 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Eye Tracking for Low-Latency Pupil Detection
Dec 10, 2025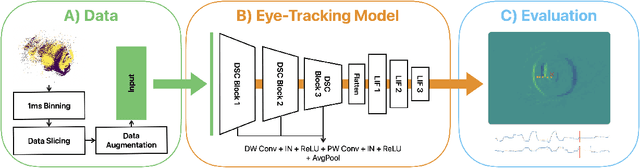
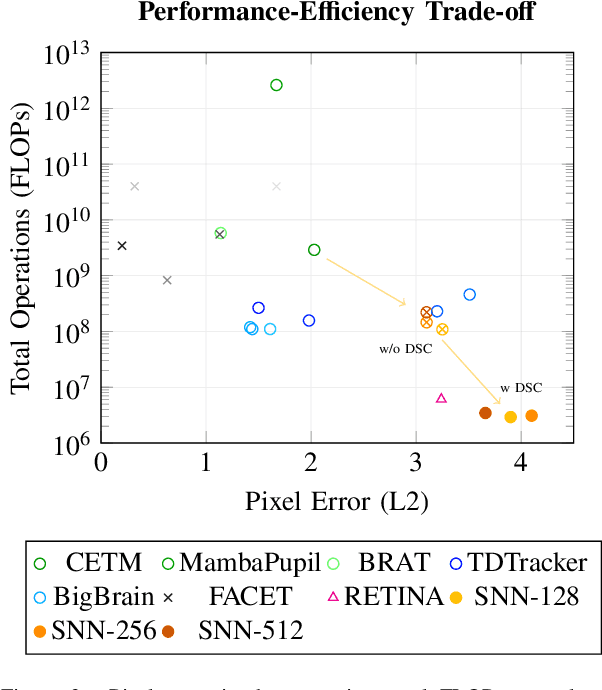
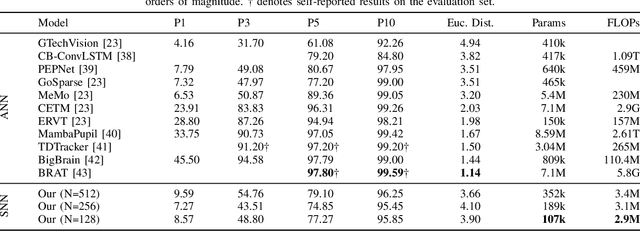
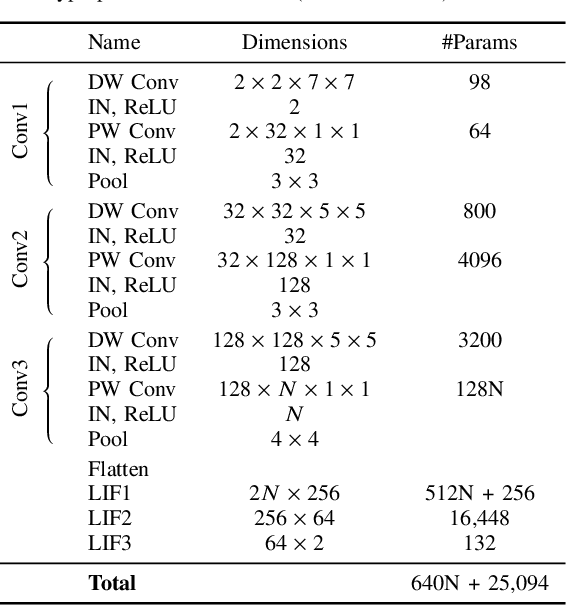
Eye tracking for wearable systems demands low latency and milliwatt-level power, but conventional frame-based pipelines struggle with motion blur, high compute cost, and limited temporal resolution. Such capabilities are vital for enabling seamless and responsive interaction in emerging technologies like augmented reality (AR) and virtual reality (VR), where understanding user gaze is key to immersion and interface design. Neuromorphic sensors and spiking neural networks (SNNs) offer a promising alternative, yet existing SNN approaches are either too specialized or fall short of the performance of modern ANN architectures. This paper presents a neuromorphic version of top-performing event-based eye-tracking models, replacing their recurrent and attention modules with lightweight LIF layers and exploiting depth-wise separable convolutions to reduce model complexity. Our models obtain 3.7-4.1px mean error, approaching the accuracy of the application-specific neuromorphic system, Retina (3.24px), while reducing model size by 20x and theoretical compute by 850x, compared to the closest ANN variant of the proposed model. These efficient variants are projected to operate at an estimated 3.9-4.9 mW with 3 ms latency at 1 kHz. The present results indicate that high-performing event-based eye-tracking architectures can be redesigned as SNNs with substantial efficiency gains, while retaining accuracy suitable for real-time wearable deployment.
Hyperdimensional Decoding of Spiking Neural Networks
Nov 12, 2025This work presents a novel spiking neural network (SNN) decoding method, combining SNNs with Hyperdimensional computing (HDC). The goal is to create a decoding method with high accuracy, high noise robustness, low latency and low energy usage. Compared to analogous architectures decoded with existing approaches, the presented SNN-HDC model attains generally better classification accuracy, lower classification latency and lower estimated energy consumption on multiple test cases from literature. The SNN-HDC achieved estimated energy consumption reductions ranging from 1.24x to 3.67x on the DvsGesture dataset and from 1.38x to 2.27x on the SL-Animals-DVS dataset. The presented decoding method can also efficiently identify unknown classes it has not been trained on. In the DvsGesture dataset the SNN-HDC model can identify 100% of samples from an unseen/untrained class. Given the numerous benefits shown and discussed in this paper, this decoding method represents a very compelling alternative to both rate and latency decoding.