 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Aware Video Panoptic Segmentation
Papers and Code
Balancing Shared and Task-Specific Representations: A Hybrid Approach to Depth-Aware Video Panoptic Segmentation
Dec 10, 2024



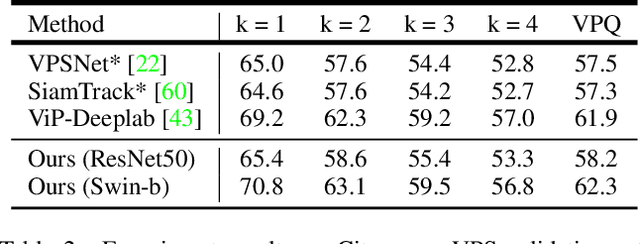
In this work, we present Multiformer, a novel approach to depth-aware video panoptic segmentation (DVPS) based on the mask transformer paradigm. Our method learns object representations that are shared across segmentation, monocular depth estimation, and object tracking subtasks. In contrast to recent unified approaches that progressively refine a common object representation, we propose a hybrid method using task-specific branches within each decoder block, ultimately fusing them into a shared representation at the block interfaces. Extensive experiments on the Cityscapes-DVPS and SemKITTI-DVPS datasets demonstrate that Multiformer achieves state-of-the-art performance across all DVPS metrics, outperforming previous methods by substantial margins. With a ResNet-50 backbone, Multiformer surpasses the previous best result by 3.0 DVPQ points while also improving depth estimation accuracy. Using a Swin-B backbone, Multiformer further improves performance by 4.0 DVPQ points. Multiformer also provides valuable insights into the design of multi-task decoder architectures.
Unified Perception: Efficient Video Panoptic Segmentation with Minimal Annotation Costs
Mar 03, 2023



Depth-aware video panoptic segmentation is a promising approach to camera based scene understanding. However, the current state-of-the-art methods require costly video annotations and use a complex training pipeline compared to their image-based equivalents. In this paper, we present a new approach titled Unified Perception that achieves state-of-the-art performance without requiring video-based training. Our method employs a simple two-stage cascaded tracking algorithm that (re)uses object embeddings computed in an image-based network. Experimental results on the Cityscapes-DVPS dataset demonstrate that our method achieves an overall DVPQ of 57.1, surpassing state-of-the-art methods. Furthermore, we show that our tracking strategies are effective for long-term object association on KITTI-STEP, achieving an STQ of 59.1 which exceeded the performance of state-of-the-art methods that employ the same backbone network.
MonoDVPS: A Self-Supervised Monocular Depth Estimation Approach to Depth-aware Video Panoptic Segmentation
Oct 14, 2022


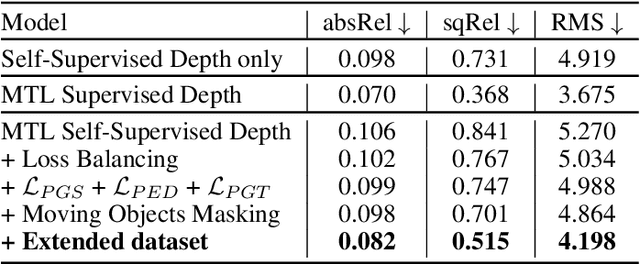
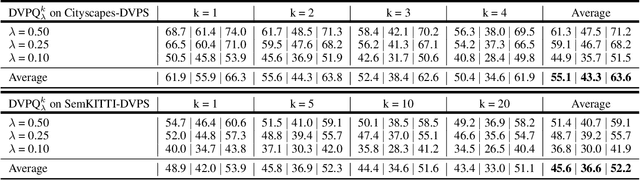
Depth-aware video panoptic segmentation tackles the inverse projection problem of restoring panoptic 3D point clouds from video sequences, where the 3D points are augmented with semantic classes and temporally consistent instance identifiers. We propose a novel solution with a multi-task network that performs monocular depth estimation and video panoptic segmentation. Since acquiring ground truth labels for both depth and image segmentation has a relatively large cost, we leverage the power of unlabeled video sequences with self-supervised monocular depth estimation and semi-supervised learning from pseudo-labels for video panoptic segmentation. To further improve the depth prediction, we introduce panoptic-guided depth losses and a novel panoptic masking scheme for moving objects to avoid corrupting the training signal. Extensive experiments on the Cityscapes-DVPS and SemKITTI-DVPS datasets demonstrate that our model with the proposed improvements achieves competitive results and fast inference speed.
PolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation
Dec 05, 2021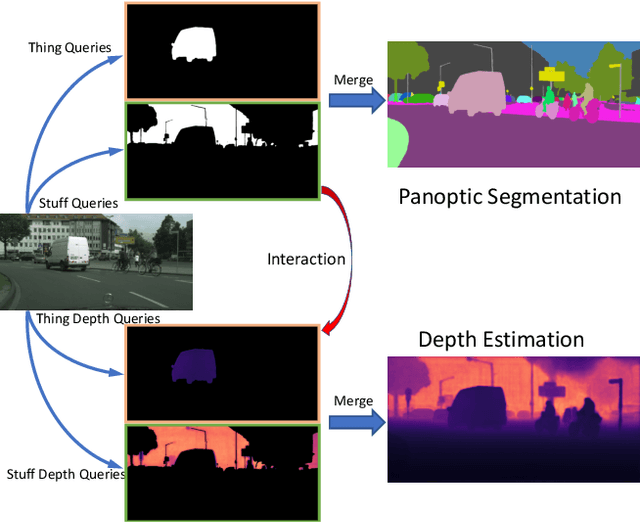
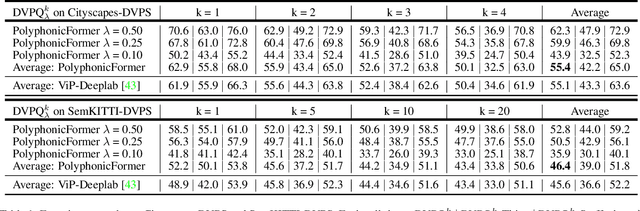
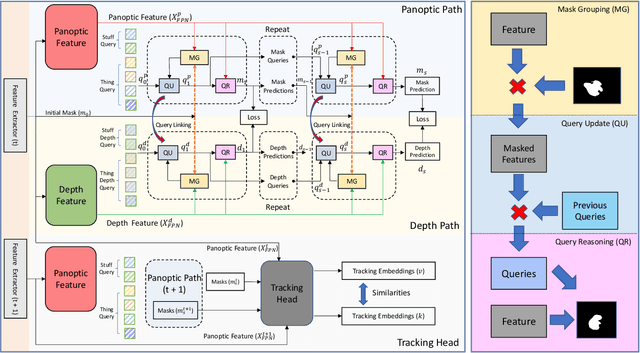
The recently proposed Depth-aware Video Panoptic Segmentation (DVPS) aims to predict panoptic segmentation results and depth maps in a video, which is a challenging scene understanding problem. In this paper, we present PolyphonicFormer, a vision transformer to unify all the sub-tasks under the DVPS task. Our method explores the relationship between depth estimation and panoptic segmentation via query-based learning. In particular, we design three different queries including thing query, stuff query, and depth query. Then we propose to learn the correlations among these queries via gated fusion. From the experiments, we prove the benefits of our design from both depth estimation and panoptic segmentation aspects. Since each thing query also encodes the instance-wise information, it is natural to perform tracking via cropping instance mask features with appearance learning. Our method ranks 1st on the ICCV-2021 BMTT Challenge video + depth track. Ablation studies are reported to show how we improve the performance. Code will be available at https://github.com/HarborYuan/PolyphonicFormer.
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
Dec 09, 2020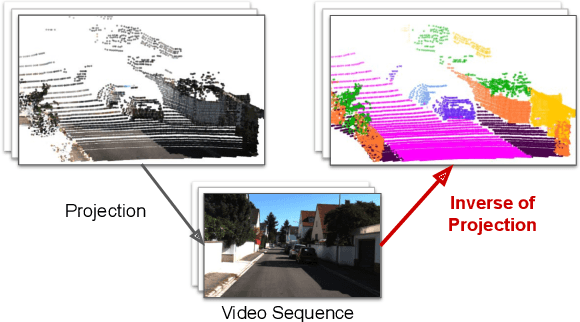
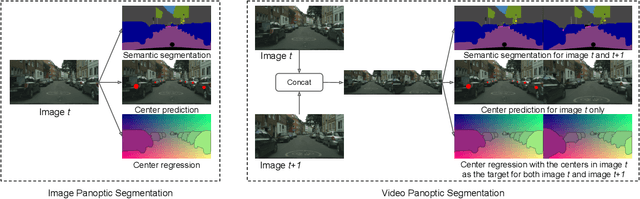
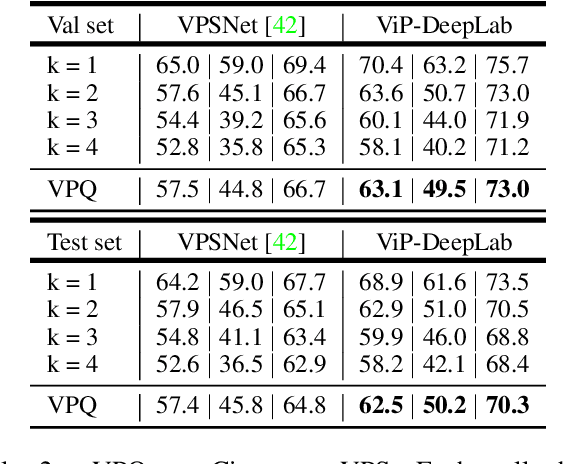
In this paper, we present ViP-DeepLab, a unified model attempting to tackle the long-standing and challenging inverse projection problem in vision, which we model as restoring the point clouds from perspective image sequences while providing each point with instance-level semantic interpretations. Solving this problem requires the vision models to predict the spatial location, semantic class, and temporally consistent instance label for each 3D point. ViP-DeepLab approaches it by jointly performing monocular depth estimation and video panoptic segmentation. We name this joint task as Depth-aware Video Panoptic Segmentation, and propose a new evaluation metric along with two derived datasets for it, which will be made available to the public. On the individual sub-tasks, ViP-DeepLab also achieves state-of-the-art results, outperforming previous methods by 5.1% VPQ on Cityscapes-VPS, ranking 1st on the KITTI monocular depth estimation benchmark, and 1st on KITTI MOTS pedestrian. The datasets and the evaluation codes are made publicly available.
MGNet: Monocular Geometric Scene Understanding for Autonomous Driving
Jun 27, 2022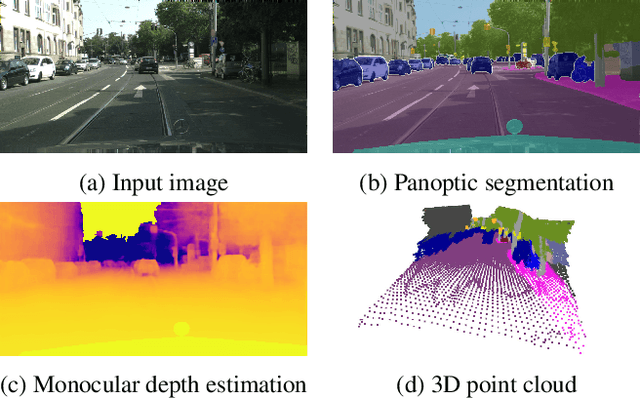
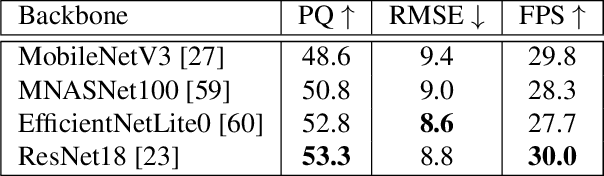
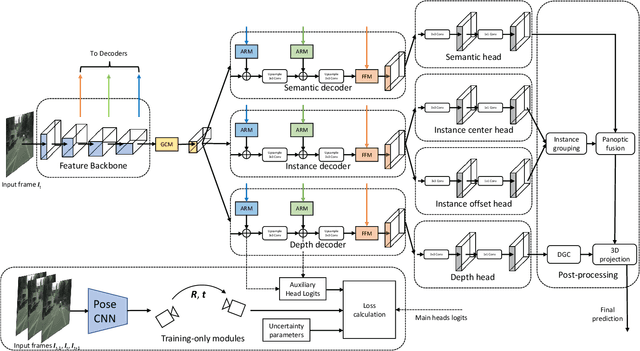
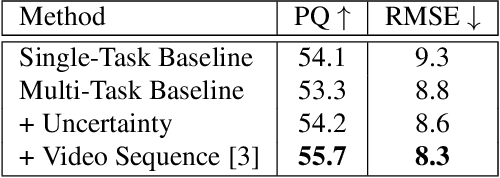
We introduce MGNet, a multi-task framework for monocular geometric scene understanding. We define monocular geometric scene understanding as the combination of two known tasks: Panoptic segmentation and self-supervised monocular depth estimation. Panoptic segmentation captures the full scene not only semantically, but also on an instance basis. Self-supervised monocular depth estimation uses geometric constraints derived from the camera measurement model in order to measure depth from monocular video sequences only. To the best of our knowledge, we are the first to propose the combination of these two tasks in one single model. Our model is designed with focus on low latency to provide fast inference in real-time on a single consumer-grade GPU. During deployment, our model produces dense 3D point clouds with instance aware semantic labels from single high-resolution camera images. We evaluate our model on two popular autonomous driving benchmarks, i.e., Cityscapes and KITTI, and show competitive performance among other real-time capable methods. Source code is available at https://github.com/markusschoen/MGNet.