 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreethazards
Papers and Code
Maskomaly:Zero-Shot Mask Anomaly Segmentation
May 26, 2023



We present a simple and practical framework for anomaly segmentation called Maskomaly. It builds upon mask-based standard semantic segmentation networks by adding a simple inference-time post-processing step which leverages the raw mask outputs of such networks. Maskomaly does not require additional training and only adds a small computational overhead to inference. Most importantly, it does not require anomalous data at training. We show top results for our method on SMIYC, RoadAnomaly, and StreetHazards. On the most central benchmark, SMIYC, Maskomaly outperforms all directly comparable approaches. Further, we introduce a novel metric that benefits the development of robust anomaly segmentation methods and demonstrate its informativeness on RoadAnomaly.
Far Away in the Deep Space: Nearest-Neighbor-Based Dense Out-of-Distribution Detection
Nov 12, 2022



The key to out-of-distribution detection is density estimation of the in-distribution data or of its feature representations. While good parametric solutions to this problem exist for well curated classification data, these are less suitable for complex domains, such as semantic segmentation. In this paper, we show that a k-Nearest-Neighbors approach can achieve surprisingly good results with small reference datasets and runtimes, and be robust with respect to hyperparameters, such as the number of neighbors and the choice of the support set size. Moreover, we show that it combines well with anomaly scores from standard parametric approaches, and we find that transformer features are particularly well suited to detect novel objects in combination with k-Nearest-Neighbors. Ultimately, the approach is simple and non-invasive, i.e., it does not affect the primary segmentation performance, avoids training on examples of anomalies, and achieves state-of-the-art results on the common benchmarks with +23% and +16% AP improvements on on RoadAnomaly and StreetHazards respectively.
Prototype Guided Network for Anomaly Segmentation
Jan 15, 2022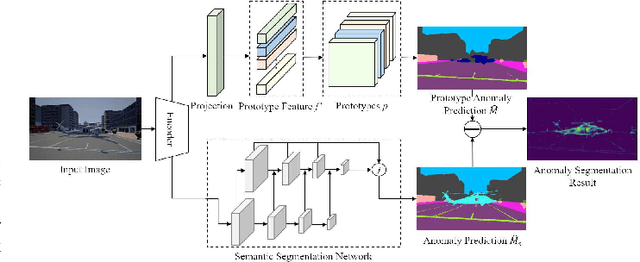

Semantic segmentation methods can not directly identify abnormal objects in images. Anomaly Segmentation algorithm from this realistic setting can distinguish between in-distribution objects and Out-Of-Distribution (OOD) objects and output the anomaly probability for pixels. In this paper, a Prototype Guided Anomaly segmentation Network (PGAN) is proposed to extract semantic prototypes for in-distribution training data from limited annotated images. In the model, prototypes are used to model the hierarchical category semantic information and distinguish OOD pixels. The proposed PGAN model includes a semantic segmentation network and a prototype extraction network. Similarity measures are adopted to optimize the prototypes. The learned semantic prototypes are used as category semantics to compare the similarity with features extracted from test images and then to generate semantic segmentation prediction. The proposed prototype extraction network can also be integrated into most semantic segmentation networks and recognize OOD pixels. On the StreetHazards dataset, the proposed PGAN model produced mIoU of 53.4% for anomaly segmentation. The experimental results demonstrate PGAN may achieve the SOTA performance in the anomaly segmentation tasks.
Anomaly Discovery in Semantic Segmentation via Distillation Comparison Networks
Dec 18, 2021
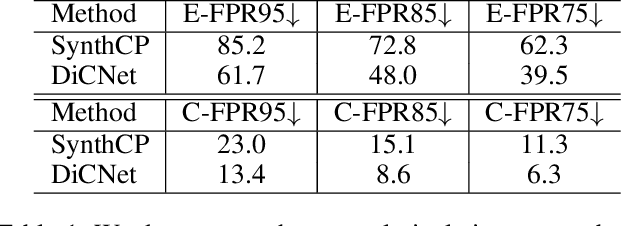
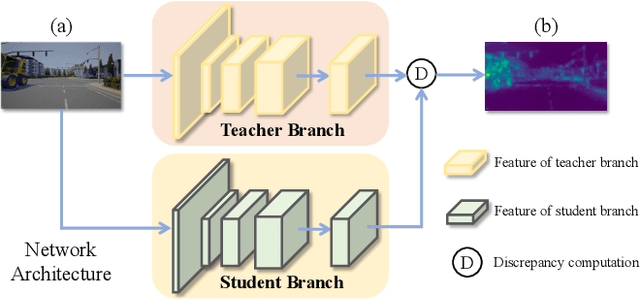
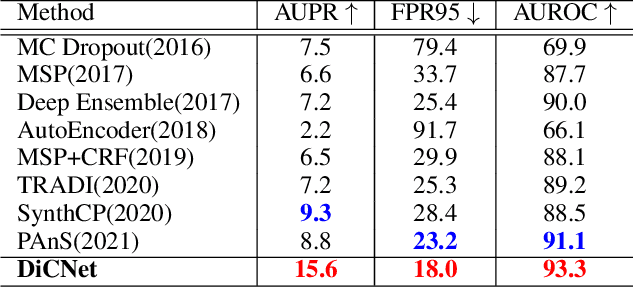
This paper aims to address the problem of anomaly discovery in semantic segmentation. Our key observation is that semantic classification plays a critical role in existing approaches, while the incorrectly classified pixels are easily regarded as anomalies. Such a phenomenon frequently appears and is rarely discussed, which significantly reduces the performance of anomaly discovery. To this end, we propose a novel Distillation Comparison Network (DiCNet). It comprises of a teacher branch which is a semantic segmentation network that removed the semantic classification head, and a student branch that is distilled from the teacher branch through a distribution distillation. We show that the distillation guarantees the semantic features of the two branches hold consistency in the known classes, while reflect inconsistency in the unknown class. Therefore, we leverage the semantic feature discrepancy between the two branches to discover the anomalies. DiCNet abandons the semantic classification head in the inference process, and hence significantly alleviates the issue caused by incorrect semantic classification. Extensive experimental results on StreetHazards dataset and BDD-Anomaly dataset are conducted to verify the superior performance of DiCNet. In particular, DiCNet obtains a 6.3% improvement in AUPR and a 5.2% improvement in FPR95 on StreetHazards dataset, achieves a 4.2% improvement in AUPR and a 6.8% improvement in FPR95 on BDD-Anomaly dataset. Codes are available at https://github.com/zhouhuan-hust/DiCNet.
Detecting Anomalies in Semantic Segmentation with Prototypes
Jun 01, 2021
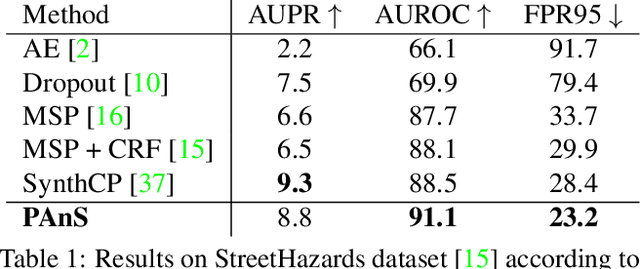


Traditional semantic segmentation methods can recognize at test time only the classes that are present in the training set. This is a significant limitation, especially for semantic segmentation algorithms mounted on intelligent autonomous systems, deployed in realistic settings. Regardless of how many classes the system has seen at training time, it is inevitable that unexpected, unknown objects will appear at test time. The failure in identifying such anomalies may lead to incorrect, even dangerous behaviors of the autonomous agent equipped with such segmentation model when deployed in the real world. Current state of the art of anomaly segmentation uses generative models, exploiting their incapability to reconstruct patterns unseen during training. However, training these models is expensive, and their generated artifacts may create false anomalies. In this paper we take a different route and we propose to address anomaly segmentation through prototype learning. Our intuition is that anomalous pixels are those that are dissimilar to all class prototypes known by the model. We extract class prototypes from the training data in a lightweight manner using a cosine similarity-based classifier. Experiments on StreetHazards show that our approach achieves the new state of the art, with a significant margin over previous works, despite the reduced computational overhead. Code is available at https://github.com/DarioFontanel/PAnS.
Dense outlier detection and open-set recognition based on training with noisy negative images
Jan 22, 2021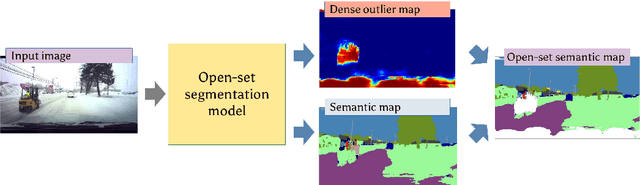
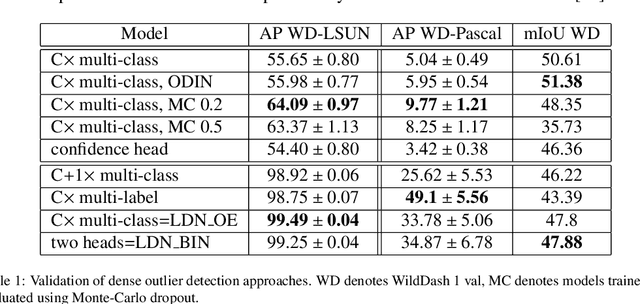
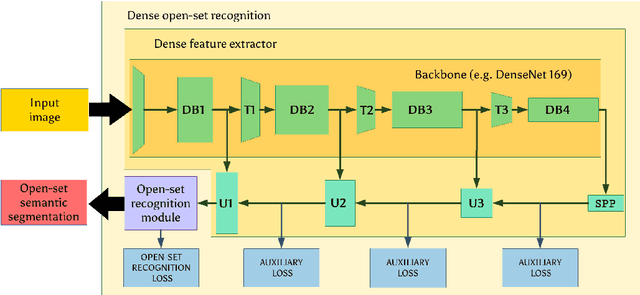
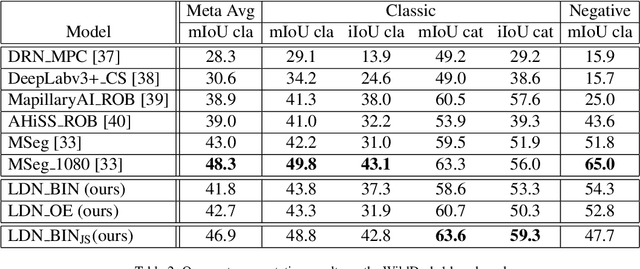
Deep convolutional models often produce inadequate predictions for inputs foreign to the training distribution. Consequently, the problem of detecting outlier images has recently been receiving a lot of attention. Unlike most previous work, we address this problem in the dense prediction context in order to be able to locate outlier objects in front of in-distribution background. Our approach is based on two reasonable assumptions. First, we assume that the inlier dataset is related to some narrow application field (e.g.~road driving). Second, we assume that there exists a general-purpose dataset which is much more diverse than the inlier dataset (e.g.~ImageNet-1k). We consider pixels from the general-purpose dataset as noisy negative training samples since most (but not all) of them are outliers. We encourage the model to recognize borders between known and unknown by pasting jittered negative patches over inlier training images. Our experiments target two dense open-set recognition benchmarks (WildDash 1 and Fishyscapes) and one dense open-set recognition dataset (StreetHazard). Extensive performance evaluation indicates competitive potential of the proposed approach.
Dense open-set recognition with synthetic outliers generated by Real NVP
Nov 22, 2020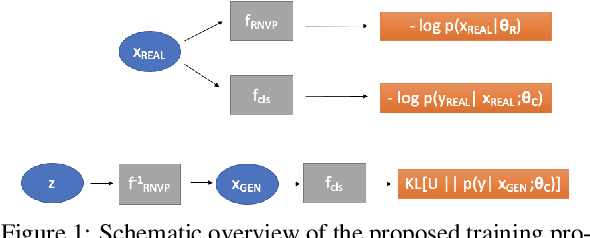

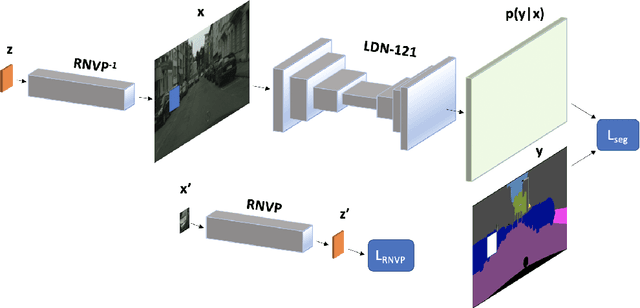
Today's deep models are often unable to detect inputs which do not belong to the training distribution. This gives rise to confident incorrect predictions which could lead to devastating consequences in many important application fields such as healthcare and autonomous driving. Interestingly, both discriminative and generative models appear to be equally affected. Consequently, this vulnerability represents an important research challenge. We consider an outlier detection approach based on discriminative training with jointly learned synthetic outliers. We obtain the synthetic outliers by sampling an RNVP model which is jointly trained to generate datapoints at the border of the training distribution. We show that this approach can be adapted for simultaneous semantic segmentation and dense outlier detection. We present image classification experiments on CIFAR-10, as well as semantic segmentation experiments on three existing datasets (StreetHazards, WD-Pascal, Fishyscapes Lost & Found), and one contributed dataset. Our models perform competitively with respect to the state of the art despite producing predictions with only one forward pass.
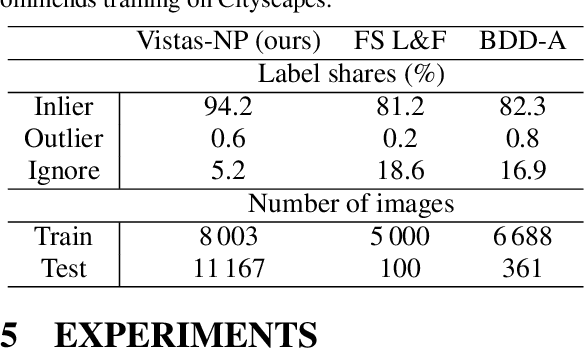
Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation
Mar 18, 2020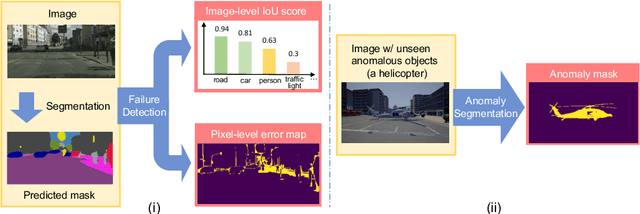
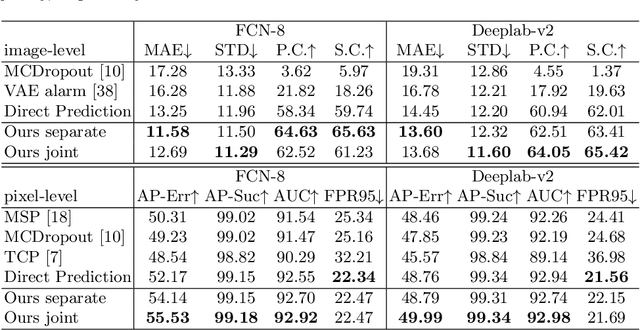
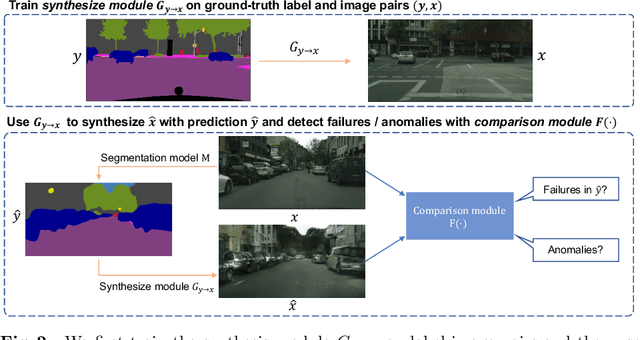
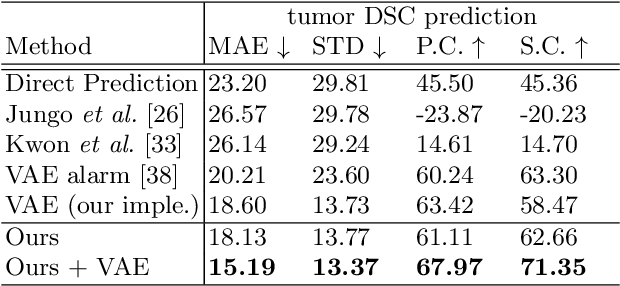
The ability to detect failures and anomalies are fundamental requirements for building reliable systems for computer vision applications, especially safety-critical applications of semantic segmentation, such as autonomous driving and medical image analysis. In this paper, we systematically study failure and anomaly detection for semantic segmentation and propose a unified framework, consisting of two modules, to address these two related problems. The first module is an image synthesis module, which generates a synthesized image from a segmentation layout map, and the second is a comparison module, which computes the difference between the synthesized image and the input image. We validate our framework on three challenging datasets and improve the state-of-the-arts by large margins, i.e., 6% AUPR-Error on Cityscapes, 10% DSC correlation on pancreatic tumor segmentation in MSD and 20% AUPR on StreetHazards anomaly segmentation.