 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScicap
Papers and Code
Five Years of SciCap: What We Learned and Future Directions for Scientific Figure Captioning
Dec 25, 2025Between 2021 and 2025, the SciCap project grew from a small seed-funded idea at The Pennsylvania State University (Penn State) into one of the central efforts shaping the scientific figure-captioning landscape. Supported by a Penn State seed grant, Adobe, and the Alfred P. Sloan Foundation, what began as our attempt to test whether domain-specific training, which was successful in text models like SciBERT, could also work for figure captions expanded into a multi-institution collaboration. Over these five years, we curated, released, and continually updated a large collection of figure-caption pairs from arXiv papers, conducted extensive automatic and human evaluations on both generated and author-written captions, navigated the rapid rise of large language models (LLMs), launched annual challenges, and built interactive systems that help scientists write better captions. In this piece, we look back at the first five years of SciCap and summarize the key technical and methodological lessons we learned. We then outline five major unsolved challenges and propose directions for the next phase of research in scientific figure captioning.
Leveraging Author-Specific Context for Scientific Figure Caption Generation: 3rd SciCap Challenge
Oct 09, 2025



Scientific figure captions require both accuracy and stylistic consistency to convey visual information. Here, we present a domain-specific caption generation system for the 3rd SciCap Challenge that integrates figure-related textual context with author-specific writing styles using the LaMP-Cap dataset. Our approach uses a two-stage pipeline: Stage 1 combines context filtering, category-specific prompt optimization via DSPy's MIPROv2 and SIMBA, and caption candidate selection; Stage 2 applies few-shot prompting with profile figures for stylistic refinement. Our experiments demonstrate that category-specific prompts outperform both zero-shot and general optimized approaches, improving ROUGE-1 recall by +8.3\% while limiting precision loss to -2.8\% and BLEU-4 reduction to -10.9\%. Profile-informed stylistic refinement yields 40--48\% gains in BLEU scores and 25--27\% in ROUGE. Overall, our system demonstrates that combining contextual understanding with author-specific stylistic adaptation can generate captions that are both scientifically accurate and stylistically faithful to the source paper.
Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Jan 31, 2025



Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?
Proposal Report for the 2nd SciCAP Competition 2024
Jul 02, 2024In this paper, we propose a method for document summarization using auxiliary information. This approach effectively summarizes descriptions related to specific images, tables, and appendices within lengthy texts. Our experiments demonstrate that leveraging high-quality OCR data and initially extracted information from the original text enables efficient summarization of the content related to described objects. Based on these findings, we enhanced popular text generation model models by incorporating additional auxiliary branches to improve summarization performance. Our method achieved top scores of 4.33 and 4.66 in the long caption and short caption tracks, respectively, of the 2024 SciCAP competition, ranking highest in both categories.
DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ
May 28, 2024Creating high-quality scientific figures can be time-consuming and challenging, even though sketching ideas on paper is relatively easy. Furthermore, recreating existing figures that are not stored in formats preserving semantic information is equally complex. To tackle this problem, we introduce DeTikZify, a novel multimodal language model that automatically synthesizes scientific figures as semantics-preserving TikZ graphics programs based on sketches and existing figures. To achieve this, we create three new datasets: DaTikZv2, the largest TikZ dataset to date, containing over 360k human-created TikZ graphics; SketchFig, a dataset that pairs hand-drawn sketches with their corresponding scientific figures; and SciCap++, a collection of diverse scientific figures and associated metadata. We train DeTikZify on SciCap++ and DaTikZv2, along with synthetically generated sketches learned from SketchFig. We also introduce an MCTS-based inference algorithm that enables DeTikZify to iteratively refine its outputs without the need for additional training. Through both automatic and human evaluation, we demonstrate that DeTikZify outperforms commercial Claude 3 and GPT-4V in synthesizing TikZ programs, with the MCTS algorithm effectively boosting its performance. We make our code, models, and datasets publicly available.
GPT-4 as an Effective Zero-Shot Evaluator for Scientific Figure Captions
Oct 23, 2023



There is growing interest in systems that generate captions for scientific figures. However, assessing these systems output poses a significant challenge. Human evaluation requires academic expertise and is costly, while automatic evaluation depends on often low-quality author-written captions. This paper investigates using large language models (LLMs) as a cost-effective, reference-free method for evaluating figure captions. We first constructed SCICAP-EVAL, a human evaluation dataset that contains human judgments for 3,600 scientific figure captions, both original and machine-made, for 600 arXiv figures. We then prompted LLMs like GPT-4 and GPT-3 to score (1-6) each caption based on its potential to aid reader understanding, given relevant context such as figure-mentioning paragraphs. Results show that GPT-4, used as a zero-shot evaluator, outperformed all other models and even surpassed assessments made by Computer Science and Informatics undergraduates, achieving a Kendall correlation score of 0.401 with Ph.D. students rankings
SciCap+: A Knowledge Augmented Dataset to Study the Challenges of Scientific Figure Captioning
Jun 06, 2023



In scholarly documents, figures provide a straightforward way of communicating scientific findings to readers. Automating figure caption generation helps move model understandings of scientific documents beyond text and will help authors write informative captions that facilitate communicating scientific findings. Unlike previous studies, we reframe scientific figure captioning as a knowledge-augmented image captioning task that models need to utilize knowledge embedded across modalities for caption generation. To this end, we extended the large-scale SciCap dataset~\cite{hsu-etal-2021-scicap-generating} to SciCap+ which includes mention-paragraphs (paragraphs mentioning figures) and OCR tokens. Then, we conduct experiments with the M4C-Captioner (a multimodal transformer-based model with a pointer network) as a baseline for our study. Our results indicate that mention-paragraphs serves as additional context knowledge, which significantly boosts the automatic standard image caption evaluation scores compared to the figure-only baselines. Human evaluations further reveal the challenges of generating figure captions that are informative to readers. The code and SciCap+ dataset will be publicly available at https://github.com/ZhishenYang/scientific_figure_captioning_dataset
SciCap: Generating Captions for Scientific Figures
Oct 25, 2021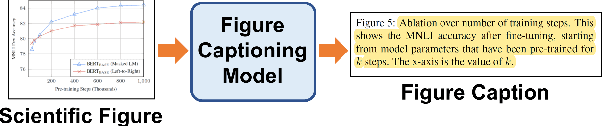
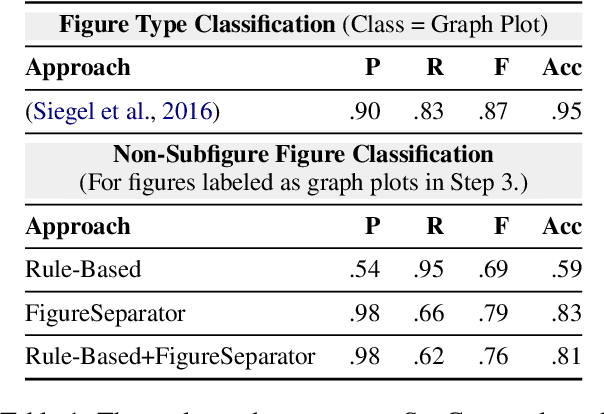
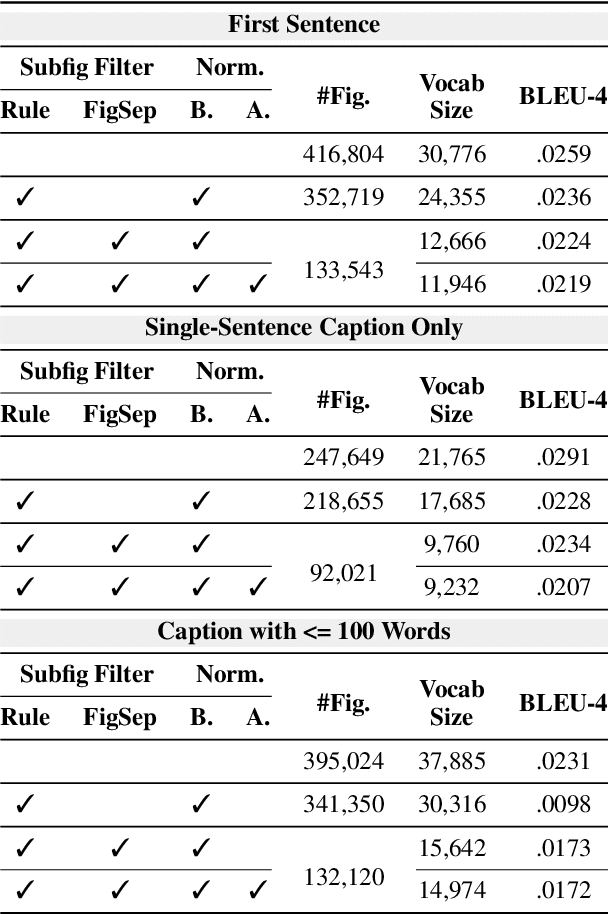
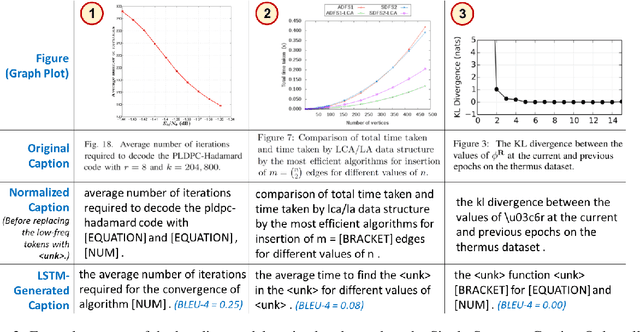
Researchers use figures to communicate rich, complex information in scientific papers. The captions of these figures are critical to conveying effective messages. However, low-quality figure captions commonly occur in scientific articles and may decrease understanding. In this paper, we propose an end-to-end neural framework to automatically generate informative, high-quality captions for scientific figures. To this end, we introduce SCICAP, a large-scale figure-caption dataset based on computer science arXiv papers published between 2010 and 2020. After pre-processing - including figure-type classification, sub-figure identification, text normalization, and caption text selection - SCICAP contained more than two million figures extracted from over 290,000 papers. We then established baseline models that caption graph plots, the dominant (19.2%) figure type. The experimental results showed both opportunities and steep challenges of generating captions for scientific figures.