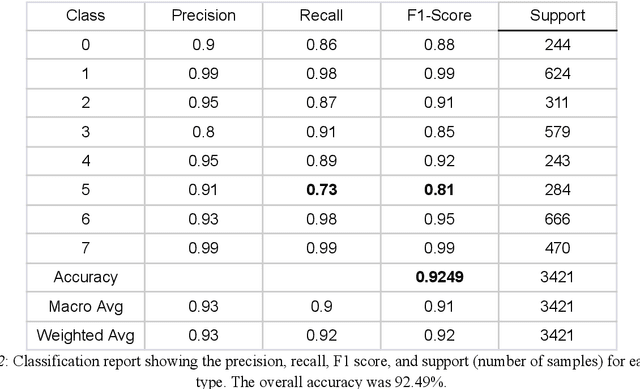
Transformers are very powerful tools for a variety of tasks across domains, from text generation to image captioning. However, transformers require substantial amounts of training data, which is often a challenge in biomedical settings, where high quality labeled data can be challenging or expensive to obtain. This study investigates the efficacy of Compact Convolutional Transformers (CCT) for robust medical image classification with limited data, addressing a key issue faced by conventional Vision Transformers - their requirement for large datasets. A hybrid of transformers and convolutional layers, CCTs demonstrate high accuracy on modestly sized datasets. We employed a benchmark dataset of peripheral blood cell images of eight distinct cell types, each represented by approximately 2,000 low-resolution (28x28x3 pixel) samples. Despite the dataset size being smaller than those typically used with Vision Transformers, we achieved a commendable classification accuracy of 92.49% and a micro-average ROC AUC of 0.9935. The CCT also learned quickly, exceeding 80% validation accuracy after five epochs. Analysis of per-class precision, recall, F1, and ROC showed that performance was strong across cell types. Our findings underscore the robustness of CCTs, indicating their potential as a solution to data scarcity issues prevalent in biomedical imaging. We substantiate the applicability of CCTs in data-constrained areas and encourage further work on CCTs.