 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised training of universal visual concepts for multi-domain semantic segmentation
Dec 20, 2022Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on multiple datasets becomes a method of choice towards strong generalization in usual scenes and graceful performance degradation in edge cases. Unfortunately, different datasets often have incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. Furthermore, many datasets have overlapping labels. For instance, pickups are labeled as trucks in VIPER, cars in Vistas, and vans in ADE20k. We address this challenge by considering labels as unions of universal visual concepts. This allows seamless and principled learning on multi-domain dataset collections without requiring any relabeling effort. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
Automatic universal taxonomies for multi-domain semantic segmentation
Jul 18, 2022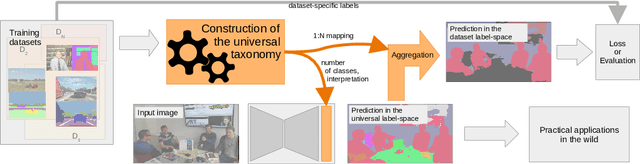
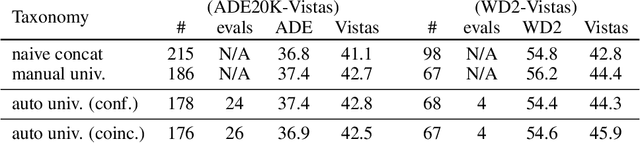
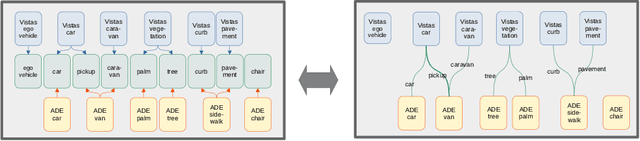

Training semantic segmentation models on multiple datasets has sparked a lot of recent interest in the computer vision community. This interest has been motivated by expensive annotations and a desire to achieve proficiency across multiple visual domains. However, established datasets have mutually incompatible labels which disrupt principled inference in the wild. We address this issue by automatic construction of universal taxonomies through iterative dataset integration. Our method detects subset-superset relationships between dataset-specific labels, and supports learning of sub-class logits by treating super-classes as partial labels. We present experiments on collections of standard datasets and demonstrate competitive generalization performance with respect to previous work.
DenseHybrid: Hybrid Anomaly Detection for Dense Open-set Recognition
Jul 06, 2022
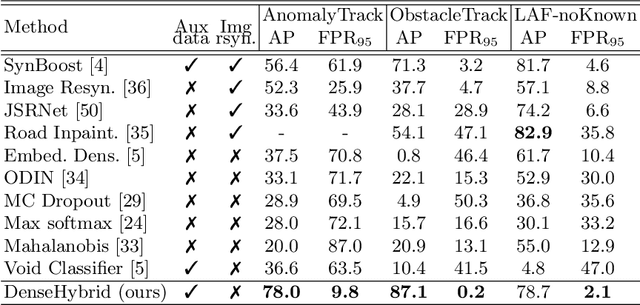
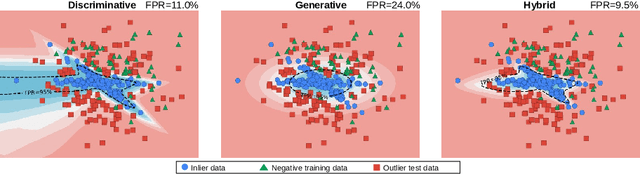
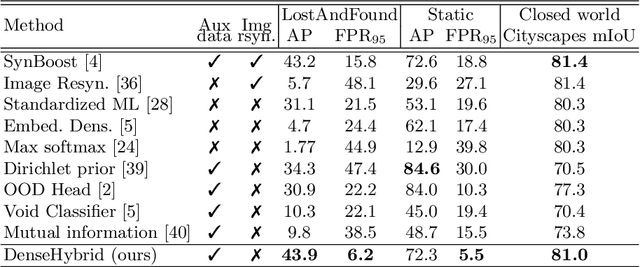
Anomaly detection can be conceived either through generative modelling of regular training data or by discriminating with respect to negative training data. These two approaches exhibit different failure modes. Consequently, hybrid algorithms present an attractive research goal. Unfortunately, dense anomaly detection requires translational equivariance and very large input resolutions. These requirements disqualify all previous hybrid approaches to the best of our knowledge. We therefore design a novel hybrid algorithm based on reinterpreting discriminative logits as a logarithm of the unnormalized joint distribution $\hat{p}(\mathbf{x}, \mathbf{y})$. Our model builds on a shared convolutional representation from which we recover three dense predictions: i) the closed-set class posterior $P(\mathbf{y}|\mathbf{x})$, ii) the dataset posterior $P(d_{in}|\mathbf{x})$, iii) unnormalized data likelihood $\hat{p}(\mathbf{x})$. The latter two predictions are trained both on the standard training data and on a generic negative dataset. We blend these two predictions into a hybrid anomaly score which allows dense open-set recognition on large natural images. We carefully design a custom loss for the data likelihood in order to avoid backpropagation through the untractable normalizing constant $Z(\theta)$. Experiments evaluate our contributions on standard dense anomaly detection benchmarks as well as in terms of open-mIoU - a novel metric for dense open-set performance. Our submissions achieve state-of-the-art performance despite neglectable computational overhead over the standard semantic segmentation baseline.
Dense anomaly detection by robust learning on synthetic negative data
Dec 31, 2021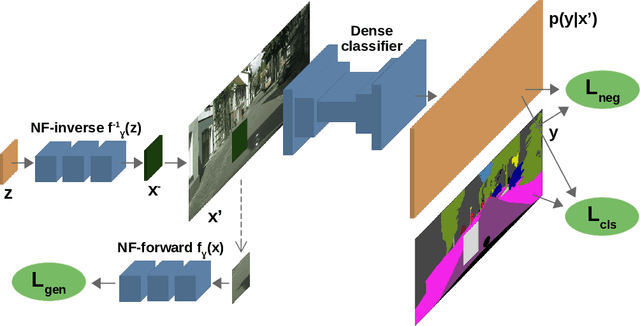

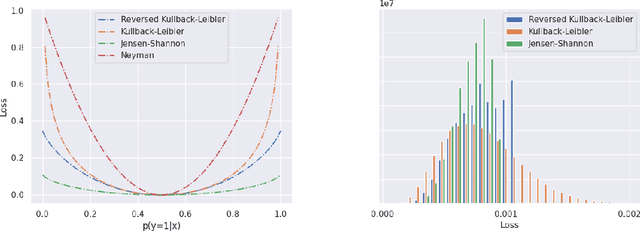
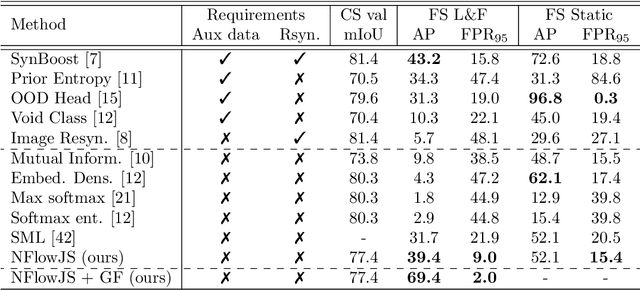
Standard machine learning is unable to accommodate inputs which do not belong to the training distribution. The resulting models often give rise to confident incorrect predictions which may lead to devastating consequences. This problem is especially demanding in the context of dense prediction since input images may be partially anomalous. Previous work has addressed dense anomaly detection by discriminative training on mixed-content images. We extend this approach with synthetic negative patches which simultaneously achieve high inlier likelihood and uniform discriminative prediction. We generate synthetic negatives with normalizing flows due to their outstanding distribution coverage and capability to generate samples at different resolutions. We also propose to detect anomalies according to a principled information-theoretic criterion which can be consistently applied through training and inference. The resulting models set the new state of the art on standard benchmarks and datasets in spite of minimal computational overhead and refraining from auxiliary negative data.
Multi-domain semantic segmentation with overlapping labels
Aug 25, 2021

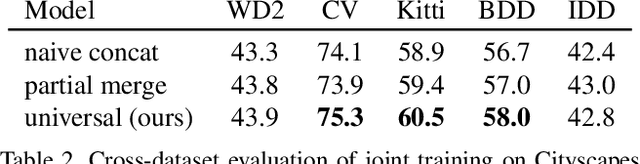

Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on many datasets becomes a method of choice towards graceful degradation in unusual scenes. Unfortunately, different datasets often use incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. We address this challenge by proposing a principled method for seamless learning on datasets with overlapping classes based on partial labels and probabilistic loss. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
Dense outlier detection and open-set recognition based on training with noisy negative images
Jan 22, 2021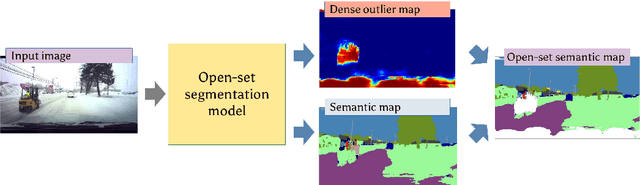
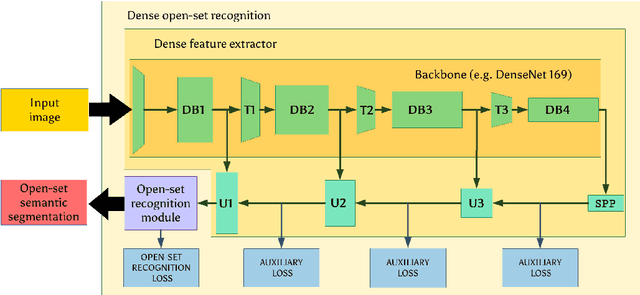
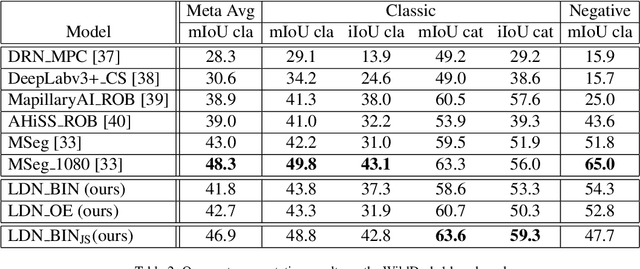
Deep convolutional models often produce inadequate predictions for inputs foreign to the training distribution. Consequently, the problem of detecting outlier images has recently been receiving a lot of attention. Unlike most previous work, we address this problem in the dense prediction context in order to be able to locate outlier objects in front of in-distribution background. Our approach is based on two reasonable assumptions. First, we assume that the inlier dataset is related to some narrow application field (e.g.~road driving). Second, we assume that there exists a general-purpose dataset which is much more diverse than the inlier dataset (e.g.~ImageNet-1k). We consider pixels from the general-purpose dataset as noisy negative training samples since most (but not all) of them are outliers. We encourage the model to recognize borders between known and unknown by pasting jittered negative patches over inlier training images. Our experiments target two dense open-set recognition benchmarks (WildDash 1 and Fishyscapes) and one dense open-set recognition dataset (StreetHazard). Extensive performance evaluation indicates competitive potential of the proposed approach.
Dense open-set recognition with synthetic outliers generated by Real NVP
Nov 22, 2020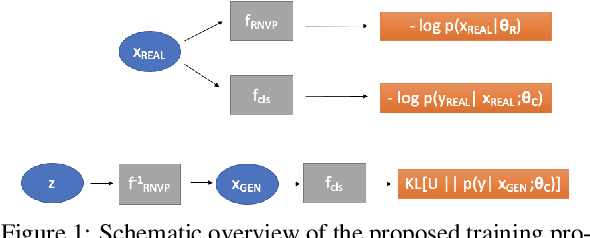

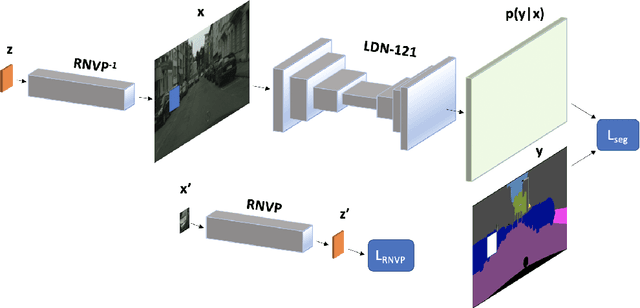
Today's deep models are often unable to detect inputs which do not belong to the training distribution. This gives rise to confident incorrect predictions which could lead to devastating consequences in many important application fields such as healthcare and autonomous driving. Interestingly, both discriminative and generative models appear to be equally affected. Consequently, this vulnerability represents an important research challenge. We consider an outlier detection approach based on discriminative training with jointly learned synthetic outliers. We obtain the synthetic outliers by sampling an RNVP model which is jointly trained to generate datapoints at the border of the training distribution. We show that this approach can be adapted for simultaneous semantic segmentation and dense outlier detection. We present image classification experiments on CIFAR-10, as well as semantic segmentation experiments on three existing datasets (StreetHazards, WD-Pascal, Fishyscapes Lost & Found), and one contributed dataset. Our models perform competitively with respect to the state of the art despite producing predictions with only one forward pass.
Multi-domain semantic segmentation with pyramidal fusion
Sep 16, 2020
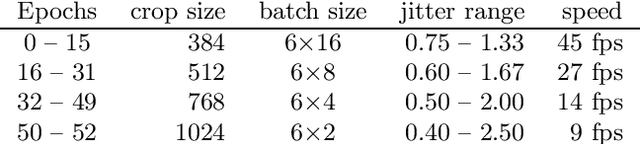

We present our submission to the semantic segmentation contest of the Robust Vision Challenge held at ECCV 2020. The contest requires submitting the same model to seven benchmarks from three different domains. Our approach is based on the SwiftNet architecture with pyramidal fusion. We address inconsistent taxonomies with a single-level 193-dimensional softmax output. We strive to train with large batches in order to stabilize optimization of a hard recognition problem, and to favour smooth evolution of batchnorm statistics. We achieve this by implementing a custom backward step through log-sum-prob loss, and by using small crops before freezing the population statistics. Our model ranks first on the RVC semantic segmentation challenge as well as on the WildDash 2 leaderboard. This suggests that pyramidal fusion is competitive not only for efficient inference with lightweight backbones, but also in large-scale setups for multi-domain application.
Simultaneous Semantic Segmentation and Outlier Detection in Presence of Domain Shift
Aug 03, 2019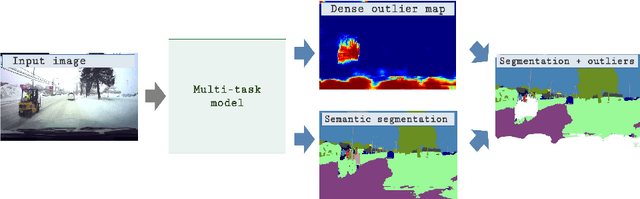
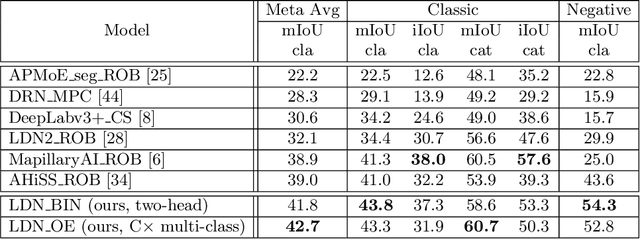
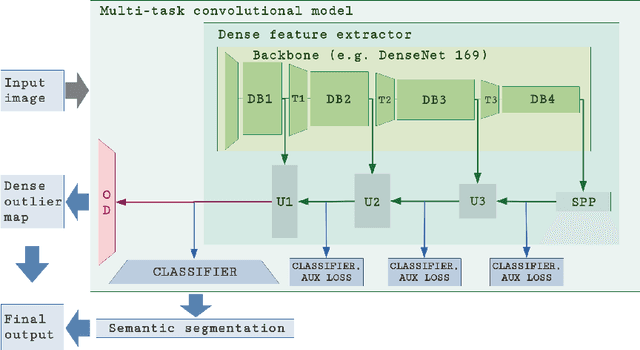
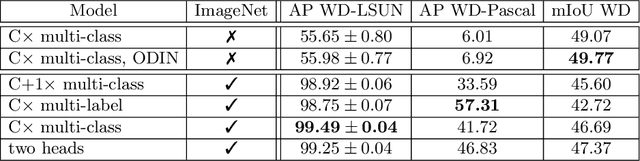
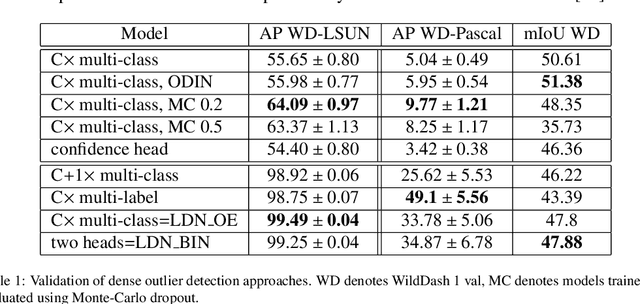
Recent success on realistic road driving datasets has increased interest in exploring robust performance in real-world applications. One of the major unsolved problems is to identify image content which can not be reliably recognized with a given inference engine. We therefore study approaches to recover a dense outlier map alongside the primary task with a single forward pass, by relying on shared convolutional features. We consider semantic segmentation as the primary task and perform extensive validation on WildDash val (inliers), LSUN val (outliers), and pasted objects from Pascal VOC 2007 (outliers). We achieve the best validation performance by training to discriminate inliers from pasted ImageNet-1k content, even though ImageNet-1k contains many road-driving pixels, and, at least nominally, fails to account for the full diversity of the visual world. The proposed two-head model performs comparably to the C-way multi-class model trained to predict uniform distribution in outliers, while outperforming several other validated approaches. We evaluate our best two models on the WildDash test dataset and set a new state of the art on the WildDash benchmark.
In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images
Apr 12, 2019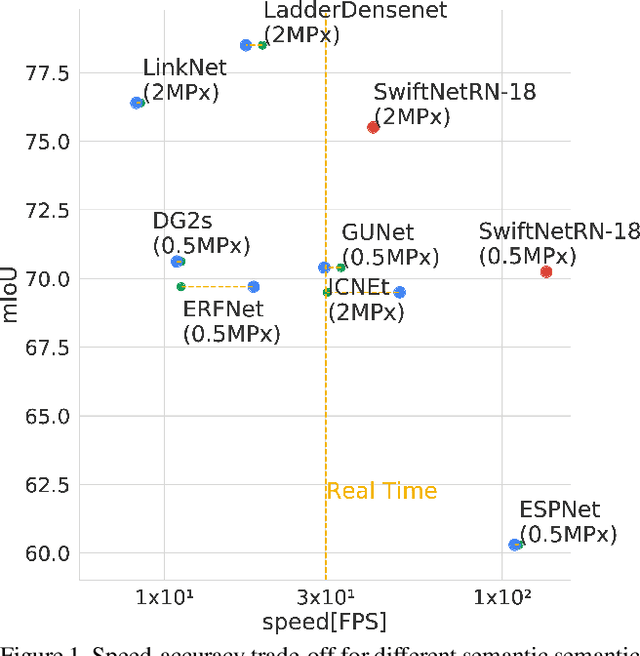
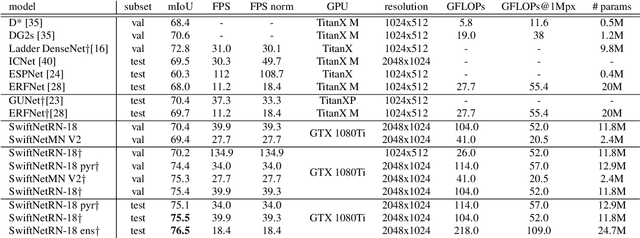
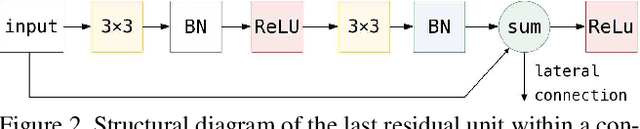
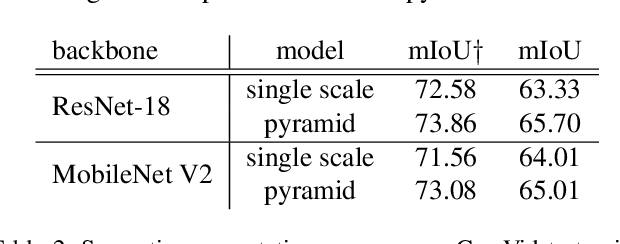
Recent success of semantic segmentation approaches on demanding road driving datasets has spurred interest in many related application fields. Many of these applications involve real-time prediction on mobile platforms such as cars, drones and various kinds of robots. Real-time setup is challenging due to extraordinary computational complexity involved. Many previous works address the challenge with custom lightweight architectures which decrease computational complexity by reducing depth, width and layer capacity with respect to general purpose architectures. We propose an alternative approach which achieves a significantly better performance across a wide range of computing budgets. First, we rely on a light-weight general purpose architecture as the main recognition engine. Then, we leverage light-weight upsampling with lateral connections as the most cost-effective solution to restore the prediction resolution. Finally, we propose to enlarge the receptive field by fusing shared features at multiple resolutions in a novel fashion. Experiments on several road driving datasets show a substantial advantage of the proposed approach, either with ImageNet pre-trained parameters or when we learn from scratch. Our Cityscapes test submission entitled SwiftNetRN-18 delivers 75.5% MIoU and achieves 39.9 Hz on 1024x2048 images on GTX1080Ti.