 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraud Detection
Fraud detection is a vital topic that applies to many industries including the financial sectors, banking, government agencies, insurance, and law enforcement, and more. Fraud endeavors have detected a radical rise in recent years, making this topic more critical than ever. Despite struggles on the part of the troubled organizations, hundreds of millions of dollars are lost to fraud each year. Because nearly a few samples confirm fraud in a vast community, locating these can be complex. Data mining and statistics help to predict and immediately distinguish fraud and take immediate action to minimize costs.
Papers and Code
GARG-AML against Smurfing: A Scalable and Interpretable Graph-Based Framework for Anti-Money Laundering
Jun 04, 2025Money laundering poses a significant challenge as it is estimated to account for 2%-5% of the global GDP. This has compelled regulators to impose stringent controls on financial institutions. One prominent laundering method for evading these controls, called smurfing, involves breaking up large transactions into smaller amounts. Given the complexity of smurfing schemes, which involve multiple transactions distributed among diverse parties, network analytics has become an important anti-money laundering tool. However, recent advances have focused predominantly on black-box network embedding methods, which has hindered their adoption in businesses. In this paper, we introduce GARG-AML, a novel graph-based method that quantifies smurfing risk through a single interpretable metric derived from the structure of the second-order transaction network of each individual node in the network. Unlike traditional methods, GARG-AML strikes an effective balance among computational efficiency, detection power and transparency, which enables its integration into existing AML workflows. To enhance its capabilities, we combine the GARG-AML score calculation with different tree-based methods and also incorporate the scores of the node's neighbours. An experimental evaluation on large-scale synthetic and open-source networks demonstrate that the GARG-AML outperforms the current state-of-the-art smurfing detection methods. By leveraging only the adjacency matrix of the second-order neighbourhood and basic network features, this work highlights the potential of fundamental network properties towards advancing fraud detection.
Toward Practical Quantum Machine Learning: A Novel Hybrid Quantum LSTM for Fraud Detection
Apr 30, 2025We present a novel hybrid quantum-classical neural network architecture for fraud detection that integrates a classical Long Short-Term Memory (LSTM) network with a variational quantum circuit. By leveraging quantum phenomena such as superposition and entanglement, our model enhances the feature representation of sequential transaction data, capturing complex non-linear patterns that are challenging for purely classical models. A comprehensive data preprocessing pipeline is employed to clean, encode, balance, and normalize a credit card fraud dataset, ensuring a fair comparison with baseline models. Notably, our hybrid approach achieves per-epoch training times in the range of 45-65 seconds, which is significantly faster than similar architectures reported in the literature, where training typically requires several minutes per epoch. Both classical and quantum gradients are jointly optimized via a unified backpropagation procedure employing the parameter-shift rule for the quantum parameters. Experimental evaluations demonstrate competitive improvements in accuracy, precision, recall, and F1 score relative to a conventional LSTM baseline. These results underscore the promise of hybrid quantum-classical techniques in advancing the efficiency and performance of fraud detection systems. Keywords: Hybrid Quantum-Classical Neural Networks, Quantum Computing, Fraud Detection, Hybrid Quantum LSTM, Variational Quantum Circuit, Parameter-Shift Rule, Financial Risk Analysis
ScamAgents: How AI Agents Can Simulate Human-Level Scam Calls
Aug 08, 2025Large Language Models (LLMs) have demonstrated impressive fluency and reasoning capabilities, but their potential for misuse has raised growing concern. In this paper, we present ScamAgent, an autonomous multi-turn agent built on top of LLMs, capable of generating highly realistic scam call scripts that simulate real-world fraud scenarios. Unlike prior work focused on single-shot prompt misuse, ScamAgent maintains dialogue memory, adapts dynamically to simulated user responses, and employs deceptive persuasion strategies across conversational turns. We show that current LLM safety guardrails, including refusal mechanisms and content filters, are ineffective against such agent-based threats. Even models with strong prompt-level safeguards can be bypassed when prompts are decomposed, disguised, or delivered incrementally within an agent framework. We further demonstrate the transformation of scam scripts into lifelike voice calls using modern text-to-speech systems, completing a fully automated scam pipeline. Our findings highlight an urgent need for multi-turn safety auditing, agent-level control frameworks, and new methods to detect and disrupt conversational deception powered by generative AI.
Rethinking Contrastive Learning in Graph Anomaly Detection: A Clean-View Perspective
May 23, 2025Graph anomaly detection aims to identify unusual patterns in graph-based data, with wide applications in fields such as web security and financial fraud detection. Existing methods typically rely on contrastive learning, assuming that a lower similarity between a node and its local subgraph indicates abnormality. However, these approaches overlook a crucial limitation: the presence of interfering edges invalidates this assumption, since it introduces disruptive noise that compromises the contrastive learning process. Consequently, this limitation impairs the ability to effectively learn meaningful representations of normal patterns, leading to suboptimal detection performance. To address this issue, we propose a Clean-View Enhanced Graph Anomaly Detection framework (CVGAD), which includes a multi-scale anomaly awareness module to identify key sources of interference in the contrastive learning process. Moreover, to mitigate bias from the one-step edge removal process, we introduce a novel progressive purification module. This module incrementally refines the graph by iteratively identifying and removing interfering edges, thereby enhancing model performance. Extensive experiments on five benchmark datasets validate the effectiveness of our approach.
Dual-channel Heterophilic Message Passing for Graph Fraud Detection
Apr 19, 2025Fraudulent activities have significantly increased across various domains, such as e-commerce, online review platforms, and social networks, making fraud detection a critical task. Spatial Graph Neural Networks (GNNs) have been successfully applied to fraud detection tasks due to their strong inductive learning capabilities. However, existing spatial GNN-based methods often enhance the graph structure by excluding heterophilic neighbors during message passing to align with the homophilic bias of GNNs. Unfortunately, this approach can disrupt the original graph topology and increase uncertainty in predictions. To address these limitations, this paper proposes a novel framework, Dual-channel Heterophilic Message Passing (DHMP), for fraud detection. DHMP leverages a heterophily separation module to divide the graph into homophilic and heterophilic subgraphs, mitigating the low-pass inductive bias of traditional GNNs. It then applies shared weights to capture signals at different frequencies independently and incorporates a customized sampling strategy for training. This allows nodes to adaptively balance the contributions of various signals based on their labels. Extensive experiments on three real-world datasets demonstrate that DHMP outperforms existing methods, highlighting the importance of separating signals with different frequencies for improved fraud detection. The code is available at https://github.com/shaieesss/DHMP.
AD-AGENT: A Multi-agent Framework for End-to-end Anomaly Detection
May 19, 2025



Anomaly detection (AD) is essential in areas such as fraud detection, network monitoring, and scientific research. However, the diversity of data modalities and the increasing number of specialized AD libraries pose challenges for non-expert users who lack in-depth library-specific knowledge and advanced programming skills. To tackle this, we present AD-AGENT, an LLM-driven multi-agent framework that turns natural-language instructions into fully executable AD pipelines. AD-AGENT coordinates specialized agents for intent parsing, data preparation, library and model selection, documentation mining, and iterative code generation and debugging. Using a shared short-term workspace and a long-term cache, the agents integrate popular AD libraries like PyOD, PyGOD, and TSLib into a unified workflow. Experiments demonstrate that AD-AGENT produces reliable scripts and recommends competitive models across libraries. The system is open-sourced to support further research and practical applications in AD.
Joint Detection of Fraud and Concept Drift inOnline Conversations with LLM-Assisted Judgment
May 07, 2025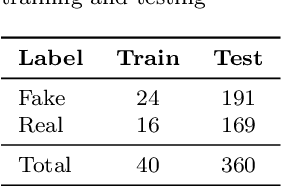
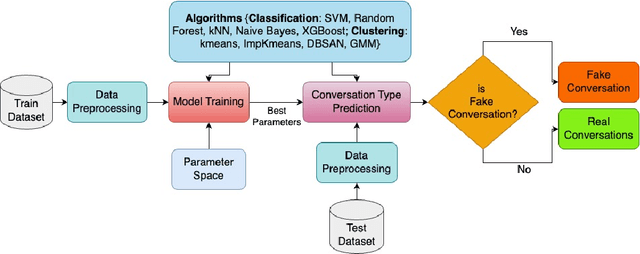
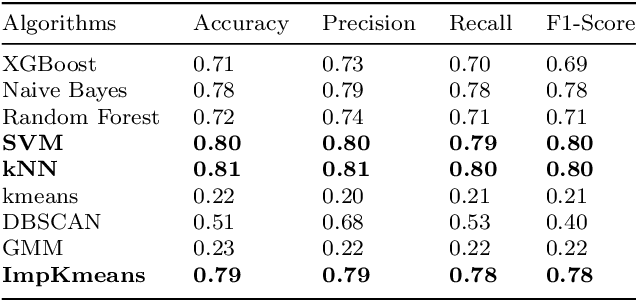
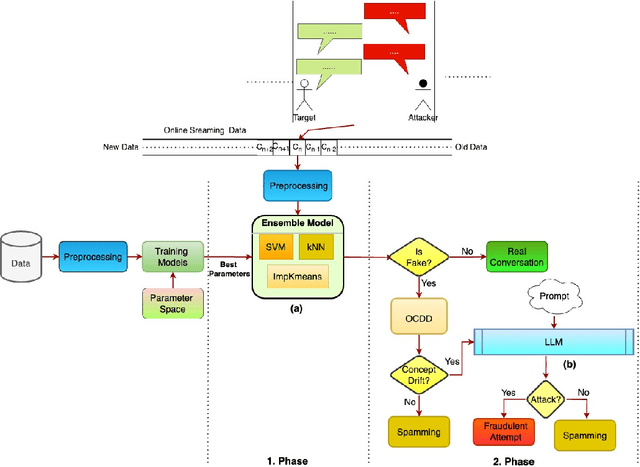
Detecting fake interactions in digital communication platforms remains a challenging and insufficiently addressed problem. These interactions may appear as harmless spam or escalate into sophisticated scam attempts, making it difficult to flag malicious intent early. Traditional detection methods often rely on static anomaly detection techniques that fail to adapt to dynamic conversational shifts. One key limitation is the misinterpretation of benign topic transitions referred to as concept drift as fraudulent behavior, leading to either false alarms or missed threats. We propose a two stage detection framework that first identifies suspicious conversations using a tailored ensemble classification model. To improve the reliability of detection, we incorporate a concept drift analysis step using a One Class Drift Detector (OCDD) to isolate conversational shifts within flagged dialogues. When drift is detected, a large language model (LLM) assesses whether the shift indicates fraudulent manipulation or a legitimate topic change. In cases where no drift is found, the behavior is inferred to be spam like. We validate our framework using a dataset of social engineering chat scenarios and demonstrate its practical advantages in improving both accuracy and interpretability for real time fraud detection. To contextualize the trade offs, we compare our modular approach against a Dual LLM baseline that performs detection and judgment using different language models.
QFDNN: A Resource-Efficient Variational Quantum Feature Deep Neural Networks for Fraud Detection and Loan Prediction
Apr 28, 2025



Social financial technology focuses on trust, sustainability, and social responsibility, which require advanced technologies to address complex financial tasks in the digital era. With the rapid growth in online transactions, automating credit card fraud detection and loan eligibility prediction has become increasingly challenging. Classical machine learning (ML) models have been used to solve these challenges; however, these approaches often encounter scalability, overfitting, and high computational costs due to complexity and high-dimensional financial data. Quantum computing (QC) and quantum machine learning (QML) provide a promising solution to efficiently processing high-dimensional datasets and enabling real-time identification of subtle fraud patterns. However, existing quantum algorithms lack robustness in noisy environments and fail to optimize performance with reduced feature sets. To address these limitations, we propose a quantum feature deep neural network (QFDNN), a novel, resource efficient, and noise-resilient quantum model that optimizes feature representation while requiring fewer qubits and simpler variational circuits. The model is evaluated using credit card fraud detection and loan eligibility prediction datasets, achieving competitive accuracies of 82.2% and 74.4%, respectively, with reduced computational overhead. Furthermore, we test QFDNN against six noise models, demonstrating its robustness across various error conditions. Our findings highlight QFDNN potential to enhance trust and security in social financial technology by accurately detecting fraudulent transactions while supporting sustainability through its resource-efficient design and minimal computational overhead.
Cyber Security Data Science: Machine Learning Methods and their Performance on Imbalanced Datasets
May 07, 2025Cybersecurity has become essential worldwide and at all levels, concerning individuals, institutions, and governments. A basic principle in cybersecurity is to be always alert. Therefore, automation is imperative in processes where the volume of daily operations is large. Several cybersecurity applications can be addressed as binary classification problems, including anomaly detection, fraud detection, intrusion detection, spam detection, or malware detection. We present three experiments. In the first experiment, we evaluate single classifiers including Random Forests, Light Gradient Boosting Machine, eXtreme Gradient Boosting, Logistic Regression, Decision Tree, and Gradient Boosting Decision Tree. In the second experiment, we test different sampling techniques including over-sampling, under-sampling, Synthetic Minority Over-sampling Technique, and Self-Paced Ensembling. In the last experiment, we evaluate Self-Paced Ensembling and its number of base classifiers. We found that imbalance learning techniques had positive and negative effects, as reported in related studies. Thus, these techniques should be applied with caution. Besides, we found different best performers for each dataset. Therefore, we recommend testing single classifiers and imbalance learning techniques for each new dataset and application involving imbalanced datasets as is the case in several cyber security applications.
* 13 pages, 5 figures. Digital Management and Artificial Intelligence. Proceedings of the Fourth International Scientific-Practical Conference (ISPC 2024), Hybrid, October 10-11, 2024. https://link.springer.com/chapter/10.1007/978-3-031-88052-0_45
ROSFD: Robust Online Streaming Fraud Detection with Resilience to Concept Drift in Data Streams
Apr 14, 2025Continuous generation of streaming data from diverse sources, such as online transactions and digital interactions, necessitates timely fraud detection. Traditional batch processing methods often struggle to capture the rapidly evolving patterns of fraudulent activities. This paper highlights the critical importance of processing streaming data for effective fraud detection. To address the inherent challenges of latency, scalability, and concept drift in streaming environments, we propose a robust online streaming fraud detection (ROSFD) framework. Our proposed framework comprises two key stages: (i) Stage One: Offline Model Initialization. In this initial stage, a model is built in offline settings using incremental learning principles to overcome the "cold-start" problem. (ii) Stage Two: Real-time Model Adaptation. In this dynamic stage, drift detection algorithms (viz.,, DDM, EDDM, and ADWIN) are employed to identify concept drift in the incoming data stream and incrementally train the model accordingly. This "train-only-when-required" strategy drastically reduces the number of retrains needed without significantly impacting the area under the receiver operating characteristic curve (AUC). Overall, ROSFD utilizing ADWIN as the drift detection method demonstrated the best performance among the employed methods. In terms of model efficacy, Adaptive Random Forest consistently outperformed other models, achieving the highest AUC in four out of five datasets.