 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HPFormer: Hyperspectral image prompt object tracking
Aug 14, 2023

Hyperspectral imagery contains abundant spectral information beyond the visible RGB bands, providing rich discriminative details about objects in a scene. Leveraging such data has the potential to enhance visual tracking performance. While prior hyperspectral trackers employ CNN or hybrid CNN-Transformer architectures, we propose a novel approach HPFormer on Transformers to capitalize on their powerful representation learning capabilities. The core of HPFormer is a Hyperspectral Hybrid Attention (HHA) module which unifies feature extraction and fusion within one component through token interactions. Additionally, a Transform Band Module (TBM) is introduced to selectively aggregate spatial details and spectral signatures from the full hyperspectral input for injecting informative target representations. Extensive experiments demonstrate state-of-the-art performance of HPFormer on benchmark NIR and VIS tracking datasets. Our work provides new insights into harnessing the strengths of transformers and hyperspectral fusion to advance robust object tracking.
Efficient Transfer Learning in Diffusion Models via Adversarial Noise
Aug 23, 2023
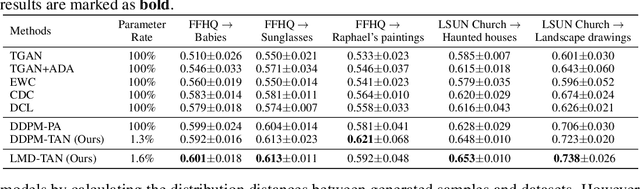
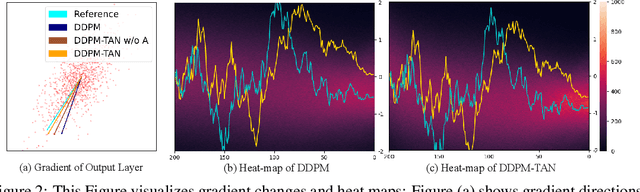

Diffusion Probabilistic Models (DPMs) have demonstrated substantial promise in image generation tasks but heavily rely on the availability of large amounts of training data. Previous works, like GANs, have tackled the limited data problem by transferring pre-trained models learned with sufficient data. However, those methods are hard to be utilized in DPMs since the distinct differences between DPM-based and GAN-based methods, showing in the unique iterative denoising process integral and the need for many timesteps with no-targeted noise in DPMs. In this paper, we propose a novel DPMs-based transfer learning method, TAN, to address the limited data problem. It includes two strategies: similarity-guided training, which boosts transfer with a classifier, and adversarial noise selection which adaptive chooses targeted noise based on the input image. Extensive experiments in the context of few-shot image generation tasks demonstrate that our method is not only efficient but also excels in terms of image quality and diversity when compared to existing GAN-based and DDPM-based methods.
TMComposites: Plug-and-Play Collaboration Between Specialized Tsetlin Machines
Sep 12, 2023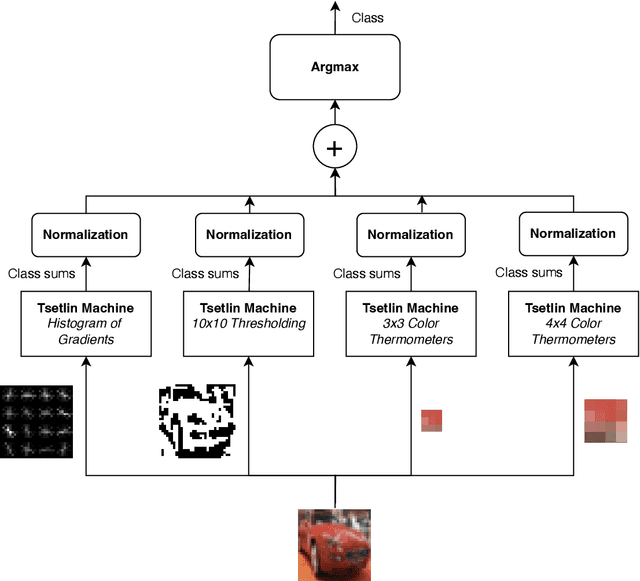

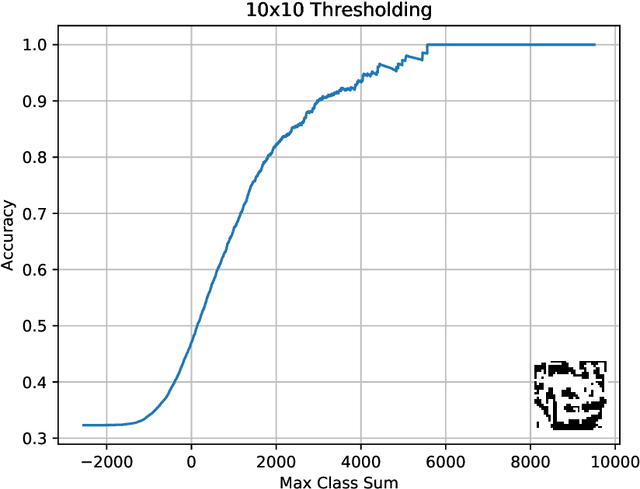
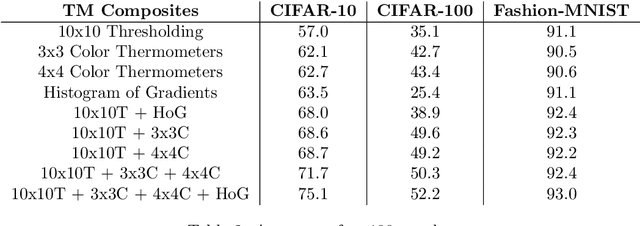
Tsetlin Machines (TMs) provide a fundamental shift from arithmetic-based to logic-based machine learning. Supporting convolution, they deal successfully with image classification datasets like MNIST, Fashion-MNIST, and CIFAR-2. However, the TM struggles with getting state-of-the-art performance on CIFAR-10 and CIFAR-100, representing more complex tasks. This paper introduces plug-and-play collaboration between specialized TMs, referred to as TM Composites. The collaboration relies on a TM's ability to specialize during learning and to assess its competence during inference. When teaming up, the most confident TMs make the decisions, relieving the uncertain ones. In this manner, a TM Composite becomes more competent than its members, benefiting from their specializations. The collaboration is plug-and-play in that members can be combined in any way, at any time, without fine-tuning. We implement three TM specializations in our empirical evaluation: Histogram of Gradients, Adaptive Gaussian Thresholding, and Color Thermometers. The resulting TM Composite increases accuracy on Fashion-MNIST by two percentage points, CIFAR-10 by twelve points, and CIFAR-100 by nine points, yielding new state-of-the-art results for TMs. Overall, we envision that TM Composites will enable an ultra-low energy and transparent alternative to state-of-the-art deep learning on more tasks and datasets.
Jersey Number Recognition using Keyframe Identification from Low-Resolution Broadcast Videos
Sep 12, 2023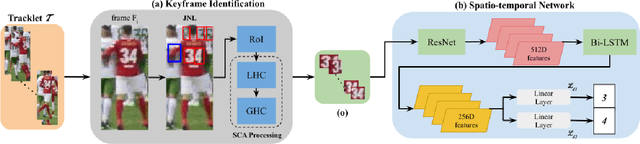
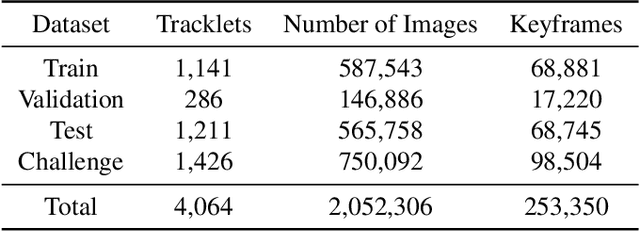
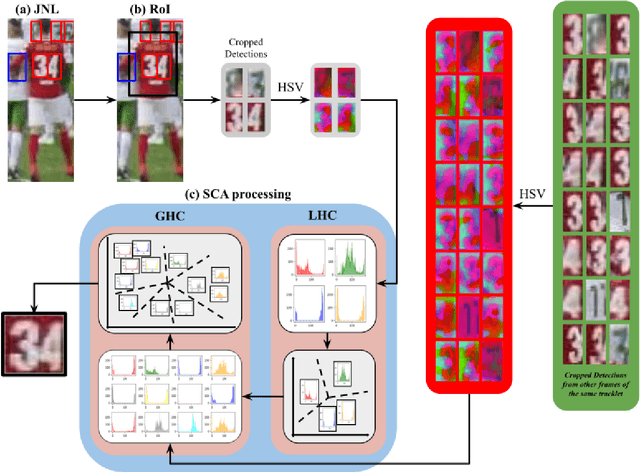
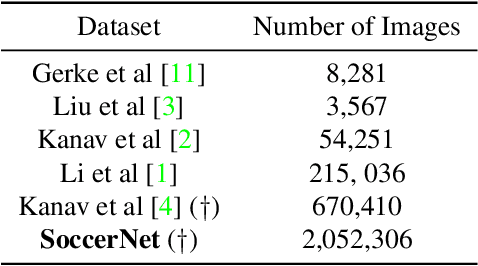
Player identification is a crucial component in vision-driven soccer analytics, enabling various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatically detecting jersey numbers from player tracklets in videos presents challenges due to motion blur, low resolution, distortions, and occlusions. Existing methods, utilizing Spatial Transformer Networks, CNNs, and Vision Transformers, have shown success in image data but struggle with real-world video data, where jersey numbers are not visible in most of the frames. Hence, identifying frames that contain the jersey number is a key sub-problem to tackle. To address these issues, we propose a robust keyframe identification module that extracts frames containing essential high-level information about the jersey number. A spatio-temporal network is then employed to model spatial and temporal context and predict the probabilities of jersey numbers in the video. Additionally, we adopt a multi-task loss function to predict the probability distribution of each digit separately. Extensive evaluations on the SoccerNet dataset demonstrate that incorporating our proposed keyframe identification module results in a significant 37.81% and 37.70% increase in the accuracies of 2 different test sets with domain gaps. These results highlight the effectiveness and importance of our approach in tackling the challenges of automatic jersey number detection in sports videos.
Quality-Agnostic Deepfake Detection with Intra-model Collaborative Learning
Sep 12, 2023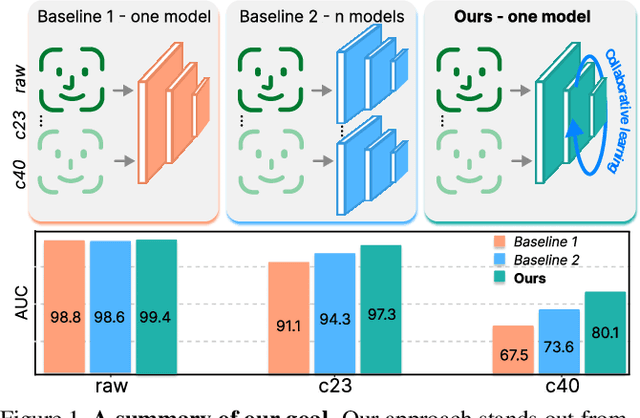
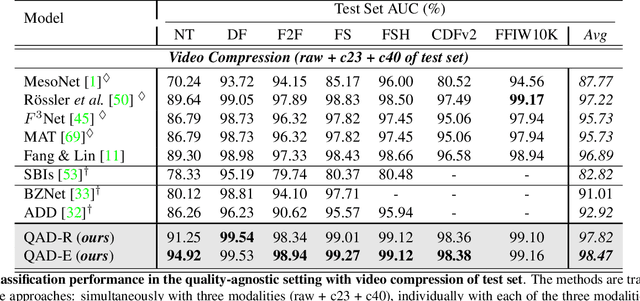
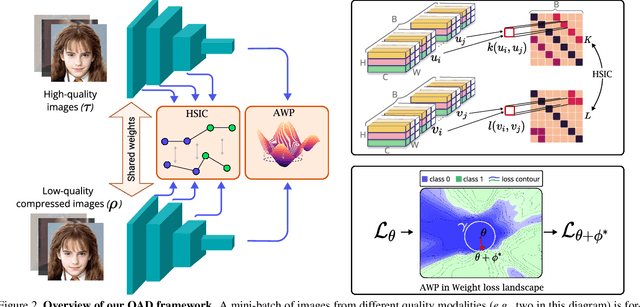
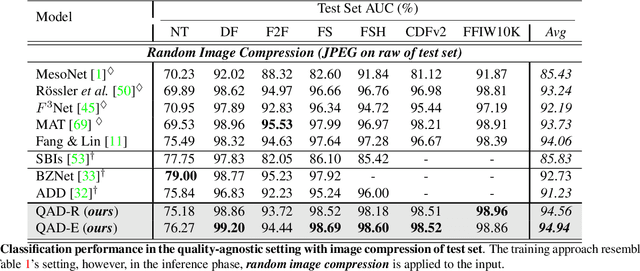
Deepfake has recently raised a plethora of societal concerns over its possible security threats and dissemination of fake information. Much research on deepfake detection has been undertaken. However, detecting low quality as well as simultaneously detecting different qualities of deepfakes still remains a grave challenge. Most SOTA approaches are limited by using a single specific model for detecting certain deepfake video quality type. When constructing multiple models with prior information about video quality, this kind of strategy incurs significant computational cost, as well as model and training data overhead. Further, it cannot be scalable and practical to deploy in real-world settings. In this work, we propose a universal intra-model collaborative learning framework to enable the effective and simultaneous detection of different quality of deepfakes. That is, our approach is the quality-agnostic deepfake detection method, dubbed QAD . In particular, by observing the upper bound of general error expectation, we maximize the dependency between intermediate representations of images from different quality levels via Hilbert-Schmidt Independence Criterion. In addition, an Adversarial Weight Perturbation module is carefully devised to enable the model to be more robust against image corruption while boosting the overall model's performance. Extensive experiments over seven popular deepfake datasets demonstrate the superiority of our QAD model over prior SOTA benchmarks.
MoMA: Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation for Histopathology Image Analysis
Aug 31, 2023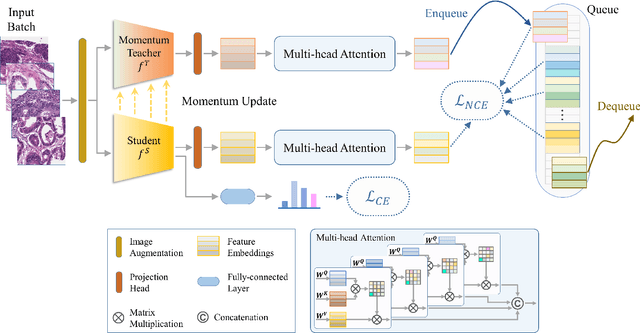
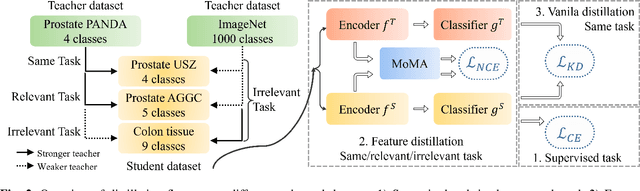
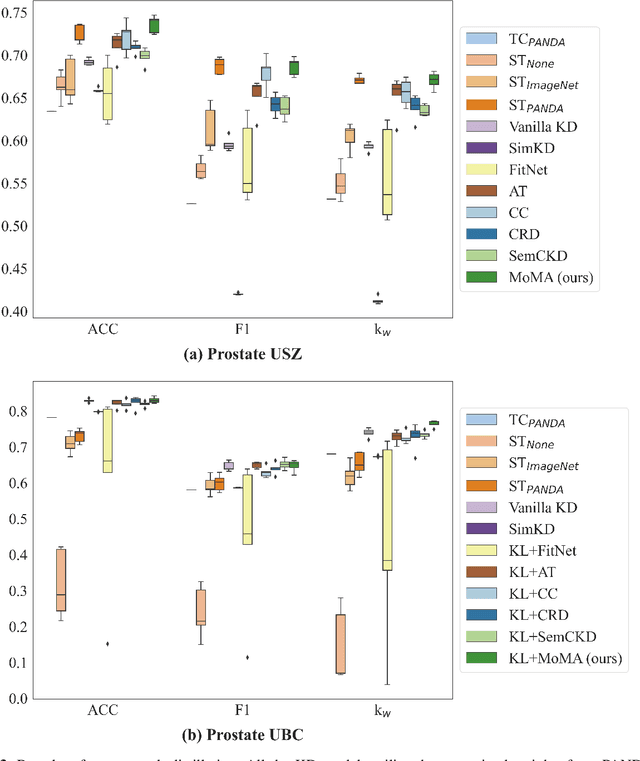
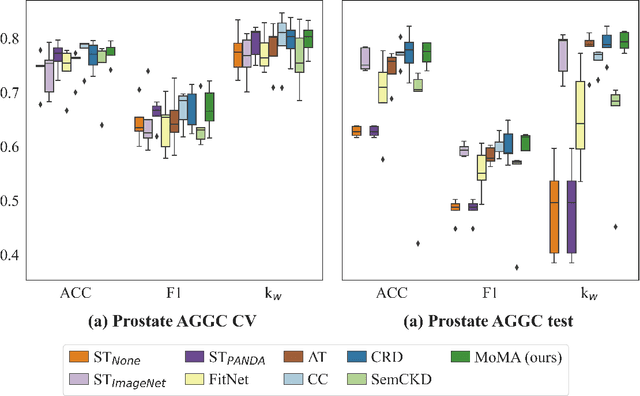
There is no doubt that advanced artificial intelligence models and high quality data are the keys to success in developing computational pathology tools. Although the overall volume of pathology data keeps increasing, a lack of quality data is a common issue when it comes to a specific task due to several reasons including privacy and ethical issues with patient data. In this work, we propose to exploit knowledge distillation, i.e., utilize the existing model to learn a new, target model, to overcome such issues in computational pathology. Specifically, we employ a student-teacher framework to learn a target model from a pre-trained, teacher model without direct access to source data and distill relevant knowledge via momentum contrastive learning with multi-head attention mechanism, which provides consistent and context-aware feature representations. This enables the target model to assimilate informative representations of the teacher model while seamlessly adapting to the unique nuances of the target data. The proposed method is rigorously evaluated across different scenarios where the teacher model was trained on the same, relevant, and irrelevant classification tasks with the target model. Experimental results demonstrate the accuracy and robustness of our approach in transferring knowledge to different domains and tasks, outperforming other related methods. Moreover, the results provide a guideline on the learning strategy for different types of tasks and scenarios in computational pathology. Code is available at: \url{https://github.com/trinhvg/MoMA}.
PFB-Diff: Progressive Feature Blending Diffusion for Text-driven Image Editing
Jun 28, 2023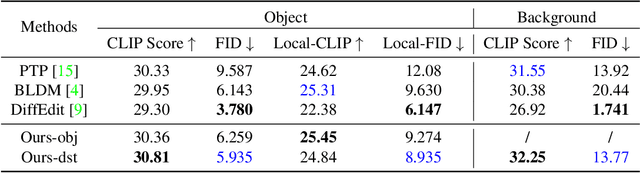
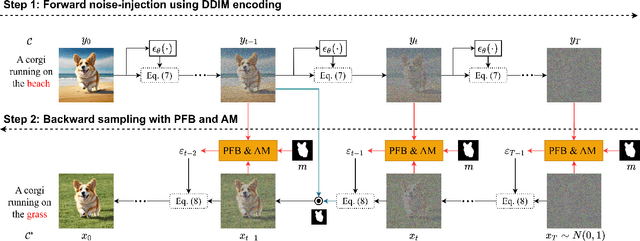

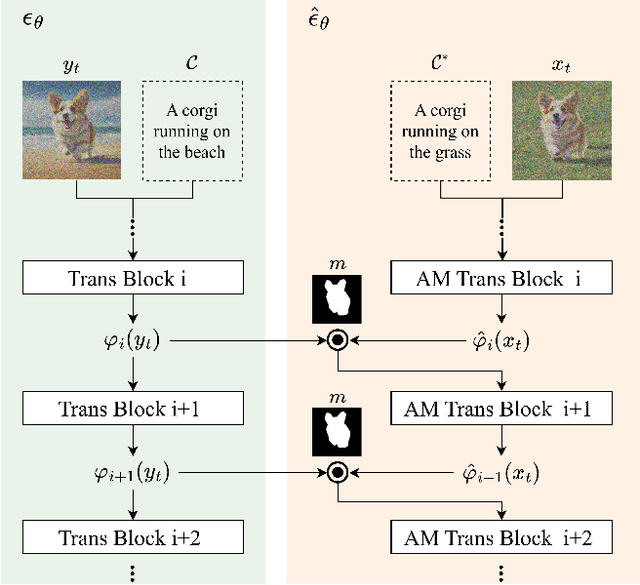
Diffusion models have showcased their remarkable capability to synthesize diverse and high-quality images, sparking interest in their application for real image editing. However, existing diffusion-based approaches for local image editing often suffer from undesired artifacts due to the pixel-level blending of the noised target images and diffusion latent variables, which lack the necessary semantics for maintaining image consistency. To address these issues, we propose PFB-Diff, a Progressive Feature Blending method for Diffusion-based image editing. Unlike previous methods, PFB-Diff seamlessly integrates text-guided generated content into the target image through multi-level feature blending. The rich semantics encoded in deep features and the progressive blending scheme from high to low levels ensure semantic coherence and high quality in edited images. Additionally, we introduce an attention masking mechanism in the cross-attention layers to confine the impact of specific words to desired regions, further improving the performance of background editing. PFB-Diff can effectively address various editing tasks, including object/background replacement and object attribute editing. Our method demonstrates its superior performance in terms of image fidelity, editing accuracy, efficiency, and faithfulness to the original image, without the need for fine-tuning or training.
Stream-based Active Learning by Exploiting Temporal Properties in Perception with Temporal Predicted Loss
Sep 11, 2023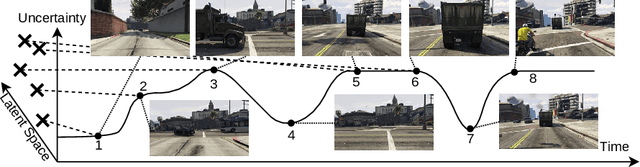
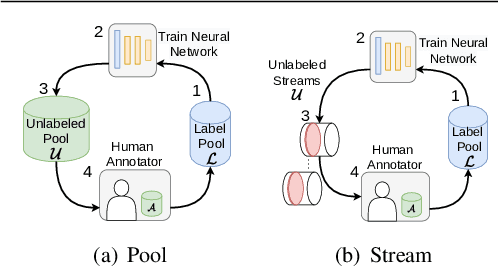
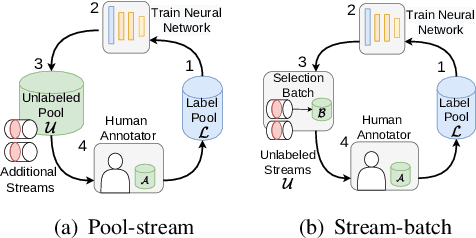

Active learning (AL) reduces the amount of labeled data needed to train a machine learning model by intelligently choosing which instances to label. Classic pool-based AL requires all data to be present in a datacenter, which can be challenging with the increasing amounts of data needed in deep learning. However, AL on mobile devices and robots, like autonomous cars, can filter the data from perception sensor streams before reaching the datacenter. We exploited the temporal properties for such image streams in our work and proposed the novel temporal predicted loss (TPL) method. To evaluate the stream-based setting properly, we introduced the GTA V streets and the A2D2 streets dataset and made both publicly available. Our experiments showed that our approach significantly improves the diversity of the selection while being an uncertainty-based method. As pool-based approaches are more common in perception applications, we derived a concept for comparing pool-based and stream-based AL, where TPL out-performed state-of-the-art pool- or stream-based approaches for different models. TPL demonstrated a gain of 2.5 precept points (pp) less required data while being significantly faster than pool-based methods.
Approximately Equivariant Graph Networks
Sep 03, 2023

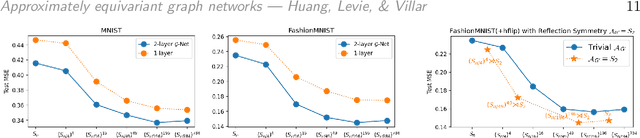

Graph neural networks (GNNs) are commonly described as being permutation equivariant with respect to node relabeling in the graph. This symmetry of GNNs is often compared to the translation equivariance symmetry of Euclidean convolution neural networks (CNNs). However, these two symmetries are fundamentally different: The translation equivariance of CNNs corresponds to symmetries of the fixed domain acting on the image signal (sometimes known as active symmetries), whereas in GNNs any permutation acts on both the graph signals and the graph domain (sometimes described as passive symmetries). In this work, we focus on the active symmetries of GNNs, by considering a learning setting where signals are supported on a fixed graph. In this case, the natural symmetries of GNNs are the automorphisms of the graph. Since real-world graphs tend to be asymmetric, we relax the notion of symmetries by formalizing approximate symmetries via graph coarsening. We present a bias-variance formula that quantifies the tradeoff between the loss in expressivity and the gain in the regularity of the learned estimator, depending on the chosen symmetry group. To illustrate our approach, we conduct extensive experiments on image inpainting, traffic flow prediction, and human pose estimation with different choices of symmetries. We show theoretically and empirically that the best generalization performance can be achieved by choosing a suitably larger group than the graph automorphism group, but smaller than the full permutation group.
Deep Unfolding Convolutional Dictionary Model for Multi-Contrast MRI Super-resolution and Reconstruction
Sep 03, 2023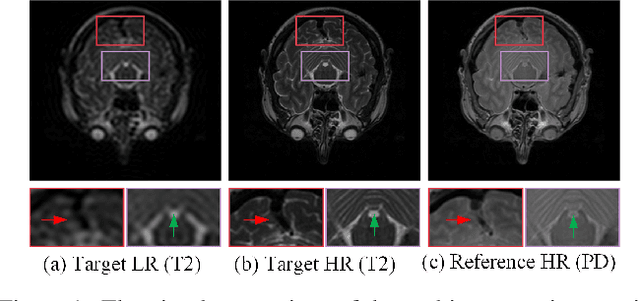
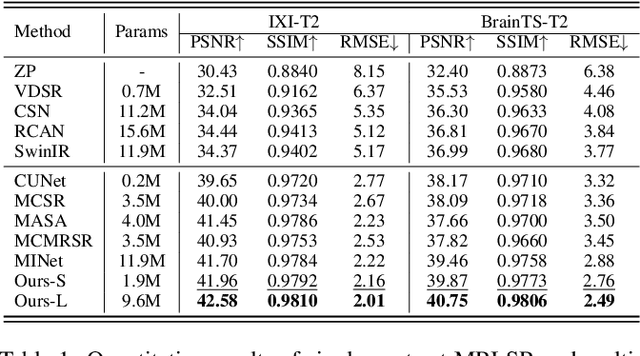
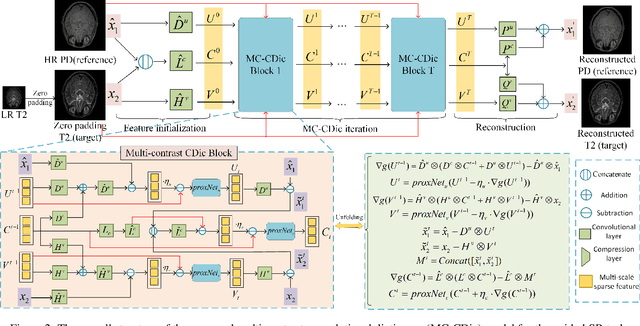
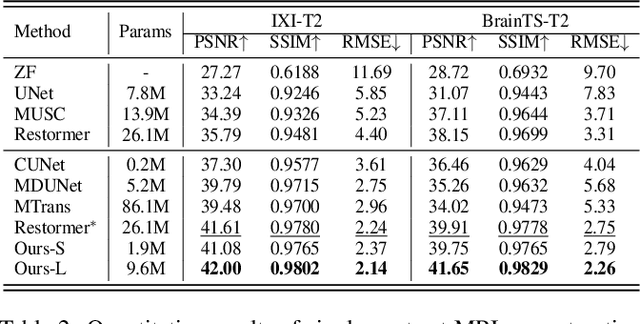
Magnetic resonance imaging (MRI) tasks often involve multiple contrasts. Recently, numerous deep learning-based multi-contrast MRI super-resolution (SR) and reconstruction methods have been proposed to explore the complementary information from the multi-contrast images. However, these methods either construct parameter-sharing networks or manually design fusion rules, failing to accurately model the correlations between multi-contrast images and lacking certain interpretations. In this paper, we propose a multi-contrast convolutional dictionary (MC-CDic) model under the guidance of the optimization algorithm with a well-designed data fidelity term. Specifically, we bulid an observation model for the multi-contrast MR images to explicitly model the multi-contrast images as common features and unique features. In this way, only the useful information in the reference image can be transferred to the target image, while the inconsistent information will be ignored. We employ the proximal gradient algorithm to optimize the model and unroll the iterative steps into a deep CDic model. Especially, the proximal operators are replaced by learnable ResNet. In addition, multi-scale dictionaries are introduced to further improve the model performance. We test our MC-CDic model on multi-contrast MRI SR and reconstruction tasks. Experimental results demonstrate the superior performance of the proposed MC-CDic model against existing SOTA methods. Code is available at https://github.com/lpcccc-cv/MC-CDic.