 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConala
Papers and Code
An LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
May 27, 2025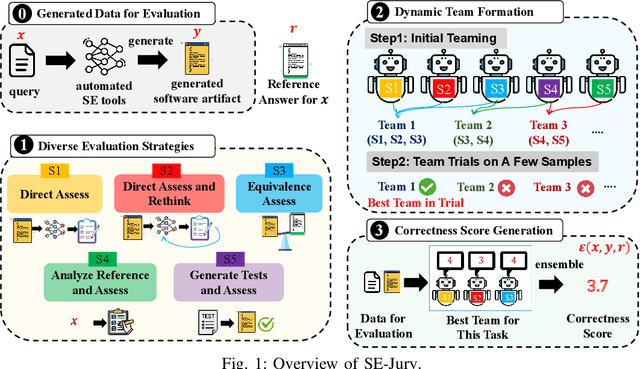
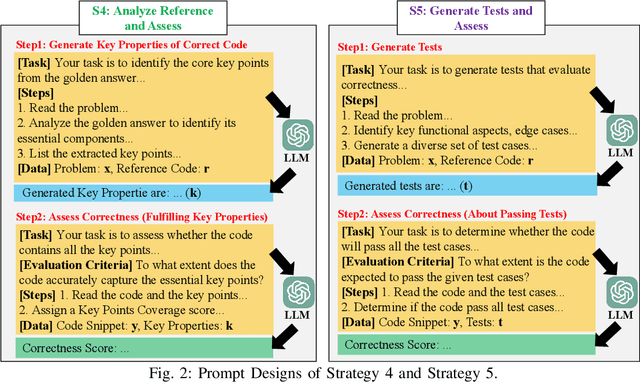
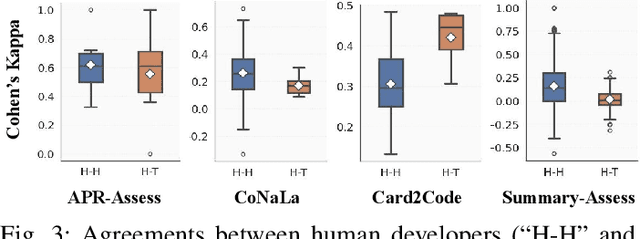
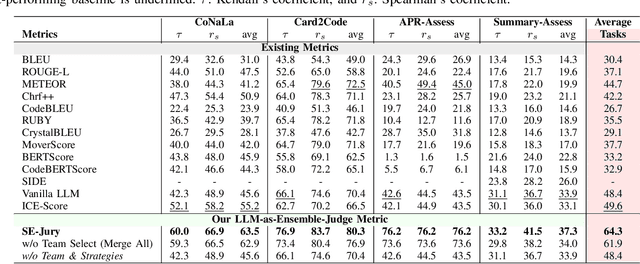
Large Language Models (LLMs) and other automated techniques have been increasingly used to support software developers by generating software artifacts such as code snippets, patches, and comments. However, accurately assessing the correctness of these generated artifacts remains a significant challenge. On one hand, human evaluation provides high accuracy but is labor-intensive and lacks scalability. On the other hand, other existing automatic evaluation metrics are scalable and require minimal human effort, but they often fail to accurately reflect the actual correctness of generated software artifacts. In this paper, we present SWE-Judge, the first evaluation metric for LLM-as-Ensemble-Judge specifically designed to accurately assess the correctness of generated software artifacts. SWE-Judge first defines five distinct evaluation strategies, each implemented as an independent judge. A dynamic team selection mechanism then identifies the most appropriate subset of judges to produce a final correctness score through ensembling. We evaluate SWE-Judge across a diverse set of software engineering (SE) benchmarks, including CoNaLa, Card2Code, HumanEval-X, APPS, APR-Assess, and Summary-Assess. These benchmarks span three SE tasks: code generation, automated program repair, and code summarization. Experimental results demonstrate that SWE-Judge consistently achieves a higher correlation with human judgments, with improvements ranging from 5.9% to 183.8% over existing automatic metrics. Furthermore, SWE-Judge reaches agreement levels with human annotators that are comparable to inter-annotator agreement in code generation and program repair tasks. These findings underscore SWE-Judge's potential as a scalable and reliable alternative to human evaluation.
Model Editing for LLMs4Code: How Far are We?
Nov 11, 2024



Large Language Models for Code (LLMs4Code) have been found to exhibit outstanding performance in the software engineering domain, especially the remarkable performance in coding tasks. However, even the most advanced LLMs4Code can inevitably contain incorrect or outdated code knowledge. Due to the high cost of training LLMs4Code, it is impractical to re-train the models for fixing these problematic code knowledge. Model editing is a new technical field for effectively and efficiently correcting erroneous knowledge in LLMs, where various model editing techniques and benchmarks have been proposed recently. Despite that, a comprehensive study that thoroughly compares and analyzes the performance of the state-of-the-art model editing techniques for adapting the knowledge within LLMs4Code across various code-related tasks is notably absent. To bridge this gap, we perform the first systematic study on applying state-of-the-art model editing approaches to repair the inaccuracy of LLMs4Code. To that end, we introduce a benchmark named CLMEEval, which consists of two datasets, i.e., CoNaLa-Edit (CNLE) with 21K+ code generation samples and CodeSearchNet-Edit (CSNE) with 16K+ code summarization samples. With the help of CLMEEval, we evaluate six advanced model editing techniques on three LLMs4Code: CodeLlama (7B), CodeQwen1.5 (7B), and Stable-Code (3B). Our findings include that the external memorization-based GRACE approach achieves the best knowledge editing effectiveness and specificity (the editing does not influence untargeted knowledge), while generalization (whether the editing can generalize to other semantically-identical inputs) is a universal challenge for existing techniques. Furthermore, building on in-depth case analysis, we introduce an enhanced version of GRACE called A-GRACE, which incorporates contrastive learning to better capture the semantics of the inputs.
Neural Models for Source Code Synthesis and Completion
Feb 08, 2024Natural language (NL) to code suggestion systems assist developers in Integrated Development Environments (IDEs) by translating NL utterances into compilable code snippet. The current approaches mainly involve hard-coded, rule-based systems based on semantic parsing. These systems make heavy use of hand-crafted rules that map patterns in NL or elements in its syntax parse tree to various query constructs and can only work on a limited subset of NL with a restricted NL syntax. These systems are unable to extract semantic information from the coding intents of the developer, and often fail to infer types, names, and the context of the source code to get accurate system-level code suggestions. In this master thesis, we present sequence-to-sequence deep learning models and training paradigms to map NL to general-purpose programming languages that can assist users with suggestions of source code snippets, given a NL intent, and also extend auto-completion functionality of the source code to users while they are writing source code. The developed architecture incorporates contextual awareness into neural models which generate source code tokens directly instead of generating parse trees/abstract meaning representations from the source code and converting them back to source code. The proposed pretraining strategy and the data augmentation techniques improve the performance of the proposed architecture. The proposed architecture has been found to exceed the performance of a neural semantic parser, TranX, based on the BLEU-4 metric by 10.82%. Thereafter, a finer analysis for the parsable code translations from the NL intent for CoNaLA challenge was introduced. The proposed system is bidirectional as it can be also used to generate NL code documentation given source code. Lastly, a RoBERTa masked language model for Python was proposed to extend the developed system for code completion.
Out of the BLEU: how should we assess quality of the Code Generation models?
Aug 05, 2022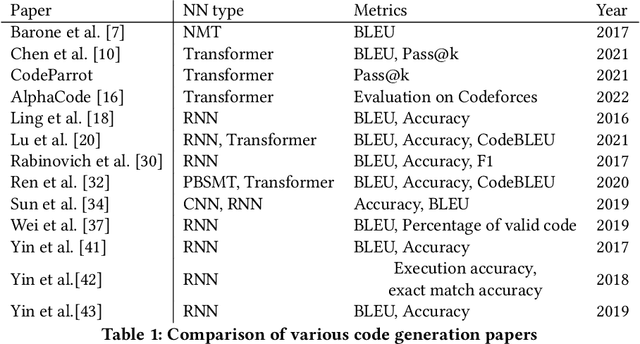
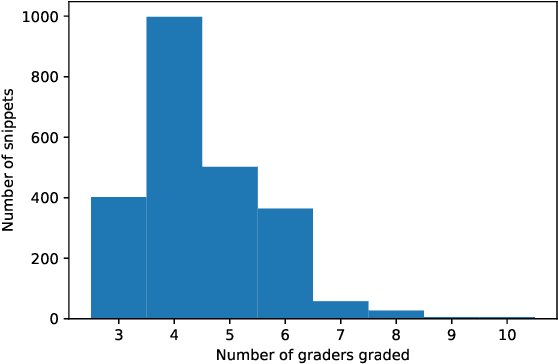

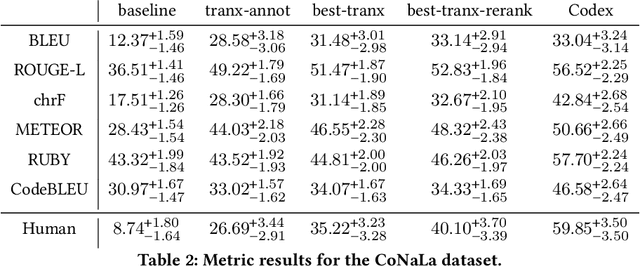
In recent years, researchers have created and introduced a significant number of various code generation models. As human evaluation of every new model version is unfeasible, the community adopted automatic evaluation metrics such as BLEU to approximate the results of human judgement. These metrics originate from the machine translation domain and it is unclear whether they are applicable for the code generation tasks and how well do they agree with the human evaluation on this task. There also are two metrics, CodeBLEU and RUBY, that were developed to estimate the similarity of code and take into account the code properties. However, for these metrics there are hardly any studies on their agreement with the human evaluation. Despite all that, minimal differences in the metric scores are used to claim superiority of some code generation models over the others. In this paper, we present a study on applicability of six metrics -- BLEU, ROUGE-L, METEOR, ChrF, CodeBLEU, RUBY -- for evaluation of the code generation models. We conduct a study on two different code generation datasets and use human annotators to assess the quality of all models run on these datasets. The results indicate that for the CoNaLa dataset of Python one-liners none of the metrics can correctly emulate human judgement on which model is better with $>95\%$ certainty if the difference in model scores is less than 5 points. For the HearthStone dataset, which consists of classes of particular structure, the difference in model scores of at least 2 points is enough to claim the superiority of one model over the other. Using our findings, we derive several recommendations on using metrics to estimate the model performance on the code generation task.
DocCoder: Generating Code by Retrieving and Reading Docs
Jul 13, 2022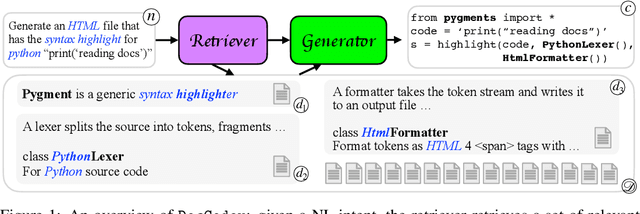
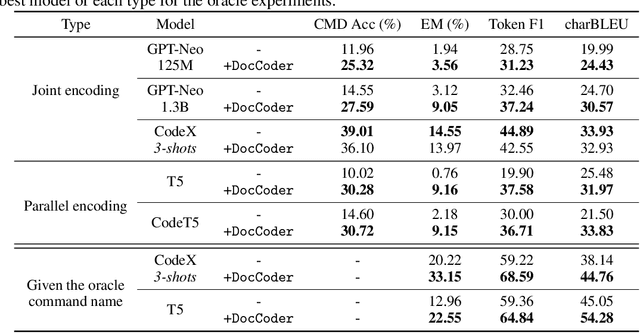
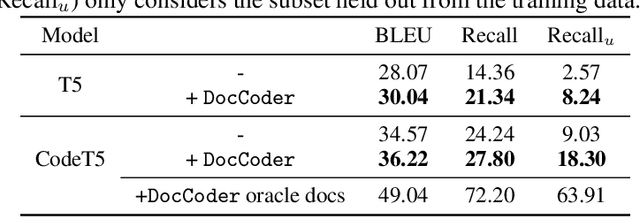
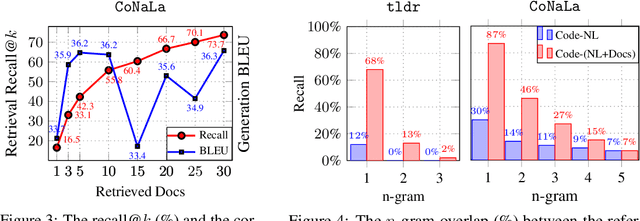
Natural-language-to-code models learn to generate a code snippet given a natural language (NL) intent. However, the rapid growth of both publicly available and proprietary libraries and functions makes it impossible to cover all APIs using training examples, as new libraries and functions are introduced daily. Thus, existing models inherently cannot generalize to using unseen functions and libraries merely through incorporating them into the training data. In contrast, when human programmers write programs, they frequently refer to textual resources such as code manuals, documentation, and tutorials, to explore and understand available library functionality. Inspired by this observation, we introduce DocCoder: an approach that explicitly leverages code manuals and documentation by (1) retrieving the relevant documentation given the NL intent, and (2) generating the code based on the NL intent and the retrieved documentation. Our approach is general, can be applied to any programming language, and is agnostic to the underlying neural model. We demonstrate that DocCoder consistently improves NL-to-code models: DocCoder achieves 11x higher exact match accuracy than strong baselines on a new Bash dataset tldr; on the popular Python CoNaLa benchmark, DocCoder improves over strong baselines by 1.65 BLEU.
MCoNaLa: A Benchmark for Code Generation from Multiple Natural Languages
Mar 16, 2022
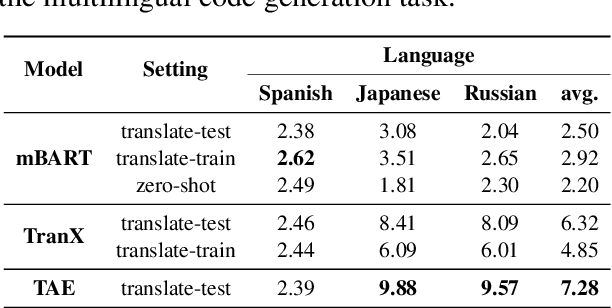

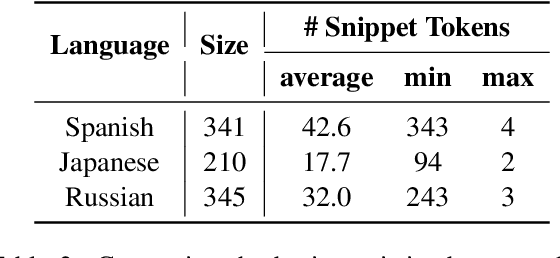
While there has been a recent burgeoning of applications at the intersection of natural and programming languages, such as code generation and code summarization, these applications are usually English-centric. This creates a barrier for program developers who are not proficient in English. To mitigate this gap in technology development across languages, we propose a multilingual dataset, MCoNaLa, to benchmark code generation from natural language commands extending beyond English. Modeled off of the methodology from the English Code/Natural Language Challenge (CoNaLa) dataset, we annotated a total of 896 NL-code pairs in three languages: Spanish, Japanese, and Russian. We present a quantitative evaluation of performance on the MCoNaLa dataset by testing with state-of-the-art code generation systems. While the difficulties vary across these three languages, all systems lag significantly behind their English counterparts, revealing the challenges in adapting code generation to new languages.
Natural Language to Code Using Transformers
Feb 01, 2022We tackle the problem of generating code snippets from natural language descriptions using the CoNaLa dataset. We use the self-attention based transformer architecture and show that it performs better than recurrent attention-based encoder decoder. Furthermore, we develop a modified form of back translation and use cycle consistent losses to train the model in an end-to-end fashion. We achieve a BLEU score of 16.99 beating the previously reported baseline of the CoNaLa challenge.
Text Classification for Task-based Source Code Related Questions
Oct 31, 2021There is a key demand to automatically generate code for small tasks for developers. Websites such as StackOverflow provide a simplistic way by offering solutions in small snippets which provide a complete answer to whatever task question the developer wants to code. Natural Language Processing and particularly Question-Answering Systems are very helpful in resolving and working on these tasks. In this paper, we develop a two-fold deep learning model: Seq2Seq and a binary classifier that takes in the intent (which is in natural language) and code snippets in Python. We train both the intent and the code utterances in the Seq2Seq model, where we decided to compare the effect of the hidden layer embedding from the encoder for representing the intent and similarly, using the decoder's hidden layer embeddings for the code sequence. Then we combine both these embeddings and then train a simple binary neural network classifier model for predicting if the intent is correctly answered by the predicted code sequence from the seq2seq model. We find that the hidden state layer's embeddings perform slightly better than regular standard embeddings from a constructed vocabulary. We experimented with our tests on the CoNaLa dataset in addition to the StaQC database consisting of simple task-code snippet-based pairs. We empirically establish that using additional pre-trained embeddings for code snippets in Python is less context-based in comparison to using hidden state context vectors from seq2seq models.
Reading StackOverflow Encourages Cheating: Adding Question Text Improves Extractive Code Generation
Jun 08, 2021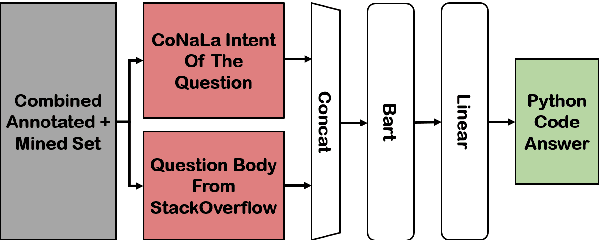

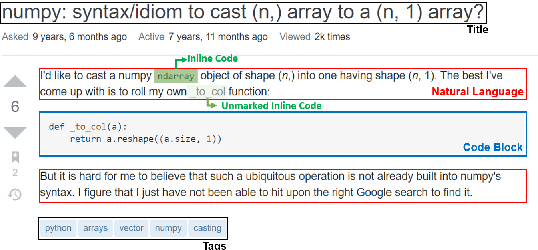

Answering a programming question using only its title is difficult as salient contextual information is omitted. Based on this observation, we present a corpus of over 40,000 StackOverflow question texts to be used in conjunction with their corresponding intents from the CoNaLa dataset (Yin et al., 2018). Using both the intent and question body, we use BART to establish a baseline BLEU score of 34.35 for this new task. We find further improvements of $2.8\%$ by combining the mined CoNaLa data with the labeled data to achieve a 35.32 BLEU score. We evaluate prior state-of-the-art CoNaLa models with this additional data and find that our proposed method of using the body and mined data beats the BLEU score of the prior state-of-the-art by $71.96\%$. Finally, we perform ablations to demonstrate that BART is an unsupervised multimodal learner and examine its extractive behavior. The code and data can be found https://github.com/gabeorlanski/stackoverflow-encourages-cheating.
Generating Code with the Help of Retrieved Template Functions and Stack Overflow Answers
Apr 13, 2021

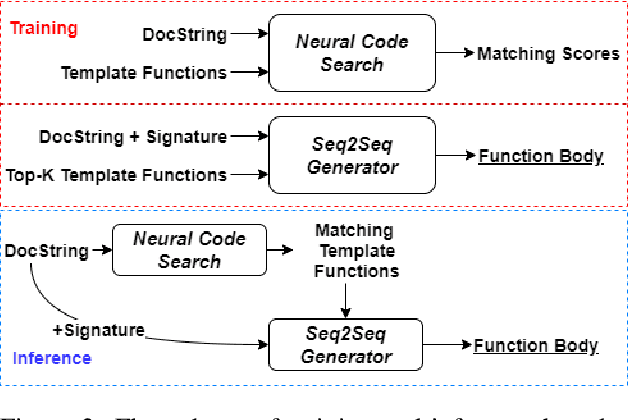

We approach the important challenge of code autocompletion as an open-domain task, in which a sequence-to-sequence code generator model is enhanced with the ability to attend to reference code snippets supplied by a semantic code search engine. In this work, we present a novel framework to precisely retrieve template functions as well as intent-snippet pairs and effectively train such a retrieval-guided code generator. To demonstrate the effectiveness of our model designs, we perform extensive experiments with CodeSearchNet which contains template functions and CoNaLa which contains Stack Overflow intent-snippet pairs. We also investigate different retrieval models, including Elasticsearch, DPR, and our fusion representation search model, which currently holds the number one spot on the CodeSearchNet leaderboard. We observe improvements by leveraging multiple database elements and further gain from retrieving diverse data points by using Maximal Marginal Relevance. Overall, we see a 4% improvement to cross-entropy loss, a 15% improvement to edit distance, and a 44% improvement to BLEU score when retrieving template functions. We see subtler improvements of 2%, 11%, and 6% respectively when retrieving Stack Overflow intent-snippet pairs. We also create a novel Stack Overflow-Function Alignment dataset, which consists of 150K tuples of functions and Stack Overflow intent-snippet pairs that are of help in writing the associated function, of which 1.7K are manually curated.