 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Socratis: Are large multimodal models emotionally aware?
Sep 05, 2023


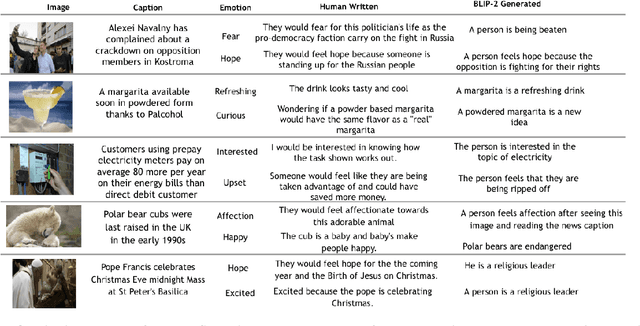
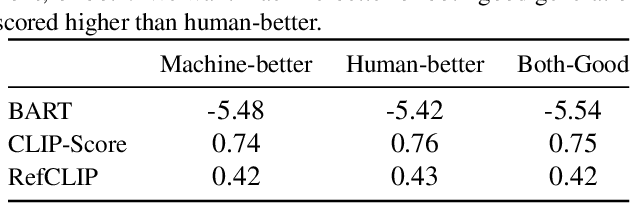
Existing emotion prediction benchmarks contain coarse emotion labels which do not consider the diversity of emotions that an image and text can elicit in humans due to various reasons. Learning diverse reactions to multimodal content is important as intelligent machines take a central role in generating and delivering content to society. To address this gap, we propose Socratis, a societal reactions benchmark, where each image-caption (IC) pair is annotated with multiple emotions and the reasons for feeling them. Socratis contains 18K free-form reactions for 980 emotions on 2075 image-caption pairs from 5 widely-read news and image-caption (IC) datasets. We benchmark the capability of state-of-the-art multimodal large language models to generate the reasons for feeling an emotion given an IC pair. Based on a preliminary human study, we observe that humans prefer human-written reasons over 2 times more often than machine-generated ones. This shows our task is harder than standard generation tasks because it starkly contrasts recent findings where humans cannot tell apart machine vs human-written news articles, for instance. We further see that current captioning metrics based on large vision-language models also fail to correlate with human preferences. We hope that these findings and our benchmark will inspire further research on training emotionally aware models.
WiSARD: A Labeled Visual and Thermal Image Dataset for Wilderness Search and Rescue
Sep 08, 2023Sensor-equipped unoccupied aerial vehicles (UAVs) have the potential to help reduce search times and alleviate safety risks for first responders carrying out Wilderness Search and Rescue (WiSAR) operations, the process of finding and rescuing person(s) lost in wilderness areas. Unfortunately, visual sensors alone do not address the need for robustness across all the possible terrains, weather, and lighting conditions that WiSAR operations can be conducted in. The use of multi-modal sensors, specifically visual-thermal cameras, is critical in enabling WiSAR UAVs to perform in diverse operating conditions. However, due to the unique challenges posed by the wilderness context, existing dataset benchmarks are inadequate for developing vision-based algorithms for autonomous WiSAR UAVs. To this end, we present WiSARD, a dataset with roughly 56,000 labeled visual and thermal images collected from UAV flights in various terrains, seasons, weather, and lighting conditions. To the best of our knowledge, WiSARD is the first large-scale dataset collected with multi-modal sensors for autonomous WiSAR operations. We envision that our dataset will provide researchers with a diverse and challenging benchmark that can test the robustness of their algorithms when applied to real-world (life-saving) applications.
Learning Semantic Segmentation with Query Points Supervision on Aerial Images
Sep 11, 2023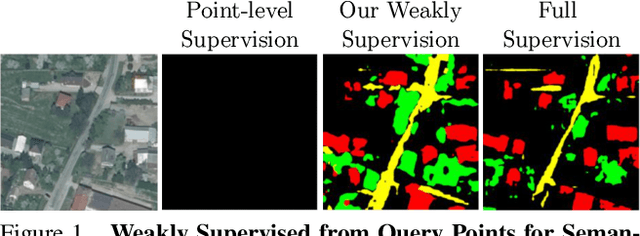
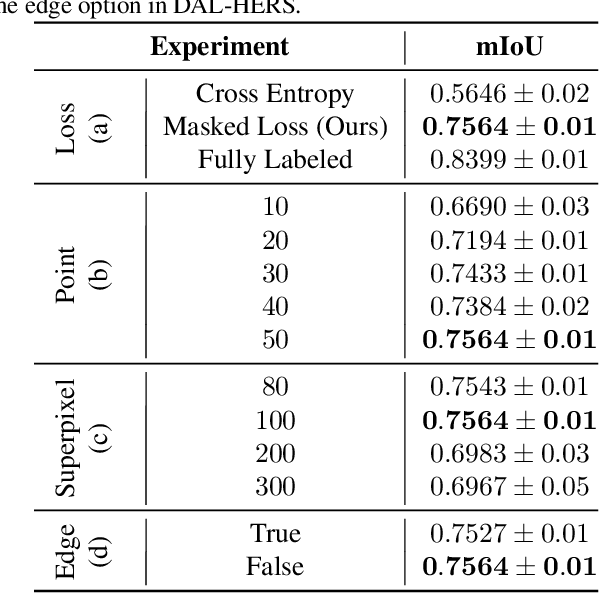
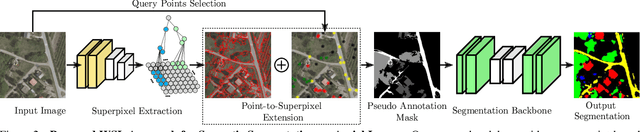
Semantic segmentation is crucial in remote sensing, where high-resolution satellite images are segmented into meaningful regions. Recent advancements in deep learning have significantly improved satellite image segmentation. However, most of these methods are typically trained in fully supervised settings that require high-quality pixel-level annotations, which are expensive and time-consuming to obtain. In this work, we present a weakly supervised learning algorithm to train semantic segmentation algorithms that only rely on query point annotations instead of full mask labels. Our proposed approach performs accurate semantic segmentation and improves efficiency by significantly reducing the cost and time required for manual annotation. Specifically, we generate superpixels and extend the query point labels into those superpixels that group similar meaningful semantics. Then, we train semantic segmentation models, supervised with images partially labeled with the superpixels pseudo-labels. We benchmark our weakly supervised training approach on an aerial image dataset and different semantic segmentation architectures, showing that we can reach competitive performance compared to fully supervised training while reducing the annotation effort.
When is a Foundation Model a Foundation Model
Sep 14, 2023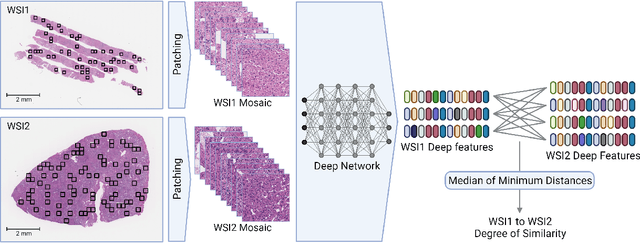
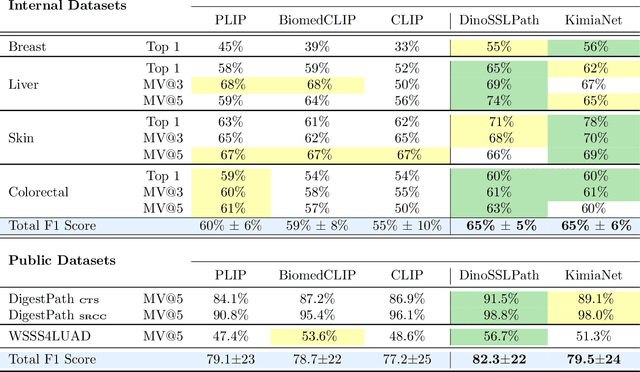
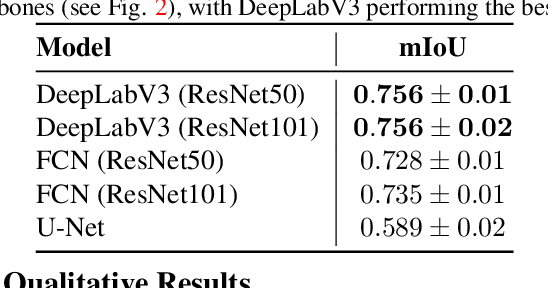
Recently, several studies have reported on the fine-tuning of foundation models for image-text modeling in the field of medicine, utilizing images from online data sources such as Twitter and PubMed. Foundation models are large, deep artificial neural networks capable of learning the context of a specific domain through training on exceptionally extensive datasets. Through validation, we have observed that the representations generated by such models exhibit inferior performance in retrieval tasks within digital pathology when compared to those generated by significantly smaller, conventional deep networks.
SwIPE: Efficient and Robust Medical Image Segmentation with Implicit Patch Embeddings
Jul 23, 2023Modern medical image segmentation methods primarily use discrete representations in the form of rasterized masks to learn features and generate predictions. Although effective, this paradigm is spatially inflexible, scales poorly to higher-resolution images, and lacks direct understanding of object shapes. To address these limitations, some recent works utilized implicit neural representations (INRs) to learn continuous representations for segmentation. However, these methods often directly adopted components designed for 3D shape reconstruction. More importantly, these formulations were also constrained to either point-based or global contexts, lacking contextual understanding or local fine-grained details, respectively--both critical for accurate segmentation. To remedy this, we propose a novel approach, SwIPE (Segmentation with Implicit Patch Embeddings), that leverages the advantages of INRs and predicts shapes at the patch level--rather than at the point level or image level--to enable both accurate local boundary delineation and global shape coherence. Extensive evaluations on two tasks (2D polyp segmentation and 3D abdominal organ segmentation) show that SwIPE significantly improves over recent implicit approaches and outperforms state-of-the-art discrete methods with over 10x fewer parameters. Our method also demonstrates superior data efficiency and improved robustness to data shifts across image resolutions and datasets. Code is available on Github.
LDP: Language-driven Dual-Pixel Image Defocus Deblurring Network
Jul 21, 2023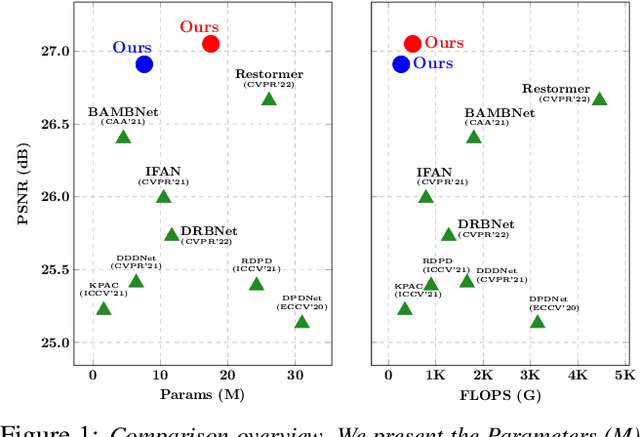
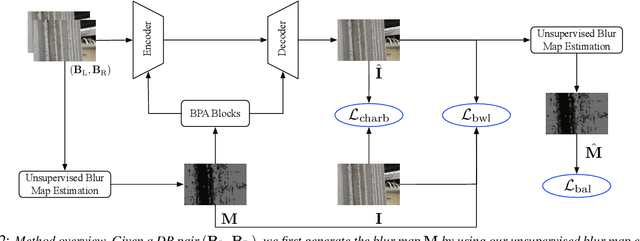
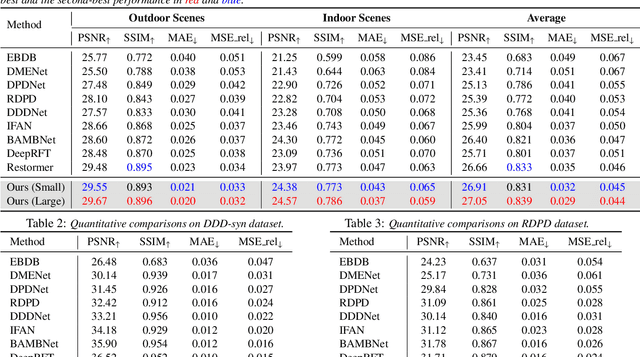
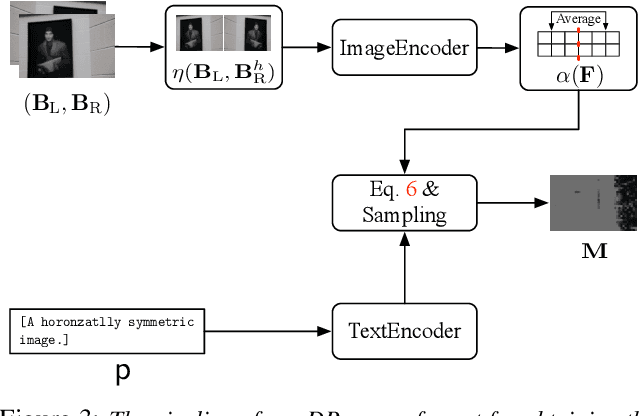
Recovering sharp images from dual-pixel (DP) pairs with disparity-dependent blur is a challenging task.~Existing blur map-based deblurring methods have demonstrated promising results. In this paper, we propose, to the best of our knowledge, the first framework to introduce the contrastive language-image pre-training framework (CLIP) to achieve accurate blur map estimation from DP pairs unsupervisedly. To this end, we first carefully design text prompts to enable CLIP to understand blur-related geometric prior knowledge from the DP pair. Then, we propose a format to input stereo DP pair to the CLIP without any fine-tuning, where the CLIP is pre-trained on monocular images. Given the estimated blur map, we introduce a blur-prior attention block, a blur-weighting loss and a blur-aware loss to recover the all-in-focus image. Our method achieves state-of-the-art performance in extensive experiments.
Segment Anything Model for Brain Tumor Segmentation
Sep 15, 2023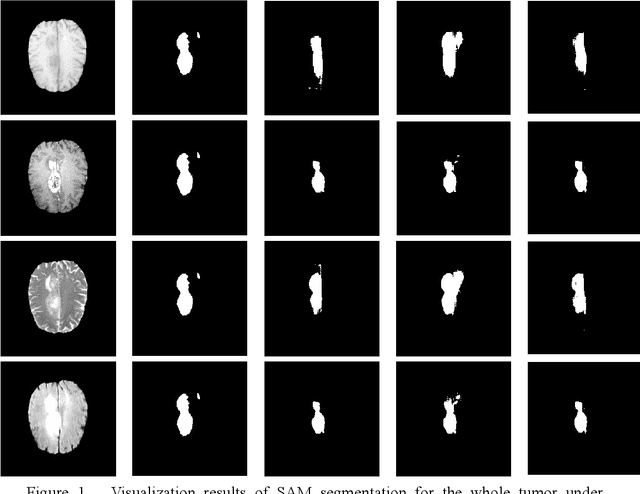
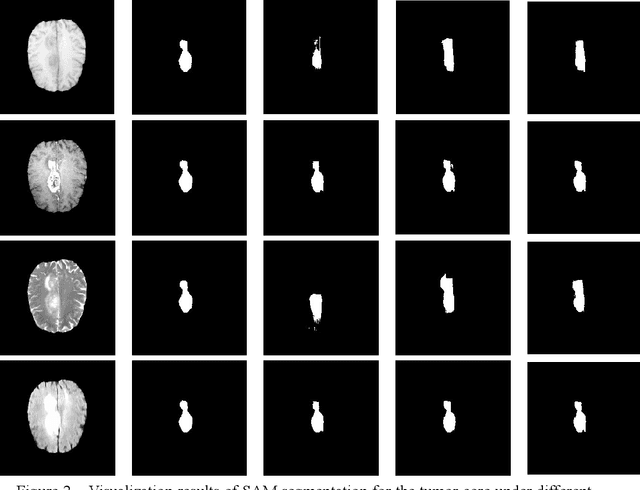

Glioma is a prevalent brain tumor that poses a significant health risk to individuals. Accurate segmentation of brain tumor is essential for clinical diagnosis and treatment. The Segment Anything Model(SAM), released by Meta AI, is a fundamental model in image segmentation and has excellent zero-sample generalization capabilities. Thus, it is interesting to apply SAM to the task of brain tumor segmentation. In this study, we evaluated the performance of SAM on brain tumor segmentation and found that without any model fine-tuning, there is still a gap between SAM and the current state-of-the-art(SOTA) model.
Enhancing Bloodstain Analysis Through AI-Based Segmentation: Leveraging Segment Anything Model for Crime Scene Investigation
Aug 27, 2023
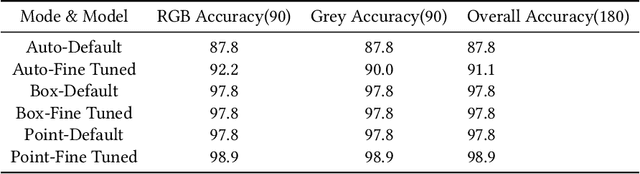


Bloodstain pattern analysis plays a crucial role in crime scene investigations by providing valuable information through the study of unique blood patterns. Conventional image analysis methods, like Thresholding and Contrast, impose stringent requirements on the image background and is labor-intensive in the context of droplet image segmentation. The Segment Anything Model (SAM), a recently proposed method for extensive image recognition, is yet to be adequately assessed for its accuracy and efficiency on bloodstain image segmentation. This paper explores the application of pre-trained SAM and fine-tuned SAM on bloodstain image segmentation with diverse image backgrounds. Experiment results indicate that both pre-trained and fine-tuned SAM perform the bloodstain image segmentation task with satisfactory accuracy and efficiency, while fine-tuned SAM achieves an overall 2.2\% accuracy improvement than pre-trained SAM and 4.70\% acceleration in terms of speed for image recognition. Analysis of factors that influence bloodstain recognition is carried out. This research demonstrates the potential application of SAM on bloodstain image segmentation, showcasing the effectiveness of Artificial Intelligence application in criminology research. We release all code and demos at \url{https://github.com/Zdong104/Bloodstain_Analysis_Ai_Tool}
A Sentence Speaks a Thousand Images: Domain Generalization through Distilling CLIP with Language Guidance
Sep 21, 2023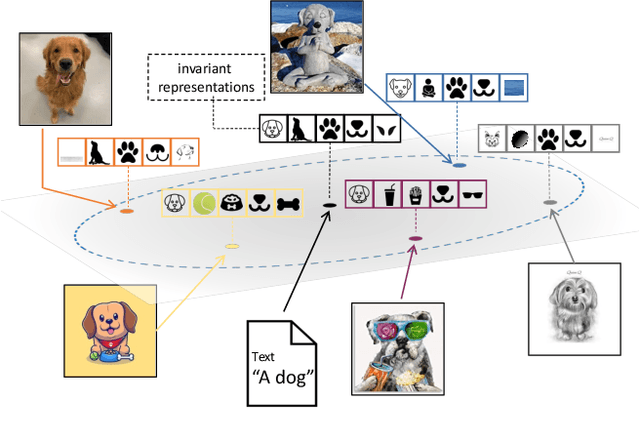
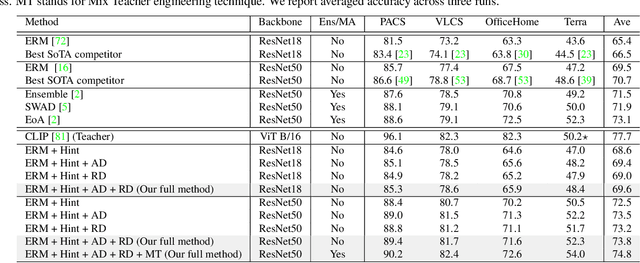

Domain generalization studies the problem of training a model with samples from several domains (or distributions) and then testing the model with samples from a new, unseen domain. In this paper, we propose a novel approach for domain generalization that leverages recent advances in large vision-language models, specifically a CLIP teacher model, to train a smaller model that generalizes to unseen domains. The key technical contribution is a new type of regularization that requires the student's learned image representations to be close to the teacher's learned text representations obtained from encoding the corresponding text descriptions of images. We introduce two designs of the loss function, absolute and relative distance, which provide specific guidance on how the training process of the student model should be regularized. We evaluate our proposed method, dubbed RISE (Regularized Invariance with Semantic Embeddings), on various benchmark datasets and show that it outperforms several state-of-the-art domain generalization methods. To our knowledge, our work is the first to leverage knowledge distillation using a large vision-language model for domain generalization. By incorporating text-based information, RISE improves the generalization capability of machine learning models.
Vulnerability of 3D Face Recognition Systems to Morphing Attacks
Sep 21, 2023
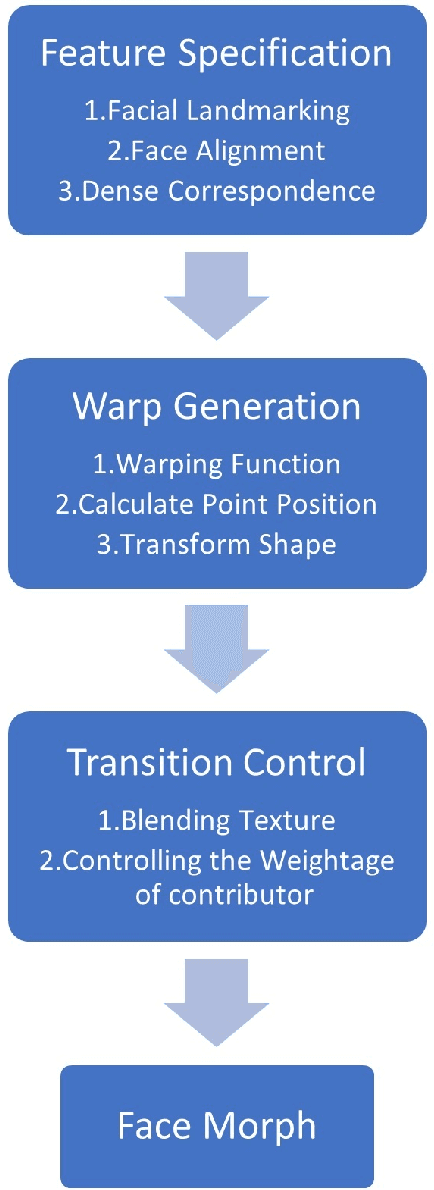


In recent years face recognition systems have been brought to the mainstream due to development in hardware and software. Consistent efforts are being made to make them better and more secure. This has also brought developments in 3D face recognition systems at a rapid pace. These 3DFR systems are expected to overcome certain vulnerabilities of 2DFR systems. One such problem that the domain of 2DFR systems face is face image morphing. A substantial amount of research is being done for generation of high quality face morphs along with detection of attacks from these morphs. Comparatively the understanding of vulnerability of 3DFR systems against 3D face morphs is less. But at the same time an expectation is set from 3DFR systems to be more robust against such attacks. This paper attempts to research and gain more information on this matter. The paper describes a couple of methods that can be used to generate 3D face morphs. The face morphs that are generated using this method are then compared to the contributing faces to obtain similarity scores. The highest MMPMR is obtained around 40% with RMMR of 41.76% when 3DFRS are attacked with look-a-like morphs.