 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInception V4
Papers and Code
Multi-Label Scene Classification in Remote Sensing Benefits from Image Super-Resolution
Jan 12, 2025



Satellite imagery is a cornerstone for numerous Remote Sensing (RS) applications; however, limited spatial resolution frequently hinders the precision of such systems, especially in multi-label scene classification tasks as it requires a higher level of detail and feature differentiation. In this study, we explore the efficacy of image Super-Resolution (SR) as a pre-processing step to enhance the quality of satellite images and thus improve downstream classification performance. We investigate four SR models - SRResNet, HAT, SeeSR, and RealESRGAN - and evaluate their impact on multi-label scene classification across various CNN architectures, including ResNet-50, ResNet-101, ResNet-152, and Inception-v4. Our results show that applying SR significantly improves downstream classification performance across various metrics, demonstrating its ability to preserve spatial details critical for multi-label tasks. Overall, this work offers valuable insights into the selection of SR techniques for multi-label prediction in remote sensing and presents an easy-to-integrate framework to improve existing RS systems.
DeepGI: An Automated Approach for Gastrointestinal Tract Segmentation in MRI Scans
Jan 27, 2024Gastrointestinal (GI) tract cancers pose a global health challenge, demanding precise radiotherapy planning for optimal treatment outcomes. This paper introduces a cutting-edge approach to automate the segmentation of GI tract regions in magnetic resonance imaging (MRI) scans. Leveraging advanced deep learning architectures, the proposed model integrates Inception-V4 for initial classification, UNet++ with a VGG19 encoder for 2.5D data, and Edge UNet for grayscale data segmentation. Meticulous data preprocessing, including innovative 2.5D processing, is employed to enhance adaptability, robustness, and accuracy. This work addresses the manual and time-consuming segmentation process in current radiotherapy planning, presenting a unified model that captures intricate anatomical details. The integration of diverse architectures, each specializing in unique aspects of the segmentation task, signifies a novel and comprehensive solution. This model emerges as an efficient and accurate tool for clinicians, marking a significant advancement in the field of GI tract image segmentation for radiotherapy planning.
Augmenting endometriosis analysis from ultrasound data with deep learning
Feb 19, 2023Endometriosis is a non-malignant disorder that affects 176 million women globally. Diagnostic delays result in severe dysmenorrhea, dyspareunia, chronic pelvic pain, and infertility. Therefore, there is a significant need to diagnose patients at an early stage. Our objective in this work is to investigate the potential of deep learning methods to classify endometriosis from ultrasound data. Retrospective data from 100 subjects were collected at the Rutgers Robert Wood Johnson University Hospital (New Brunswick, NJ, USA). Endometriosis was diagnosed via laparoscopy or laparotomy. We designed and trained five different deep learning methods (Xception, Inception-V4, ResNet50, DenseNet, and EfficientNetB2) for the classification of endometriosis from ultrasound data. Using 5-fold cross-validation study we achieved an average area under the receiver operator curve (AUC) of 0.85 and 0.90 respectively for the two evaluation studies.
Semi-supervised Vision Transformers at Scale
Aug 11, 2022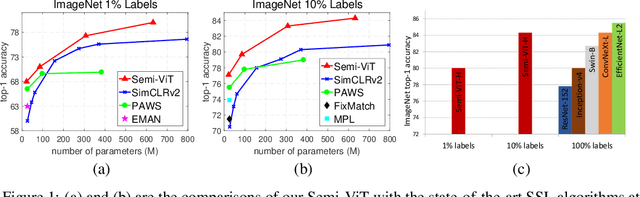
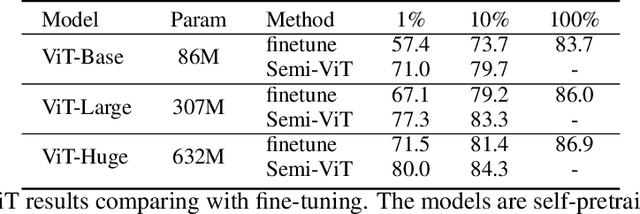
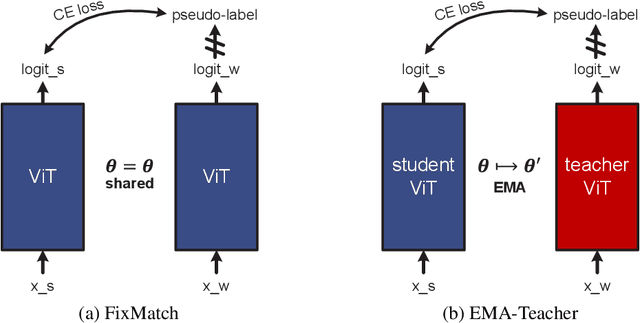
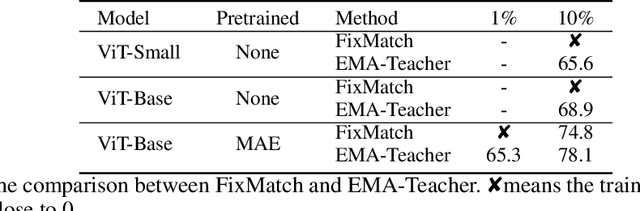
We study semi-supervised learning (SSL) for vision transformers (ViT), an under-explored topic despite the wide adoption of the ViT architectures to different tasks. To tackle this problem, we propose a new SSL pipeline, consisting of first un/self-supervised pre-training, followed by supervised fine-tuning, and finally semi-supervised fine-tuning. At the semi-supervised fine-tuning stage, we adopt an exponential moving average (EMA)-Teacher framework instead of the popular FixMatch, since the former is more stable and delivers higher accuracy for semi-supervised vision transformers. In addition, we propose a probabilistic pseudo mixup mechanism to interpolate unlabeled samples and their pseudo labels for improved regularization, which is important for training ViTs with weak inductive bias. Our proposed method, dubbed Semi-ViT, achieves comparable or better performance than the CNN counterparts in the semi-supervised classification setting. Semi-ViT also enjoys the scalability benefits of ViTs that can be readily scaled up to large-size models with increasing accuracies. For example, Semi-ViT-Huge achieves an impressive 80% top-1 accuracy on ImageNet using only 1% labels, which is comparable with Inception-v4 using 100% ImageNet labels.
Ensemble CNN models for Covid-19 Recognition and Severity Perdition From 3D CT-scan
Jun 29, 2022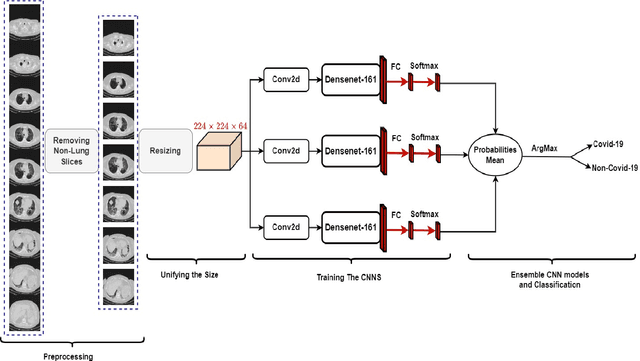
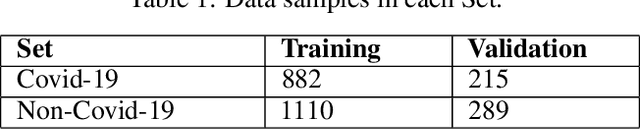
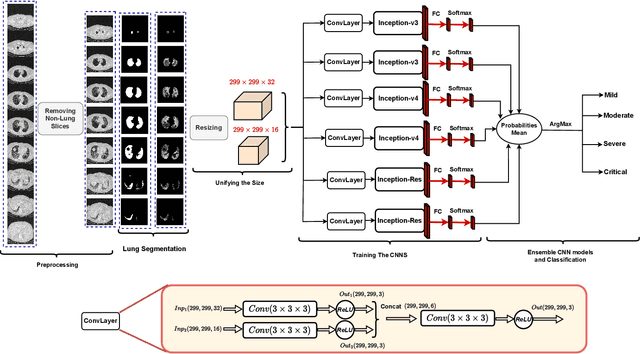
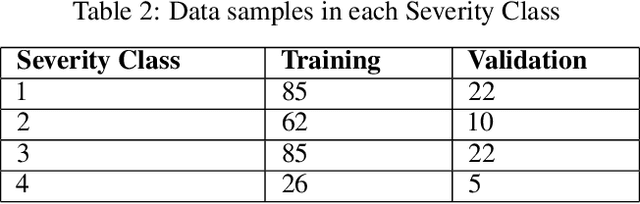
Since the appearance of Covid-19 in late 2019, Covid-19 has become an active research topic for the artificial intelligence (AI) community. One of the most interesting AI topics is Covid-19 analysis of medical imaging. CT-scan imaging is the most informative tool about this disease. This work is part of the 2nd COV19D competition, where two challenges are set: Covid-19 Detection and Covid-19 Severity Detection from the CT-scans. For Covid-19 detection from CT-scans, we proposed an ensemble of 2D Convolution blocks with Densenet-161 models. Here, each 2D convolutional block with Densenet-161 architecture is trained separately and in testing phase, the ensemble model is based on the average of their probabilities. On the other hand, we proposed an ensemble of Convolutional Layers with Inception models for Covid-19 severity detection. In addition to the Convolutional Layers, three Inception variants were used, namely Inception-v3, Inception-v4 and Inception-Resnet. Our proposed approaches outperformed the baseline approach in the validation data of the 2nd COV19D competition by 11% and 16% for Covid-19 detection and Covid-19 severity detection, respectively.
A Deep Learning based Wearable Healthcare IoT Device for AI-enabled Hearing Assistance Automation
May 16, 2020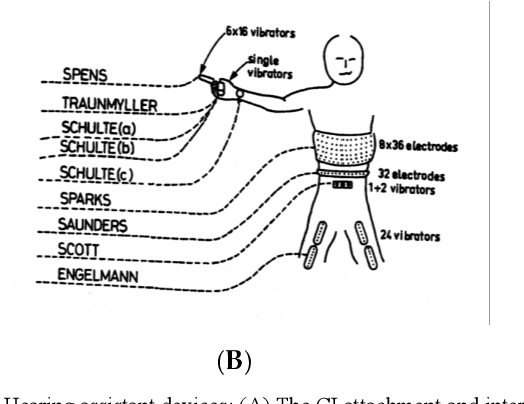

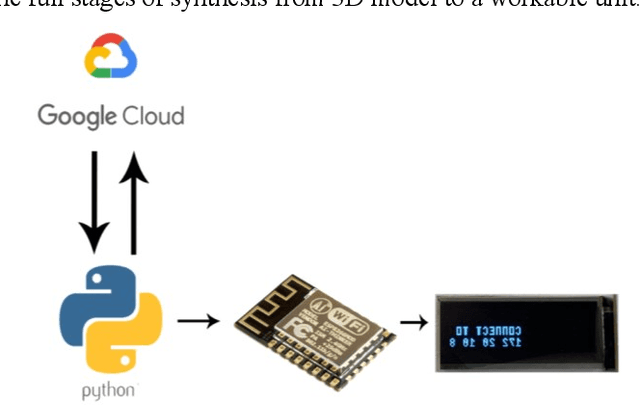

With the recent booming of artificial intelligence (AI), particularly deep learning techniques, digital healthcare is one of the prevalent areas that could gain benefits from AI-enabled functionality. This research presents a novel AI-enabled Internet of Things (IoT) device operating from the ESP-8266 platform capable of assisting those who suffer from impairment of hearing or deafness to communicate with others in conversations. In the proposed solution, a server application is created that leverages Google's online speech recognition service to convert the received conversations into texts, then deployed to a micro-display attached to the glasses to display the conversation contents to deaf people, to enable and assist conversation as normal with the general population. Furthermore, in order to raise alert of traffic or dangerous scenarios, an 'urban-emergency' classifier is developed using a deep learning model, Inception-v4, with transfer learning to detect/recognize alerting/alarming sounds, such as a horn sound or a fire alarm, with texts generated to alert the prospective user. The training of Inception-v4 was carried out on a consumer desktop PC and then implemented into the AI based IoT application. The empirical results indicate that the developed prototype system achieves an accuracy rate of 92% for sound recognition and classification with real-time performance.
Comprehensive Comparison of Deep Learning Models for Lung and COVID-19 Lesion Segmentation in CT scans
Sep 10, 2020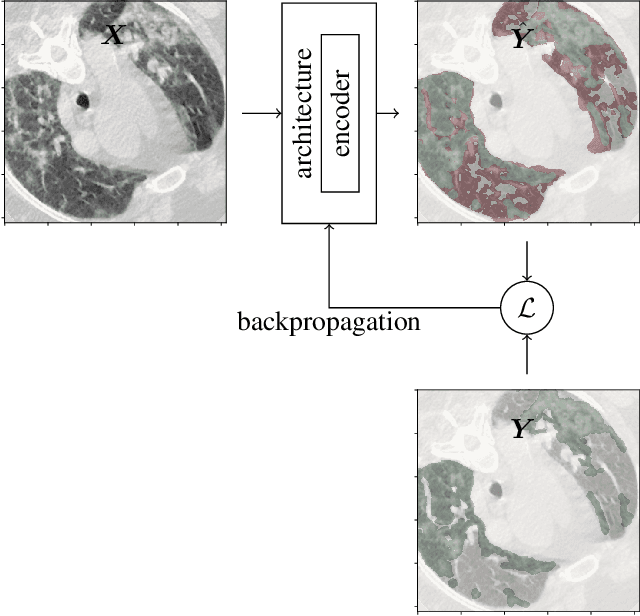
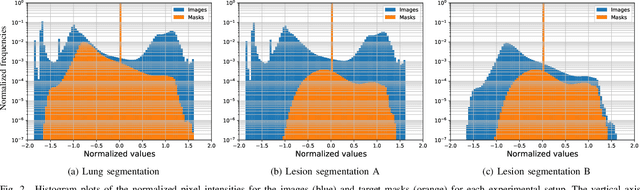

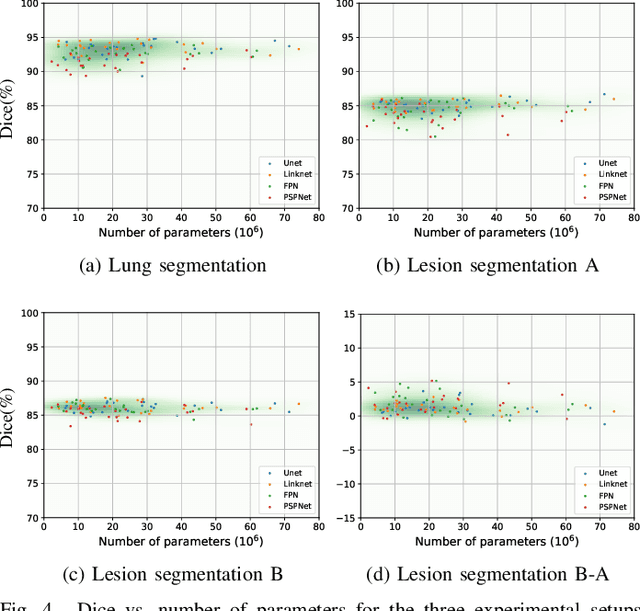
Recently there has been an explosion in the use of Deep Learning (DL) methods for medical image segmentation. However the field's reliability is hindered by the lack of a common base of reference for accuracy/performance evaluation and the fact that previous research uses different datasets for evaluation. In this paper, an extensive comparison of DL models for lung and COVID-19 lesion segmentation in Computerized Tomography (CT) scans is presented, which can also be used as a benchmark for testing medical image segmentation models. Four DL architectures (Unet, Linknet, FPN, PSPNet) are combined with 25 randomly initialized and pretrained encoders (variations of VGG, DenseNet, ResNet, ResNext, DPN, MobileNet, Xception, Inception-v4, EfficientNet), to construct 200 tested models. Three experimental setups are conducted for lung segmentation, lesion segmentation and lesion segmentation using the original lung masks. A public COVID-19 dataset with 100 CT scan images (80 for train, 20 for validation) is used for training/validation and a different public dataset consisting of 829 images from 9 CT scan volumes for testing. Multiple findings are provided including the best architecture-encoder models for each experiment as well as mean Dice results for each experiment, architecture and encoder independently. Finally, the upper bounds improvements when using lung masks as a preprocessing step or when using pretrained models are quantified. The source code and 600 pretrained models for the three experiments are provided, suitable for fine-tuning in experimental setups without GPU capabilities.
Effects of Approximate Multiplication on Convolutional Neural Networks
Jul 20, 2020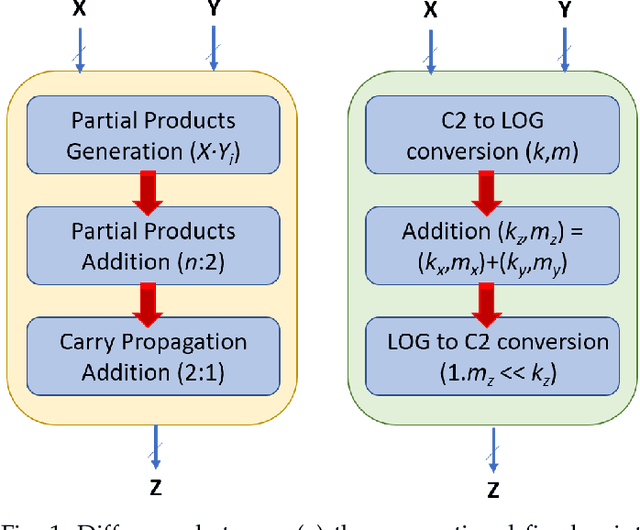
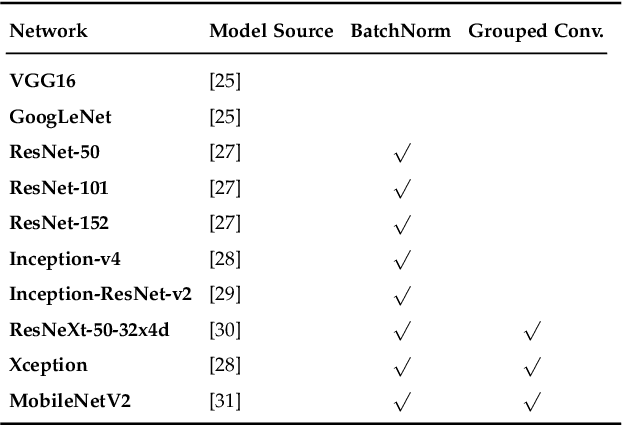
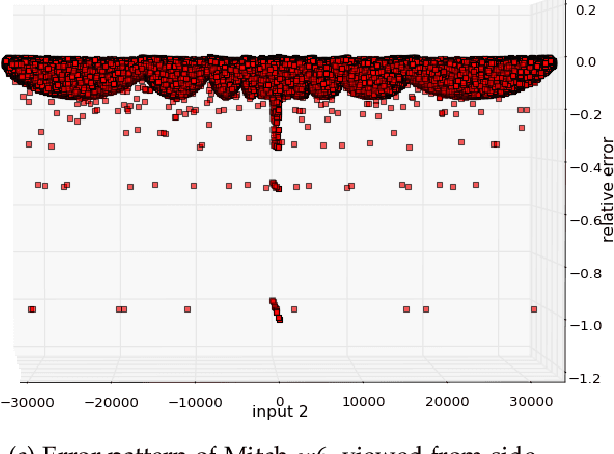

This paper analyzes the effects of approximate multiplication when performing inferences on deep convolutional neural networks (CNNs). The approximate multiplication can reduce the cost of underlying circuits so that CNN inferences can be performed more efficiently in hardware accelerators. The study identifies the critical factors in the convolution, fully-connected, and batch normalization layers that allow more accurate CNN predictions despite the errors from approximate multiplication. The same factors also provide an arithmetic explanation of why bfloat16 multiplication performs well on CNNs. The experiments are performed with recognized network architectures to show that the approximate multipliers can produce predictions that are nearly as accurate as the FP32 references, without additional training. For example, the ResNet and Inception-v4 models with Mitch-$w$6 multiplication produces Top-5 errors that are within 0.2% compared to the FP32 references. A brief cost comparison of Mitch-$w$6 against bfloat16 is presented, where a MAC operation saves up to 80% of energy compared to the bfloat16 arithmetic. The most far-reaching contribution of this paper is the analytical justification that multiplications can be approximated while additions need to be exact in CNN MAC operations.
Inception Architecture and Residual Connections in Classification of Breast Cancer Histology Images
Dec 10, 2019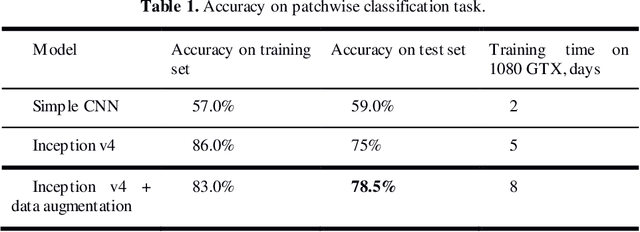

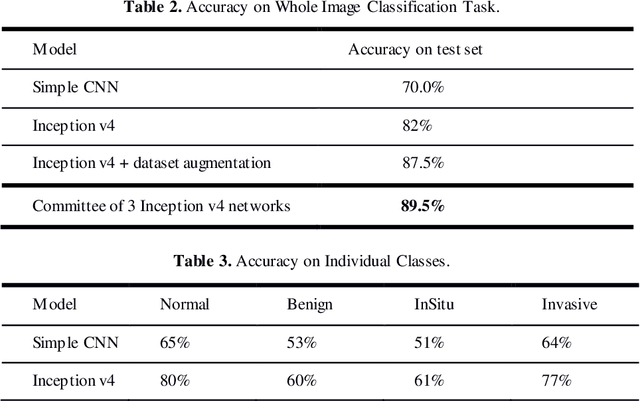
This paper presents results of applying Inception v4 deep convolutional neural network to ICIAR-2018 Breast Cancer Classification Grand Challenge, part a. The Challenge task is to classify breast cancer biopsy results, presented in form of hematoxylin and eosin stained images. Breast cancer classification is of primary interest to the medical practitioners and thus binary classification of breast cancer images have been under investigation by many researchers, but multi-class categorization of histology breast images have been challenging due to the subtle differences among the categories. In this work extensive data augmentation is conducted to reduce overfitting and effectiveness of committee of several Inception v4 networks is studied. We report 89% accuracy on 4 class classification task and 93.7% on carcinoma/non-carcinoma two class classification task using our test set of 80 images.
A Robust Iris Authentication System on GPU-Based Edge Devices using Multi-Modalities Learning Model
Dec 02, 2019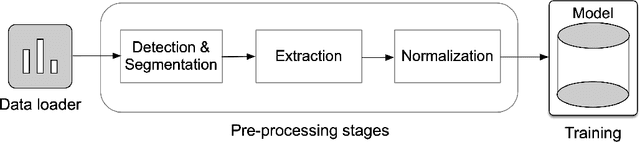
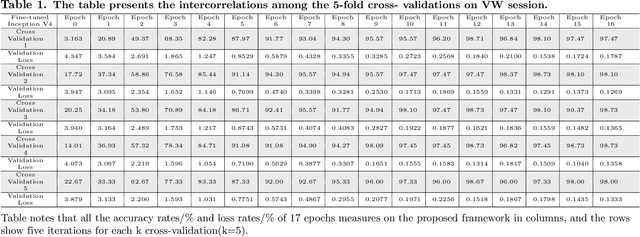
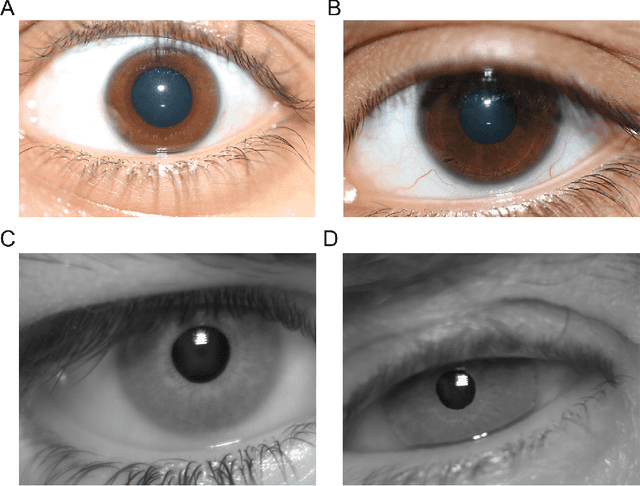
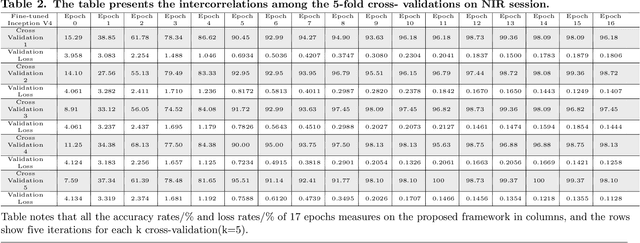
In recent years, mobile Internet has accelerated the proliferation of smart mobile development. The mobile payment, mobile security and privacy protection have become the focus of widespread attention. Iris recognition becomes a high-security authentication technology in these fields, it is widely used in distinct science fields in biometric authentication fields. The Convolutional Neural Network (CNN) is one of the mainstream deep learning approaches for image recognition, whereas its anti-noise ability is weak and needs a certain amount of memory to train in image classification tasks. Under these conditions we put forward a fine-tuning neural network model based on the Mask R-CNN and Inception V4 neural network model, which integrates every component in an overall system that combines the iris detection, extraction, and recognition function as an iris recognition system. The proposed framework has the characteristics of scalability and high availability; it not only can learn part-whole relationships of the iris image but also enhancing the robustness of the whole framework. Importantly, the proposed model can be trained using the different spectrum of samples, such as Visible Wavelength (VW) and Near Infrared (NIR) iris biometric databases. The recognition average accuracy of 99.10% is achieved while executing in the mobile edge calculation device of the Jetson Nano.