 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJft 300m
Papers and Code
Investigating the Impact of Large-Scale Pre-training on Nutritional Content Estimation from 2D Images
Aug 06, 2025



Estimating the nutritional content of food from images is a critical task with significant implications for health and dietary monitoring. This is challenging, especially when relying solely on 2D images, due to the variability in food presentation, lighting, and the inherent difficulty in inferring volume and mass without depth information. Furthermore, reproducibility in this domain is hampered by the reliance of state-of-the-art methods on proprietary datasets for large-scale pre-training. In this paper, we investigate the impact of large-scale pre-training datasets on the performance of deep learning models for nutritional estimation using only 2D images. We fine-tune and evaluate Vision Transformer (ViT) models pre-trained on two large public datasets, ImageNet and COYO, comparing their performance against baseline CNN models (InceptionV2 and ResNet-50) and a state-of-the-art method pre-trained on the proprietary JFT-300M dataset. We conduct extensive experiments on the Nutrition5k dataset, a large-scale collection of real-world food plates with high-precision nutritional annotations. Our evaluation using Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAE%) reveals that models pre-trained on JFT-300M significantly outperform those pre-trained on public datasets. Unexpectedly, the model pre-trained on the massive COYO dataset performs worse than the model pre-trained on ImageNet for this specific regression task, refuting our initial hypothesis. Our analysis provides quantitative evidence highlighting the critical role of pre-training dataset characteristics, including scale, domain relevance, and curation quality, for effective transfer learning in 2D nutritional estimation.
On The Relationship between Visual Anomaly-free and Anomalous Representations
Oct 09, 2024Anomaly Detection is an important problem within computer vision, having variety of real-life applications. Yet, the current set of solutions to this problem entail known, systematic shortcomings. Specifically, contemporary surface Anomaly Detection task assumes the presence of multiple specific anomaly classes e.g. cracks, rusting etc., unlike one-class classification model of past. However, building a deep learning model in such setup remains a challenge because anomalies arise rarely, and hence anomaly samples are quite scarce. Transfer learning has been a preferred paradigm in such situations. But the typical source domains with large dataset sizes e.g. ImageNet, JFT-300M, LAION-2B do not correlate well with the domain of surfaces and materials, an important premise of transfer learning. In this paper, we make an important hypothesis and show, by exhaustive experimentation, that the space of anomaly-free visual patterns of the normal samples correlates well with each of the various spaces of anomalous patterns of the class-specific anomaly samples. The first results of using this hypothesis in transfer learning have indeed been quite encouraging. We expect that finding such a simple closeby domain that readily entails large number of samples, and which also oftentimes shows interclass separability though with narrow margins, will be a useful discovery. Especially, it is expected to improve domain adaptation for anomaly detection, and few-shot learning for anomaly detection, making in-the-wild anomaly detection realistically possible in future.
Visual Atoms: Pre-training Vision Transformers with Sinusoidal Waves
Mar 02, 2023



Formula-driven supervised learning (FDSL) has been shown to be an effective method for pre-training vision transformers, where ExFractalDB-21k was shown to exceed the pre-training effect of ImageNet-21k. These studies also indicate that contours mattered more than textures when pre-training vision transformers. However, the lack of a systematic investigation as to why these contour-oriented synthetic datasets can achieve the same accuracy as real datasets leaves much room for skepticism. In the present work, we develop a novel methodology based on circular harmonics for systematically investigating the design space of contour-oriented synthetic datasets. This allows us to efficiently search the optimal range of FDSL parameters and maximize the variety of synthetic images in the dataset, which we found to be a critical factor. When the resulting new dataset VisualAtom-21k is used for pre-training ViT-Base, the top-1 accuracy reached 83.7% when fine-tuning on ImageNet-1k. This is close to the top-1 accuracy (84.2%) achieved by JFT-300M pre-training, while the number of images is 1/14. Unlike JFT-300M which is a static dataset, the quality of synthetic datasets will continue to improve, and the current work is a testament to this possibility. FDSL is also free of the common issues associated with real images, e.g. privacy/copyright issues, labeling costs/errors, and ethical biases.
A simple, efficient and scalable contrastive masked autoencoder for learning visual representations
Oct 30, 2022



We introduce CAN, a simple, efficient and scalable method for self-supervised learning of visual representations. Our framework is a minimal and conceptually clean synthesis of (C) contrastive learning, (A) masked autoencoders, and (N) the noise prediction approach used in diffusion models. The learning mechanisms are complementary to one another: contrastive learning shapes the embedding space across a batch of image samples; masked autoencoders focus on reconstruction of the low-frequency spatial correlations in a single image sample; and noise prediction encourages the reconstruction of the high-frequency components of an image. The combined approach results in a robust, scalable and simple-to-implement algorithm. The training process is symmetric, with 50% of patches in both views being masked at random, yielding a considerable efficiency improvement over prior contrastive learning methods. Extensive empirical studies demonstrate that CAN achieves strong downstream performance under both linear and finetuning evaluations on transfer learning and robustness tasks. CAN outperforms MAE and SimCLR when pre-training on ImageNet, but is especially useful for pre-training on larger uncurated datasets such as JFT-300M: for linear probe on ImageNet, CAN achieves 75.4% compared to 73.4% for SimCLR and 64.1% for MAE. The finetuned performance on ImageNet of our ViT-L model is 86.1%, compared to 85.5% for SimCLR, and 85.4% for MAE. The overall FLOPs load of SimCLR is 70% higher than CAN for ViT-L models.
Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022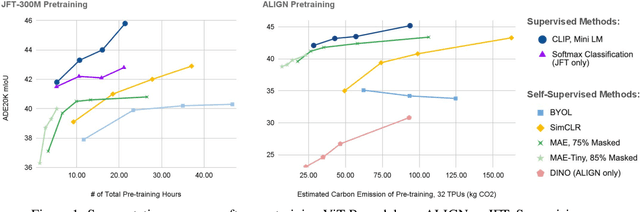
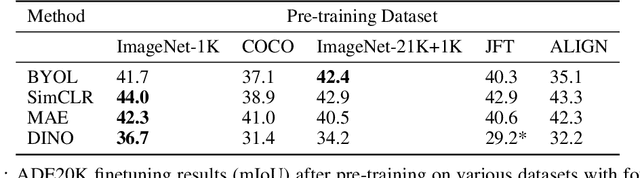
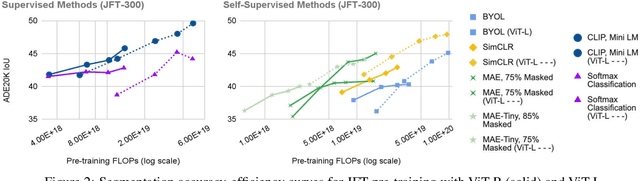
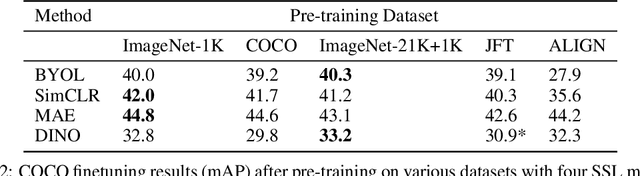
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.
How to Train Vision Transformer on Small-scale Datasets?
Oct 13, 2022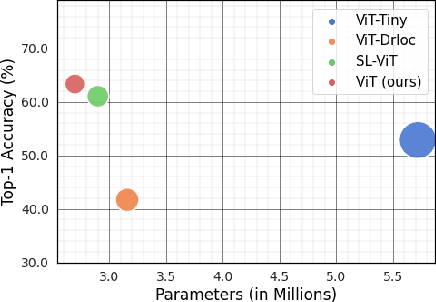

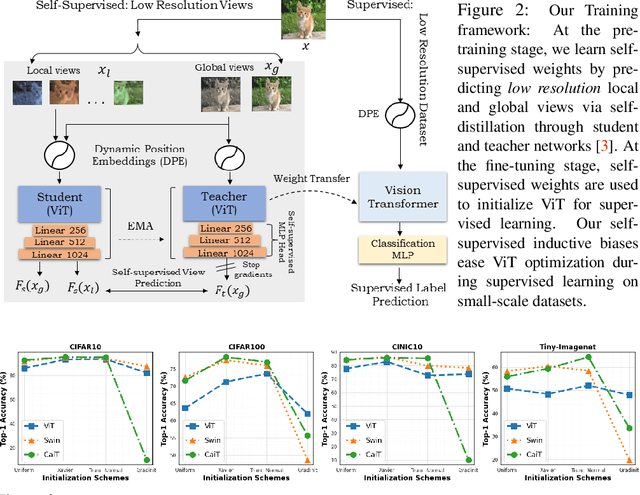
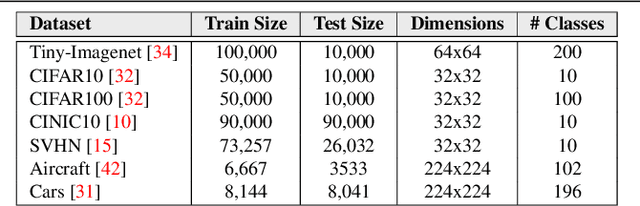
Vision Transformer (ViT), a radically different architecture than convolutional neural networks offers multiple advantages including design simplicity, robustness and state-of-the-art performance on many vision tasks. However, in contrast to convolutional neural networks, Vision Transformer lacks inherent inductive biases. Therefore, successful training of such models is mainly attributed to pre-training on large-scale datasets such as ImageNet with 1.2M or JFT with 300M images. This hinders the direct adaption of Vision Transformer for small-scale datasets. In this work, we show that self-supervised inductive biases can be learned directly from small-scale datasets and serve as an effective weight initialization scheme for fine-tuning. This allows to train these models without large-scale pre-training, changes to model architecture or loss functions. We present thorough experiments to successfully train monolithic and non-monolithic Vision Transformers on five small datasets including CIFAR10/100, CINIC10, SVHN, Tiny-ImageNet and two fine-grained datasets: Aircraft and Cars. Our approach consistently improves the performance of Vision Transformers while retaining their properties such as attention to salient regions and higher robustness. Our codes and pre-trained models are available at: https://github.com/hananshafi/vits-for-small-scale-datasets.
Progress and limitations of deep networks to recognize objects in unusual poses
Jul 16, 2022
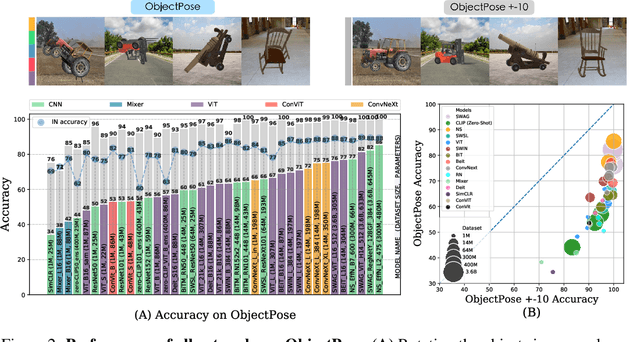
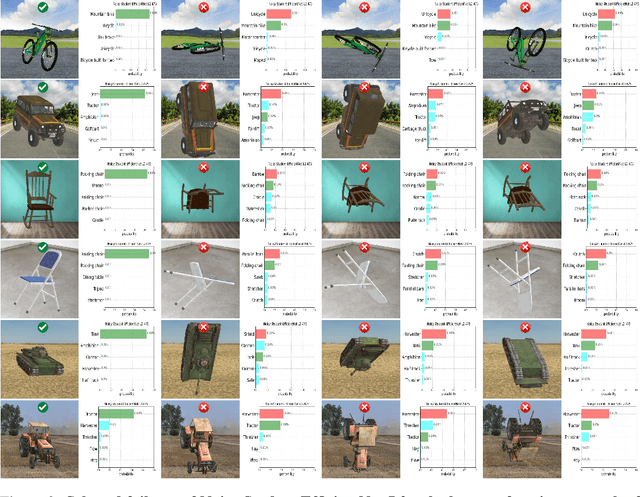
Deep networks should be robust to rare events if they are to be successfully deployed in high-stakes real-world applications (e.g., self-driving cars). Here we study the capability of deep networks to recognize objects in unusual poses. We create a synthetic dataset of images of objects in unusual orientations, and evaluate the robustness of a collection of 38 recent and competitive deep networks for image classification. We show that classifying these images is still a challenge for all networks tested, with an average accuracy drop of 29.5% compared to when the objects are presented upright. This brittleness is largely unaffected by various network design choices, such as training losses (e.g., supervised vs. self-supervised), architectures (e.g., convolutional networks vs. transformers), dataset modalities (e.g., images vs. image-text pairs), and data-augmentation schemes. However, networks trained on very large datasets substantially outperform others, with the best network tested$\unicode{x2014}$Noisy Student EfficentNet-L2 trained on JFT-300M$\unicode{x2014}$showing a relatively small accuracy drop of only 14.5% on unusual poses. Nevertheless, a visual inspection of the failures of Noisy Student reveals a remaining gap in robustness with the human visual system. Furthermore, combining multiple object transformations$\unicode{x2014}$3D-rotations and scaling$\unicode{x2014}$further degrades the performance of all networks. Altogether, our results provide another measurement of the robustness of deep networks that is important to consider when using them in the real world. Code and datasets are available at https://github.com/amro-kamal/ObjectPose.
Training Vision Transformers with Only 2040 Images
Jan 26, 2022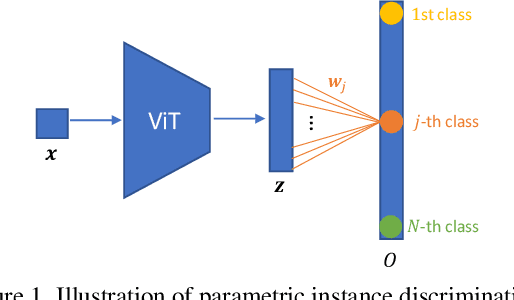
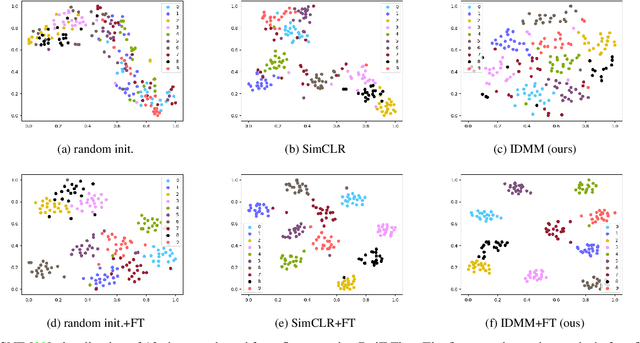
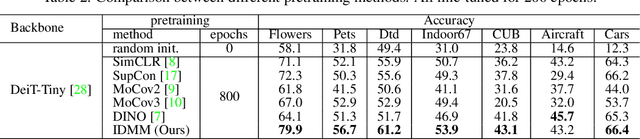
Vision Transformers (ViTs) is emerging as an alternative to convolutional neural networks (CNNs) for visual recognition. They achieve competitive results with CNNs but the lack of the typical convolutional inductive bias makes them more data-hungry than common CNNs. They are often pretrained on JFT-300M or at least ImageNet and few works study training ViTs with limited data. In this paper, we investigate how to train ViTs with limited data (e.g., 2040 images). We give theoretical analyses that our method (based on parametric instance discrimination) is superior to other methods in that it can capture both feature alignment and instance similarities. We achieve state-of-the-art results when training from scratch on 7 small datasets under various ViT backbones. We also investigate the transferring ability of small datasets and find that representations learned from small datasets can even improve large-scale ImageNet training.
Vision Transformer for Small-Size Datasets
Dec 27, 2021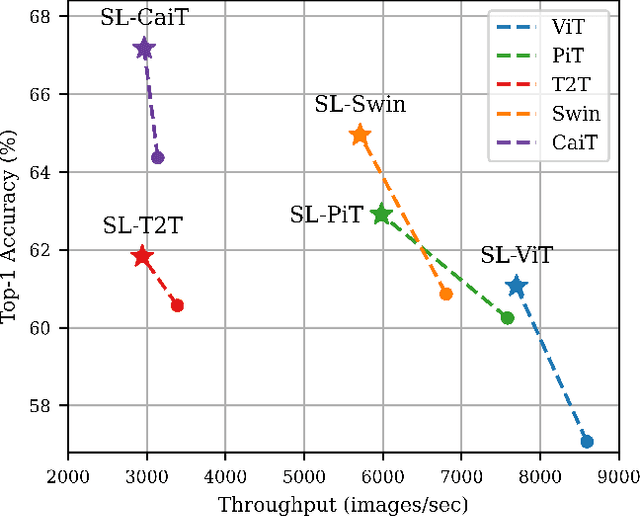
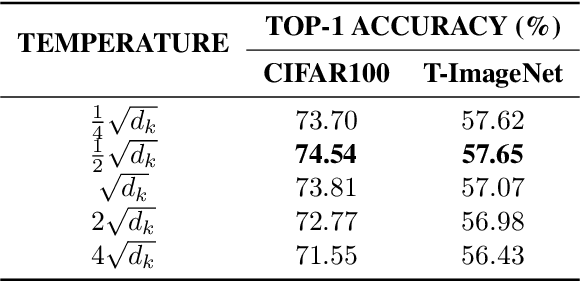

Recently, the Vision Transformer (ViT), which applied the transformer structure to the image classification task, has outperformed convolutional neural networks. However, the high performance of the ViT results from pre-training using a large-size dataset such as JFT-300M, and its dependence on a large dataset is interpreted as due to low locality inductive bias. This paper proposes Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA), which effectively solve the lack of locality inductive bias and enable it to learn from scratch even on small-size datasets. Moreover, SPT and LSA are generic and effective add-on modules that are easily applicable to various ViTs. Experimental results show that when both SPT and LSA were applied to the ViTs, the performance improved by an average of 2.96% in Tiny-ImageNet, which is a representative small-size dataset. Especially, Swin Transformer achieved an overwhelming performance improvement of 4.08% thanks to the proposed SPT and LSA.
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Jun 18, 2021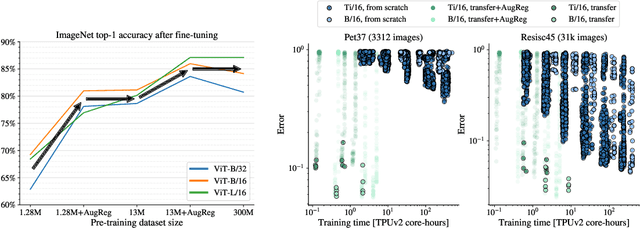
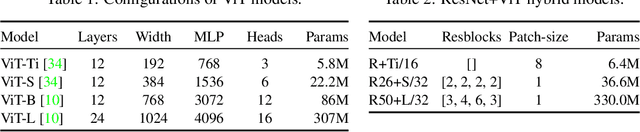
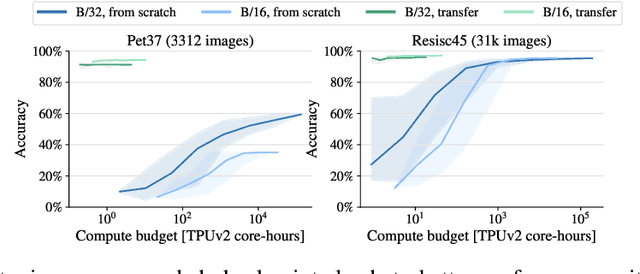
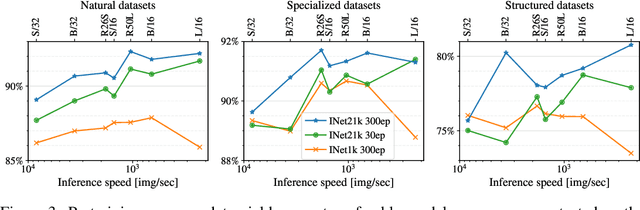
Vision Transformers (ViT) have been shown to attain highly competitive performance for a wide range of vision applications, such as image classification, object detection and semantic image segmentation. In comparison to convolutional neural networks, the Vision Transformer's weaker inductive bias is generally found to cause an increased reliance on model regularization or data augmentation (``AugReg'' for short) when training on smaller training datasets. We conduct a systematic empirical study in order to better understand the interplay between the amount of training data, AugReg, model size and compute budget. As one result of this study we find that the combination of increased compute and AugReg can yield models with the same performance as models trained on an order of magnitude more training data: we train ViT models of various sizes on the public ImageNet-21k dataset which either match or outperform their counterparts trained on the larger, but not publicly available JFT-300M dataset.