 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNt Xent
Papers and Code
Contrastive and Multi-Task Learning on Noisy Brain Signals with Nonlinear Dynamical Signatures
Jan 13, 2026We introduce a two-stage multitask learning framework for analyzing Electroencephalography (EEG) signals that integrates denoising, dynamical modeling, and representation learning. In the first stage, a denoising autoencoder is trained to suppress artifacts and stabilize temporal dynamics, providing robust signal representations. In the second stage, a multitask architecture processes these denoised signals to achieve three objectives: motor imagery classification, chaotic versus non-chaotic regime discrimination using Lyapunov exponent-based labels, and self-supervised contrastive representation learning with NT-Xent loss. A convolutional backbone combined with a Transformer encoder captures spatial-temporal structure, while the dynamical task encourages sensitivity to nonlinear brain dynamics. This staged design mitigates interference between reconstruction and discriminative goals, improves stability across datasets, and supports reproducible training by clearly separating noise reduction from higher-level feature learning. Empirical studies show that our framework not only enhances robustness and generalization but also surpasses strong baselines and recent state-of-the-art methods in EEG decoding, highlighting the effectiveness of combining denoising, dynamical features, and self-supervised learning.
MS-ConTab: Multi-Scale Contrastive Learning of Mutation Signatures for Pan Cancer Representation and Stratification
Aug 26, 2025Motivation. Understanding the pan-cancer mutational landscape offers critical insights into the molecular mechanisms underlying tumorigenesis. While patient-level machine learning techniques have been widely employed to identify tumor subtypes, cohort-level clustering, where entire cancer types are grouped based on shared molecular features, has largely relied on classical statistical methods. Results. In this study, we introduce a novel unsupervised contrastive learning framework to cluster 43 cancer types based on coding mutation data derived from the COSMIC database. For each cancer type, we construct two complementary mutation signatures: a gene-level profile capturing nucleotide substitution patterns across the most frequently mutated genes, and a chromosome-level profile representing normalized substitution frequencies across chromosomes. These dual views are encoded using TabNet encoders and optimized via a multi-scale contrastive learning objective (NT-Xent loss) to learn unified cancer-type embeddings. We demonstrate that the resulting latent representations yield biologically meaningful clusters of cancer types, aligning with known mutational processes and tissue origins. Our work represents the first application of contrastive learning to cohort-level cancer clustering, offering a scalable and interpretable framework for mutation-driven cancer subtyping.
Improving Query-by-Vocal Imitation with Contrastive Learning and Audio Pretraining
Aug 21, 2024



Query-by-Vocal Imitation (QBV) is about searching audio files within databases using vocal imitations created by the user's voice. Since most humans can effectively communicate sound concepts through voice, QBV offers the more intuitive and convenient approach compared to text-based search. To fully leverage QBV, developing robust audio feature representations for both the vocal imitation and the original sound is crucial. In this paper, we present a new system for QBV that utilizes the feature extraction capabilities of Convolutional Neural Networks pre-trained with large-scale general-purpose audio datasets. We integrate these pre-trained models into a dual encoder architecture and fine-tune them end-to-end using contrastive learning. A distinctive aspect of our proposed method is the fine-tuning strategy of pre-trained models using an adapted NT-Xent loss for contrastive learning, creating a shared embedding space for reference recordings and vocal imitations. The proposed system significantly enhances audio retrieval performance, establishing a new state of the art on both coarse- and fine-grained QBV tasks.
Additive Margin in Contrastive Self-Supervised Frameworks to Learn Discriminative Speaker Representations
Apr 23, 2024Self-Supervised Learning (SSL) frameworks became the standard for learning robust class representations by benefiting from large unlabeled datasets. For Speaker Verification (SV), most SSL systems rely on contrastive-based loss functions. We explore different ways to improve the performance of these techniques by revisiting the NT-Xent contrastive loss. Our main contribution is the definition of the NT-Xent-AM loss and the study of the importance of Additive Margin (AM) in SimCLR and MoCo SSL methods to further separate positive from negative pairs. Despite class collisions, we show that AM enhances the compactness of same-speaker embeddings and reduces the number of false negatives and false positives on SV. Additionally, we demonstrate the effectiveness of the symmetric contrastive loss, which provides more supervision for the SSL task. Implementing these two modifications to SimCLR improves performance and results in 7.85% EER on VoxCeleb1-O, outperforming other equivalent methods.
Self-supervised Pre-training of Text Recognizers
May 01, 2024



In this paper, we investigate self-supervised pre-training methods for document text recognition. Nowadays, large unlabeled datasets can be collected for many research tasks, including text recognition, but it is costly to annotate them. Therefore, methods utilizing unlabeled data are researched. We study self-supervised pre-training methods based on masked label prediction using three different approaches -- Feature Quantization, VQ-VAE, and Post-Quantized AE. We also investigate joint-embedding approaches with VICReg and NT-Xent objectives, for which we propose an image shifting technique to prevent model collapse where it relies solely on positional encoding while completely ignoring the input image. We perform our experiments on historical handwritten (Bentham) and historical printed datasets mainly to investigate the benefits of the self-supervised pre-training techniques with different amounts of annotated target domain data. We use transfer learning as strong baselines. The evaluation shows that the self-supervised pre-training on data from the target domain is very effective, but it struggles to outperform transfer learning from closely related domains. This paper is one of the first researches exploring self-supervised pre-training in document text recognition, and we believe that it will become a cornerstone for future research in this area. We made our implementation of the investigated methods publicly available at https://github.com/DCGM/pero-pretraining.
Token-Level Contrastive Learning with Modality-Aware Prompting for Multimodal Intent Recognition
Dec 22, 2023



Multimodal intent recognition aims to leverage diverse modalities such as expressions, body movements and tone of speech to comprehend user's intent, constituting a critical task for understanding human language and behavior in real-world multimodal scenarios. Nevertheless, the majority of existing methods ignore potential correlations among different modalities and own limitations in effectively learning semantic features from nonverbal modalities. In this paper, we introduce a token-level contrastive learning method with modality-aware prompting (TCL-MAP) to address the above challenges. To establish an optimal multimodal semantic environment for text modality, we develop a modality-aware prompting module (MAP), which effectively aligns and fuses features from text, video and audio modalities with similarity-based modality alignment and cross-modality attention mechanism. Based on the modality-aware prompt and ground truth labels, the proposed token-level contrastive learning framework (TCL) constructs augmented samples and employs NT-Xent loss on the label token. Specifically, TCL capitalizes on the optimal textual semantic insights derived from intent labels to guide the learning processes of other modalities in return. Extensive experiments show that our method achieves remarkable improvements compared to state-of-the-art methods. Additionally, ablation analyses demonstrate the superiority of the modality-aware prompt over the handcrafted prompt, which holds substantial significance for multimodal prompt learning. The codes are released at https://github.com/thuiar/TCL-MAP.
A Simplified Framework for Contrastive Learning for Node Representations
May 01, 2023Contrastive learning has recently established itself as a powerful self-supervised learning framework for extracting rich and versatile data representations. Broadly speaking, contrastive learning relies on a data augmentation scheme to generate two versions of the input data and learns low-dimensional representations by maximizing a normalized temperature-scaled cross entropy loss (NT-Xent) to identify augmented samples corresponding to the same original entity. In this paper, we investigate the potential of deploying contrastive learning in combination with Graph Neural Networks for embedding nodes in a graph. Specifically, we show that the quality of the resulting embeddings and training time can be significantly improved by a simple column-wise postprocessing of the embedding matrix, instead of the row-wise postprocessing via multilayer perceptrons (MLPs) that is adopted by the majority of peer methods. This modification yields improvements in downstream classification tasks of up to 1.5% and even beats existing state-of-the-art approaches on 6 out of 8 different benchmarks. We justify our choices of postprocessing by revisiting the "alignment vs. uniformity paradigm", and show that column-wise post-processing improves both "alignment" and "uniformity" of the embeddings.
The NT-Xent loss upper bound
May 06, 2022Self-supervised learning is a growing paradigm in deep representation learning, showing great generalization capabilities and competitive performance in low-labeled data regimes. The SimCLR framework proposes the NT-Xent loss for contrastive representation learning. The objective of the loss function is to maximize agreement, similarity, between sampled positive pairs. This short paper derives and proposes an upper bound for the loss and average similarity. An analysis of the implications is however not provided, but we strongly encourage anyone in the field to conduct this.
TypoSwype: An Imaging Approach to Detect Typo-Squatting
Sep 02, 2022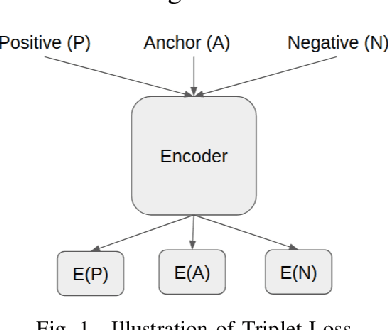
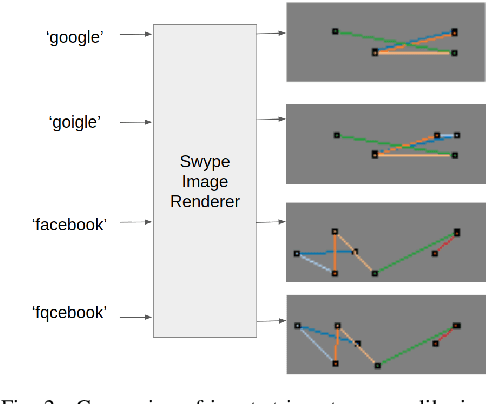
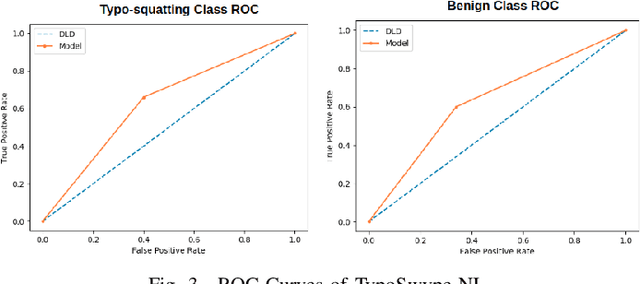

Typo-squatting domains are a common cyber-attack technique. It involves utilising domain names, that exploit possible typographical errors of commonly visited domains, to carry out malicious activities such as phishing, malware installation, etc. Current approaches typically revolve around string comparison algorithms like the Demaru-Levenschtein Distance (DLD) algorithm. Such techniques do not take into account keyboard distance, which researchers find to have a strong correlation with typical typographical errors and are trying to take account of. In this paper, we present the TypoSwype framework which converts strings to images that take into account keyboard location innately. We also show how modern state of the art image recognition techniques involving Convolutional Neural Networks, trained via either Triplet Loss or NT-Xent Loss, can be applied to learn a mapping to a lower dimensional space where distances correspond to image, and equivalently, textual similarity. Finally, we also demonstrate our method's ability to improve typo-squatting detection over the widely used DLD algorithm, while maintaining the classification accuracy as to which domain the input domain was attempting to typo-squat.
Mutual Contrastive Learning to Disentangle Whole Slide Image Representations for Glioma Grading
Mar 08, 2022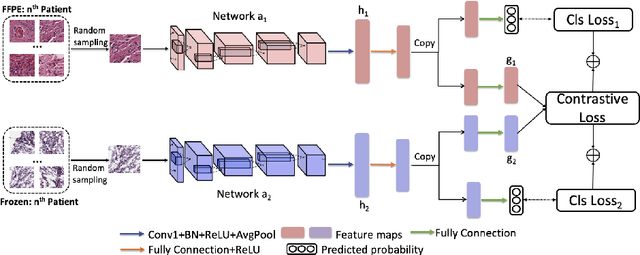
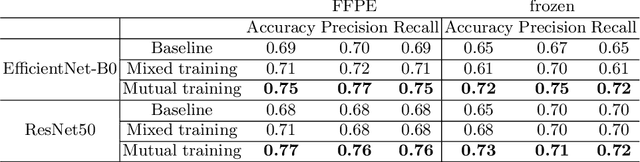

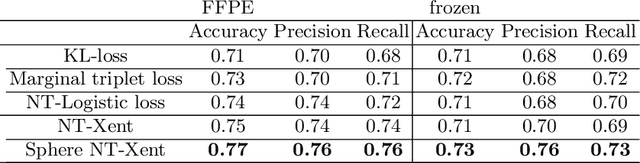
Whole slide images (WSI) provide valuable phenotypic information for histological assessment and malignancy grading of tumors. The WSI-based computational pathology promises to provide rapid diagnostic support and facilitate digital health. The most commonly used WSI are derived from formalin-fixed paraffin-embedded (FFPE) and frozen sections. Currently, the majority of automatic tumor grading models are developed based on FFPE sections, which could be affected by the artifacts introduced by tissue processing. Here we propose a mutual contrastive learning scheme to integrate FFPE and frozen sections and disentangle cross-modality representations for glioma grading. We first design a mutual learning scheme to jointly optimize the model training based on FFPE and frozen sections. Further, we develop a multi-modality domain alignment mechanism to ensure semantic consistency in the backbone model training. We finally design a sphere normalized temperature-scaled cross-entropy loss (NT-Xent), which could promote cross-modality representation disentangling of FFPE and frozen sections. Our experiments show that the proposed scheme achieves better performance than the model trained based on each single modality or mixed modalities. The sphere NT-Xent loss outperforms other typical metrics loss functions.