 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Sentiment Analysis
Papers and Code
MMAFFBen: A Multilingual and Multimodal Affective Analysis Benchmark for Evaluating LLMs and VLMs
May 30, 2025



Large language models and vision-language models (which we jointly call LMs) have transformed NLP and CV, demonstrating remarkable potential across various fields. However, their capabilities in affective analysis (i.e. sentiment analysis and emotion detection) remain underexplored. This gap is largely due to the absence of comprehensive evaluation benchmarks, and the inherent complexity of affective analysis tasks. In this paper, we introduce MMAFFBen, the first extensive open-source benchmark for multilingual multimodal affective analysis. MMAFFBen encompasses text, image, and video modalities across 35 languages, covering four key affective analysis tasks: sentiment polarity, sentiment intensity, emotion classification, and emotion intensity. Moreover, we construct the MMAFFIn dataset for fine-tuning LMs on affective analysis tasks, and further develop MMAFFLM-3b and MMAFFLM-7b based on it. We evaluate various representative LMs, including GPT-4o-mini, providing a systematic comparison of their affective understanding capabilities. This project is available at https://github.com/lzw108/MMAFFBen.
Enhancing Sentiment Analysis through Multimodal Fusion: A BERT-DINOv2 Approach
Mar 11, 2025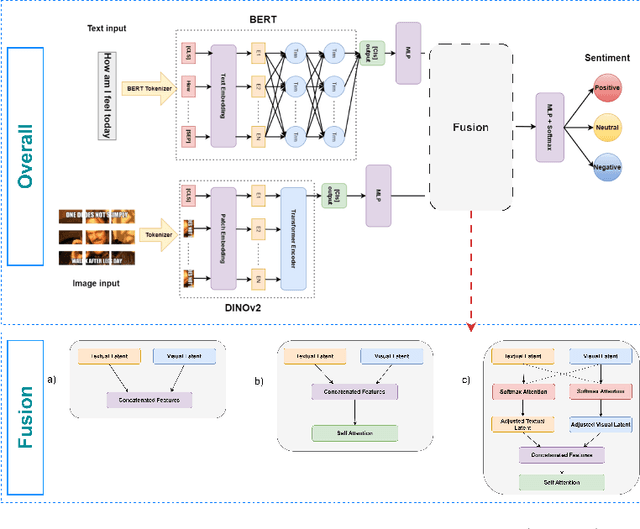
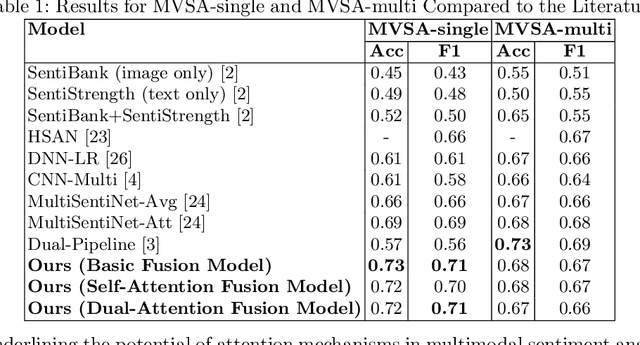
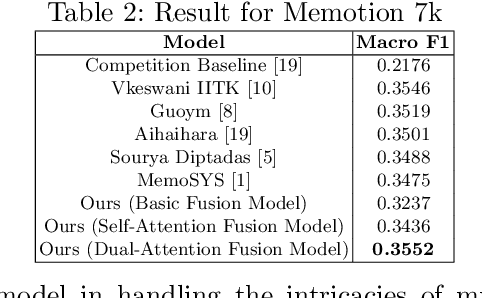
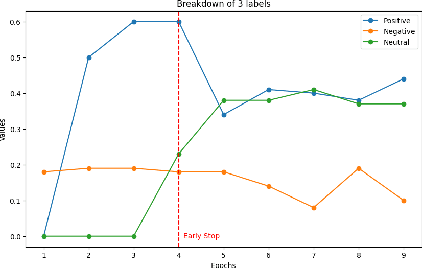
Multimodal sentiment analysis enhances conventional sentiment analysis, which traditionally relies solely on text, by incorporating information from different modalities such as images, text, and audio. This paper proposes a novel multimodal sentiment analysis architecture that integrates text and image data to provide a more comprehensive understanding of sentiments. For text feature extraction, we utilize BERT, a natural language processing model. For image feature extraction, we employ DINOv2, a vision-transformer-based model. The textual and visual latent features are integrated using proposed fusion techniques, namely the Basic Fusion Model, Self Attention Fusion Model, and Dual Attention Fusion Model. Experiments on three datasets, Memotion 7k dataset, MVSA single dataset, and MVSA multi dataset, demonstrate the viability and practicality of the proposed multimodal architecture.
Commander-GPT: Dividing and Routing for Multimodal Sarcasm Detection
Jun 24, 2025Multimodal sarcasm understanding is a high-order cognitive task. Although large language models (LLMs) have shown impressive performance on many downstream NLP tasks, growing evidence suggests that they struggle with sarcasm understanding. In this paper, we propose Commander-GPT, a modular decision routing framework inspired by military command theory. Rather than relying on a single LLM's capability, Commander-GPT orchestrates a team of specialized LLM agents where each agent will be selectively assigned to a focused sub-task such as context modeling, sentiment analysis, etc. Their outputs are then routed back to the commander, which integrates the information and performs the final sarcasm judgment. To coordinate these agents, we introduce three types of centralized commanders: (1) a trained lightweight encoder-based commander (e.g., multi-modal BERT); (2) four small autoregressive language models, serving as moderately capable commanders (e.g., DeepSeek-VL); (3) two large LLM-based commander (Gemini Pro and GPT-4o) that performs task routing, output aggregation, and sarcasm decision-making in a zero-shot fashion. We evaluate Commander-GPT on the MMSD and MMSD 2.0 benchmarks, comparing five prompting strategies. Experimental results show that our framework achieves 4.4% and 11.7% improvement in F1 score over state-of-the-art (SoTA) baselines on average, demonstrating its effectiveness.
Cultural Bias Matters: A Cross-Cultural Benchmark Dataset and Sentiment-Enriched Model for Understanding Multimodal Metaphors
Jun 08, 2025



Metaphors are pervasive in communication, making them crucial for natural language processing (NLP). Previous research on automatic metaphor processing predominantly relies on training data consisting of English samples, which often reflect Western European or North American biases. This cultural skew can lead to an overestimation of model performance and contributions to NLP progress. However, the impact of cultural bias on metaphor processing, particularly in multimodal contexts, remains largely unexplored. To address this gap, we introduce MultiMM, a Multicultural Multimodal Metaphor dataset designed for cross-cultural studies of metaphor in Chinese and English. MultiMM consists of 8,461 text-image advertisement pairs, each accompanied by fine-grained annotations, providing a deeper understanding of multimodal metaphors beyond a single cultural domain. Additionally, we propose Sentiment-Enriched Metaphor Detection (SEMD), a baseline model that integrates sentiment embeddings to enhance metaphor comprehension across cultural backgrounds. Experimental results validate the effectiveness of SEMD on metaphor detection and sentiment analysis tasks. We hope this work increases awareness of cultural bias in NLP research and contributes to the development of fairer and more inclusive language models. Our dataset and code are available at https://github.com/DUTIR-YSQ/MultiMM.
MSE-Adapter: A Lightweight Plugin Endowing LLMs with the Capability to Perform Multimodal Sentiment Analysis and Emotion Recognition
Feb 18, 2025Current Multimodal Sentiment Analysis (MSA) and Emotion Recognition in Conversations (ERC) methods based on pre-trained language models exhibit two primary limitations: 1) Once trained for MSA and ERC tasks, these pre-trained language models lose their original generalized capabilities. 2) They demand considerable computational resources. As the size of pre-trained language models continues to grow, training larger multimodal sentiment analysis models using previous approaches could result in unnecessary computational cost. In response to this challenge, we propose \textbf{M}ultimodal \textbf{S}entiment Analysis and \textbf{E}motion Recognition \textbf{Adapter} (MSE-Adapter), a lightweight and adaptable plugin. This plugin enables a large language model (LLM) to carry out MSA or ERC tasks with minimal computational overhead (only introduces approximately 2.6M to 2.8M trainable parameters upon the 6/7B models), while preserving the intrinsic capabilities of the LLM. In the MSE-Adapter, the Text-Guide-Mixer (TGM) module is introduced to establish explicit connections between non-textual and textual modalities through the Hadamard product. This allows non-textual modalities to better align with textual modalities at the feature level, promoting the generation of higher-quality pseudo tokens. Extensive experiments were conducted on four public English and Chinese datasets using consumer-grade GPUs and open-source LLMs (Qwen-1.8B, ChatGLM3-6B-base, and LLaMA2-7B) as the backbone. The results demonstrate the effectiveness of the proposed plugin. The code will be released on GitHub after a blind review.
Emotions in the Loop: A Survey of Affective Computing for Emotional Support
May 02, 2025In a world where technology is increasingly embedded in our everyday experiences, systems that sense and respond to human emotions are elevating digital interaction. At the intersection of artificial intelligence and human-computer interaction, affective computing is emerging with innovative solutions where machines are humanized by enabling them to process and respond to user emotions. This survey paper explores recent research contributions in affective computing applications in the area of emotion recognition, sentiment analysis and personality assignment developed using approaches like large language models (LLMs), multimodal techniques, and personalized AI systems. We analyze the key contributions and innovative methodologies applied by the selected research papers by categorizing them into four domains: AI chatbot applications, multimodal input systems, mental health and therapy applications, and affective computing for safety applications. We then highlight the technological strengths as well as the research gaps and challenges related to these studies. Furthermore, the paper examines the datasets used in each study, highlighting how modality, scale, and diversity impact the development and performance of affective models. Finally, the survey outlines ethical considerations and proposes future directions to develop applications that are more safe, empathetic and practical.
Multimodal Emotion Recognition and Sentiment Analysis in Multi-Party Conversation Contexts
Mar 09, 2025Emotion recognition and sentiment analysis are pivotal tasks in speech and language processing, particularly in real-world scenarios involving multi-party, conversational data. This paper presents a multimodal approach to tackle these challenges on a well-known dataset. We propose a system that integrates four key modalities/channels using pre-trained models: RoBERTa for text, Wav2Vec2 for speech, a proposed FacialNet for facial expressions, and a CNN+Transformer architecture trained from scratch for video analysis. Feature embeddings from each modality are concatenated to form a multimodal vector, which is then used to predict emotion and sentiment labels. The multimodal system demonstrates superior performance compared to unimodal approaches, achieving an accuracy of 66.36% for emotion recognition and 72.15% for sentiment analysis.
TI-JEPA: An Innovative Energy-based Joint Embedding Strategy for Text-Image Multimodal Systems
Mar 09, 2025This paper focuses on multimodal alignment within the realm of Artificial Intelligence, particularly in text and image modalities. The semantic gap between the textual and visual modality poses a discrepancy problem towards the effectiveness of multi-modalities fusion. Therefore, we introduce Text-Image Joint Embedding Predictive Architecture (TI-JEPA), an innovative pre-training strategy that leverages energy-based model (EBM) framework to capture complex cross-modal relationships. TI-JEPA combines the flexibility of EBM in self-supervised learning to facilitate the compatibility between textual and visual elements. Through extensive experiments across multiple benchmarks, we demonstrate that TI-JEPA achieves state-of-the-art performance on multimodal sentiment analysis task (and potentially on a wide range of multimodal-based tasks, such as Visual Question Answering), outperforming existing pre-training methodologies. Our findings highlight the potential of using energy-based framework in advancing multimodal fusion and suggest significant improvements for downstream applications.
LLaVAC: Fine-tuning LLaVA as a Multimodal Sentiment Classifier
Feb 05, 2025



We present LLaVAC, a method for constructing a classifier for multimodal sentiment analysis. This method leverages fine-tuning of the Large Language and Vision Assistant (LLaVA) to predict sentiment labels across both image and text modalities. Our approach involves designing a structured prompt that incorporates both unimodal and multimodal labels to fine-tune LLaVA, enabling it to perform sentiment classification effectively. Experiments on the MVSA-Single dataset demonstrate that LLaVAC outperforms existing methods in multimodal sentiment analysis across three data processing procedures. The implementation of LLaVAC is publicly available at https://github.com/tchayintr/llavac.
Modality-Invariant Bidirectional Temporal Representation Distillation Network for Missing Multimodal Sentiment Analysis
Jan 07, 2025



Multimodal Sentiment Analysis (MSA) integrates diverse modalities(text, audio, and video) to comprehensively analyze and understand individuals' emotional states. However, the real-world prevalence of incomplete data poses significant challenges to MSA, mainly due to the randomness of modality missing. Moreover, the heterogeneity issue in multimodal data has yet to be effectively addressed. To tackle these challenges, we introduce the Modality-Invariant Bidirectional Temporal Representation Distillation Network (MITR-DNet) for Missing Multimodal Sentiment Analysis. MITR-DNet employs a distillation approach, wherein a complete modality teacher model guides a missing modality student model, ensuring robustness in the presence of modality missing. Simultaneously, we developed the Modality-Invariant Bidirectional Temporal Representation Learning Module (MIB-TRL) to mitigate heterogeneity.