 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Synthesis under Limited Data: A Survey and Taxonomy
Jul 31, 2023
Deep generative models, which target reproducing the given data distribution to produce novel samples, have made unprecedented advancements in recent years. Their technical breakthroughs have enabled unparalleled quality in the synthesis of visual content. However, one critical prerequisite for their tremendous success is the availability of a sufficient number of training samples, which requires massive computation resources. When trained on limited data, generative models tend to suffer from severe performance deterioration due to overfitting and memorization. Accordingly, researchers have devoted considerable attention to develop novel models that are capable of generating plausible and diverse images from limited training data recently. Despite numerous efforts to enhance training stability and synthesis quality in the limited data scenarios, there is a lack of a systematic survey that provides 1) a clear problem definition, critical challenges, and taxonomy of various tasks; 2) an in-depth analysis on the pros, cons, and remain limitations of existing literature; as well as 3) a thorough discussion on the potential applications and future directions in the field of image synthesis under limited data. In order to fill this gap and provide a informative introduction to researchers who are new to this topic, this survey offers a comprehensive review and a novel taxonomy on the development of image synthesis under limited data. In particular, it covers the problem definition, requirements, main solutions, popular benchmarks, and remain challenges in a comprehensive and all-around manner.
Identity-preserving Editing of Multiple Facial Attributes by Learning Global Edit Directions and Local Adjustments
Sep 25, 2023
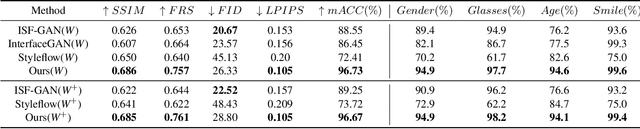
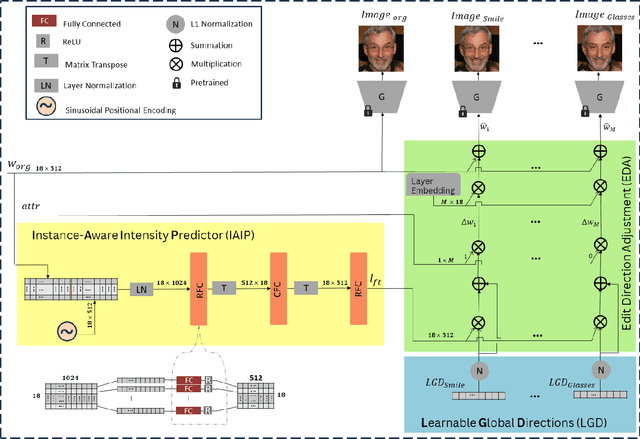
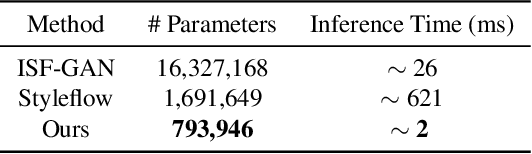
Semantic facial attribute editing using pre-trained Generative Adversarial Networks (GANs) has attracted a great deal of attention and effort from researchers in recent years. Due to the high quality of face images generated by StyleGANs, much work has focused on the StyleGANs' latent space and the proposed methods for facial image editing. Although these methods have achieved satisfying results for manipulating user-intended attributes, they have not fulfilled the goal of preserving the identity, which is an important challenge. We present ID-Style, a new architecture capable of addressing the problem of identity loss during attribute manipulation. The key components of ID-Style include Learnable Global Direction (LGD), which finds a shared and semi-sparse direction for each attribute, and an Instance-Aware Intensity Predictor (IAIP) network, which finetunes the global direction according to the input instance. Furthermore, we introduce two losses during training to enforce the LGD to find semi-sparse semantic directions, which along with the IAIP, preserve the identity of the input instance. Despite reducing the size of the network by roughly 95% as compared to similar state-of-the-art works, it outperforms baselines by 10% and 7% in Identity preserving metric (FRS) and average accuracy of manipulation (mACC), respectively.
MMA-Net: Multiple Morphology-Aware Network for Automated Cobb Angle Measurement
Sep 25, 2023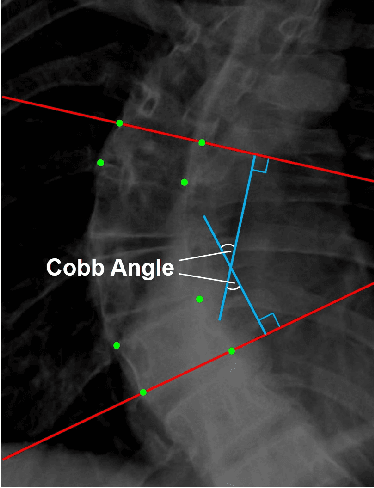
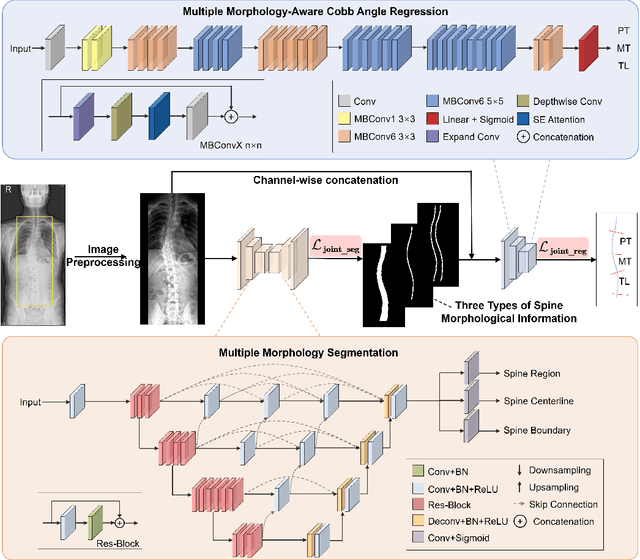
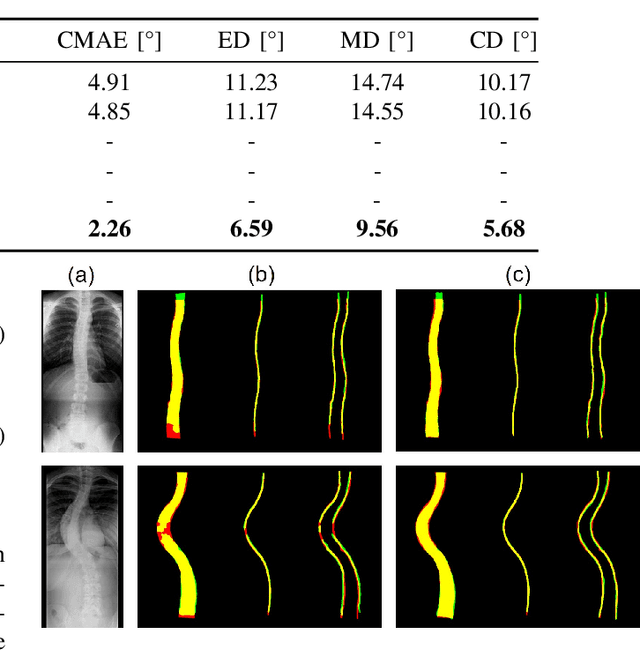
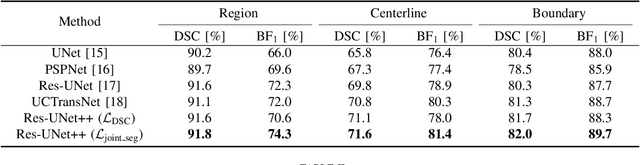
Scoliosis diagnosis and assessment depend largely on the measurement of the Cobb angle in spine X-ray images. With the emergence of deep learning techniques that employ landmark detection, tilt prediction, and spine segmentation, automated Cobb angle measurement has become increasingly popular. However, these methods encounter difficulties such as high noise sensitivity, intricate computational procedures, and exclusive reliance on a single type of morphological information. In this paper, we introduce the Multiple Morphology-Aware Network (MMA-Net), a novel framework that improves Cobb angle measurement accuracy by integrating multiple spine morphology as attention information. In the MMA-Net, we first feed spine X-ray images into the segmentation network to produce multiple morphological information (spine region, centerline, and boundary) and then concatenate the original X-ray image with the resulting segmentation maps as input for the regression module to perform precise Cobb angle measurement. Furthermore, we devise joint loss functions for our segmentation and regression network training, respectively. We evaluate our method on the AASCE challenge dataset and achieve superior performance with the SMAPE of 7.28% and the MAE of 3.18{\deg}, indicating a strong competitiveness compared to other outstanding methods. Consequently, we can offer clinicians automated, efficient, and reliable Cobb angle measurement.
ResShift: Efficient Diffusion Model for Image Super-resolution by Residual Shifting
Jul 25, 2023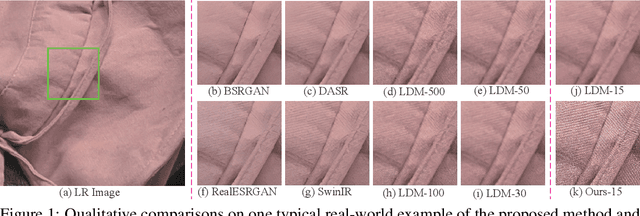
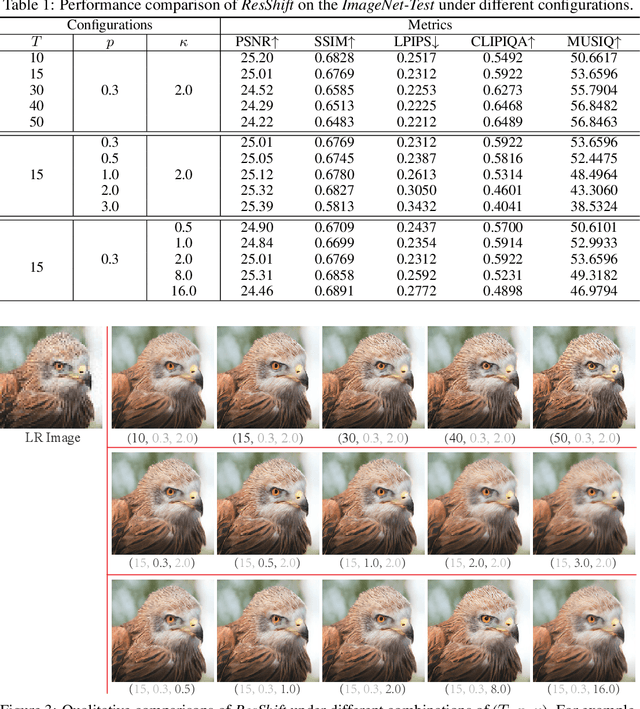

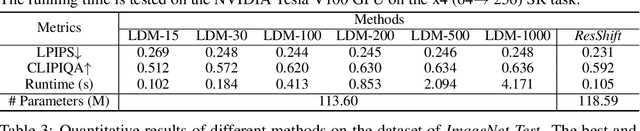
Diffusion-based image super-resolution (SR) methods are mainly limited by the low inference speed due to the requirements of hundreds or even thousands of sampling steps. Existing acceleration sampling techniques inevitably sacrifice performance to some extent, leading to over-blurry SR results. To address this issue, we propose a novel and efficient diffusion model for SR that significantly reduces the number of diffusion steps, thereby eliminating the need for post-acceleration during inference and its associated performance deterioration. Our method constructs a Markov chain that transfers between the high-resolution image and the low-resolution image by shifting the residual between them, substantially improving the transition efficiency. Additionally, an elaborate noise schedule is developed to flexibly control the shifting speed and the noise strength during the diffusion process. Extensive experiments demonstrate that the proposed method obtains superior or at least comparable performance to current state-of-the-art methods on both synthetic and real-world datasets, even only with 15 sampling steps. Our code and model are available at https://github.com/zsyOAOA/ResShift.
The Use of Multi-Scale Fiducial Markers To Aid Takeoff and Landing Navigation by Rotorcraft
Sep 15, 2023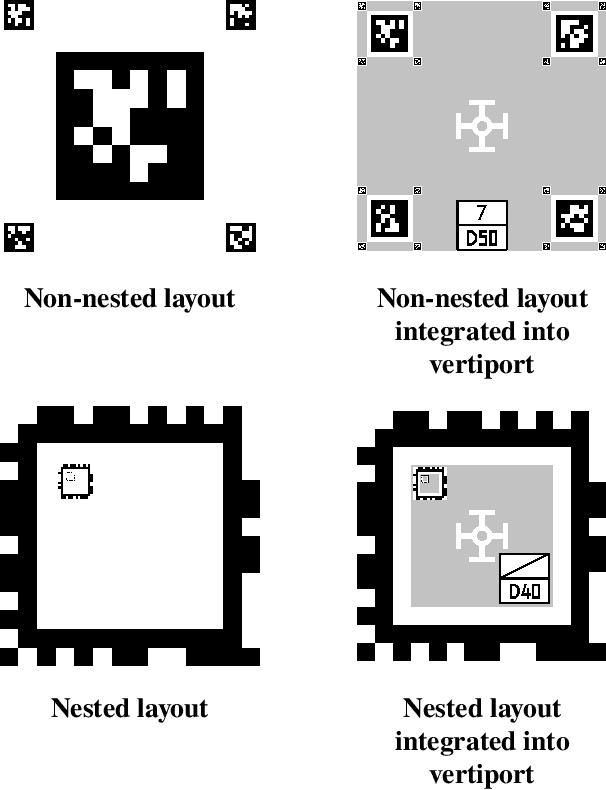
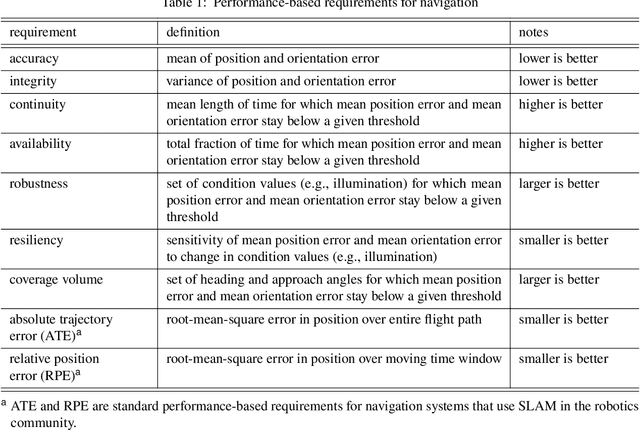
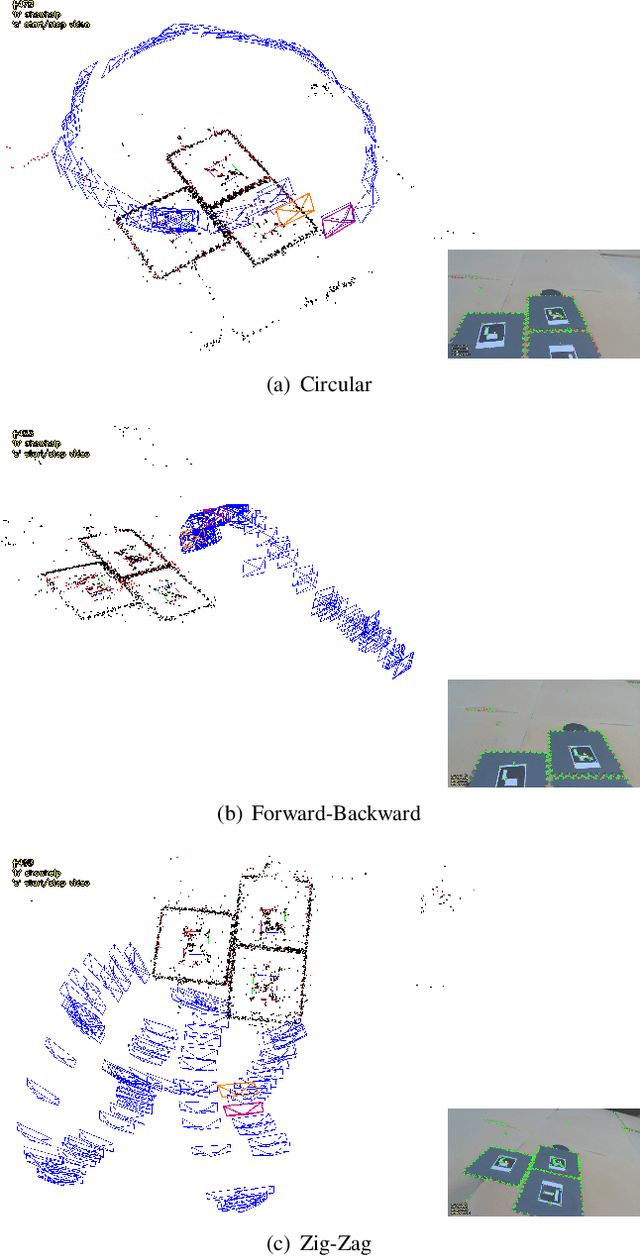
This paper quantifies the impact of adverse environmental conditions on the detection of fiducial markers (i.e., artificial landmarks) by color cameras mounted on rotorcraft. We restrict our attention to square markers with a black-and-white pattern of grid cells that can be nested to allow detection at multiple scales. These markers have the potential to enhance the reliability of precision takeoff and landing at vertiports by flying vehicles in urban settings. Prior work has shown, in particular, that these markers can be detected with high precision (i.e., few false positives) and high recall (i.e., few false negatives). However, most of this prior work has been based on image sequences collected indoors with hand-held cameras. Our work is based on image sequences collected outdoors with cameras mounted on a quadrotor during semi-autonomous takeoff and landing operations under adverse environmental conditions that include variations in temperature, illumination, wind speed, humidity, visibility, and precipitation. In addition to precision and recall, performance measures include continuity, availability, robustness, resiliency, and coverage volume. We release both our dataset and the code we used for analysis to the public as open source.
Overcoming Distribution Mismatch in Quantizing Image Super-Resolution Networks
Jul 25, 2023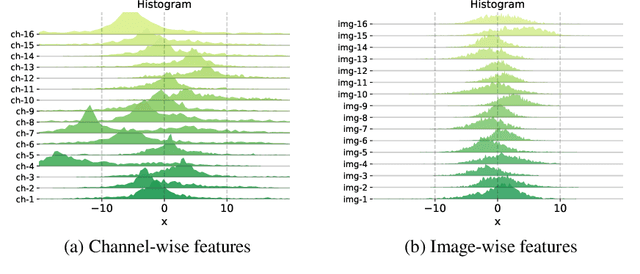
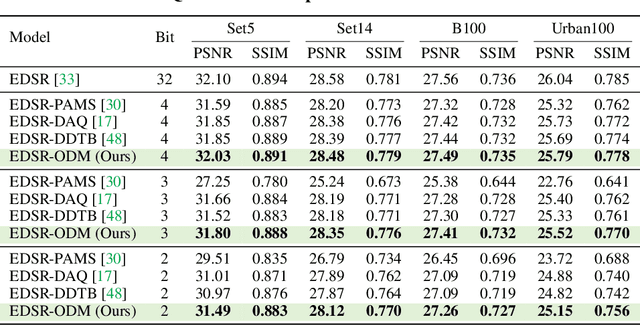
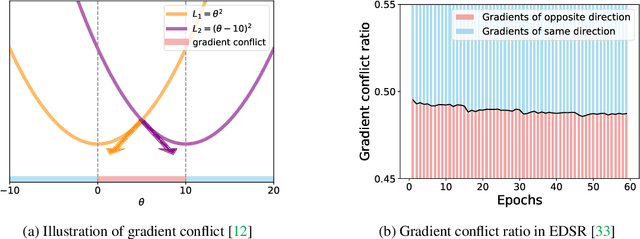
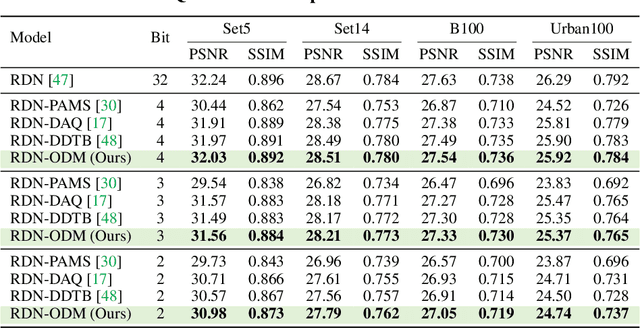
Quantization is a promising approach to reduce the high computational complexity of image super-resolution (SR) networks. However, compared to high-level tasks like image classification, low-bit quantization leads to severe accuracy loss in SR networks. This is because feature distributions of SR networks are significantly divergent for each channel or input image, and is thus difficult to determine a quantization range. Existing SR quantization works approach this distribution mismatch problem by dynamically adapting quantization ranges to the variant distributions during test time. However, such dynamic adaptation incurs additional computational costs that limit the benefits of quantization. Instead, we propose a new quantization-aware training framework that effectively Overcomes the Distribution Mismatch problem in SR networks without the need for dynamic adaptation. Intuitively, the mismatch can be reduced by directly regularizing the variance in features during training. However, we observe that variance regularization can collide with the reconstruction loss during training and adversely impact SR accuracy. Thus, we avoid the conflict between two losses by regularizing the variance only when the gradients of variance regularization are cooperative with that of reconstruction. Additionally, to further reduce the distribution mismatch, we introduce distribution offsets to layers with a significant mismatch, which either scales or shifts channel-wise features. Our proposed algorithm, called ODM, effectively reduces the mismatch in distributions with minimal computational overhead. Experimental results show that ODM effectively outperforms existing SR quantization approaches with similar or fewer computations, demonstrating the importance of reducing the distribution mismatch problem. Our code is available at https://github.com/Cheeun/ODM.
Tracking Snake-like Robots in the Wild Using Only a Single Camera
Sep 27, 2023

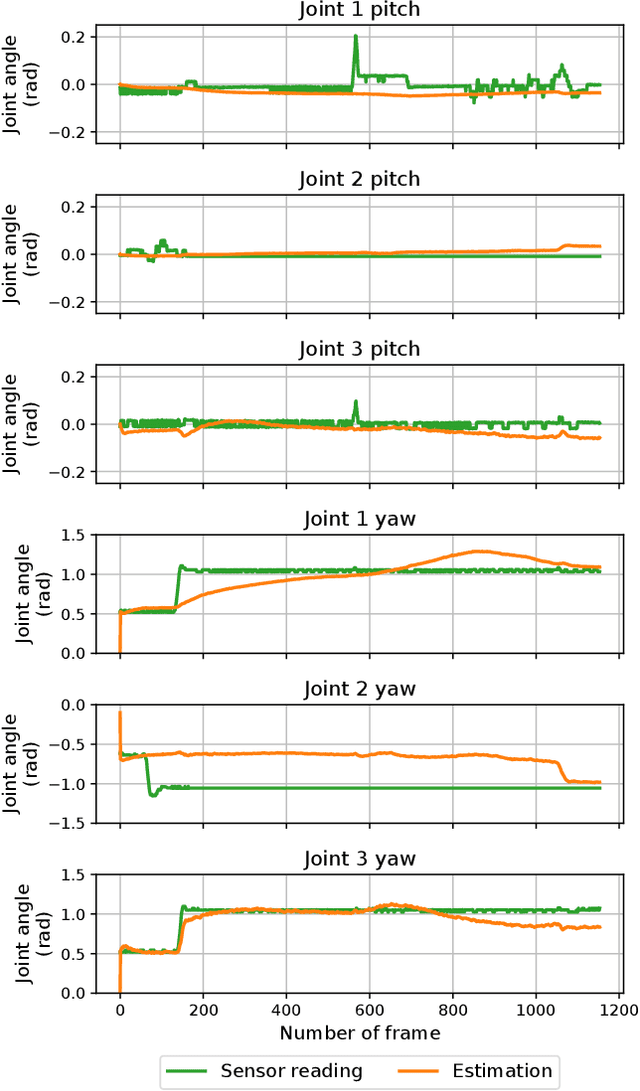

Robot navigation within complex environments requires precise state estimation and localization to ensure robust and safe operations. For ambulating mobile robots like robot snakes, traditional methods for sensing require multiple embedded sensors or markers, leading to increased complexity, cost, and increased points of failure. Alternatively, deploying an external camera in the environment is very easy to do, and marker-less state estimation of the robot from this camera's images is an ideal solution: both simple and cost-effective. However, the challenge in this process is in tracking the robot under larger environments where the cameras may be moved around without extrinsic calibration, or maybe when in motion (e.g., a drone following the robot). The scenario itself presents a complex challenge: single-image reconstruction of robot poses under noisy observations. In this paper, we address the problem of tracking ambulatory mobile robots from a single camera. The method combines differentiable rendering with the Kalman filter. This synergy allows for simultaneous estimation of the robot's joint angle and pose while also providing state uncertainty which could be used later on for robust control. We demonstrate the efficacy of our approach on a snake-like robot in both stationary and non-stationary (moving) cameras, validating its performance in both structured and unstructured scenarios. The results achieved show an average error of 0.05 m in localizing the robot's base position and 6 degrees in joint state estimation. We believe this novel technique opens up possibilities for enhanced robot mobility and navigation in future exploratory and search-and-rescue missions.
Missing-modality Enabled Multi-modal Fusion Architecture for Medical Data
Sep 27, 2023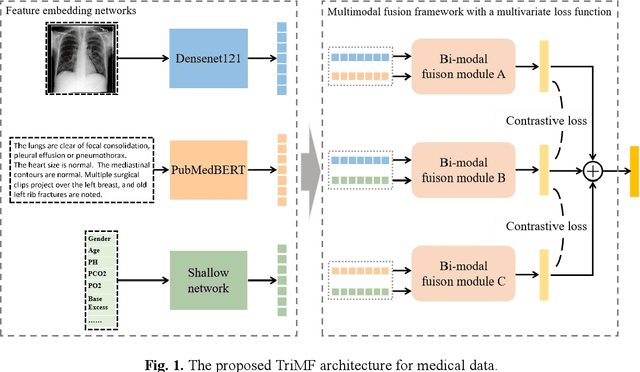
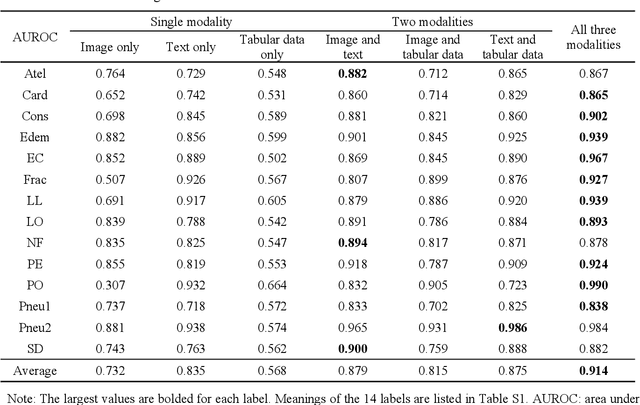
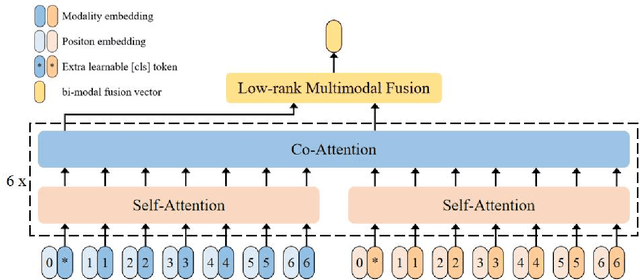
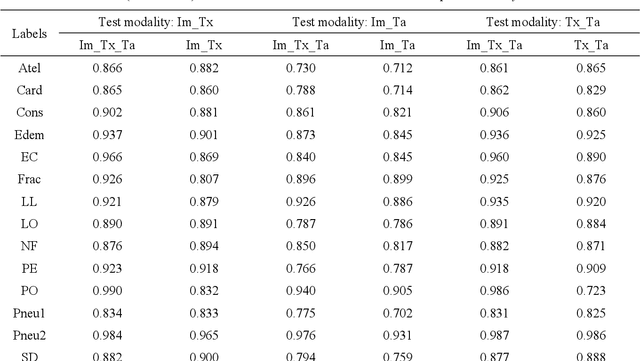
Fusing multi-modal data can improve the performance of deep learning models. However, missing modalities are common for medical data due to patients' specificity, which is detrimental to the performance of multi-modal models in applications. Therefore, it is critical to adapt the models to missing modalities. This study aimed to develop an efficient multi-modal fusion architecture for medical data that was robust to missing modalities and further improved the performance on disease diagnosis.X-ray chest radiographs for the image modality, radiology reports for the text modality, and structured value data for the tabular data modality were fused in this study. Each modality pair was fused with a Transformer-based bi-modal fusion module, and the three bi-modal fusion modules were then combined into a tri-modal fusion framework. Additionally, multivariate loss functions were introduced into the training process to improve model's robustness to missing modalities in the inference process. Finally, we designed comparison and ablation experiments for validating the effectiveness of the fusion, the robustness to missing modalities and the enhancements from each key component. Experiments were conducted on MIMIC-IV, MIMIC-CXR with the 14-label disease diagnosis task. Areas under the receiver operating characteristic curve (AUROC), the area under the precision-recall curve (AUPRC) were used to evaluate models' performance. The experimental results demonstrated that our proposed multi-modal fusion architecture effectively fused three modalities and showed strong robustness to missing modalities. This method is hopeful to be scaled to more modalities to enhance the clinical practicality of the model.
CAIT: Triple-Win Compression towards High Accuracy, Fast Inference, and Favorable Transferability For ViTs
Sep 27, 2023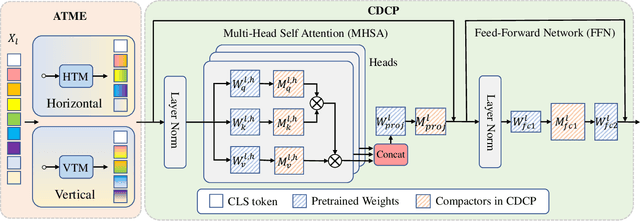

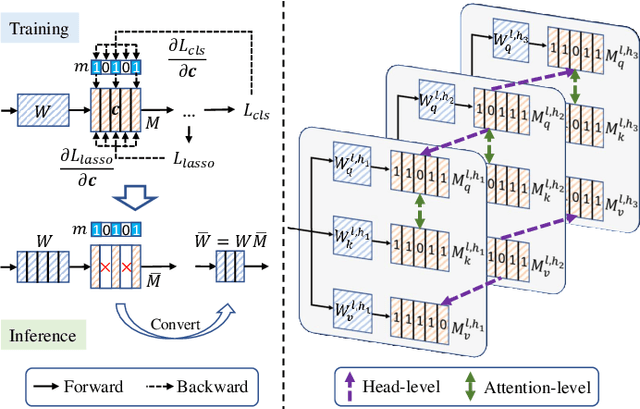
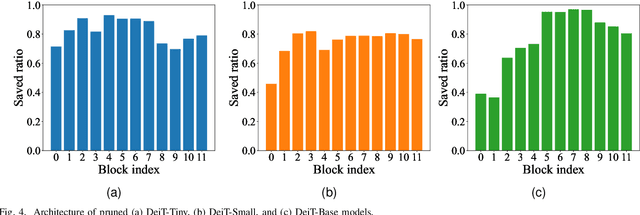
Vision Transformers (ViTs) have emerged as state-of-the-art models for various vision tasks recently. However, their heavy computation costs remain daunting for resource-limited devices. Consequently, researchers have dedicated themselves to compressing redundant information in ViTs for acceleration. However, they generally sparsely drop redundant image tokens by token pruning or brutally remove channels by channel pruning, leading to a sub-optimal balance between model performance and inference speed. They are also disadvantageous in transferring compressed models to downstream vision tasks that require the spatial structure of images, such as semantic segmentation. To tackle these issues, we propose a joint compression method for ViTs that offers both high accuracy and fast inference speed, while also maintaining favorable transferability to downstream tasks (CAIT). Specifically, we introduce an asymmetric token merging (ATME) strategy to effectively integrate neighboring tokens. It can successfully compress redundant token information while preserving the spatial structure of images. We further employ a consistent dynamic channel pruning (CDCP) strategy to dynamically prune unimportant channels in ViTs. Thanks to CDCP, insignificant channels in multi-head self-attention modules of ViTs can be pruned uniformly, greatly enhancing the model compression. Extensive experiments on benchmark datasets demonstrate that our proposed method can achieve state-of-the-art performance across various ViTs. For example, our pruned DeiT-Tiny and DeiT-Small achieve speedups of 1.7$\times$ and 1.9$\times$, respectively, without accuracy drops on ImageNet. On the ADE20k segmentation dataset, our method can enjoy up to 1.31$\times$ speedups with comparable mIoU. Our code will be publicly available.
Learning Unbiased Image Segmentation: A Case Study with Plain Knee Radiographs
Aug 08, 2023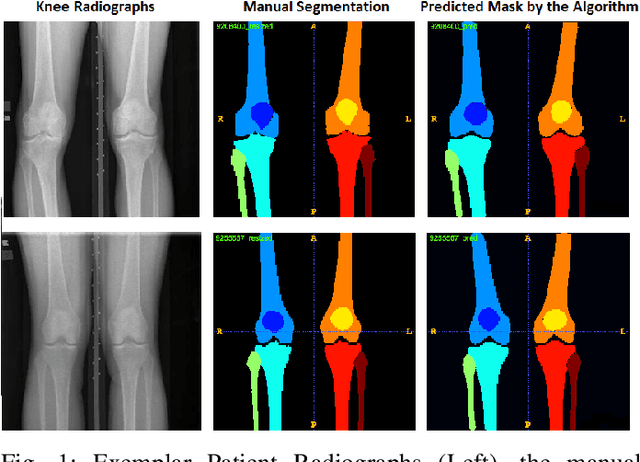
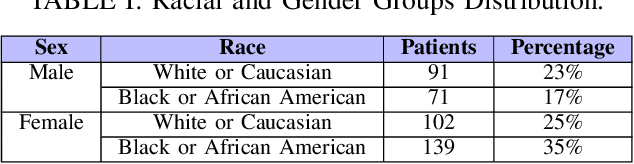
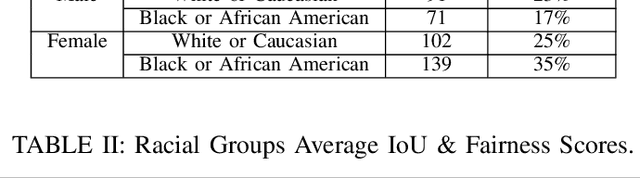
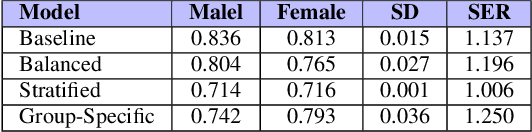
Automatic segmentation of knee bony anatomy is essential in orthopedics, and it has been around for several years in both pre-operative and post-operative settings. While deep learning algorithms have demonstrated exceptional performance in medical image analysis, the assessment of fairness and potential biases within these models remains limited. This study aims to revisit deep learning-powered knee-bony anatomy segmentation using plain radiographs to uncover visible gender and racial biases. The current contribution offers the potential to advance our understanding of biases, and it provides practical insights for researchers and practitioners in medical imaging. The proposed mitigation strategies mitigate gender and racial biases, ensuring fair and unbiased segmentation results. Furthermore, this work promotes equal access to accurate diagnoses and treatment outcomes for diverse patient populations, fostering equitable and inclusive healthcare provision.