 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel What Matters: Modality-Balanced and Difficulty-Aware Multimodal Active Learning
Mar 26, 2026Multimodal learning integrates complementary information from different modalities such as image, text, and audio to improve model performance, but its success relies on large-scale labeled data, which is costly to obtain. Active learning (AL) mitigates this challenge by selectively annotating informative samples. In multimodal settings, many approaches implicitly assume that modality importance is stable across rounds and keep selection rules fixed at the fusion stage, which leaves them insensitive to the dynamic nature of multimodal learning, where the relative value of modalities and the difficulty of instances shift as training proceeds. To address this issue, we propose RL-MBA, a reinforcement-learning framework for modality-balanced, difficulty-aware multimodal active learning. RL-MBA models sample selection as a Markov Decision Process, where the policy adapts to modality contributions, uncertainty, and diversity, and the reward encourages accuracy gains and balance. Two key components drive this adaptability: (1) Adaptive Modality Contribution Balancing (AMCB), which dynamically adjusts modality weights via reinforcement feedback, and (2) Evidential Fusion for DifficultyAware Policy Adjustment (EFDA), which estimates sample difficulty via uncertainty-based evidential fusion to prioritize informative samples. Experiments on Food101, KineticsSound, and VGGSound demonstrate that RL-MBA consistently outperforms strong baselines, improving both classification accuracy and modality fairness under limited labeling budgets.
Prototype Guided Network for Anomaly Segmentation
Jan 15, 2022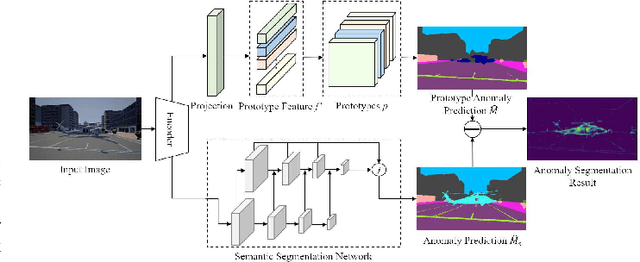

Semantic segmentation methods can not directly identify abnormal objects in images. Anomaly Segmentation algorithm from this realistic setting can distinguish between in-distribution objects and Out-Of-Distribution (OOD) objects and output the anomaly probability for pixels. In this paper, a Prototype Guided Anomaly segmentation Network (PGAN) is proposed to extract semantic prototypes for in-distribution training data from limited annotated images. In the model, prototypes are used to model the hierarchical category semantic information and distinguish OOD pixels. The proposed PGAN model includes a semantic segmentation network and a prototype extraction network. Similarity measures are adopted to optimize the prototypes. The learned semantic prototypes are used as category semantics to compare the similarity with features extracted from test images and then to generate semantic segmentation prediction. The proposed prototype extraction network can also be integrated into most semantic segmentation networks and recognize OOD pixels. On the StreetHazards dataset, the proposed PGAN model produced mIoU of 53.4% for anomaly segmentation. The experimental results demonstrate PGAN may achieve the SOTA performance in the anomaly segmentation tasks.