 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViHERMES: A Graph-Grounded Multihop Question Answering Benchmark and System for Vietnamese Healthcare Regulations
Feb 07, 2026Question Answering (QA) over regulatory documents is inherently challenging due to the need for multihop reasoning across legally interdependent texts, a requirement that is particularly pronounced in the healthcare domain where regulations are hierarchically structured and frequently revised through amendments and cross-references. Despite recent progress in retrieval-augmented and graph-based QA methods, systematic evaluation in this setting remains limited, especially for low-resource languages such as Vietnamese, due to the lack of benchmark datasets that explicitly support multihop reasoning over healthcare regulations. In this work, we introduce the Vietnamese Healthcare Regulations-Multihop Reasoning Dataset (ViHERMES), a benchmark designed for multihop QA over Vietnamese healthcare regulatory documents. ViHERMES consists of high-quality question-answer pairs that require reasoning across multiple regulations and capture diverse dependency patterns, including amendment tracing, cross-document comparison, and procedural synthesis. To construct the dataset, we propose a controlled multihop QA generation pipeline based on semantic clustering and graph-inspired data mining, followed by large language model-based generation with structured evidence and reasoning annotations. We further present a graph-aware retrieval framework that models formal legal relations at the level of legal units and supports principled context expansion for legally valid and coherent answers. Experimental results demonstrate that ViHERMES provides a challenging benchmark for evaluating multihop regulatory QA systems and that the proposed graph-aware approach consistently outperforms strong retrieval-based baselines. The ViHERMES dataset and system implementation are publicly available at https://github.com/ura-hcmut/ViHERMES.
A Benchmark Dataset and Evaluation Framework for Vietnamese Large Language Models in Customer Support
Jul 30, 2025
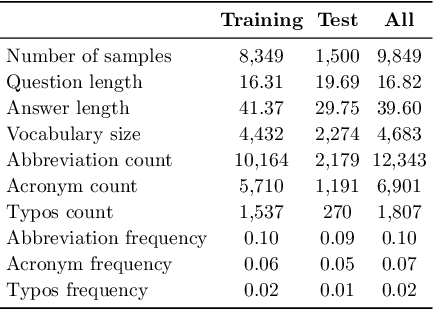
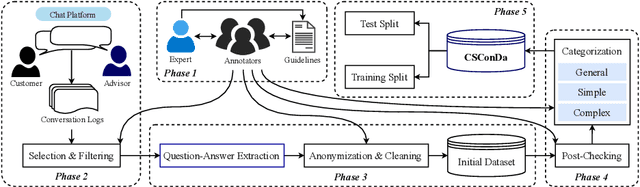

With the rapid growth of Artificial Intelligence, Large Language Models (LLMs) have become essential for Question Answering (QA) systems, improving efficiency and reducing human workload in customer service. The emergence of Vietnamese LLMs (ViLLMs) highlights lightweight open-source models as a practical choice for their accuracy, efficiency, and privacy benefits. However, domain-specific evaluations remain limited, and the absence of benchmark datasets reflecting real customer interactions makes it difficult for enterprises to select suitable models for support applications. To address this gap, we introduce the Customer Support Conversations Dataset (CSConDa), a curated benchmark of over 9,000 QA pairs drawn from real interactions with human advisors at a large Vietnamese software company. Covering diverse topics such as pricing, product availability, and technical troubleshooting, CSConDa provides a representative basis for evaluating ViLLMs in practical scenarios. We further present a comprehensive evaluation framework, benchmarking 11 lightweight open-source ViLLMs on CSConDa with both automatic metrics and syntactic analysis to reveal model strengths, weaknesses, and linguistic patterns. This study offers insights into model behavior, explains performance differences, and identifies key areas for improvement, supporting the development of next-generation ViLLMs. By establishing a robust benchmark and systematic evaluation, our work enables informed model selection for customer service QA and advances research on Vietnamese LLMs. The dataset is publicly available at https://huggingface.co/datasets/ura-hcmut/Vietnamese-Customer-Support-QA.
TI-JEPA: An Innovative Energy-based Joint Embedding Strategy for Text-Image Multimodal Systems
Mar 09, 2025This paper focuses on multimodal alignment within the realm of Artificial Intelligence, particularly in text and image modalities. The semantic gap between the textual and visual modality poses a discrepancy problem towards the effectiveness of multi-modalities fusion. Therefore, we introduce Text-Image Joint Embedding Predictive Architecture (TI-JEPA), an innovative pre-training strategy that leverages energy-based model (EBM) framework to capture complex cross-modal relationships. TI-JEPA combines the flexibility of EBM in self-supervised learning to facilitate the compatibility between textual and visual elements. Through extensive experiments across multiple benchmarks, we demonstrate that TI-JEPA achieves state-of-the-art performance on multimodal sentiment analysis task (and potentially on a wide range of multimodal-based tasks, such as Visual Question Answering), outperforming existing pre-training methodologies. Our findings highlight the potential of using energy-based framework in advancing multimodal fusion and suggest significant improvements for downstream applications.