 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncation Trick
Papers and Code
DFORD: Directional Feedback based Online Ordinal Regression Learning
Dec 22, 2025In this paper, we introduce directional feedback in the ordinal regression setting, in which the learner receives feedback on whether the predicted label is on the left or the right side of the actual label. This is a weak supervision setting for ordinal regression compared to the full information setting, where the learner can access the labels. We propose an online algorithm for ordinal regression using directional feedback. The proposed algorithm uses an exploration-exploitation scheme to learn from directional feedback efficiently. Furthermore, we introduce its kernel-based variant to learn non-linear ordinal regression models in an online setting. We use a truncation trick to make the kernel implementation more memory efficient. The proposed algorithm maintains the ordering of the thresholds in the expected sense. Moreover, it achieves the expected regret of $\mathcal{O}(\log T)$. We compare our approach with a full information and a weakly supervised algorithm for ordinal regression on synthetic and real-world datasets. The proposed approach, which learns using directional feedback, performs comparably (sometimes better) to its full information counterpart.
Feature Proliferation -- the "Cancer" in StyleGAN and its Treatments
Oct 13, 2023



Despite the success of StyleGAN in image synthesis, the images it synthesizes are not always perfect and the well-known truncation trick has become a standard post-processing technique for StyleGAN to synthesize high-quality images. Although effective, it has long been noted that the truncation trick tends to reduce the diversity of synthesized images and unnecessarily sacrifices many distinct image features. To address this issue, in this paper, we first delve into the StyleGAN image synthesis mechanism and discover an important phenomenon, namely Feature Proliferation, which demonstrates how specific features reproduce with forward propagation. Then, we show how the occurrence of Feature Proliferation results in StyleGAN image artifacts. As an analogy, we refer to it as the" cancer" in StyleGAN from its proliferating and malignant nature. Finally, we propose a novel feature rescaling method that identifies and modulates risky features to mitigate feature proliferation. Thanks to our discovery of Feature Proliferation, the proposed feature rescaling method is less destructive and retains more useful image features than the truncation trick, as it is more fine-grained and works in a lower-level feature space rather than a high-level latent space. Experimental results justify the validity of our claims and the effectiveness of the proposed feature rescaling method. Our code is available at https://github. com/songc42/Feature-proliferation.
Recursive Speculative Decoding: Accelerating LLM Inference via Sampling Without Replacement
Mar 05, 2024



Speculative decoding is an inference-acceleration method for large language models (LLMs) where a small language model generates a draft-token sequence which is further verified by the target LLM in parallel. Recent works have advanced this method by establishing a draft-token tree, achieving superior performance over a single-sequence speculative decoding. However, those works independently generate tokens at each level of the tree, not leveraging the tree's entire diversifiability. Besides, their empirical superiority has been shown for fixed length of sequences, implicitly granting more computational resource to LLM for the tree-based methods. None of the existing works has conducted empirical studies with fixed target computational budgets despite its importance to resource-bounded devices. We present Recursive Speculative Decoding (RSD), a novel tree-based method that samples draft tokens without replacement and maximizes the diversity of the tree. During RSD's drafting, the tree is built by either Gumbel-Top-$k$ trick that draws tokens without replacement in parallel or Stochastic Beam Search that samples sequences without replacement while early-truncating unlikely draft sequences and reducing the computational cost of LLM. We empirically evaluate RSD with Llama 2 and OPT models, showing that RSD outperforms the baseline methods, consistently for fixed draft sequence length and in most cases for fixed computational budgets at LLM.
Unsupervised evaluation of GAN sample quality: Introducing the TTJac Score
Aug 31, 2023



Evaluation metrics are essential for assessing the performance of generative models in image synthesis. However, existing metrics often involve high memory and time consumption as they compute the distance between generated samples and real data points. In our study, the new evaluation metric called the "TTJac score" is proposed to measure the fidelity of individual synthesized images in a data-free manner. The study first establishes a theoretical approach to directly evaluate the generated sample density. Then, a method incorporating feature extractors and discrete function approximation through tensor train is introduced to effectively assess the quality of generated samples. Furthermore, the study demonstrates that this new metric can be used to improve the fidelity-variability trade-off when applying the truncation trick. The experimental results of applying the proposed metric to StyleGAN 2 and StyleGAN 2 ADA models on FFHQ, AFHQ-Wild, LSUN-Cars, and LSUN-Horse datasets are presented. The code used in this research will be made publicly available online for the research community to access and utilize.
TransMRSR: Transformer-based Self-Distilled Generative Prior for Brain MRI Super-Resolution
Jun 11, 2023Magnetic resonance images (MRI) acquired with low through-plane resolution compromise time and cost. The poor resolution in one orientation is insufficient to meet the requirement of high resolution for early diagnosis of brain disease and morphometric study. The common Single image super-resolution (SISR) solutions face two main challenges: (1) local detailed and global anatomical structural information combination; and (2) large-scale restoration when applied for reconstructing thick-slice MRI into high-resolution (HR) iso-tropic data. To address these problems, we propose a novel two-stage network for brain MRI SR named TransMRSR based on the convolutional blocks to extract local information and transformer blocks to capture long-range dependencies. TransMRSR consists of three modules: the shallow local feature extraction, the deep non-local feature capture, and the HR image reconstruction. We perform a generative task to encapsulate diverse priors into a generative network (GAN), which is the decoder sub-module of the deep non-local feature capture part, in the first stage. The pre-trained GAN is used for the second stage of SR task. We further eliminate the potential latent space shift caused by the two-stage training strategy through the self-distilled truncation trick. The extensive experiments show that our method achieves superior performance to other SSIR methods on both public and private datasets. Code is released at https://github.com/goddesshs/TransMRSR.git .
Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling
Jun 13, 2022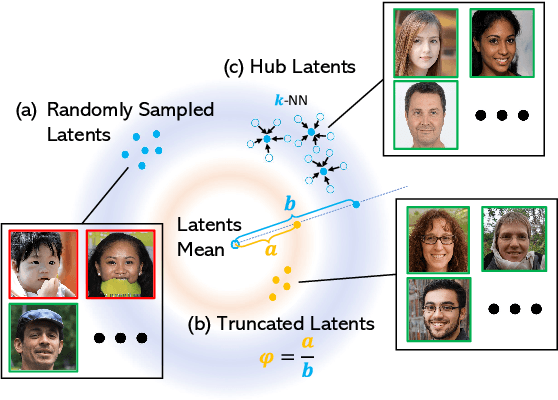
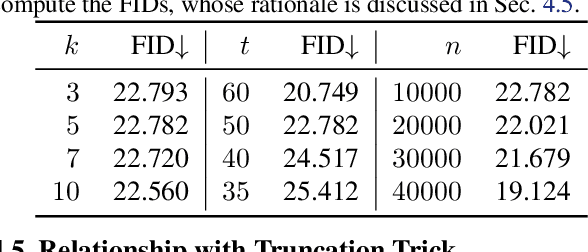
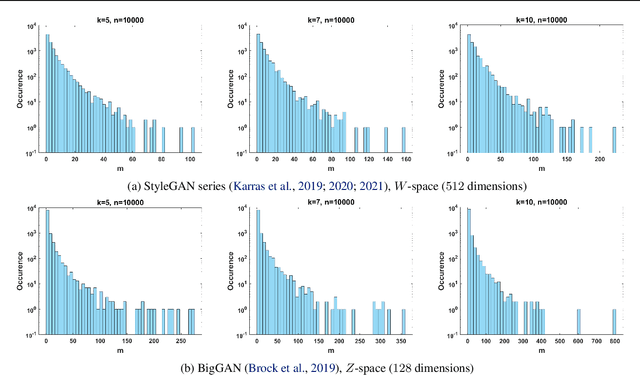
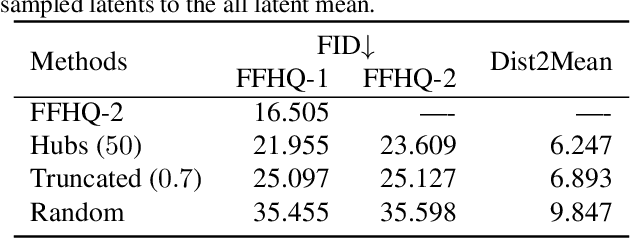
Despite the extensive studies on Generative Adversarial Networks (GANs), how to reliably sample high-quality images from their latent spaces remains an under-explored topic. In this paper, we propose a novel GAN latent sampling method by exploring and exploiting the hubness priors of GAN latent distributions. Our key insight is that the high dimensionality of the GAN latent space will inevitably lead to the emergence of hub latents that usually have much larger sampling densities than other latents in the latent space. As a result, these hub latents are better trained and thus contribute more to the synthesis of high-quality images. Unlike the a posterior "cherry-picking", our method is highly efficient as it is an a priori method that identifies high-quality latents before the synthesis of images. Furthermore, we show that the well-known but purely empirical truncation trick is a naive approximation to the central clustering effect of hub latents, which not only uncovers the rationale of the truncation trick, but also indicates the superiority and fundamentality of our method. Extensive experimental results demonstrate the effectiveness of the proposed method.
Art Creation with Multi-Conditional StyleGANs
Feb 23, 2022



Creating meaningful art is often viewed as a uniquely human endeavor. A human artist needs a combination of unique skills, understanding, and genuine intention to create artworks that evoke deep feelings and emotions. In this paper, we introduce a multi-conditional Generative Adversarial Network (GAN) approach trained on large amounts of human paintings to synthesize realistic-looking paintings that emulate human art. Our approach is based on the StyleGAN neural network architecture, but incorporates a custom multi-conditional control mechanism that provides fine-granular control over characteristics of the generated paintings, e.g., with regard to the perceived emotion evoked in a spectator. For better control, we introduce the conditional truncation trick, which adapts the standard truncation trick for the conditional setting and diverse datasets. Finally, we develop a diverse set of evaluation techniques tailored to multi-conditional generation.
Self-Distilled StyleGAN: Towards Generation from Internet Photos
Feb 24, 2022
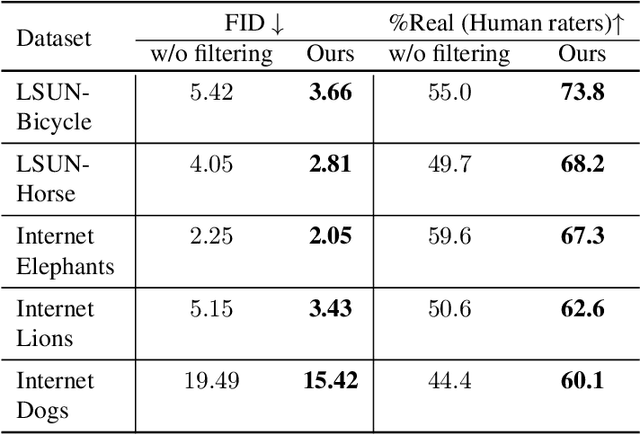
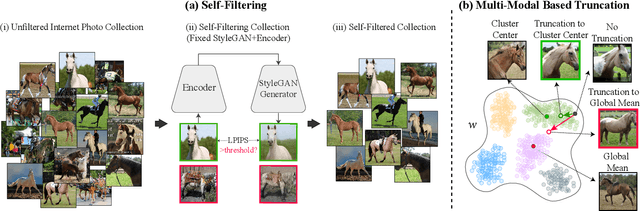
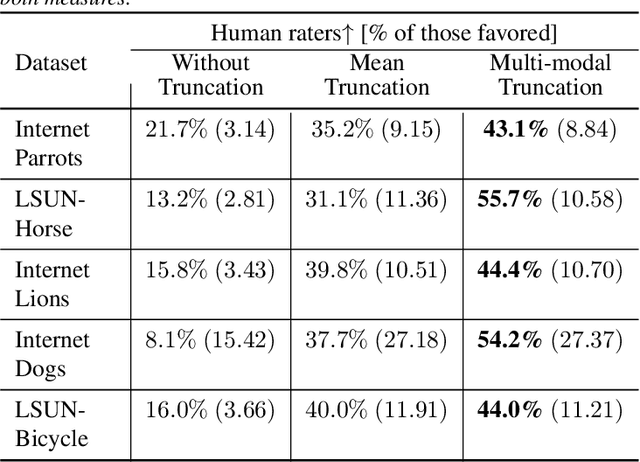
StyleGAN is known to produce high-fidelity images, while also offering unprecedented semantic editing. However, these fascinating abilities have been demonstrated only on a limited set of datasets, which are usually structurally aligned and well curated. In this paper, we show how StyleGAN can be adapted to work on raw uncurated images collected from the Internet. Such image collections impose two main challenges to StyleGAN: they contain many outlier images, and are characterized by a multi-modal distribution. Training StyleGAN on such raw image collections results in degraded image synthesis quality. To meet these challenges, we proposed a StyleGAN-based self-distillation approach, which consists of two main components: (i) A generative-based self-filtering of the dataset to eliminate outlier images, in order to generate an adequate training set, and (ii) Perceptual clustering of the generated images to detect the inherent data modalities, which are then employed to improve StyleGAN's "truncation trick" in the image synthesis process. The presented technique enables the generation of high-quality images, while minimizing the loss in diversity of the data. Through qualitative and quantitative evaluation, we demonstrate the power of our approach to new challenging and diverse domains collected from the Internet. New datasets and pre-trained models are available at https://self-distilled-stylegan.github.io/ .
Self-supervised learning with rotation-invariant kernels
Jul 28, 2022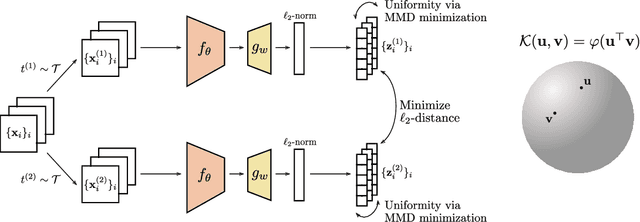
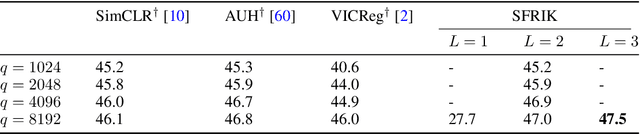
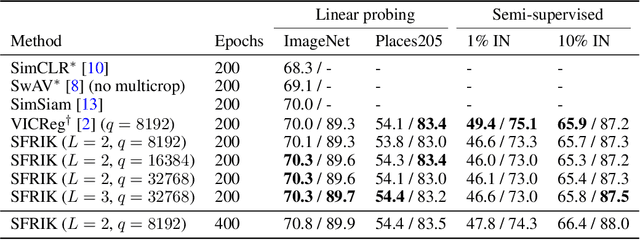

A major paradigm for learning image representations in a self-supervised manner is to learn a model that is invariant to some predefined image transformations (cropping, blurring, color jittering, etc.), while regularizing the embedding distribution to avoid learning a degenerate solution. Our first contribution is to propose a general kernel framework to design a generic regularization loss that promotes the embedding distribution to be close to the uniform distribution on the hypersphere, with respect to the maximum mean discrepancy pseudometric. Our framework uses rotation-invariant kernels defined on the hypersphere, also known as dot-product kernels. Our second contribution is to show that this flexible kernel approach encompasses several existing self-supervised learning methods, including uniformity-based and information-maximization methods. Finally, by exploring empirically several kernel choices, our experiments demonstrate that using a truncated rotation-invariant kernel provides competitive results compared to state-of-the-art methods, and we show practical situations where our method benefits from the kernel trick to reduce computational complexity.
SVD-GCN: A Simplified Graph Convolution Paradigm for Recommendation
Aug 26, 2022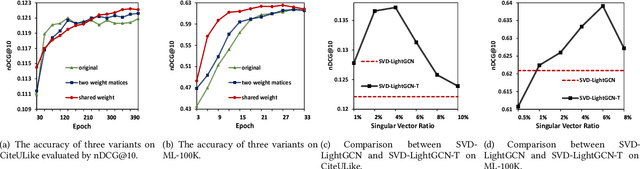
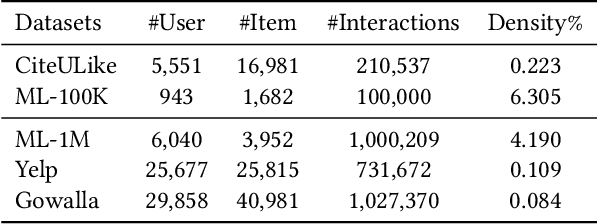
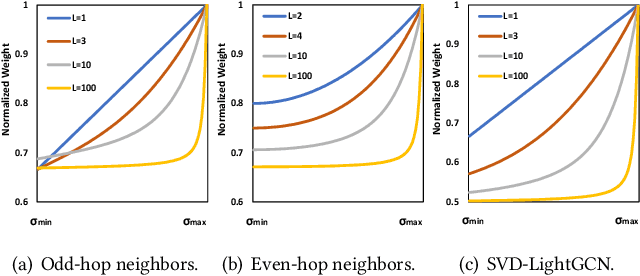
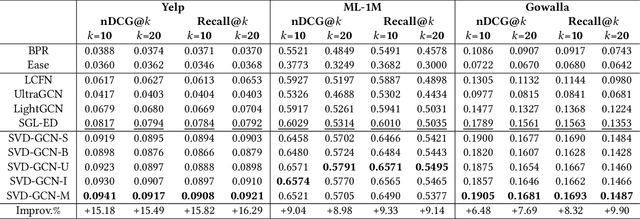
With the tremendous success of Graph Convolutional Networks (GCNs), they have been widely applied to recommender systems and have shown promising performance. However, most GCN-based methods rigorously stick to a common GCN learning paradigm and suffer from two limitations: (1) the limited scalability due to the high computational cost and slow training convergence; (2) the notorious over-smoothing issue which reduces performance as stacking graph convolution layers. We argue that the above limitations are due to the lack of a deep understanding of GCN-based methods. To this end, we first investigate what design makes GCN effective for recommendation. By simplifying LightGCN, we show the close connection between GCN-based and low-rank methods such as Singular Value Decomposition (SVD) and Matrix Factorization (MF), where stacking graph convolution layers is to learn a low-rank representation by emphasizing (suppressing) components with larger (smaller) singular values. Based on this observation, we replace the core design of GCN-based methods with a flexible truncated SVD and propose a simplified GCN learning paradigm dubbed SVD-GCN, which only exploits $K$-largest singular vectors for recommendation. To alleviate the over-smoothing issue, we propose a renormalization trick to adjust the singular value gap, resulting in significant improvement. Extensive experiments on three real-world datasets show that our proposed SVD-GCN not only significantly outperforms state-of-the-arts but also achieves over 100x and 10x speedups over LightGCN and MF, respectively.