 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDailytalk
Papers and Code
Retrieval-Augmented Dialogue Knowledge Aggregation for Expressive Conversational Speech Synthesis
Jan 11, 2025



Conversational speech synthesis (CSS) aims to take the current dialogue (CD) history as a reference to synthesize expressive speech that aligns with the conversational style. Unlike CD, stored dialogue (SD) contains preserved dialogue fragments from earlier stages of user-agent interaction, which include style expression knowledge relevant to scenarios similar to those in CD. Note that this knowledge plays a significant role in enabling the agent to synthesize expressive conversational speech that generates empathetic feedback. However, prior research has overlooked this aspect. To address this issue, we propose a novel Retrieval-Augmented Dialogue Knowledge Aggregation scheme for expressive CSS, termed RADKA-CSS, which includes three main components: 1) To effectively retrieve dialogues from SD that are similar to CD in terms of both semantic and style. First, we build a stored dialogue semantic-style database (SDSSD) which includes the text and audio samples. Then, we design a multi-attribute retrieval scheme to match the dialogue semantic and style vectors of the CD with the stored dialogue semantic and style vectors in the SDSSD, retrieving the most similar dialogues. 2) To effectively utilize the style knowledge from CD and SD, we propose adopting the multi-granularity graph structure to encode the dialogue and introducing a multi-source style knowledge aggregation mechanism. 3) Finally, the aggregated style knowledge are fed into the speech synthesizer to help the agent synthesize expressive speech that aligns with the conversational style. We conducted a comprehensive and in-depth experiment based on the DailyTalk dataset, which is a benchmarking dataset for the CSS task. Both objective and subjective evaluations demonstrate that RADKA-CSS outperforms baseline models in expressiveness rendering. Code and audio samples can be found at: https://github.com/Coder-jzq/RADKA-CSS.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
Intra- and Inter-modal Context Interaction Modeling for Conversational Speech Synthesis
Dec 25, 2024Conversational Speech Synthesis (CSS) aims to effectively take the multimodal dialogue history (MDH) to generate speech with appropriate conversational prosody for target utterance. The key challenge of CSS is to model the interaction between the MDH and the target utterance. Note that text and speech modalities in MDH have their own unique influences, and they complement each other to produce a comprehensive impact on the target utterance. Previous works did not explicitly model such intra-modal and inter-modal interactions. To address this issue, we propose a new intra-modal and inter-modal context interaction scheme-based CSS system, termed III-CSS. Specifically, in the training phase, we combine the MDH with the text and speech modalities in the target utterance to obtain four modal combinations, including Historical Text-Next Text, Historical Speech-Next Speech, Historical Text-Next Speech, and Historical Speech-Next Text. Then, we design two contrastive learning-based intra-modal and two inter-modal interaction modules to deeply learn the intra-modal and inter-modal context interaction. In the inference phase, we take MDH and adopt trained interaction modules to fully infer the speech prosody of the target utterance's text content. Subjective and objective experiments on the DailyTalk dataset show that III-CSS outperforms the advanced baselines in terms of prosody expressiveness. Code and speech samples are available at https://github.com/AI-S2-Lab/I3CSS.
Emphasis Rendering for Conversational Text-to-Speech with Multi-modal Multi-scale Context Modeling
Oct 12, 2024



Conversational Text-to-Speech (CTTS) aims to accurately express an utterance with the appropriate style within a conversational setting, which attracts more attention nowadays. While recognizing the significance of the CTTS task, prior studies have not thoroughly investigated speech emphasis expression, which is essential for conveying the underlying intention and attitude in human-machine interaction scenarios, due to the scarcity of conversational emphasis datasets and the difficulty in context understanding. In this paper, we propose a novel Emphasis Rendering scheme for the CTTS model, termed ER-CTTS, that includes two main components: 1) we simultaneously take into account textual and acoustic contexts, with both global and local semantic modeling to understand the conversation context comprehensively; 2) we deeply integrate multi-modal and multi-scale context to learn the influence of context on the emphasis expression of the current utterance. Finally, the inferred emphasis feature is fed into the neural speech synthesizer to generate conversational speech. To address data scarcity, we create emphasis intensity annotations on the existing conversational dataset (DailyTalk). Both objective and subjective evaluations suggest that our model outperforms the baseline models in emphasis rendering within a conversational setting. The code and audio samples are available at https://github.com/CodeStoreTTS/ER-CTTS.
Emotion Rendering for Conversational Speech Synthesis with Heterogeneous Graph-Based Context Modeling
Dec 19, 2023Conversational Speech Synthesis (CSS) aims to accurately express an utterance with the appropriate prosody and emotional inflection within a conversational setting. While recognising the significance of CSS task, the prior studies have not thoroughly investigated the emotional expressiveness problems due to the scarcity of emotional conversational datasets and the difficulty of stateful emotion modeling. In this paper, we propose a novel emotional CSS model, termed ECSS, that includes two main components: 1) to enhance emotion understanding, we introduce a heterogeneous graph-based emotional context modeling mechanism, which takes the multi-source dialogue history as input to model the dialogue context and learn the emotion cues from the context; 2) to achieve emotion rendering, we employ a contrastive learning-based emotion renderer module to infer the accurate emotion style for the target utterance. To address the issue of data scarcity, we meticulously create emotional labels in terms of category and intensity, and annotate additional emotional information on the existing conversational dataset (DailyTalk). Both objective and subjective evaluations suggest that our model outperforms the baseline models in understanding and rendering emotions. These evaluations also underscore the importance of comprehensive emotional annotations. Code and audio samples can be found at: https://github.com/walker-hyf/ECSS.
TempAdaCos: Learning Temporally Structured Embeddings for Few-Shot Keyword Spotting with Dynamic Time Warping
May 18, 2023


Few-shot keyword spotting (KWS) systems often utilize a sliding window of fixed size. Because of the varying lengths of different keywords or their spoken instances, choosing the right window size is a problem: A window should be long enough to contain all necessary information needed to recognize a keyword but a longer window may contain irrelevant information such as multiple words or noise and thus makes it difficult to reliably detect on- and offsets of keywords. In this work, TempAdaCos, an angular margin loss for obtaining embeddings with temporal structure, that can be used to detect keywords with dynamic time warping is proposed. In experiments conducted on KWS-DailyTalk, a few-shot keyword spotting (KWS) dataset presented in this work, it is shown that using these embeddings outperforms using other representations or a sliding window. Furthermore, it is shown that using time-reversed segments of the keywords while training the system improves the performance.
DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech
Jul 03, 2022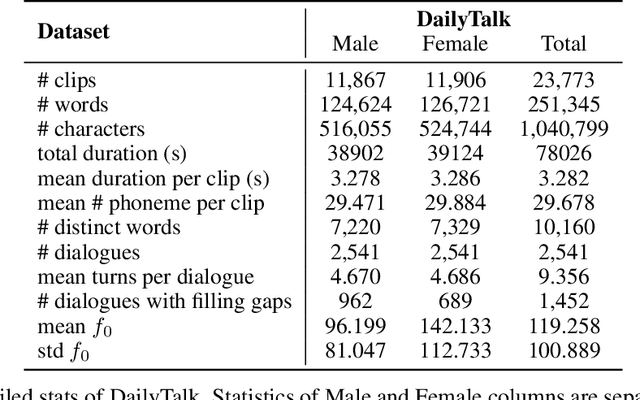
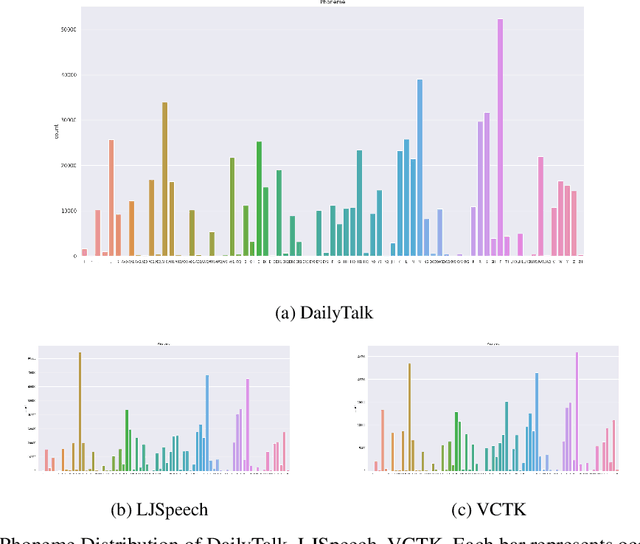

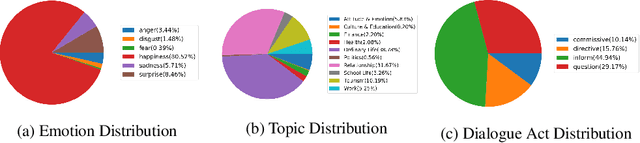
The majority of current TTS datasets, which are collections of individual utterances, contain few conversational aspects in terms of both style and metadata. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for Text-to-Speech. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog which are adequately long to represent context of each dialogue. During the data construction step, we maintained attributes distribution originally annotated in DailyDialog to support diverse dialogue in DailyTalk. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialog. We gather metadata so that a TTS model can learn historical dialog information, the key to generating context-aware speech. From the baseline experiment results, we show that DailyTalk can be used to train neural text-to-speech models, and our baseline can represent contextual information. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.