 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnarks
Papers and Code
ZK-WAGON: Imperceptible Watermark for Image Generation Models using ZK-SNARKs
Oct 02, 2025As image generation models grow increasingly powerful and accessible, concerns around authenticity, ownership, and misuse of synthetic media have become critical. The ability to generate lifelike images indistinguishable from real ones introduces risks such as misinformation, deepfakes, and intellectual property violations. Traditional watermarking methods either degrade image quality, are easily removed, or require access to confidential model internals - making them unsuitable for secure and scalable deployment. We are the first to introduce ZK-WAGON, a novel system for watermarking image generation models using the Zero-Knowledge Succinct Non Interactive Argument of Knowledge (ZK-SNARKs). Our approach enables verifiable proof of origin without exposing model weights, generation prompts, or any sensitive internal information. We propose Selective Layer ZK-Circuit Creation (SL-ZKCC), a method to selectively convert key layers of an image generation model into a circuit, reducing proof generation time significantly. Generated ZK-SNARK proofs are imperceptibly embedded into a generated image via Least Significant Bit (LSB) steganography. We demonstrate this system on both GAN and Diffusion models, providing a secure, model-agnostic pipeline for trustworthy AI image generation.
ZKTorch: Compiling ML Inference to Zero-Knowledge Proofs via Parallel Proof Accumulation
Jul 09, 2025As AI models become ubiquitous in our daily lives, there has been an increasing demand for transparency in ML services. However, the model owner does not want to reveal the weights, as they are considered trade secrets. To solve this problem, researchers have turned to zero-knowledge proofs of ML model inference. These proofs convince the user that the ML model output is correct, without revealing the weights of the model to the user. Past work on these provers can be placed into two categories. The first method compiles the ML model into a low-level circuit, and proves the circuit using a ZK-SNARK. The second method uses custom cryptographic protocols designed only for a specific class of models. Unfortunately, the first method is highly inefficient, making it impractical for the large models used today, and the second method does not generalize well, making it difficult to update in the rapidly changing field of machine learning. To solve this, we propose ZKTorch, an open source end-to-end proving system that compiles ML models into base cryptographic operations called basic blocks, each proved using specialized protocols. ZKTorch is built on top of a novel parallel extension to the Mira accumulation scheme, enabling succinct proofs with minimal accumulation overhead. These contributions allow ZKTorch to achieve at least a $3\times$ reduction in the proof size compared to specialized protocols and up to a $6\times$ speedup in proving time over a general-purpose ZKML framework.
A Cryptographic Perspective on Mitigation vs. Detection in Machine Learning
Apr 28, 2025In this paper, we initiate a cryptographically inspired theoretical study of detection versus mitigation of adversarial inputs produced by attackers of Machine Learning algorithms during inference time. We formally define defense by detection (DbD) and defense by mitigation (DbM). Our definitions come in the form of a 3-round protocol between two resource-bounded parties: a trainer/defender and an attacker. The attacker aims to produce inference-time inputs that fool the training algorithm. We define correctness, completeness, and soundness properties to capture successful defense at inference time while not degrading (too much) the performance of the algorithm on inputs from the training distribution. We first show that achieving DbD and achieving DbM are equivalent for ML classification tasks. Surprisingly, this is not the case for ML generative learning tasks, where there are many possible correct outputs that can be generated for each input. We show a separation between DbD and DbM by exhibiting a generative learning task for which is possible to defend by mitigation but is provably impossible to defend by detection under the assumption that the Identity-Based Fully Homomorphic Encryption (IB-FHE), publicly-verifiable zero-knowledge Succinct Non-Interactive Arguments of Knowledge (zk-SNARK) and Strongly Unforgeable Signatures exist. The mitigation phase uses significantly fewer samples than the initial training algorithm.
TeleSparse: Practical Privacy-Preserving Verification of Deep Neural Networks
Apr 27, 2025Verification of the integrity of deep learning inference is crucial for understanding whether a model is being applied correctly. However, such verification typically requires access to model weights and (potentially sensitive or private) training data. So-called Zero-knowledge Succinct Non-Interactive Arguments of Knowledge (ZK-SNARKs) would appear to provide the capability to verify model inference without access to such sensitive data. However, applying ZK-SNARKs to modern neural networks, such as transformers and large vision models, introduces significant computational overhead. We present TeleSparse, a ZK-friendly post-processing mechanisms to produce practical solutions to this problem. TeleSparse tackles two fundamental challenges inherent in applying ZK-SNARKs to modern neural networks: (1) Reducing circuit constraints: Over-parameterized models result in numerous constraints for ZK-SNARK verification, driving up memory and proof generation costs. We address this by applying sparsification to neural network models, enhancing proof efficiency without compromising accuracy or security. (2) Minimizing the size of lookup tables required for non-linear functions, by optimizing activation ranges through neural teleportation, a novel adaptation for narrowing activation functions' range. TeleSparse reduces prover memory usage by 67% and proof generation time by 46% on the same model, with an accuracy trade-off of approximately 1%. We implement our framework using the Halo2 proving system and demonstrate its effectiveness across multiple architectures (Vision-transformer, ResNet, MobileNet) and datasets (ImageNet,CIFAR-10,CIFAR-100). This work opens new directions for ZK-friendly model design, moving toward scalable, resource-efficient verifiable deep learning.
VerifBFL: Leveraging zk-SNARKs for A Verifiable Blockchained Federated Learning
Jan 08, 2025



Blockchain-based Federated Learning (FL) is an emerging decentralized machine learning paradigm that enables model training without relying on a central server. Although some BFL frameworks are considered privacy-preserving, they are still vulnerable to various attacks, including inference and model poisoning. Additionally, most of these solutions employ strong trust assumptions among all participating entities or introduce incentive mechanisms to encourage collaboration, making them susceptible to multiple security flaws. This work presents VerifBFL, a trustless, privacy-preserving, and verifiable federated learning framework that integrates blockchain technology and cryptographic protocols. By employing zero-knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARKs) and incrementally verifiable computation (IVC), VerifBFL ensures the verifiability of both local training and aggregation processes. The proofs of training and aggregation are verified on-chain, guaranteeing the integrity and auditability of each participant's contributions. To protect training data from inference attacks, VerifBFL leverages differential privacy. Finally, to demonstrate the efficiency of the proposed protocols, we built a proof of concept using emerging tools. The results show that generating proofs for local training and aggregation in VerifBFL takes less than 81s and 2s, respectively, while verifying them on-chain takes less than 0.6s.
Privacy-Preserving UCB Decision Process Verification via zk-SNARKs
Apr 18, 2024With the increasingly widespread application of machine learning, how to strike a balance between protecting the privacy of data and algorithm parameters and ensuring the verifiability of machine learning has always been a challenge. This study explores the intersection of reinforcement learning and data privacy, specifically addressing the Multi-Armed Bandit (MAB) problem with the Upper Confidence Bound (UCB) algorithm. We introduce zkUCB, an innovative algorithm that employs the Zero-Knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARKs) to enhance UCB. zkUCB is carefully designed to safeguard the confidentiality of training data and algorithmic parameters, ensuring transparent UCB decision-making. Experiments highlight zkUCB's superior performance, attributing its enhanced reward to judicious quantization bit usage that reduces information entropy in the decision-making process. zkUCB's proof size and verification time scale linearly with the execution steps of zkUCB. This showcases zkUCB's adept balance between data security and operational efficiency. This approach contributes significantly to the ongoing discourse on reinforcing data privacy in complex decision-making processes, offering a promising solution for privacy-sensitive applications.
AC4: Algebraic Computation Checker for Circuit Constraints in ZKPs
Mar 23, 2024ZKP systems have surged attention and held a fundamental role in contemporary cryptography. Zk-SNARK protocols dominate the ZKP usage, often implemented through arithmetic circuit programming paradigm. However, underconstrained or overconstrained circuits may lead to bugs. Underconstrained circuits refer to circuits that lack the necessary constraints, resulting in unexpected solutions in the circuit and causing the verifier to accept a bogus witness. Overconstrained circuits refer to circuits that are constrained excessively, resulting in the circuit lacking necessary solutions and causing the verifier to accept no witness, rendering the circuit meaningless. This paper introduces a novel approach for pinpointing two distinct types of bugs in ZKP circuits. The method involves encoding the arithmetic circuit constraints to polynomial equation systems and solving polynomial equation systems over a finite field by algebraic computation. The classification of verification results is refined, greatly enhancing the expressive power of the system. We proposed a tool, AC4, to represent the implementation of this method. Experiments demonstrate that AC4 represents a substantial 29% increase in the checked ratio compared to prior work. Within a solvable range, the checking time of AC4 has also exhibited noticeable improvement, demonstrating a magnitude increase compared to previous efforts.
Binary Linear Tree Commitment-based Ownership Protection for Distributed Machine Learning
Jan 11, 2024Distributed machine learning enables parallel training of extensive datasets by delegating computing tasks across multiple workers. Despite the cost reduction benefits of distributed machine learning, the dissemination of final model weights often leads to potential conflicts over model ownership as workers struggle to substantiate their involvement in the training computation. To address the above ownership issues and prevent accidental failures and malicious attacks, verifying the computational integrity and effectiveness of workers becomes particularly crucial in distributed machine learning. In this paper, we proposed a novel binary linear tree commitment-based ownership protection model to ensure computational integrity with limited overhead and concise proof. Due to the frequent updates of parameters during training, our commitment scheme introduces a maintainable tree structure to reduce the costs of updating proofs. Distinguished from SNARK-based verifiable computation, our model achieves efficient proof aggregation by leveraging inner product arguments. Furthermore, proofs of model weights are watermarked by worker identity keys to prevent commitments from being forged or duplicated. The performance analysis and comparison with SNARK-based hash commitments validate the efficacy of our model in preserving computational integrity within distributed machine learning.
Scaling up Trustless DNN Inference with Zero-Knowledge Proofs
Oct 17, 2022
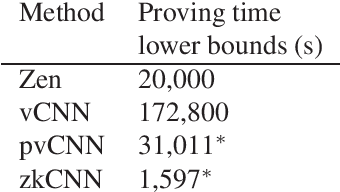


As ML models have increased in capabilities and accuracy, so has the complexity of their deployments. Increasingly, ML model consumers are turning to service providers to serve the ML models in the ML-as-a-service (MLaaS) paradigm. As MLaaS proliferates, a critical requirement emerges: how can model consumers verify that the correct predictions were served, in the face of malicious, lazy, or buggy service providers? In this work, we present the first practical ImageNet-scale method to verify ML model inference non-interactively, i.e., after the inference has been done. To do so, we leverage recent developments in ZK-SNARKs (zero-knowledge succinct non-interactive argument of knowledge), a form of zero-knowledge proofs. ZK-SNARKs allows us to verify ML model execution non-interactively and with only standard cryptographic hardness assumptions. In particular, we provide the first ZK-SNARK proof of valid inference for a full resolution ImageNet model, achieving 79\% top-5 accuracy. We further use these ZK-SNARKs to design protocols to verify ML model execution in a variety of scenarios, including for verifying MLaaS predictions, verifying MLaaS model accuracy, and using ML models for trustless retrieval. Together, our results show that ZK-SNARKs have the promise to make verified ML model inference practical.
Verifiable and Provably Secure Machine Unlearning
Oct 17, 2022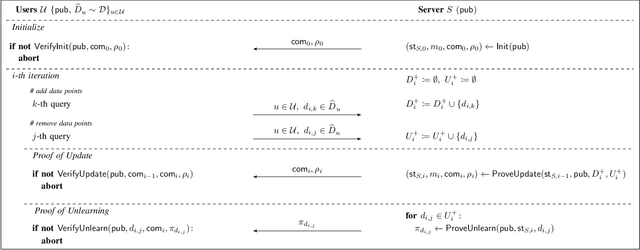



Machine unlearning aims to remove points from the training dataset of a machine learning model after training; for example when a user requests their data to be deleted. While many machine unlearning methods have been proposed, none of them enable users to audit the unlearning procedure and verify that their data was indeed unlearned. To address this, we define the first cryptographic framework to formally capture the security of verifiable machine unlearning. While our framework is generally applicable to different approaches, its advantages are perhaps best illustrated by our instantiation for the canonical approach to unlearning: retraining the model without the data to be unlearned. In our cryptographic protocol, the server first computes a proof that the model was trained on a dataset~$D$. Given a user data point $d$, the server then computes a proof of unlearning that shows that $d \notin D$. We realize our protocol using a SNARK and Merkle trees to obtain proofs of update and unlearning on the data. Based on cryptographic assumptions, we then present a formal game-based proof that our instantiation is secure. Finally, we validate the practicality of our constructions for unlearning in linear regression, logistic regression, and neural networks.