 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinigrid
Papers and Code
Latent Perspective-Taking via a Schrödinger Bridge in Influence-Augmented Local Models
Feb 02, 2026Operating in environments alongside humans requires robots to make decisions under uncertainty. In addition to exogenous dynamics, they must reason over others' hidden mental-models and mental-states. While Interactive POMDPs and Bayesian Theory of Mind formulations are principled, exact nested-belief inference is intractable, and hand-specified models are brittle in open-world settings. We address both by learning structured mental-models and an estimator of others' mental-states. Building on the Influence-Based Abstraction, we instantiate an Influence-Augmented Local Model to decompose socially-aware robot tasks into local dynamics, social influences, and exogenous factors. We propose (a) a neuro-symbolic world model instantiating a factored, discrete Dynamic Bayesian Network, and (b) a perspective-shift operator modeled as an amortized Schrödinger Bridge over the learned local dynamics that transports factored egocentric beliefs into other-centric beliefs. We show that this architecture enables agents to synthesize socially-aware policies in model-based reinforcement learning, via decision-time mental-state planning (a Schrödinger Bridge in belief space), with preliminary results in a MiniGrid social navigation task.
Unsupervised Learning of Efficient Exploration: Pre-training Adaptive Policies via Self-Imposed Goals
Jan 27, 2026Unsupervised pre-training can equip reinforcement learning agents with prior knowledge and accelerate learning in downstream tasks. A promising direction, grounded in human development, investigates agents that learn by setting and pursuing their own goals. The core challenge lies in how to effectively generate, select, and learn from such goals. Our focus is on broad distributions of downstream tasks where solving every task zero-shot is infeasible. Such settings naturally arise when the target tasks lie outside of the pre-training distribution or when their identities are unknown to the agent. In this work, we (i) optimize for efficient multi-episode exploration and adaptation within a meta-learning framework, and (ii) guide the training curriculum with evolving estimates of the agent's post-adaptation performance. We present ULEE, an unsupervised meta-learning method that combines an in-context learner with an adversarial goal-generation strategy that maintains training at the frontier of the agent's capabilities. On XLand-MiniGrid benchmarks, ULEE pre-training yields improved exploration and adaptation abilities that generalize to novel objectives, environment dynamics, and map structures. The resulting policy attains improved zero-shot and few-shot performance, and provides a strong initialization for longer fine-tuning processes. It outperforms learning from scratch, DIAYN pre-training, and alternative curricula.
Deep Intrinsic Surprise-Regularized Control (DISRC): A Biologically Inspired Mechanism for Efficient Deep Q-Learning in Sparse Environments
Jan 24, 2026Deep reinforcement learning (DRL) has driven major advances in autonomous control. Still, standard Deep Q-Network (DQN) agents tend to rely on fixed learning rates and uniform update scaling, even as updates are modulated by temporal-difference (TD) error. This rigidity destabilizes convergence, especially in sparse-reward settings where feedback is infrequent. We introduce Deep Intrinsic Surprise-Regularized Control (DISRC), a biologically inspired augmentation to DQN that dynamically scales Q-updates based on latent-space surprise. DISRC encodes states via a LayerNorm-based encoder and computes a deviation-based surprise score relative to a moving latent setpoint. Each update is then scaled in proportion to both TD error and surprise intensity, promoting plasticity during early exploration and stability as familiarity increases. We evaluate DISRC on two sparse-reward MiniGrid environments, which included MiniGrid-DoorKey-8x8 and MiniGrid-LavaCrossingS9N1, under identical settings as a vanilla DQN baseline. In DoorKey, DISRC reached the first successful episode (reward > 0.8) 33% faster than the vanilla DQN baseline (79 vs. 118 episodes), with lower reward standard deviation (0.25 vs. 0.34) and higher reward area under the curve (AUC: 596.42 vs. 534.90). These metrics reflect faster, more consistent learning - critical for sparse, delayed reward settings. In LavaCrossing, DISRC achieved a higher final reward (0.95 vs. 0.93) and the highest AUC of all agents (957.04), though it converged more gradually. These preliminary results establish DISRC as a novel mechanism for regulating learning intensity in off-policy agents, improving both efficiency and stability in sparse-reward domains. By treating surprise as an intrinsic learning signal, DISRC enables agents to modulate updates based on expectation violations, enhancing decision quality when conventional value-based methods fall short.
Beyond Fixed Tasks: Unsupervised Environment Design for Task-Level Pairs
Nov 16, 2025Training general agents to follow complex instructions (tasks) in intricate environments (levels) remains a core challenge in reinforcement learning. Random sampling of task-level pairs often produces unsolvable combinations, highlighting the need to co-design tasks and levels. While unsupervised environment design (UED) has proven effective at automatically designing level curricula, prior work has only considered a fixed task. We present ATLAS (Aligning Tasks and Levels for Autocurricula of Specifications), a novel method that generates joint autocurricula over tasks and levels. Our approach builds upon UED to automatically produce solvable yet challenging task-level pairs for policy training. To evaluate ATLAS and drive progress in the field, we introduce an evaluation suite that models tasks as reward machines in Minigrid levels. Experiments demonstrate that ATLAS vastly outperforms random sampling approaches, particularly when sampling solvable pairs is unlikely. We further show that mutations leveraging the structure of both tasks and levels accelerate convergence to performant policies.
Adaptive Context Length Optimization with Low-Frequency Truncation for Multi-Agent Reinforcement Learning
Oct 30, 2025



Recently, deep multi-agent reinforcement learning (MARL) has demonstrated promising performance for solving challenging tasks, such as long-term dependencies and non-Markovian environments. Its success is partly attributed to conditioning policies on large fixed context length. However, such large fixed context lengths may lead to limited exploration efficiency and redundant information. In this paper, we propose a novel MARL framework to obtain adaptive and effective contextual information. Specifically, we design a central agent that dynamically optimizes context length via temporal gradient analysis, enhancing exploration to facilitate convergence to global optima in MARL. Furthermore, to enhance the adaptive optimization capability of the context length, we present an efficient input representation for the central agent, which effectively filters redundant information. By leveraging a Fourier-based low-frequency truncation method, we extract global temporal trends across decentralized agents, providing an effective and efficient representation of the MARL environment. Extensive experiments demonstrate that the proposed method achieves state-of-the-art (SOTA) performance on long-term dependency tasks, including PettingZoo, MiniGrid, Google Research Football (GRF), and StarCraft Multi-Agent Challenge v2 (SMACv2).
Code-Driven Planning in Grid Worlds with Large Language Models
May 15, 2025We propose an iterative programmatic planning (IPP) framework for solving grid-based tasks by synthesizing interpretable agent policies expressed in code using large language models (LLMs). Instead of relying on traditional search or reinforcement learning, our approach uses code generation as policy synthesis, where the LLM outputs executable programs that map environment states to action sequences. Our proposed architecture incorporates several prompting strategies, including direct code generation, pseudocode-conditioned refinement, and curriculum-based prompting, but also includes an iterative refinement mechanism that updates code based on task performance feedback. We evaluate our approach using six leading LLMs and two challenging grid-based benchmarks (GRASP and MiniGrid). Our IPP framework demonstrates improvements over direct code generation ranging from 10\% to as much as 10x across five of the six models and establishes a new state-of-the-art result for GRASP. IPP is found to significantly outperform direct elicitation of a solution from GPT-o3-mini (by 63\% on MiniGrid to 116\% on GRASP), demonstrating the viability of the overall approach. Computational costs of all code generation approaches are similar. While code generation has a higher initial prompting cost compared to direct solution elicitation (\$0.08 per task vs. \$0.002 per instance for GPT-o3-mini), the code can be reused for any number of instances, making the amortized cost significantly lower (by 400x on GPT-o3-mini across the complete GRASP benchmark).
DYSTIL: Dynamic Strategy Induction with Large Language Models for Reinforcement Learning
May 06, 2025



Reinforcement learning from expert demonstrations has long remained a challenging research problem, and existing state-of-the-art methods using behavioral cloning plus further RL training often suffer from poor generalization, low sample efficiency, and poor model interpretability. Inspired by the strong reasoning abilities of large language models (LLMs), we propose a novel strategy-based reinforcement learning framework integrated with LLMs called DYnamic STrategy Induction with Llms for reinforcement learning (DYSTIL) to overcome these limitations. DYSTIL dynamically queries a strategy-generating LLM to induce textual strategies based on advantage estimations and expert demonstrations, and gradually internalizes induced strategies into the RL agent through policy optimization to improve its performance through boosting policy generalization and enhancing sample efficiency. It also provides a direct textual channel to observe and interpret the evolution of the policy's underlying strategies during training. We test DYSTIL over challenging RL environments from Minigrid and BabyAI, and empirically demonstrate that DYSTIL significantly outperforms state-of-the-art baseline methods by 17.75% in average success rate while also enjoying higher sample efficiency during the learning process.
D3HRL: A Distributed Hierarchical Reinforcement Learning Approach Based on Causal Discovery and Spurious Correlation Detection
May 04, 2025



Current Hierarchical Reinforcement Learning (HRL) algorithms excel in long-horizon sequential decision-making tasks but still face two challenges: delay effects and spurious correlations. To address them, we propose a causal HRL approach called D3HRL. First, D3HRL models delayed effects as causal relationships across different time spans and employs distributed causal discovery to learn these relationships. Second, it employs conditional independence testing to eliminate spurious correlations. Finally, D3HRL constructs and trains hierarchical policies based on the identified true causal relationships. These three steps are iteratively executed, gradually exploring the complete causal chain of the task. Experiments conducted in 2D-MineCraft and MiniGrid show that D3HRL demonstrates superior sensitivity to delay effects and accurately identifies causal relationships, leading to reliable decision-making in complex environments.
LLM-Guided Probabilistic Program Induction for POMDP Model Estimation
May 04, 2025



Partially Observable Markov Decision Processes (POMDPs) model decision making under uncertainty. While there are many approaches to approximately solving POMDPs, we aim to address the problem of learning such models. In particular, we are interested in a subclass of POMDPs wherein the components of the model, including the observation function, reward function, transition function, and initial state distribution function, can be modeled as low-complexity probabilistic graphical models in the form of a short probabilistic program. Our strategy to learn these programs uses an LLM as a prior, generating candidate probabilistic programs that are then tested against the empirical distribution and adjusted through feedback. We experiment on a number of classical toy POMDP problems, simulated MiniGrid domains, and two real mobile-base robotics search domains involving partial observability. Our results show that using an LLM to guide in the construction of a low-complexity POMDP model can be more effective than tabular POMDP learning, behavior cloning, or direct LLM planning.
World Model Agents with Change-Based Intrinsic Motivation
Mar 26, 2025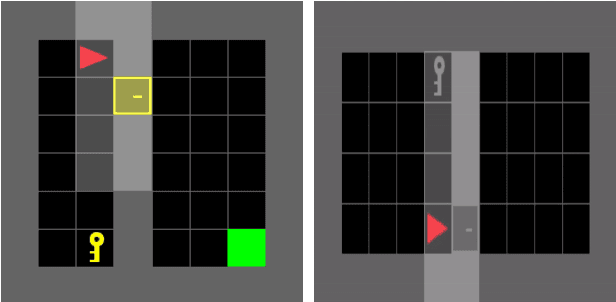
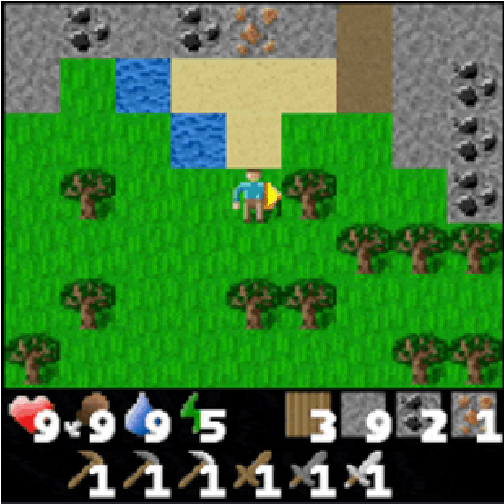
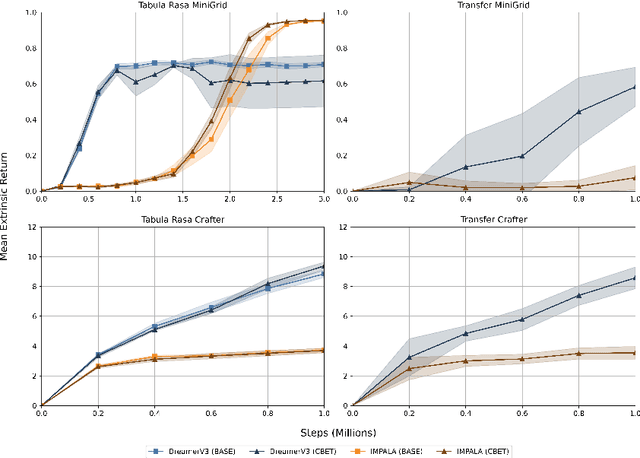
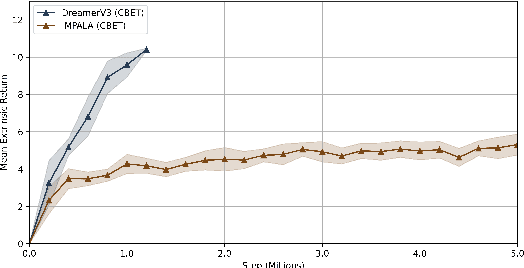
Sparse reward environments pose a significant challenge for reinforcement learning due to the scarcity of feedback. Intrinsic motivation and transfer learning have emerged as promising strategies to address this issue. Change Based Exploration Transfer (CBET), a technique that combines these two approaches for model-free algorithms, has shown potential in addressing sparse feedback but its effectiveness with modern algorithms remains understudied. This paper provides an adaptation of CBET for world model algorithms like DreamerV3 and compares the performance of DreamerV3 and IMPALA agents, both with and without CBET, in the sparse reward environments of Crafter and Minigrid. Our tabula rasa results highlight the possibility of CBET improving DreamerV3's returns in Crafter but the algorithm attains a suboptimal policy in Minigrid with CBET further reducing returns. In the same vein, our transfer learning experiments show that pre-training DreamerV3 with intrinsic rewards does not immediately lead to a policy that maximizes extrinsic rewards in Minigrid. Overall, our results suggest that CBET provides a positive impact on DreamerV3 in more complex environments like Crafter but may be detrimental in environments like Minigrid. In the latter case, the behaviours promoted by CBET in DreamerV3 may not align with the task objectives of the environment, leading to reduced returns and suboptimal policies.