 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePupil Detection
Papers and Code
Neuromorphic Eye Tracking for Low-Latency Pupil Detection
Dec 10, 2025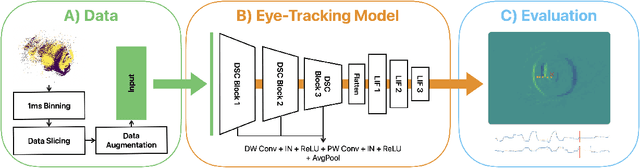
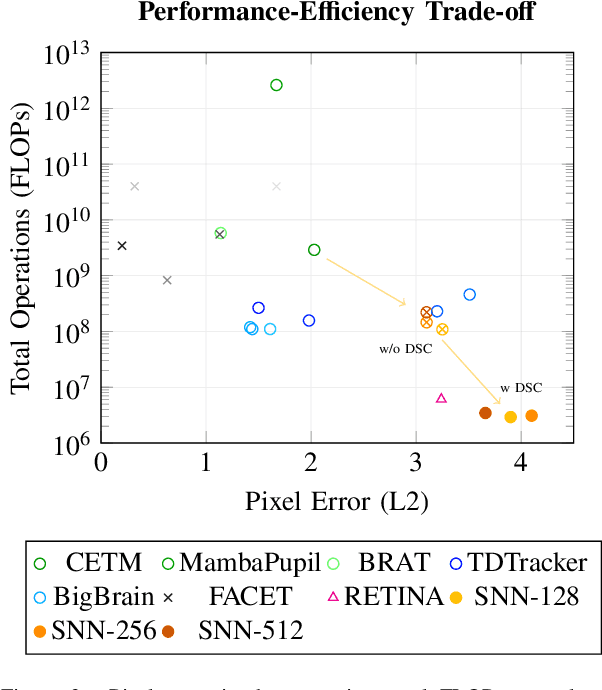
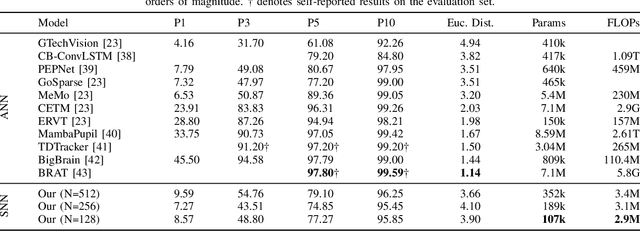
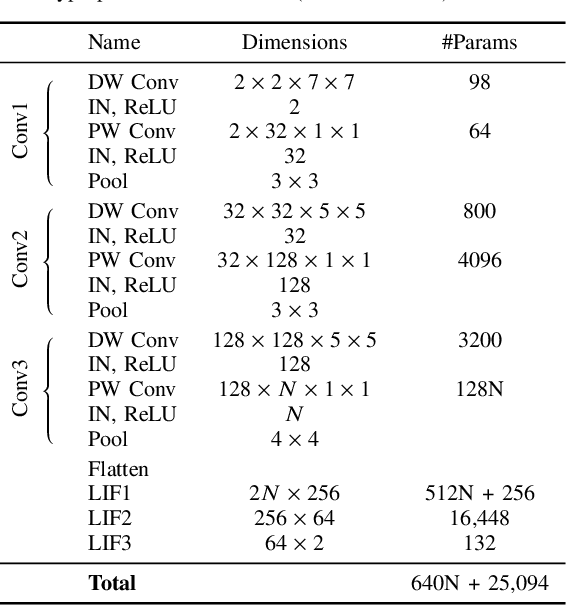
Eye tracking for wearable systems demands low latency and milliwatt-level power, but conventional frame-based pipelines struggle with motion blur, high compute cost, and limited temporal resolution. Such capabilities are vital for enabling seamless and responsive interaction in emerging technologies like augmented reality (AR) and virtual reality (VR), where understanding user gaze is key to immersion and interface design. Neuromorphic sensors and spiking neural networks (SNNs) offer a promising alternative, yet existing SNN approaches are either too specialized or fall short of the performance of modern ANN architectures. This paper presents a neuromorphic version of top-performing event-based eye-tracking models, replacing their recurrent and attention modules with lightweight LIF layers and exploiting depth-wise separable convolutions to reduce model complexity. Our models obtain 3.7-4.1px mean error, approaching the accuracy of the application-specific neuromorphic system, Retina (3.24px), while reducing model size by 20x and theoretical compute by 850x, compared to the closest ANN variant of the proposed model. These efficient variants are projected to operate at an estimated 3.9-4.9 mW with 3 ms latency at 1 kHz. The present results indicate that high-performing event-based eye-tracking architectures can be redesigned as SNNs with substantial efficiency gains, while retaining accuracy suitable for real-time wearable deployment.
EETnet: a CNN for Gaze Detection and Tracking for Smart-Eyewear
Nov 06, 2025



Event-based cameras are becoming a popular solution for efficient, low-power eye tracking. Due to the sparse and asynchronous nature of event data, they require less processing power and offer latencies in the microsecond range. However, many existing solutions are limited to validation on powerful GPUs, with no deployment on real embedded devices. In this paper, we present EETnet, a convolutional neural network designed for eye tracking using purely event-based data, capable of running on microcontrollers with limited resources. Additionally, we outline a methodology to train, evaluate, and quantize the network using a public dataset. Finally, we propose two versions of the architecture: a classification model that detects the pupil on a grid superimposed on the original image, and a regression model that operates at the pixel level.
Gradient-Guided Exploration of Generative Model's Latent Space for Controlled Iris Image Augmentations
Nov 12, 2025Developing reliable iris recognition and presentation attack detection methods requires diverse datasets that capture realistic variations in iris features and a wide spectrum of anomalies. Because of the rich texture of iris images, which spans a wide range of spatial frequencies, synthesizing same-identity iris images while controlling specific attributes remains challenging. In this work, we introduce a new iris image augmentation strategy by traversing a generative model's latent space toward latent codes that represent same-identity samples but with some desired iris image properties manipulated. The latent space traversal is guided by a gradient of specific geometrical, textural, or quality-related iris image features (e.g., sharpness, pupil size, iris size, or pupil-to-iris ratio) and preserves the identity represented by the image being manipulated. The proposed approach can be easily extended to manipulate any attribute for which a differentiable loss term can be formulated. Additionally, our approach can use either randomly generated images using either a pre-train GAN model or real-world iris images. We can utilize GAN inversion to project any given iris image into the latent space and obtain its corresponding latent code.
Building Effective Safety Guardrails in AI Education Tools
Aug 07, 2025There has been rapid development in generative AI tools across the education sector, which in turn is leading to increased adoption by teachers. However, this raises concerns regarding the safety and age-appropriateness of the AI-generated content that is being created for use in classrooms. This paper explores Oak National Academy's approach to addressing these concerns within the development of the UK Government's first publicly available generative AI tool - our AI-powered lesson planning assistant (Aila). Aila is intended to support teachers planning national curriculum-aligned lessons that are appropriate for pupils aged 5-16 years. To mitigate safety risks associated with AI-generated content we have implemented four key safety guardrails - (1) prompt engineering to ensure AI outputs are generated within pedagogically sound and curriculum-aligned parameters, (2) input threat detection to mitigate attacks, (3) an Independent Asynchronous Content Moderation Agent (IACMA) to assess outputs against predefined safety categories, and (4) taking a human-in-the-loop approach, to encourage teachers to review generated content before it is used in the classroom. Through our on-going evaluation of these safety guardrails we have identified several challenges and opportunities to take into account when implementing and testing safety guardrails. This paper highlights ways to build more effective safety guardrails in generative AI education tools including the on-going iteration and refinement of guardrails, as well as enabling cross-sector collaboration through sharing both open-source code, datasets and learnings.
* 9 pages, published in proceedings of International Conference on Artificial Intelligence in Education (AIED) 2025: Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium, Blue Sky, and WideAIED
AI Meets Maritime Training: Precision Analytics for Enhanced Safety and Performance
Jul 02, 2025Traditional simulator-based training for maritime professionals is critical for ensuring safety at sea but often depends on subjective trainer assessments of technical skills, behavioral focus, communication, and body language, posing challenges such as subjectivity, difficulty in measuring key features, and cognitive limitations. Addressing these issues, this study develops an AI-driven framework to enhance maritime training by objectively assessing trainee performance through visual focus tracking, speech recognition, and stress detection, improving readiness for high-risk scenarios. The system integrates AI techniques, including visual focus determination using eye tracking, pupil dilation analysis, and computer vision; communication analysis through a maritime-specific speech-to-text model and natural language processing; communication correctness using large language models; and mental stress detection via vocal pitch. Models were evaluated on data from simulated maritime scenarios with seafarers exposed to controlled high-stress events. The AI algorithms achieved high accuracy, with ~92% for visual detection, ~91% for maritime speech recognition, and ~90% for stress detection, surpassing existing benchmarks. The system provides insights into visual attention, adherence to communication checklists, and stress levels under demanding conditions. This study demonstrates how AI can transform maritime training by delivering objective performance analytics, enabling personalized feedback, and improving preparedness for real-world operational challenges.
Eye Movements as Indicators of Deception: A Machine Learning Approach
May 05, 2025

Gaze may enhance the robustness of lie detectors but remains under-studied. This study evaluated the efficacy of AI models (using fixations, saccades, blinks, and pupil size) for detecting deception in Concealed Information Tests across two datasets. The first, collected with Eyelink 1000, contains gaze data from a computerized experiment where 87 participants revealed, concealed, or faked the value of a previously selected card. The second, collected with Pupil Neon, involved 36 participants performing a similar task but facing an experimenter. XGBoost achieved accuracies up to 74% in a binary classification task (Revealing vs. Concealing) and 49% in a more challenging three-classification task (Revealing vs. Concealing vs. Faking). Feature analysis identified saccade number, duration, amplitude, and maximum pupil size as the most important for deception prediction. These results demonstrate the feasibility of using gaze and AI to enhance lie detectors and encourage future research that may improve on this.
High-frequency near-eye ground truth for event-based eye tracking
Feb 05, 2025



Event-based eye tracking is a promising solution for efficient and low-power eye tracking in smart eyewear technologies. However, the novelty of event-based sensors has resulted in a limited number of available datasets, particularly those with eye-level annotations, crucial for algorithm validation and deep-learning training. This paper addresses this gap by presenting an improved version of a popular event-based eye-tracking dataset. We introduce a semi-automatic annotation pipeline specifically designed for event-based data annotation. Additionally, we provide the scientific community with the computed annotations for pupil detection at 200Hz.
Dual-Modality Computational Ophthalmic Imaging with Deep Learning and Coaxial Optical Design
Apr 13, 2025The growing burden of myopia and retinal diseases necessitates more accessible and efficient eye screening solutions. This study presents a compact, dual-function optical device that integrates fundus photography and refractive error detection into a unified platform. The system features a coaxial optical design using dichroic mirrors to separate wavelength-dependent imaging paths, enabling simultaneous alignment of fundus and refraction modules. A Dense-U-Net-based algorithm with customized loss functions is employed for accurate pupil segmentation, facilitating automated alignment and focusing. Experimental evaluations demonstrate the system's capability to achieve high-precision pupil localization (EDE = 2.8 px, mIoU = 0.931) and reliable refractive estimation with a mean absolute error below 5%. Despite limitations due to commercial lens components, the proposed framework offers a promising solution for rapid, intelligent, and scalable ophthalmic screening, particularly suitable for community health settings.
Modelling Emotions in Face-to-Face Setting: The Interplay of Eye-Tracking, Personality, and Temporal Dynamics
Mar 18, 2025Accurate emotion recognition is pivotal for nuanced and engaging human-computer interactions, yet remains difficult to achieve, especially in dynamic, conversation-like settings. In this study, we showcase how integrating eye-tracking data, temporal dynamics, and personality traits can substantially enhance the detection of both perceived and felt emotions. Seventy-three participants viewed short, speech-containing videos from the CREMA-D dataset, while being recorded for eye-tracking signals (pupil size, fixation patterns), Big Five personality assessments, and self-reported emotional states. Our neural network models combined these diverse inputs including stimulus emotion labels for contextual cues and yielded marked performance gains compared to the state-of-the-art. Specifically, perceived valence predictions reached a macro F1-score of 0.76, and models incorporating personality traits and stimulus information demonstrated significant improvements in felt emotion accuracy. These results highlight the benefit of unifying physiological, individual and contextual factors to address the subjectivity and complexity of emotional expression. Beyond validating the role of user-specific data in capturing subtle internal states, our findings inform the design of future affective computing and human-agent systems, paving the way for more adaptive and cross-individual emotional intelligence in real-world interactions.
Continuous Pupillography: A Case for Visual Health Ecosystem
Oct 16, 2024This article aims to cover pupillography, and its potential use in a number of ophthalmological diagnostic applications in biomedical space. With the ever-increasing incorporation of technology within our daily lives and an ever-growing active research into smart devices and technologies, we try to make a case for a health ecosystem that revolves around continuous eye monitoring. We tend to summarize the design constraints & requirements for an IoT-based continuous pupil detection system, with an attempt at developing a pipeline for wearable pupillographic device, while comparing two compact mini-camera modules currently available in the market. We use a light algorithm that can be directly adopted to current micro-controllers, and share our results for different lighting conditions, and scenarios. Lastly, we present our findings, along with an analysis on the challenges faced and a way ahead towards successfully building this ecosystem.