 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Handwritten Chinese Character
Papers and Code
Rotation-free Online Handwritten Character Recognition Using Linear Recurrent Units
Feb 02, 2026Online handwritten character recognition leverages stroke order and dynamic features, which generally provide higher accuracy and robustness compared with offline recognition. However, in practical applications, rotational deformations can disrupt the spatial layout of strokes, substantially reducing recognition accuracy. Extracting rotation-invariant features therefore remains a challenging open problem. In this work, we employ the Sliding Window Path Signature (SW-PS) to capture local structural features of characters, and introduce the lightweight Linear Recurrent Units (LRU) as the classifier. The LRU combine the fast incremental processing capability of recurrent neural networks (RNN) with the efficient parallel training of state space models (SSM), while reliably modelling dynamic stroke characteristics. We conducted recognition experiments with random rotation angle up to $\pm 180^{\circ}$ on three subsets of the CASIA-OLHWDB1.1 dataset: digits, English upper letters, and Chinese radicals. The accuracies achieved after ensemble learning were $99.62\%$, $96.67\%$, and $94.33\%$, respectively. Experimental results demonstrate that the proposed SW-PS+LRU framework consistently surpasses competing models in both convergence speed and test accuracy.
Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach
Jul 29, 2022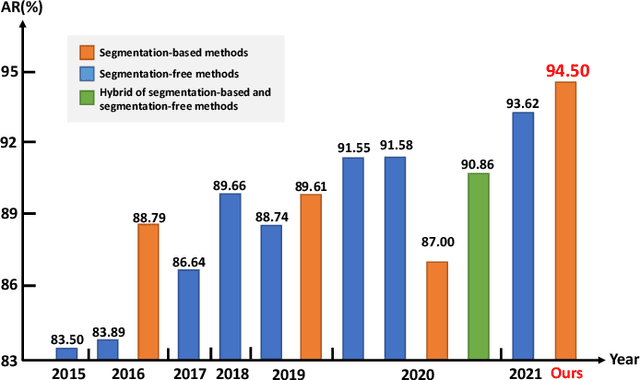
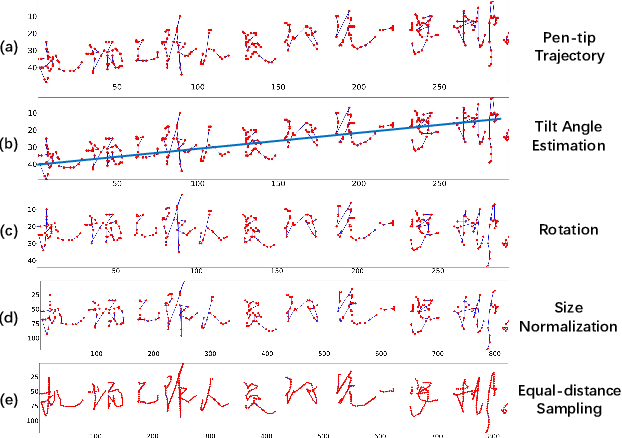


Online and offline handwritten Chinese text recognition (HTCR) has been studied for decades. Early methods adopted oversegmentation-based strategies but suffered from low speed, insufficient accuracy, and high cost of character segmentation annotations. Recently, segmentation-free methods based on connectionist temporal classification (CTC) and attention mechanism, have dominated the field of HCTR. However, people actually read text character by character, especially for ideograms such as Chinese. This raises the question: are segmentation-free strategies really the best solution to HCTR? To explore this issue, we propose a new segmentation-based method for recognizing handwritten Chinese text that is implemented using a simple yet efficient fully convolutional network. A novel weakly supervised learning method is proposed to enable the network to be trained using only transcript annotations; thus, the expensive character segmentation annotations required by previous segmentation-based methods can be avoided. Owing to the lack of context modeling in fully convolutional networks, we propose a contextual regularization method to integrate contextual information into the network during the training stage, which can further improve the recognition performance. Extensive experiments conducted on four widely used benchmarks, namely CASIA-HWDB, CASIA-OLHWDB, ICDAR2013, and SCUT-HCCDoc, show that our method significantly surpasses existing methods on both online and offline HCTR, and exhibits a considerably higher inference speed than CTC/attention-based approaches.
Two Decades of Bengali Handwritten Digit Recognition: A Survey
Jun 05, 2022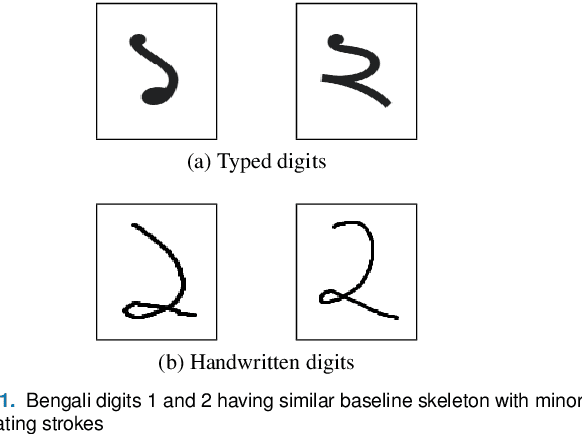
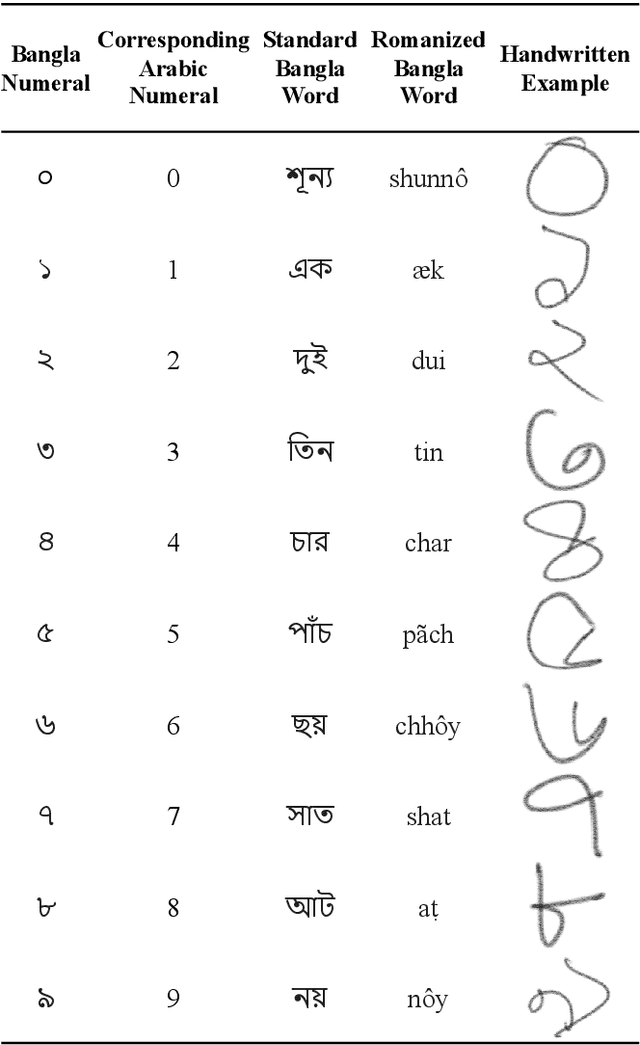
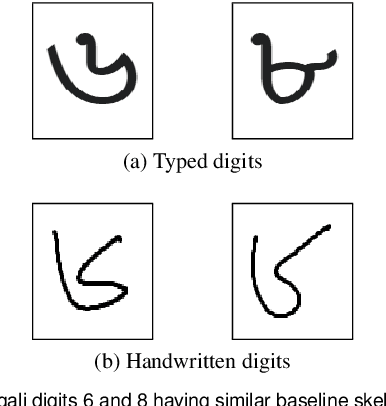

Handwritten Digit Recognition (HDR) is one of the most challenging tasks in the domain of Optical Character Recognition (OCR). Irrespective of language, there are some inherent challenges of HDR, which mostly arise due to the variations in writing styles across individuals, writing medium and environment, inability to maintain the same strokes while writing any digit repeatedly, etc. In addition to that, the structural complexities of the digits of a particular language may lead to ambiguous scenarios of HDR. Over the years, researchers have developed numerous offline and online HDR pipelines, where different image processing techniques are combined with traditional Machine Learning (ML)-based and/or Deep Learning (DL)-based architectures. Although evidence of extensive review studies on HDR exists in the literature for languages, such as: English, Arabic, Indian, Farsi, Chinese, etc., few surveys on Bengali HDR (BHDR) can be found, which lack a comprehensive analysis of the challenges, the underlying recognition process, and possible future directions. In this paper, the characteristics and inherent ambiguities of Bengali handwritten digits along with a comprehensive insight of two decades of the state-of-the-art datasets and approaches towards offline BHDR have been analyzed. Furthermore, several real-life application-specific studies, which involve BHDR, have also been discussed in detail. This paper will also serve as a compendium for researchers interested in the science behind offline BHDR, instigating the exploration of newer avenues of relevant research that may further lead to better offline recognition of Bengali handwritten digits in different application areas.
Template-Instance Loss for Offline Handwritten Chinese Character Recognition
Oct 12, 2019
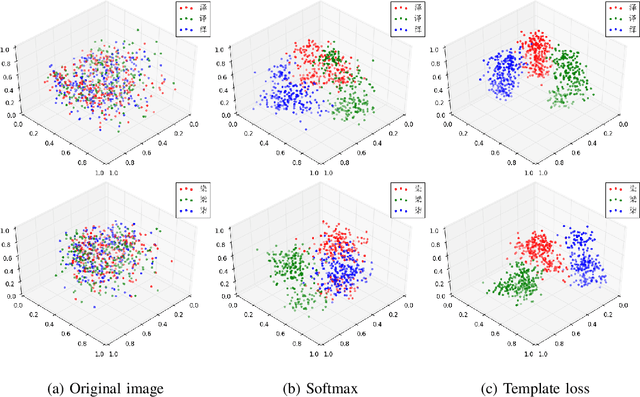


The long-standing challenges for offline handwritten Chinese character recognition (HCCR) are twofold: Chinese characters can be very diverse and complicated while similarly looking, and cursive handwriting (due to increased writing speed and infrequent pen lifting) makes strokes and even characters connected together in a flowing manner. In this paper, we propose the template and instance loss functions for the relevant machine learning tasks in offline handwritten Chinese character recognition. First, the character template is designed to deal with the intrinsic similarities among Chinese characters. Second, the instance loss can reduce category variance according to classification difficulty, giving a large penalty to the outlier instance of handwritten Chinese character. Trained with the new loss functions using our deep network architecture HCCR14Layer model consisting of simple layers, our extensive experiments show that it yields state-of-the-art performance and beyond for offline HCCR.
A High-Performance CNN Method for Offline Handwritten Chinese Character Recognition and Visualization
Dec 30, 2018



Recent researches introduced fast, compact and efficient convolutional neural networks (CNNs) for offline handwritten Chinese character recognition (HCCR). However, many of them did not address the problem of the network interpretability. We propose a new architecture of a deep CNN with a high recognition performance which is capable of learning deep features for visualization. A special characteristic of our model is the bottleneck layers which enable us to retain its expressiveness while reducing the number of multiply-accumulate operations and the required storage. We introduce a modification of global weighted average pooling (GWAP) - global weighted output average pooling (GWOAP). This paper demonstrates how they allow us to calculate class activation maps (CAMs) in order to indicate the most relevant input character image regions used by our CNN to identify a certain class. Evaluating on the ICDAR-2013 offline HCCR competition dataset, we show that our model enables a relative 0.83% error reduction having 49% fewer parameters and the same computational cost compared to the current state-of-the-art single-network method trained only on handwritten data. Our solution outperforms even recent residual learning approaches.
Deep Template Matching for Offline Handwritten Chinese Character Recognition
Nov 15, 2018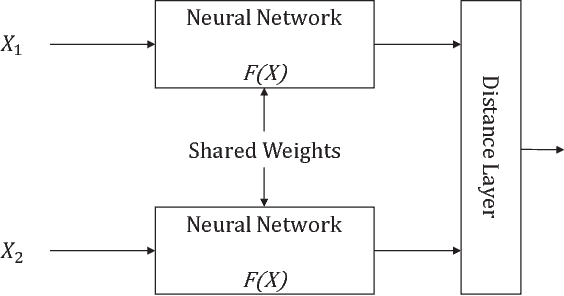

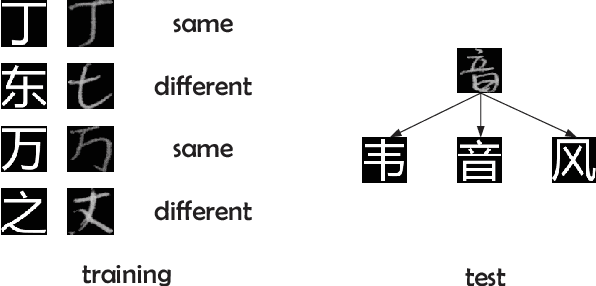

Just like its remarkable achievements in many computer vision tasks, the convolutional neural networks (CNN) provide an end-to-end solution in handwritten Chinese character recognition (HCCR) with great success. However, the process of learning discriminative features for image recognition is difficult in cases where little data is available. In this paper, we propose a novel method for learning siamese neural network which employ a special structure to predict the similarity between handwritten Chinese characters and template images. The optimization of siamese neural network can be treated as a simple binary classification problem. When the training process has been finished, the powerful discriminative features help us to generalize the predictive power not just to new data, but to entirely new classes that never appear in the training set. Experiments performed on the ICDAR-2013 offline HCCR datasets have shown that the proposed method has a very promising generalization ability to the new classes that never appear in the training set.
Offline Handwritten Chinese Text Recognition with Convolutional Neural Networks
Jun 28, 2020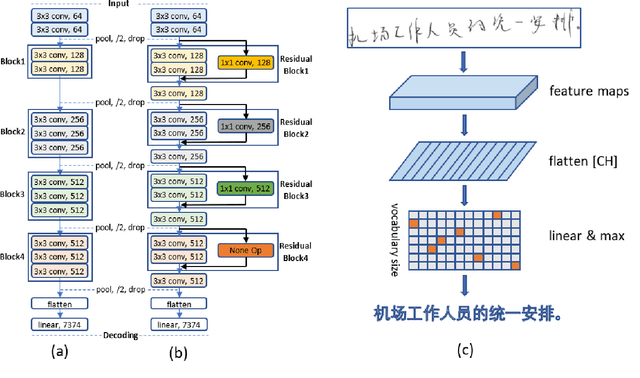
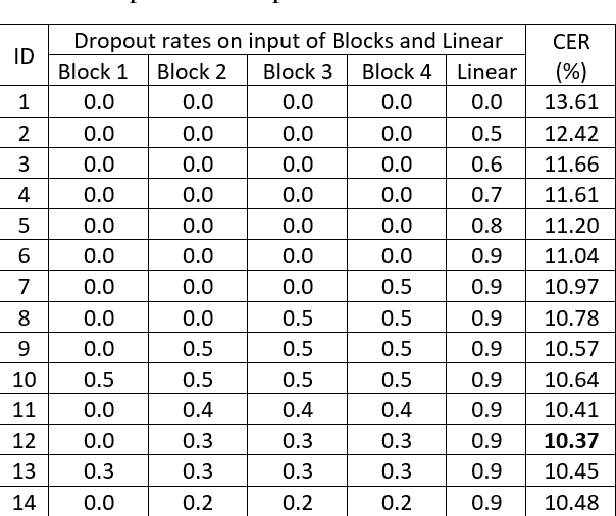
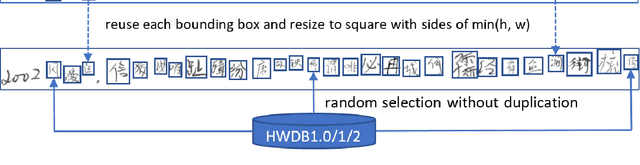
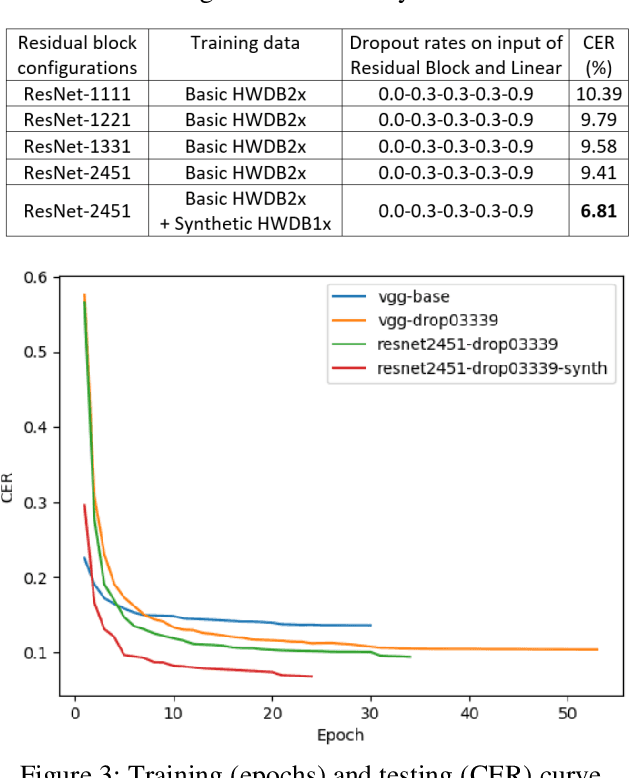
Deep learning based methods have been dominating the text recognition tasks in different and multilingual scenarios. The offline handwritten Chinese text recognition (HCTR) is one of the most challenging tasks because it involves thousands of characters, variant writing styles and complex data collection process. Recently, the recurrent-free architectures for text recognition appears to be competitive as its highly parallelism and comparable results. In this paper, we build the models using only the convolutional neural networks and use CTC as the loss function. To reduce the overfitting, we apply dropout after each max-pooling layer and with extreme high rate on the last one before the linear layer. The CASIA-HWDB database is selected to tune and evaluate the proposed models. With the existing text samples as templates, we randomly choose isolated character samples to synthesis more text samples for training. We finally achieve 6.81% character error rate (CER) on the ICDAR 2013 competition set, which is the best published result without language model correction.
DenseRAN for Offline Handwritten Chinese Character Recognition
Aug 13, 2018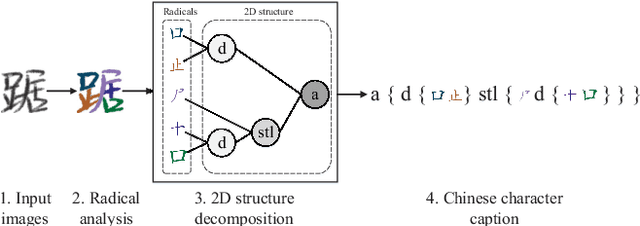
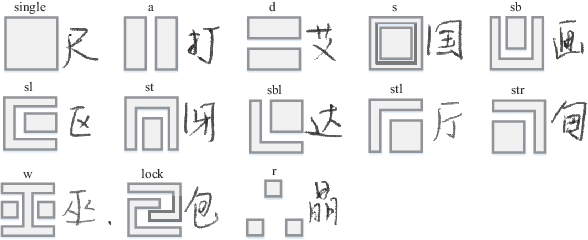
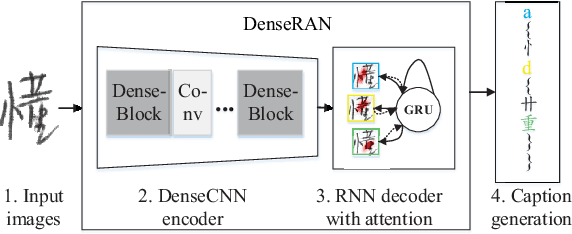
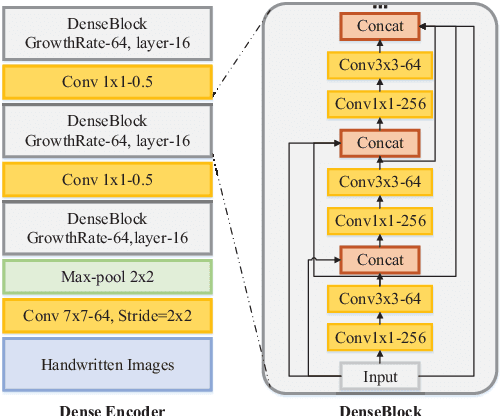
Recently, great success has been achieved in offline handwritten Chinese character recognition by using deep learning methods. Chinese characters are mainly logographic and consist of basic radicals, however, previous research mostly treated each Chinese character as a whole without explicitly considering its internal two-dimensional structure and radicals. In this study, we propose a novel radical analysis network with densely connected architecture (DenseRAN) to analyze Chinese character radicals and its two-dimensional structures simultaneously. DenseRAN first encodes input image to high-level visual features by employing DenseNet as an encoder. Then a decoder based on recurrent neural networks is employed, aiming at generating captions of Chinese characters by detecting radicals and two-dimensional structures through attention mechanism. The manner of treating a Chinese character as a composition of two-dimensional structures and radicals can reduce the size of vocabulary and enable DenseRAN to possess the capability of recognizing unseen Chinese character classes, only if the corresponding radicals have been seen in training set. Evaluated on ICDAR-2013 competition database, the proposed approach significantly outperforms whole-character modeling approach with a relative character error rate (CER) reduction of 18.54%. Meanwhile, for the case of recognizing 3277 unseen Chinese characters in CASIA-HWDB1.2 database, DenseRAN can achieve a character accuracy of about 41% while the traditional whole-character method has no capability to handle them.
Building Efficient CNN Architecture for Offline Handwritten Chinese Character Recognition
Apr 08, 2018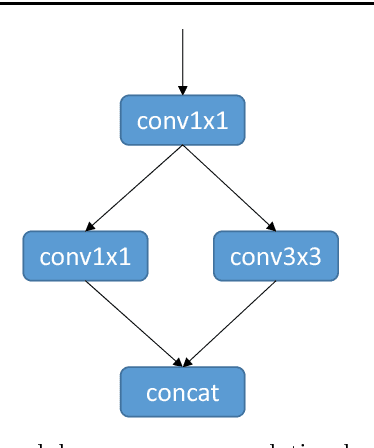
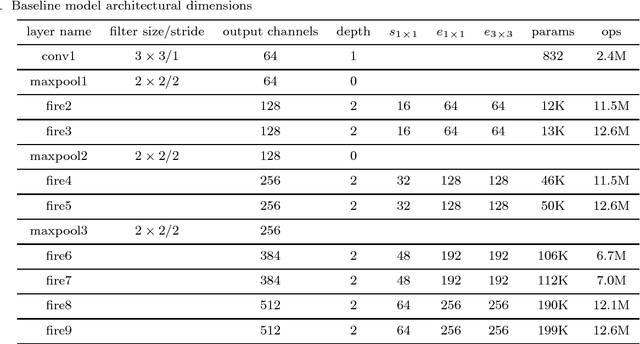
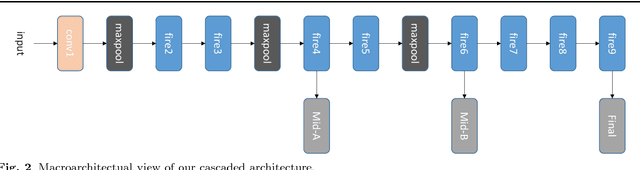
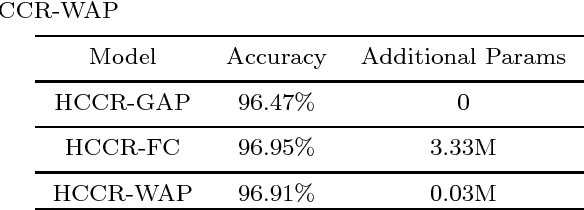
Deep convolutional networks based methods have brought great breakthrough in images classification, which provides an end-to-end solution for handwritten Chinese character recognition(HCCR) problem through learning discriminative features automatically. Nevertheless, state-of-the-art CNNs appear to incur huge computation cost, and require the storage of a large number of parameters especially in fully connected layers, which is difficult to deploy such networks into alternative hardware device with the limit of computation amount. To solve the storage problem, we propose a novel technique called Global Weighted Arverage Pooling for reducing the parameters in fully connected layer without loss in accuracy. Besides, we implement a cascaded model in single CNN by adding mid output layer to complete recognition as early as possible, which reduces average inference time significantly. Experiments were performed on the ICDAR-2013 offline HCCR dataset, and it is found that the proposed approach only needs 6.9ms for classfying a chracter image on average, and achieves the state-of-the-art accuracy of 97.1% while requiring only 3.3MB for storage.
Building Fast and Compact Convolutional Neural Networks for Offline Handwritten Chinese Character Recognition
Feb 26, 2017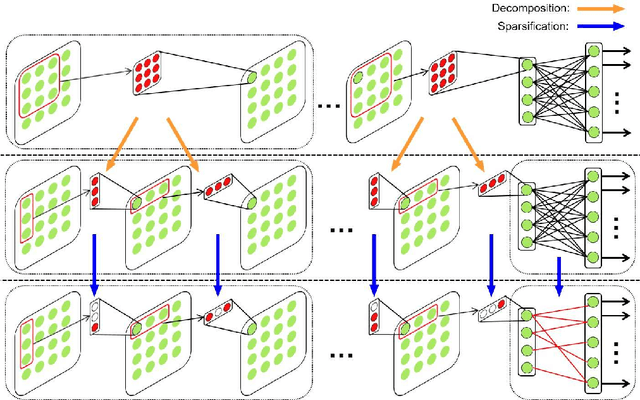


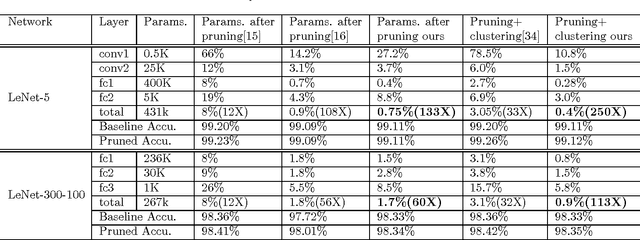
Like other problems in computer vision, offline handwritten Chinese character recognition (HCCR) has achieved impressive results using convolutional neural network (CNN)-based methods. However, larger and deeper networks are needed to deliver state-of-the-art results in this domain. Such networks intuitively appear to incur high computational cost, and require the storage of a large number of parameters, which renders them unfeasible for deployment in portable devices. To solve this problem, we propose a Global Supervised Low-rank Expansion (GSLRE) method and an Adaptive Drop-weight (ADW) technique to solve the problems of speed and storage capacity. We design a nine-layer CNN for HCCR consisting of 3,755 classes, and devise an algorithm that can reduce the networks computational cost by nine times and compress the network to 1/18 of the original size of the baseline model, with only a 0.21% drop in accuracy. In tests, the proposed algorithm surpassed the best single-network performance reported thus far in the literature while requiring only 2.3 MB for storage. Furthermore, when integrated with our effective forward implementation, the recognition of an offline character image took only 9.7 ms on a CPU. Compared with the state-of-the-art CNN model for HCCR, our approach is approximately 30 times faster, yet 10 times more cost efficient.