 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch Based Image Retrieval
Papers and Code
O3SLM: Open Weight, Open Data, and Open Vocabulary Sketch-Language Model
Nov 18, 2025While Large Vision Language Models (LVLMs) are increasingly deployed in real-world applications, their ability to interpret abstract visual inputs remains limited. Specifically, they struggle to comprehend hand-drawn sketches, a modality that offers an intuitive means of expressing concepts that are difficult to describe textually. We identify the primary bottleneck as the absence of a large-scale dataset that jointly models sketches, photorealistic images, and corresponding natural language instructions. To address this, we present two key contributions: (1) a new, large-scale dataset of image-sketch-instruction triplets designed to facilitate both pretraining and instruction tuning, and (2) O3SLM, an LVLM trained on this dataset. Comprehensive evaluations on multiple sketch-based tasks: (a) object localization, (b) counting, (c) image retrieval i.e., (SBIR and fine-grained SBIR), and (d) visual question answering (VQA); while incorporating the three existing sketch datasets, namely QuickDraw!, Sketchy, and Tu Berlin, along with our generated SketchVCL dataset, show that O3SLM achieves state-of-the-art performance, substantially outperforming existing LVLMs in sketch comprehension and reasoning.
Sketch Down the FLOPs: Towards Efficient Networks for Human Sketch
May 29, 2025
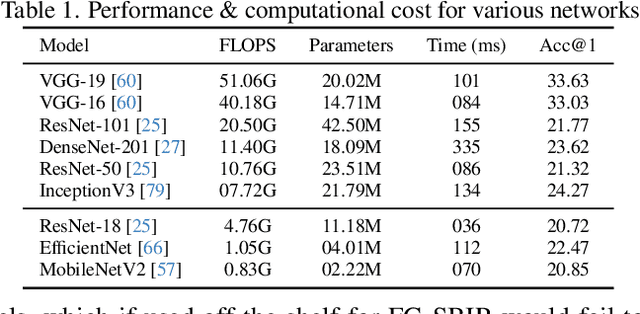
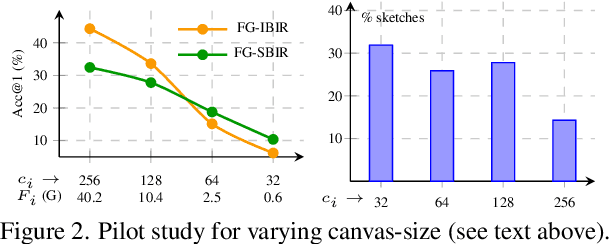

As sketch research has collectively matured over time, its adaptation for at-mass commercialisation emerges on the immediate horizon. Despite an already mature research endeavour for photos, there is no research on the efficient inference specifically designed for sketch data. In this paper, we first demonstrate existing state-of-the-art efficient light-weight models designed for photos do not work on sketches. We then propose two sketch-specific components which work in a plug-n-play manner on any photo efficient network to adapt them to work on sketch data. We specifically chose fine-grained sketch-based image retrieval (FG-SBIR) as a demonstrator as the most recognised sketch problem with immediate commercial value. Technically speaking, we first propose a cross-modal knowledge distillation network to transfer existing photo efficient networks to be compatible with sketch, which brings down number of FLOPs and model parameters by 97.96% percent and 84.89% respectively. We then exploit the abstract trait of sketch to introduce a RL-based canvas selector that dynamically adjusts to the abstraction level which further cuts down number of FLOPs by two thirds. The end result is an overall reduction of 99.37% of FLOPs (from 40.18G to 0.254G) when compared with a full network, while retaining the accuracy (33.03% vs 32.77%) -- finally making an efficient network for the sparse sketch data that exhibit even fewer FLOPs than the best photo counterpart.
Composite Sketch+Text Queries for Retrieving Objects with Elusive Names and Complex Interactions
Feb 12, 2025



Non-native speakers with limited vocabulary often struggle to name specific objects despite being able to visualize them, e.g., people outside Australia searching for numbats. Further, users may want to search for such elusive objects with difficult-to-sketch interactions, e.g., numbat digging in the ground. In such common but complex situations, users desire a search interface that accepts composite multimodal queries comprising hand-drawn sketches of difficult-to-name but easy-to-draw objects and text describing difficult-to-sketch but easy-to-verbalize object attributes or interaction with the scene. This novel problem statement distinctly differs from the previously well-researched TBIR (text-based image retrieval) and SBIR (sketch-based image retrieval) problems. To study this under-explored task, we curate a dataset, CSTBIR (Composite Sketch+Text Based Image Retrieval), consisting of approx. 2M queries and 108K natural scene images. Further, as a solution to this problem, we propose a pretrained multimodal transformer-based baseline, STNET (Sketch+Text Network), that uses a hand-drawn sketch to localize relevant objects in the natural scene image, and encodes the text and image to perform image retrieval. In addition to contrastive learning, we propose multiple training objectives that improve the performance of our model. Extensive experiments show that our proposed method outperforms several state-of-the-art retrieval methods for text-only, sketch-only, and composite query modalities. We make the dataset and code available at our project website.
Freestyle Sketch-in-the-Loop Image Segmentation
Jan 27, 2025In this paper, we expand the domain of sketch research into the field of image segmentation, aiming to establish freehand sketches as a query modality for subjective image segmentation. Our innovative approach introduces a "sketch-in-the-loop" image segmentation framework, enabling the segmentation of visual concepts partially, completely, or in groupings - a truly "freestyle" approach - without the need for a purpose-made dataset (i.e., mask-free). This framework capitalises on the synergy between sketch-based image retrieval (SBIR) models and large-scale pre-trained models (CLIP or DINOv2). The former provides an effective training signal, while fine-tuned versions of the latter execute the subjective segmentation. Additionally, our purpose-made augmentation strategy enhances the versatility of our sketch-guided mask generation, allowing segmentation at multiple granularity levels. Extensive evaluations across diverse benchmark datasets underscore the superior performance of our method in comparison to existing approaches across various evaluation scenarios.
Relation-Aware Meta-Learning for Zero-shot Sketch-Based Image Retrieval
Nov 28, 2024Sketch-based image retrieval (SBIR) relies on free-hand sketches to retrieve natural photos within the same class. However, its practical application is limited by its inability to retrieve classes absent from the training set. To address this limitation, the task has evolved into Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR), where model performance is evaluated on unseen categories. Traditional SBIR primarily focuses on narrowing the domain gap between photo and sketch modalities. However, in the zero-shot setting, the model not only needs to address this cross-modal discrepancy but also requires a strong generalization capability to transfer knowledge to unseen categories. To this end, we propose a novel framework for ZS-SBIR that employs a pair-based relation-aware quadruplet loss to bridge feature gaps. By incorporating two negative samples from different modalities, the approach prevents positive features from becoming disproportionately distant from one modality while remaining close to another, thus enhancing inter-class separability. We also propose a Relation-Aware Meta-Learning Network (RAMLN) to obtain the margin, a hyper-parameter of cross-modal quadruplet loss, to improve the generalization ability of the model. RAMLN leverages external memory to store feature information, which it utilizes to assign optimal margin values. Experimental results obtained on the extended Sketchy and TU-Berlin datasets show a sharp improvement over existing state-of-the-art methods in ZS-SBIR.
Fashion-RAG: Multimodal Fashion Image Editing via Retrieval-Augmented Generation
Apr 18, 2025In recent years, the fashion industry has increasingly adopted AI technologies to enhance customer experience, driven by the proliferation of e-commerce platforms and virtual applications. Among the various tasks, virtual try-on and multimodal fashion image editing -- which utilizes diverse input modalities such as text, garment sketches, and body poses -- have become a key area of research. Diffusion models have emerged as a leading approach for such generative tasks, offering superior image quality and diversity. However, most existing virtual try-on methods rely on having a specific garment input, which is often impractical in real-world scenarios where users may only provide textual specifications. To address this limitation, in this work we introduce Fashion Retrieval-Augmented Generation (Fashion-RAG), a novel method that enables the customization of fashion items based on user preferences provided in textual form. Our approach retrieves multiple garments that match the input specifications and generates a personalized image by incorporating attributes from the retrieved items. To achieve this, we employ textual inversion techniques, where retrieved garment images are projected into the textual embedding space of the Stable Diffusion text encoder, allowing seamless integration of retrieved elements into the generative process. Experimental results on the Dress Code dataset demonstrate that Fashion-RAG outperforms existing methods both qualitatively and quantitatively, effectively capturing fine-grained visual details from retrieved garments. To the best of our knowledge, this is the first work to introduce a retrieval-augmented generation approach specifically tailored for multimodal fashion image editing.
VRsketch2Gaussian: 3D VR Sketch Guided 3D Object Generation with Gaussian Splatting
Mar 16, 2025We propose VRSketch2Gaussian, a first VR sketch-guided, multi-modal, native 3D object generation framework that incorporates a 3D Gaussian Splatting representation. As part of our work, we introduce VRSS, the first large-scale paired dataset containing VR sketches, text, images, and 3DGS, bridging the gap in multi-modal VR sketch-based generation. Our approach features the following key innovations: 1) Sketch-CLIP feature alignment. We propose a two-stage alignment strategy that bridges the domain gap between sparse VR sketch embeddings and rich CLIP embeddings, facilitating both VR sketch-based retrieval and generation tasks. 2) Fine-Grained multi-modal conditioning. We disentangle the 3D generation process by using explicit VR sketches for geometric conditioning and text descriptions for appearance control. To facilitate this, we propose a generalizable VR sketch encoder that effectively aligns different modalities. 3) Efficient and high-fidelity 3D native generation. Our method leverages a 3D-native generation approach that enables fast and texture-rich 3D object synthesis. Experiments conducted on our VRSS dataset demonstrate that our method achieves high-quality, multi-modal VR sketch-based 3D generation. We believe our VRSS dataset and VRsketch2Gaussian method will be beneficial for the 3D generation community.
Freeview Sketching: View-Aware Fine-Grained Sketch-Based Image Retrieval
Jul 01, 2024



In this paper, we delve into the intricate dynamics of Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) by addressing a critical yet overlooked aspect -- the choice of viewpoint during sketch creation. Unlike photo systems that seamlessly handle diverse views through extensive datasets, sketch systems, with limited data collected from fixed perspectives, face challenges. Our pilot study, employing a pre-trained FG-SBIR model, highlights the system's struggle when query-sketches differ in viewpoint from target instances. Interestingly, a questionnaire however shows users desire autonomy, with a significant percentage favouring view-specific retrieval. To reconcile this, we advocate for a view-aware system, seamlessly accommodating both view-agnostic and view-specific tasks. Overcoming dataset limitations, our first contribution leverages multi-view 2D projections of 3D objects, instilling cross-modal view awareness. The second contribution introduces a customisable cross-modal feature through disentanglement, allowing effortless mode switching. Extensive experiments on standard datasets validate the effectiveness of our method.
Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval
Jul 01, 2024In this paper, we study the problem of zero-shot sketch-based image retrieval (ZS-SBIR). The prior methods tackle the problem in a two-modality setting with only category labels or even no textual information involved. However, the growing prevalence of Large-scale pre-trained Language Models (LLMs), which have demonstrated great knowledge learned from web-scale data, can provide us with an opportunity to conclude collective textual information. Our key innovation lies in the usage of text data as auxiliary information for images, thus leveraging the inherent zero-shot generalization ability that language offers. To this end, we propose an approach called Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval. The network consists of three components: (i) a Description Generation Module that generates textual descriptions for each training category by prompting an LLM with several interrogative sentences, (ii) a Feature Extraction Module that includes two ViTs for sketch and image data, a transformer for extracting tokens of sentences of each training category, finally (iii) a Cross-modal Alignment Module that exchanges the token features of both text-sketch and text-image using cross-attention mechanism, and align the tokens locally and globally. Extensive experiments on three benchmark datasets show our superior performances over the state-of-the-art ZS-SBIR methods.
Elevating All Zero-Shot Sketch-Based Image Retrieval Through Multimodal Prompt Learning
Jul 05, 2024



We address the challenges inherent in sketch-based image retrieval (SBIR) across various settings, including zero-shot SBIR, generalized zero-shot SBIR, and fine-grained zero-shot SBIR, by leveraging the vision-language foundation model, CLIP. While recent endeavors have employed CLIP to enhance SBIR, these approaches predominantly follow uni-modal prompt processing and overlook to fully exploit CLIP's integrated visual and textual capabilities. To bridge this gap, we introduce SpLIP, a novel multi-modal prompt learning scheme designed to operate effectively with frozen CLIP backbones. We diverge from existing multi-modal prompting methods that either treat visual and textual prompts independently or integrate them in a limited fashion, leading to suboptimal generalization. SpLIP implements a bi-directional prompt-sharing strategy that enables mutual knowledge exchange between CLIP's visual and textual encoders, fostering a more cohesive and synergistic prompt processing mechanism that significantly reduces the semantic gap between the sketch and photo embeddings. In addition to pioneering multi-modal prompt learning, we propose two innovative strategies for further refining the embedding space. The first is an adaptive margin generation for the sketch-photo triplet loss, regulated by CLIP's class textual embeddings. The second introduces a novel task, termed conditional cross-modal jigsaw, aimed at enhancing fine-grained sketch-photo alignment, by focusing on implicitly modelling the viable patch arrangement of sketches using knowledge of unshuffled photos. Our comprehensive experimental evaluations across multiple benchmarks demonstrate the superior performance of SpLIP in all three SBIR scenarios. Code is available at https://github.com/mainaksingha01/SpLIP.