 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiqa Benchmark
Papers and Code
Range Asymmetric Numeral Systems-Based Lightweight Intermediate Feature Compression for Split Computing of Deep Neural Networks
Nov 11, 2025Split computing distributes deep neural network inference between resource-constrained edge devices and cloud servers but faces significant communication bottlenecks when transmitting intermediate features. To this end, in this paper, we propose a novel lightweight compression framework that leverages Range Asymmetric Numeral Systems (rANS) encoding with asymmetric integer quantization and sparse tensor representation to reduce transmission overhead dramatically. Specifically, our approach combines asymmetric integer quantization with a sparse representation technique, eliminating the need for complex probability modeling or network modifications. The key contributions include: (1) a distribution-agnostic compression pipeline that exploits inherent tensor sparsity to achieve bandwidth reduction with minimal computational overhead; (2) an approximate theoretical model that optimizes tensor reshaping dimensions to maximize compression efficiency; and (3) a GPU-accelerated implementation with sub-millisecond encoding/decoding latency. Extensive evaluations across diverse neural architectures (ResNet, VGG16, MobileNetV2, SwinT, DenseNet121, EfficientNetB0) demonstrate that the proposed framework consistently maintains near-baseline accuracy across CIFAR100 and ImageNet benchmarks. Moreover, we validated the framework's effectiveness on advanced natural language processing tasks by employing Llama2 7B and 13B on standard benchmarks such as MMLU, HellaSwag, ARC, PIQA, Winogrande, BoolQ, and OpenBookQA, demonstrating its broad applicability beyond computer vision. Furthermore, this method addresses a fundamental bottleneck in deploying sophisticated artificial intelligence systems in bandwidth-constrained environments without compromising model performance.
Culturally Grounded Physical Commonsense Reasoning in Italian and English: A Submission to the MRL 2025 Shared Task
Oct 26, 2025This paper presents our submission to the MRL 2025 Shared Task on Multilingual Physical Reasoning Datasets. The objective of the shared task is to create manually-annotated evaluation data in the physical commonsense reasoning domain, for languages other than English, following a format similar to PIQA. Our contribution, FormaMentis, is a novel benchmark for physical commonsense reasoning that is grounded in Italian language and culture. The data samples in FormaMentis are created by expert annotators who are native Italian speakers and are familiar with local customs and norms. The samples are additionally translated into English, while preserving the cultural elements unique to the Italian context.
Curriculum-Guided Layer Scaling for Language Model Pretraining
Jun 13, 2025As the cost of pretraining large language models grows, there is continued interest in strategies to improve learning efficiency during this core training stage. Motivated by cognitive development, where humans gradually build knowledge as their brains mature, we propose Curriculum-Guided Layer Scaling (CGLS), a framework for compute-efficient pretraining that synchronizes increasing data difficulty with model growth through progressive layer stacking (i.e. gradually adding layers during training). At the 100M parameter scale, using a curriculum transitioning from synthetic short stories to general web data, CGLS outperforms baseline methods on the question-answering benchmarks PIQA and ARC. Pretraining at the 1.2B scale, we stratify the DataComp-LM corpus with a DistilBERT-based classifier and progress from general text to highly technical or specialized content. Our results show that progressively increasing model depth alongside sample difficulty leads to better generalization and zero-shot performance on various downstream benchmarks. Altogether, our findings demonstrate that CGLS unlocks the potential of progressive stacking, offering a simple yet effective strategy for improving generalization on knowledge-intensive and reasoning tasks.
TODO: Enhancing LLM Alignment with Ternary Preferences
Nov 02, 2024



Aligning large language models (LLMs) with human intent is critical for enhancing their performance across a variety of tasks. Standard alignment techniques, such as Direct Preference Optimization (DPO), often rely on the binary Bradley-Terry (BT) model, which can struggle to capture the complexities of human preferences -- particularly in the presence of noisy or inconsistent labels and frequent ties. To address these limitations, we introduce the Tie-rank Oriented Bradley-Terry model (TOBT), an extension of the BT model that explicitly incorporates ties, enabling more nuanced preference representation. Building on this, we propose Tie-rank Oriented Direct Preference Optimization (TODO), a novel alignment algorithm that leverages TOBT's ternary ranking system to improve preference alignment. In evaluations on Mistral-7B and Llama 3-8B models, TODO consistently outperforms DPO in modeling preferences across both in-distribution and out-of-distribution datasets. Additional assessments using MT Bench and benchmarks such as Piqa, ARC-c, and MMLU further demonstrate TODO's superior alignment performance. Notably, TODO also shows strong results in binary preference alignment, highlighting its versatility and potential for broader integration into LLM alignment. The implementation details can be found in https://github.com/XXares/TODO.
eDKM: An Efficient and Accurate Train-time Weight Clustering for Large Language Models
Sep 13, 2023Since Large Language Models or LLMs have demonstrated high-quality performance on many complex language tasks, there is a great interest in bringing these LLMs to mobile devices for faster responses and better privacy protection. However, the size of LLMs (i.e., billions of parameters) requires highly effective compression to fit into storage-limited devices. Among many compression techniques, weight-clustering, a form of non-linear quantization, is one of the leading candidates for LLM compression, and supported by modern smartphones. Yet, its training overhead is prohibitively significant for LLM fine-tuning. Especially, Differentiable KMeans Clustering, or DKM, has shown the state-of-the-art trade-off between compression ratio and accuracy regression, but its large memory complexity makes it nearly impossible to apply to train-time LLM compression. In this paper, we propose a memory-efficient DKM implementation, eDKM powered by novel techniques to reduce the memory footprint of DKM by orders of magnitudes. For a given tensor to be saved on CPU for the backward pass of DKM, we compressed the tensor by applying uniquification and sharding after checking if there is no duplicated tensor previously copied to CPU. Our experimental results demonstrate that \prjname can fine-tune and compress a pretrained LLaMA 7B model from 12.6 GB to 2.5 GB (3bit/weight) with the Alpaca dataset by reducing the train-time memory footprint of a decoder layer by 130$\times$, while delivering good accuracy on broader LLM benchmarks (i.e., 77.7% for PIQA, 66.1% for Winograde, and so on).
Who's Harry Potter? Approximate Unlearning in LLMs
Oct 04, 2023



Large language models (LLMs) are trained on massive internet corpora that often contain copyrighted content. This poses legal and ethical challenges for the developers and users of these models, as well as the original authors and publishers. In this paper, we propose a novel technique for unlearning a subset of the training data from a LLM, without having to retrain it from scratch. We evaluate our technique on the task of unlearning the Harry Potter books from the Llama2-7b model (a generative language model recently open-sourced by Meta). While the model took over 184K GPU-hours to pretrain, we show that in about 1 GPU hour of finetuning, we effectively erase the model's ability to generate or recall Harry Potter-related content, while its performance on common benchmarks (such as Winogrande, Hellaswag, arc, boolq and piqa) remains almost unaffected. We make our fine-tuned model publicly available on HuggingFace for community evaluation. To the best of our knowledge, this is the first paper to present an effective technique for unlearning in generative language models. Our technique consists of three main components: First, we use a reinforced model that is further trained on the target data to identify the tokens that are most related to the unlearning target, by comparing its logits with those of a baseline model. Second, we replace idiosyncratic expressions in the target data with generic counterparts, and leverage the model's own predictions to generate alternative labels for every token. These labels aim to approximate the next-token predictions of a model that has not been trained on the target data. Third, we finetune the model on these alternative labels, which effectively erases the original text from the model's memory whenever it is prompted with its context.
UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark
Mar 24, 2021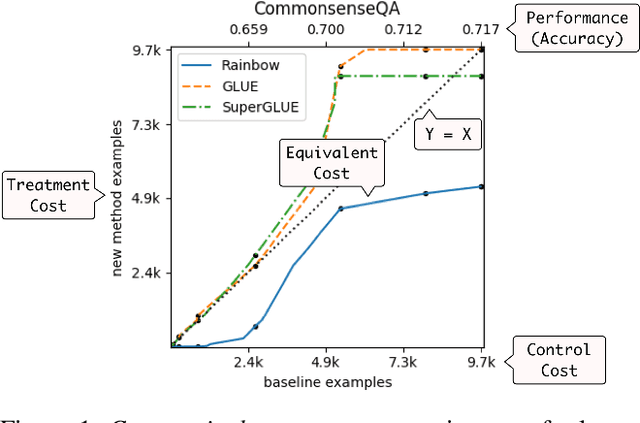


Commonsense AI has long been seen as a near impossible goal -- until recently. Now, research interest has sharply increased with an influx of new benchmarks and models. We propose two new ways to evaluate commonsense models, emphasizing their generality on new tasks and building on diverse, recently introduced benchmarks. First, we propose a new multitask benchmark, RAINBOW, to promote research on commonsense models that generalize well over multiple tasks and datasets. Second, we propose a novel evaluation, the cost equivalent curve, that sheds new insight on how the choice of source datasets, pretrained language models, and transfer learning methods impacts performance and data efficiency. We perform extensive experiments -- over 200 experiments encompassing 4800 models -- and report multiple valuable and sometimes surprising findings, e.g., that transfer almost always leads to better or equivalent performance if following a particular recipe, that QA-based commonsense datasets transfer well with each other, while commonsense knowledge graphs do not, and that perhaps counter-intuitively, larger models benefit more from transfer than smaller ones. Last but not least, we introduce a new universal commonsense reasoning model, UNICORN, that establishes new state-of-the-art performance across 8 popular commonsense benchmarks, aNLI (87.3%), CosmosQA (91.8%), HellaSWAG (93.9%), PIQA (90.1%), SocialIQa (83.2%), WinoGrande (86.6%), CycIC (94.0%) and CommonsenseQA (79.3%).
PIQA: Reasoning about Physical Commonsense in Natural Language
Nov 26, 2019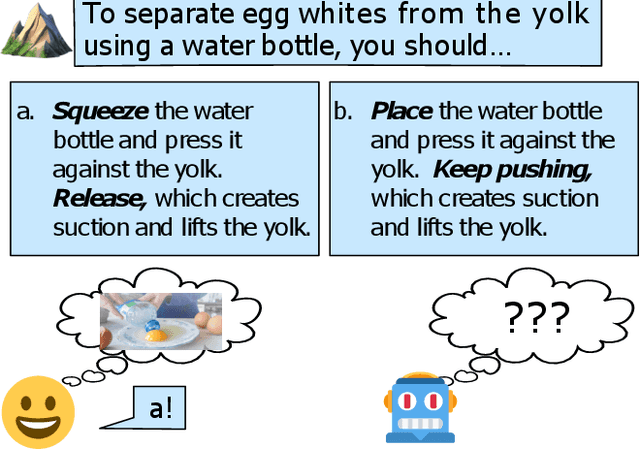
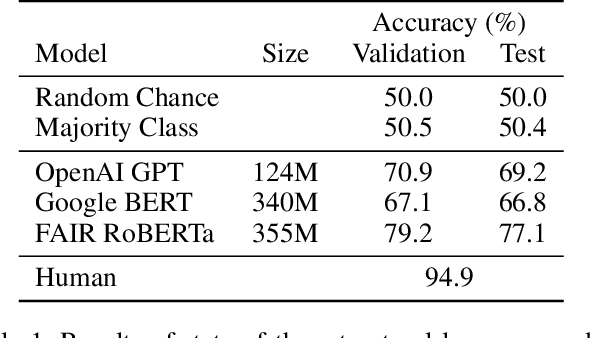
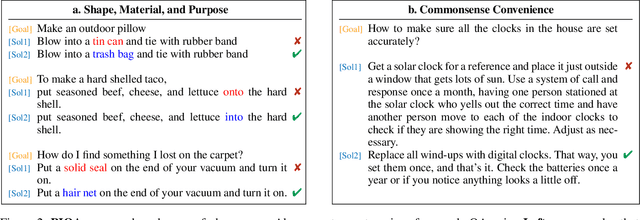
To apply eyeshadow without a brush, should I use a cotton swab or a toothpick? Questions requiring this kind of physical commonsense pose a challenge to today's natural language understanding systems. While recent pretrained models (such as BERT) have made progress on question answering over more abstract domains - such as news articles and encyclopedia entries, where text is plentiful - in more physical domains, text is inherently limited due to reporting bias. Can AI systems learn to reliably answer physical common-sense questions without experiencing the physical world? In this paper, we introduce the task of physical commonsense reasoning and a corresponding benchmark dataset Physical Interaction: Question Answering or PIQA. Though humans find the dataset easy (95% accuracy), large pretrained models struggle (77%). We provide analysis about the dimensions of knowledge that existing models lack, which offers significant opportunities for future research.
EfficientQA : a RoBERTa Based Phrase-Indexed Question-Answering System
Jan 30, 2021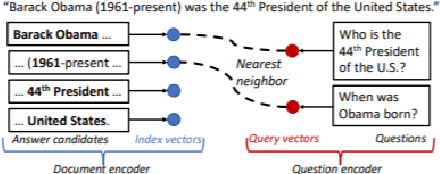
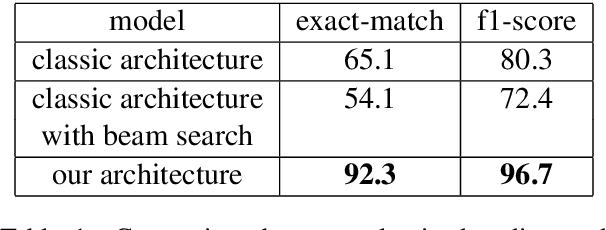
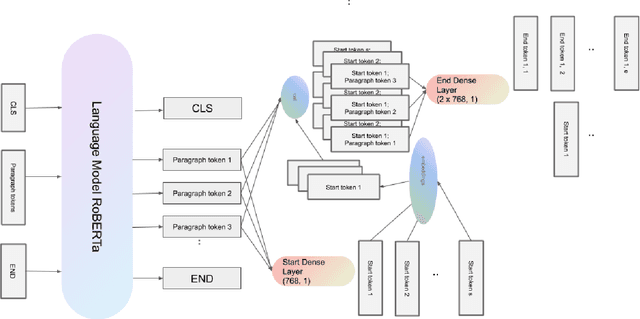
State-of-the-art extractive question answering models achieve superhuman performances on the SQuAD benchmark. Yet, they are unreasonably heavy and need expensive GPU computing to answer questions in a reasonable time. Thus, they cannot be used for real-world queries on hundreds of thousands of documents in the open-domain question answering paradigm. In this paper, we explore the possibility to transfer the natural language understanding of language models into dense vectors representing questions and answer candidates, in order to make the task of question-answering compatible with a simple nearest neighbor search task. This new model, that we call EfficientQA, takes advantage from the pair of sequences kind of input of BERT-based models to build meaningful dense representations of candidate answers. These latter are extracted from the context in a question-agnostic fashion. Our model achieves state-of-the-art results in Phrase-Indexed Question Answering (PIQA) beating the previous state-of-art by 1.3 points in exact-match and 1.4 points in f1-score. These results show that dense vectors are able to embed very rich semantic representations of sequences, although these ones were built from language models not originally trained for the use-case. Thus, in order to build more resource efficient NLP systems in the future, training language models that are better adapted to build dense representations of phrases is one of the possibilities.