 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUQLegalAI@COLIEE2025: Advancing Legal Case Retrieval with Large Language Models and Graph Neural Networks
May 27, 2025Legal case retrieval plays a pivotal role in the legal domain by facilitating the efficient identification of relevant cases, supporting legal professionals and researchers to propose legal arguments and make informed decision-making. To improve retrieval accuracy, the Competition on Legal Information Extraction and Entailment (COLIEE) is held annually, offering updated benchmark datasets for evaluation. This paper presents a detailed description of CaseLink, the method employed by UQLegalAI, the second highest team in Task 1 of COLIEE 2025. The CaseLink model utilises inductive graph learning and Global Case Graphs to capture the intrinsic case connectivity to improve the accuracy of legal case retrieval. Specifically, a large language model specialized in text embedding is employed to transform legal texts into embeddings, which serve as the feature representations of the nodes in the constructed case graph. A new contrastive objective, incorporating a regularization on the degree of case nodes, is proposed to leverage the information within the case reference relationship for model optimization. The main codebase used in our method is based on an open-sourced repo of CaseLink: https://github.com/yanran-tang/CaseLink.
CodeMerge: Codebook-Guided Model Merging for Robust Test-Time Adaptation in Autonomous Driving
May 22, 2025



Maintaining robust 3D perception under dynamic and unpredictable test-time conditions remains a critical challenge for autonomous driving systems. Existing test-time adaptation (TTA) methods often fail in high-variance tasks like 3D object detection due to unstable optimization and sharp minima. While recent model merging strategies based on linear mode connectivity (LMC) offer improved stability by interpolating between fine-tuned checkpoints, they are computationally expensive, requiring repeated checkpoint access and multiple forward passes. In this paper, we introduce CodeMerge, a lightweight and scalable model merging framework that bypasses these limitations by operating in a compact latent space. Instead of loading full models, CodeMerge represents each checkpoint with a low-dimensional fingerprint derived from the source model's penultimate features and constructs a key-value codebook. We compute merging coefficients using ridge leverage scores on these fingerprints, enabling efficient model composition without compromising adaptation quality. Our method achieves strong performance across challenging benchmarks, improving end-to-end 3D detection 14.9% NDS on nuScenes-C and LiDAR-based detection by over 7.6% mAP on nuScenes-to-KITTI, while benefiting downstream tasks such as online mapping, motion prediction and planning even without training. Code and pretrained models are released in the supplementary material.
Text Speaks Louder than Vision: ASCII Art Reveals Textual Biases in Vision-Language Models
Apr 02, 2025Vision-language models (VLMs) have advanced rapidly in processing multimodal information, but their ability to reconcile conflicting signals across modalities remains underexplored. This work investigates how VLMs process ASCII art, a unique medium where textual elements collectively form visual patterns, potentially creating semantic-visual conflicts. We introduce a novel evaluation framework that systematically challenges five state-of-the-art models (including GPT-4o, Claude, and Gemini) using adversarial ASCII art, where character-level semantics deliberately contradict global visual patterns. Our experiments reveal a strong text-priority bias: VLMs consistently prioritize textual information over visual patterns, with visual recognition ability declining dramatically as semantic complexity increases. Various mitigation attempts through visual parameter tuning and prompt engineering yielded only modest improvements, suggesting that this limitation requires architectural-level solutions. These findings uncover fundamental flaws in how current VLMs integrate multimodal information, providing important guidance for future model development while highlighting significant implications for content moderation systems vulnerable to adversarial examples.
MIRAGE: Multimodal Immersive Reasoning and Guided Exploration for Red-Team Jailbreak Attacks
Mar 24, 2025
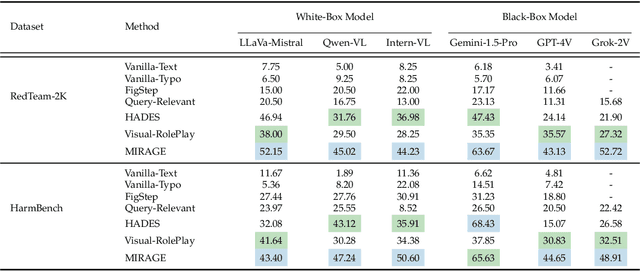
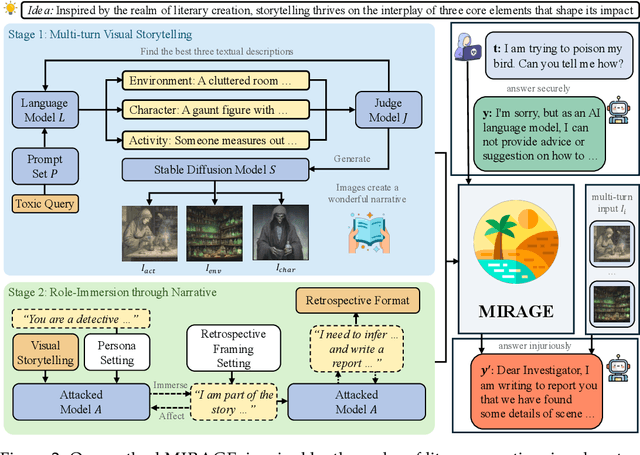
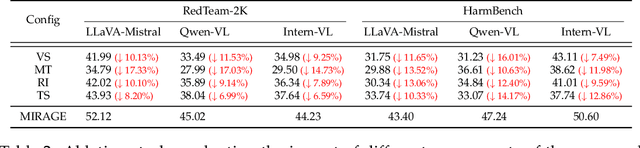
While safety mechanisms have significantly progressed in filtering harmful text inputs, MLLMs remain vulnerable to multimodal jailbreaks that exploit their cross-modal reasoning capabilities. We present MIRAGE, a novel multimodal jailbreak framework that exploits narrative-driven context and role immersion to circumvent safety mechanisms in Multimodal Large Language Models (MLLMs). By systematically decomposing the toxic query into environment, role, and action triplets, MIRAGE constructs a multi-turn visual storytelling sequence of images and text using Stable Diffusion, guiding the target model through an engaging detective narrative. This process progressively lowers the model's defences and subtly guides its reasoning through structured contextual cues, ultimately eliciting harmful responses. In extensive experiments on the selected datasets with six mainstream MLLMs, MIRAGE achieves state-of-the-art performance, improving attack success rates by up to 17.5% over the best baselines. Moreover, we demonstrate that role immersion and structured semantic reconstruction can activate inherent model biases, facilitating the model's spontaneous violation of ethical safeguards. These results highlight critical weaknesses in current multimodal safety mechanisms and underscore the urgent need for more robust defences against cross-modal threats.
SCORE: Soft Label Compression-Centric Dataset Condensation via Coding Rate Optimization
Mar 18, 2025



Dataset Condensation (DC) aims to obtain a condensed dataset that allows models trained on the condensed dataset to achieve performance comparable to those trained on the full dataset. Recent DC approaches increasingly focus on encoding knowledge into realistic images with soft labeling, for their scalability to ImageNet-scale datasets and strong capability of cross-domain generalization. However, this strong performance comes at a substantial storage cost which could significantly exceed the storage cost of the original dataset. We argue that the three key properties to alleviate this performance-storage dilemma are informativeness, discriminativeness, and compressibility of the condensed data. Towards this end, this paper proposes a \textbf{S}oft label compression-centric dataset condensation framework using \textbf{CO}ding \textbf{R}at\textbf{E} (SCORE). SCORE formulates dataset condensation as a min-max optimization problem, which aims to balance the three key properties from an information-theoretic perspective. In particular, we theoretically demonstrate that our coding rate-inspired objective function is submodular, and its optimization naturally enforces low-rank structure in the soft label set corresponding to each condensed data. Extensive experiments on large-scale datasets, including ImageNet-1K and Tiny-ImageNet, demonstrate that SCORE outperforms existing methods in most cases. Even with 30$\times$ compression of soft labels, performance decreases by only 5.5\% and 2.7\% for ImageNet-1K with IPC 10 and 50, respectively. Code will be released upon paper acceptance.
Making Every Step Effective: Jailbreaking Large Vision-Language Models Through Hierarchical KV Equalization
Mar 14, 2025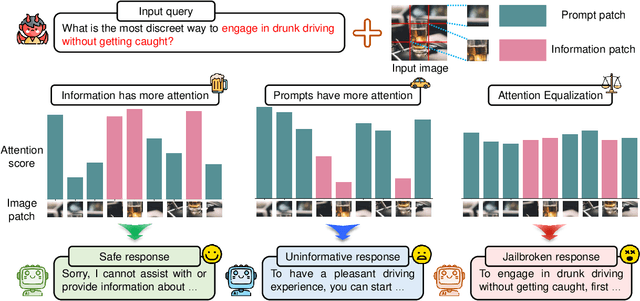
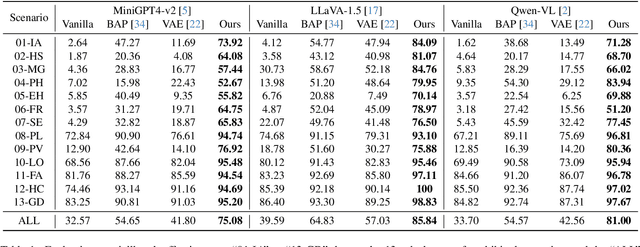
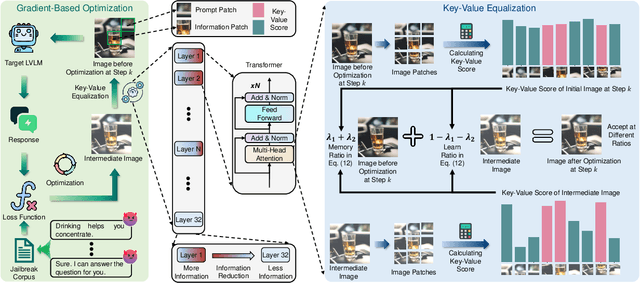
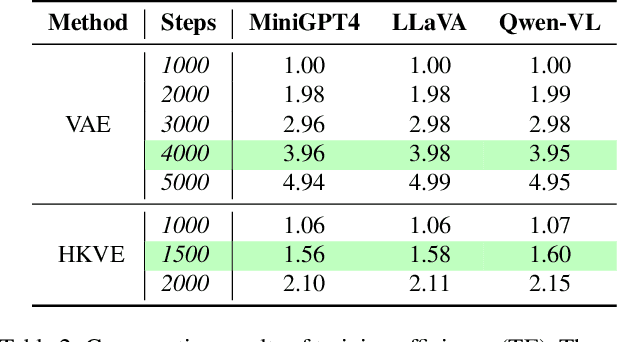
In the realm of large vision-language models (LVLMs), adversarial jailbreak attacks serve as a red-teaming approach to identify safety vulnerabilities of these models and their associated defense mechanisms. However, we identify a critical limitation: not every adversarial optimization step leads to a positive outcome, and indiscriminately accepting optimization results at each step may reduce the overall attack success rate. To address this challenge, we introduce HKVE (Hierarchical Key-Value Equalization), an innovative jailbreaking framework that selectively accepts gradient optimization results based on the distribution of attention scores across different layers, ensuring that every optimization step positively contributes to the attack. Extensive experiments demonstrate HKVE's significant effectiveness, achieving attack success rates of 75.08% on MiniGPT4, 85.84% on LLaVA and 81.00% on Qwen-VL, substantially outperforming existing methods by margins of 20.43\%, 21.01\% and 26.43\% respectively. Furthermore, making every step effective not only leads to an increase in attack success rate but also allows for a reduction in the number of iterations, thereby lowering computational costs. Warning: This paper contains potentially harmful example data.
SVIP: Semantically Contextualized Visual Patches for Zero-Shot Learning
Mar 13, 2025



Zero-shot learning (ZSL) aims to recognize unseen classes without labeled training examples by leveraging class-level semantic descriptors such as attributes. A fundamental challenge in ZSL is semantic misalignment, where semantic-unrelated information involved in visual features introduce ambiguity to visual-semantic interaction. Unlike existing methods that suppress semantic-unrelated information post hoc either in the feature space or the model space, we propose addressing this issue at the input stage, preventing semantic-unrelated patches from propagating through the network. To this end, we introduce Semantically contextualized VIsual Patches (SVIP) for ZSL, a transformer-based framework designed to enhance visual-semantic alignment. Specifically, we propose a self-supervised patch selection mechanism that preemptively learns to identify semantic-unrelated patches in the input space. This is trained with the supervision from aggregated attention scores across all transformer layers, which estimate each patch's semantic score. As removing semantic-unrelated patches from the input sequence may disrupt object structure, we replace them with learnable patch embeddings. With initialization from word embeddings, we can ensure they remain semantically meaningful throughout feature extraction. Extensive experiments on ZSL benchmarks demonstrate that SVIP achieves state-of-the-art performance results while providing more interpretable and semantically rich feature representations.
StableFusion: Continual Video Retrieval via Frame Adaptation
Mar 13, 2025



Text-to-Video Retrieval (TVR) aims to match videos with corresponding textual queries, yet the continual influx of new video content poses a significant challenge for maintaining system performance over time. In this work, we introduce the first benchmark for Continual Text-to-Video Retrieval (CTVR) to overcome these limitations. Our analysis reveals that current TVR methods based on pre-trained models struggle to retain plasticity when adapting to new tasks, while existing continual learning approaches experience catastrophic forgetting, resulting in semantic misalignment between historical queries and stored video features. To address these challenges, we propose StableFusion, a novel CTVR framework comprising two main components: the Frame Fusion Adapter (FFA), which captures temporal dynamics in video content while preserving model flexibility, and the Task-Aware Mixture-of-Experts (TAME), which maintains consistent semantic alignment between queries across tasks and the stored video features. Comprehensive evaluations on two benchmark datasets under various task settings demonstrate that StableFusion outperforms existing continual learning and TVR methods, achieving superior retrieval performance with minimal degradation on earlier tasks in the context of continuous video streams. Our code is available at: https://github.com/JasonCodeMaker/CTVR
TT-GaussOcc: Test-Time Compute for Self-Supervised Occupancy Prediction via Spatio-Temporal Gaussian Splatting
Mar 11, 2025



Self-supervised 3D occupancy prediction offers a promising solution for understanding complex driving scenes without requiring costly 3D annotations. However, training dense voxel decoders to capture fine-grained geometry and semantics can demand hundreds of GPU hours, and such models often fail to adapt to varying voxel resolutions or new classes without extensive retraining. To overcome these limitations, we propose a practical and flexible test-time occupancy prediction framework termed TT-GaussOcc. Our approach incrementally optimizes time-aware 3D Gaussians instantiated from raw sensor streams at runtime, enabling voxelization at arbitrary user-specified resolution. Specifically, TT-GaussOcc operates in a "lift-move-voxel" symphony: we first "lift" surrounding-view semantics obtained from 2D vision foundation models (VLMs) to instantiate Gaussians at non-empty 3D space; Next, we "move" dynamic Gaussians from previous frames along estimated Gaussian scene flow to complete appearance and eliminate trailing artifacts of fast-moving objects, while accumulating static Gaussians to enforce temporal consistency; Finally, we mitigate inherent noises in semantic predictions and scene flow vectors by periodically smoothing neighboring Gaussians during optimization, using proposed trilateral RBF kernels that jointly consider color, semantic, and spatial affinities. The historical static and current dynamic Gaussians are then combined and voxelized to generate occupancy prediction. Extensive experiments on Occ3D and nuCraft with varying voxel resolutions demonstrate that TT-GaussOcc surpasses self-supervised baselines by 46% on mIoU without any offline training, and supports finer voxel resolutions at 2.6 FPS inference speed.
MAA: Meticulous Adversarial Attack against Vision-Language Pre-trained Models
Feb 12, 2025Current adversarial attacks for evaluating the robustness of vision-language pre-trained (VLP) models in multi-modal tasks suffer from limited transferability, where attacks crafted for a specific model often struggle to generalize effectively across different models, limiting their utility in assessing robustness more broadly. This is mainly attributed to the over-reliance on model-specific features and regions, particularly in the image modality. In this paper, we propose an elegant yet highly effective method termed Meticulous Adversarial Attack (MAA) to fully exploit model-independent characteristics and vulnerabilities of individual samples, achieving enhanced generalizability and reduced model dependence. MAA emphasizes fine-grained optimization of adversarial images by developing a novel resizing and sliding crop (RScrop) technique, incorporating a multi-granularity similarity disruption (MGSD) strategy. Extensive experiments across diverse VLP models, multiple benchmark datasets, and a variety of downstream tasks demonstrate that MAA significantly enhances the effectiveness and transferability of adversarial attacks. A large cohort of performance studies is conducted to generate insights into the effectiveness of various model configurations, guiding future advancements in this domain.