 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpectation-Maximization Attention Networks for Semantic Segmentation
Aug 16, 2019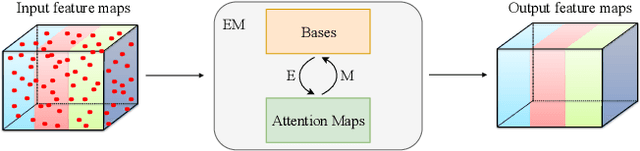
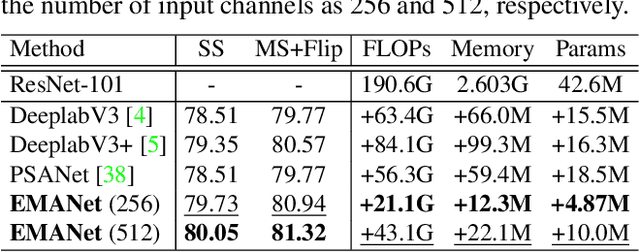
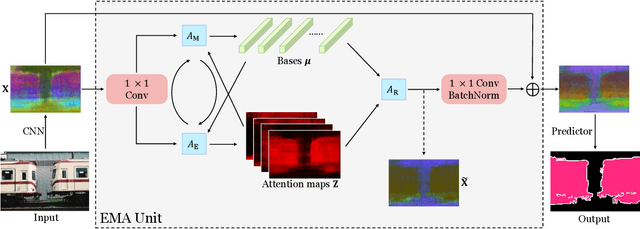
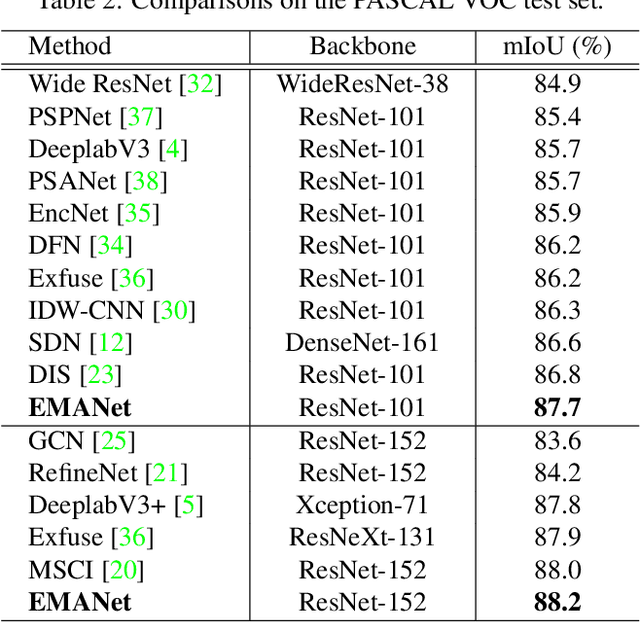
Self-attention mechanism has been widely used for various tasks. It is designed to compute the representation of each position by a weighted sum of the features at all positions. Thus, it can capture long-range relations for computer vision tasks. However, it is computationally consuming. Since the attention maps are computed w.r.t all other positions. In this paper, we formulate the attention mechanism into an expectation-maximization manner and iteratively estimate a much more compact set of bases upon which the attention maps are computed. By a weighted summation upon these bases, the resulting representation is low-rank and deprecates noisy information from the input. The proposed Expectation-Maximization Attention (EMA) module is robust to the variance of input and is also friendly in memory and computation. Moreover, we set up the bases maintenance and normalization methods to stabilize its training procedure. We conduct extensive experiments on popular semantic segmentation benchmarks including PASCAL VOC, PASCAL Context and COCO Stuff, on which we set new records.
AdaGCN: Adaboosting Graph Convolutional Networks into Deep Models
Aug 14, 2019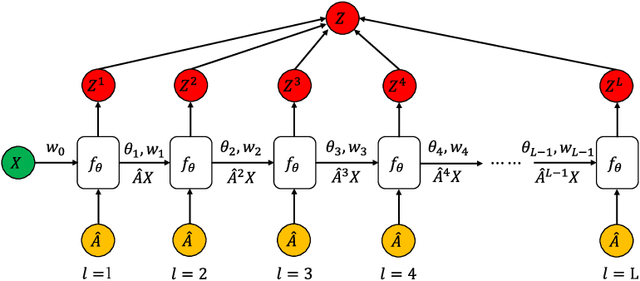

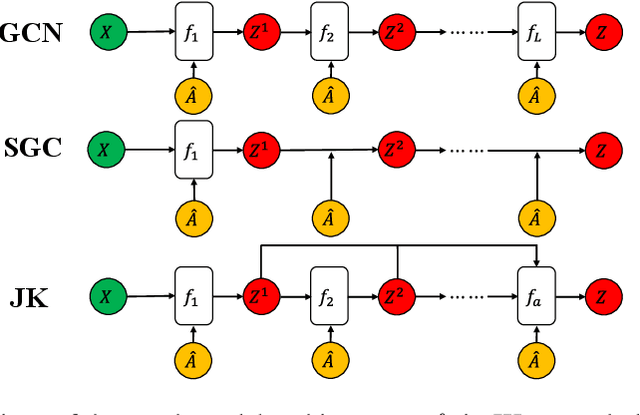
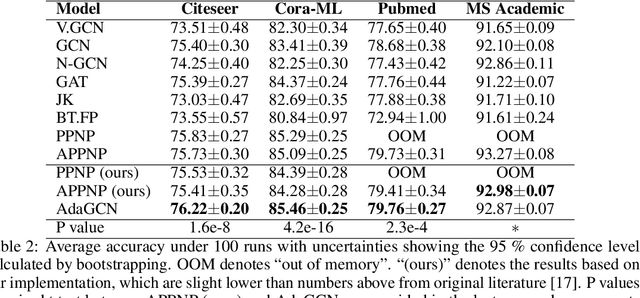
The design of deep graph models still remains to be investigated and the crucial part is how to explore and exploit the knowledge from different hops of neighbors in an efficient way. In this paper, we propose a novel RNN-like deep graph neural network architecture by incorporating AdaBoost into the computation of network; and the proposed graph convolutional network called AdaGCN~(AdaBoosting Graph Convolutional Network) has the ability to efficiently extract knowledge from high-order neighbors and integrate knowledge from different hops of neighbors into the network in an AdaBoost way. We also present the architectural difference between AdaGCN and existing graph convolutional methods to show the benefits of our proposal. Finally, extensive experiments demonstrate the state-of-the-art prediction performance and the computational advantage of our approach AdaGCN.
ADA-Tucker: Compressing Deep Neural Networks via Adaptive Dimension Adjustment Tucker Decomposition
Jun 18, 2019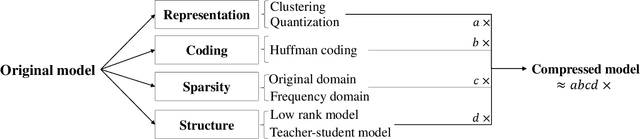
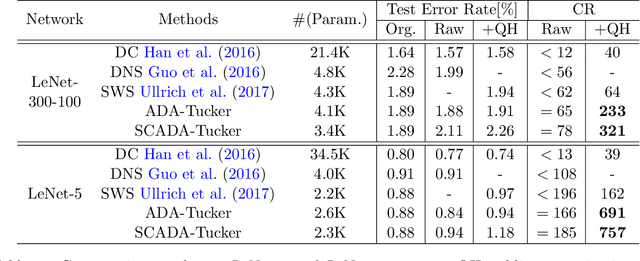
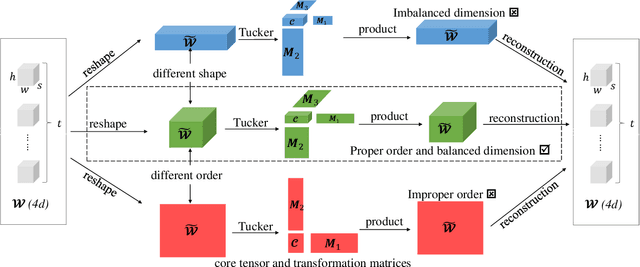

Despite the recent success of deep learning models in numerous applications, their widespread use on mobile devices is seriously impeded by storage and computational requirements. In this paper, we propose a novel network compression method called Adaptive Dimension Adjustment Tucker decomposition (ADA-Tucker). With learnable core tensors and transformation matrices, ADA-Tucker performs Tucker decomposition of arbitrary-order tensors. Furthermore, we propose that weight tensors in networks with proper order and balanced dimension are easier to be compressed. Therefore, the high flexibility in decomposition choice distinguishes ADA-Tucker from all previous low-rank models. To compress more, we further extend the model to Shared Core ADA-Tucker (SCADA-Tucker) by defining a shared core tensor for all layers. Our methods require no overhead of recording indices of non-zero elements. Without loss of accuracy, our methods reduce the storage of LeNet-5 and LeNet-300 by ratios of 691 times and 233 times, respectively, significantly outperforming state of the art. The effectiveness of our methods is also evaluated on other three benchmarks (CIFAR-10, SVHN, ILSVRC12) and modern newly deep networks (ResNet, Wide-ResNet).
* 25 pages, 12 figures
Differentiable Linearized ADMM
May 15, 2019
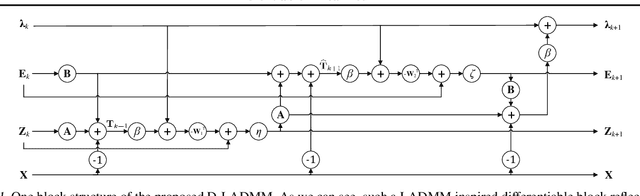
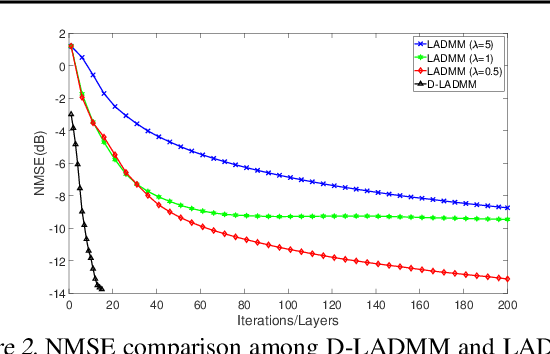
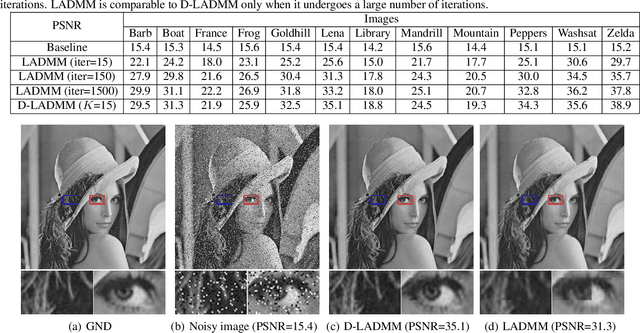
Recently, a number of learning-based optimization methods that combine data-driven architectures with the classical optimization algorithms have been proposed and explored, showing superior empirical performance in solving various ill-posed inverse problems, but there is still a scarcity of rigorous analysis about the convergence behaviors of learning-based optimization. In particular, most existing analyses are specific to unconstrained problems but cannot apply to the more general cases where some variables of interest are subject to certain constraints. In this paper, we propose Differentiable Linearized ADMM (D-LADMM) for solving the problems with linear constraints. Specifically, D-LADMM is a K-layer LADMM inspired deep neural network, which is obtained by firstly introducing some learnable weights in the classical Linearized ADMM algorithm and then generalizing the proximal operator to some learnable activation function. Notably, we rigorously prove that there exist a set of learnable parameters for D-LADMM to generate globally converged solutions, and we show that those desired parameters can be attained by training D-LADMM in a proper way. To the best of our knowledge, we are the first to provide the convergence analysis for the learning-based optimization method on constrained problems.
Self-Supervised Convolutional Subspace Clustering Network
May 01, 2019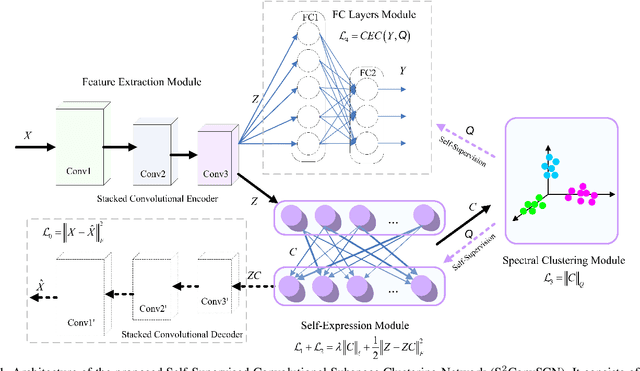
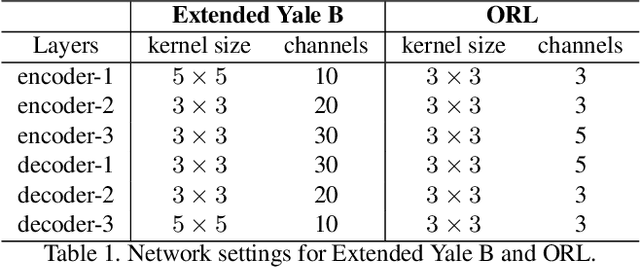
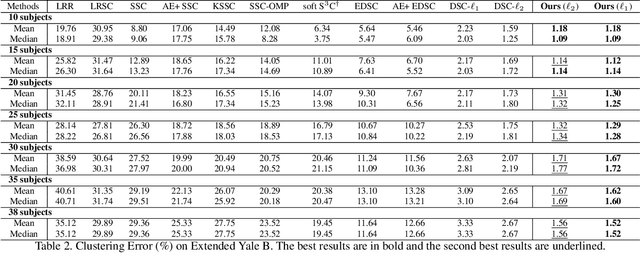
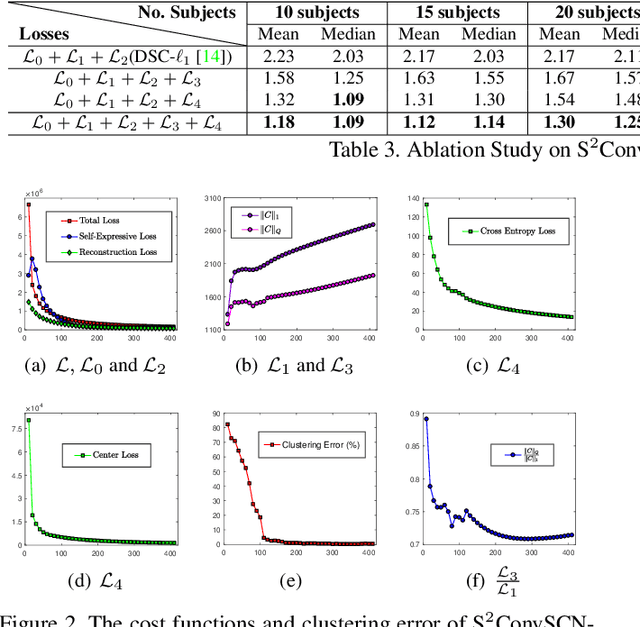
Subspace clustering methods based on data self-expression have become very popular for learning from data that lie in a union of low-dimensional linear subspaces. However, the applicability of subspace clustering has been limited because practical visual data in raw form do not necessarily lie in such linear subspaces. On the other hand, while Convolutional Neural Network (ConvNet) has been demonstrated to be a powerful tool for extracting discriminative features from visual data, training such a ConvNet usually requires a large amount of labeled data, which are unavailable in subspace clustering applications. To achieve simultaneous feature learning and subspace clustering, we propose an end-to-end trainable framework, called Self-Supervised Convolutional Subspace Clustering Network (S$^2$ConvSCN), that combines a ConvNet module (for feature learning), a self-expression module (for subspace clustering) and a spectral clustering module (for self-supervision) into a joint optimization framework. Particularly, we introduce a dual self-supervision that exploits the output of spectral clustering to supervise the training of the feature learning module (via a classification loss) and the self-expression module (via a spectral clustering loss). Our experiments on four benchmark datasets show the effectiveness of the dual self-supervision and demonstrate superior performance of our proposed approach.
Deep Comprehensive Correlation Mining for Image Clustering
Apr 16, 2019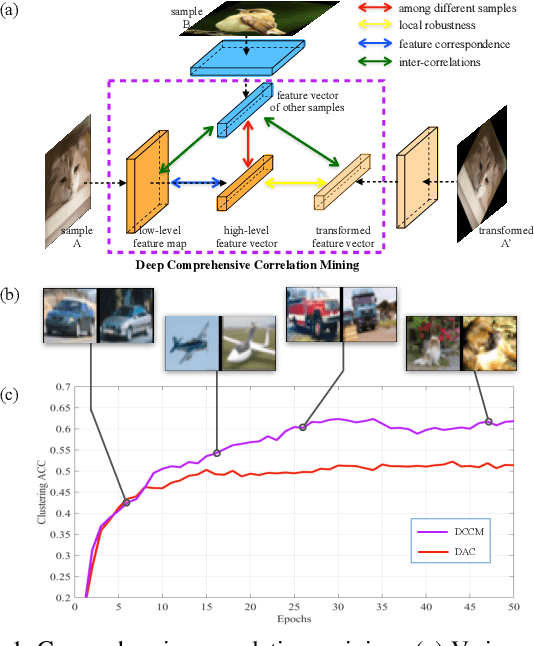
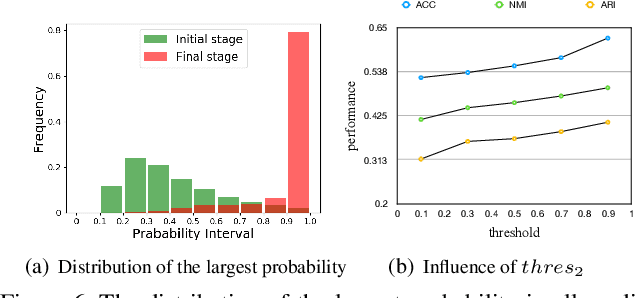
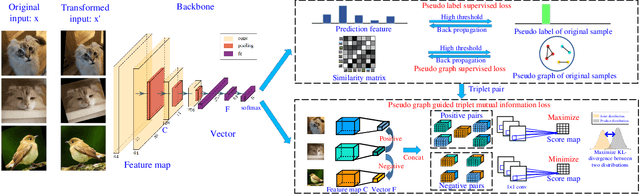
Recent developed deep unsupervised methods allow us to jointly learn representation and cluster unlabelled data. These deep clustering methods mainly focus on the correlation among samples, e.g., selecting high precision pairs to gradually tune the feature representation, which neglects other useful correlations. In this paper, we propose a novel clustering framework, named deep comprehensive correlation mining(DCCM), for exploring and taking full advantage of various kinds of correlations behind the unlabeled data from three aspects: 1) Instead of only using pair-wise information, pseudo-label supervision is proposed to investigate category information and learn discriminative features. 2) The features' robustness to image transformation of input space is fully explored, which benefits the network learning and significantly improves the performance. 3) The triplet mutual information among features is presented for clustering problem to lift the recently discovered instance-level deep mutual information to a triplet-level formation, which further helps to learn more discriminative features. Extensive experiments on several challenging datasets show that our method achieves good performance, e.g., attaining $62.3\%$ clustering accuracy on CIFAR-10, and $34.0\%$ on CIFAR-100, both of which significantly surpass the state-of-the-art results more than $10.0\%$.
Virtual Adversarial Training on Graph Convolutional Networks in Node Classification
Feb 28, 2019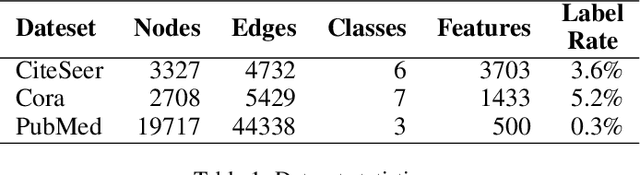
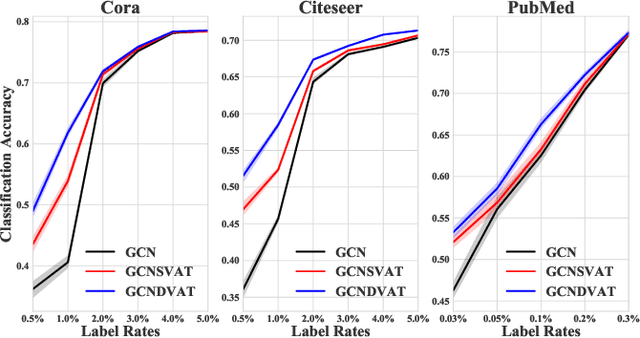
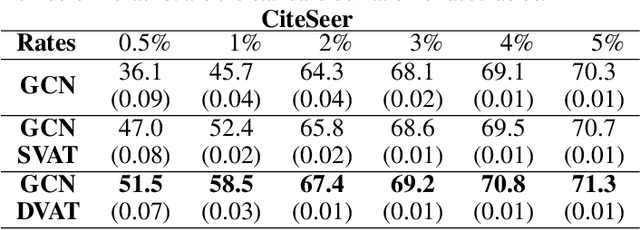
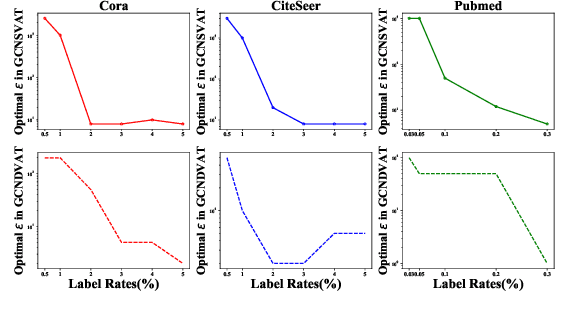
The effectiveness of Graph Convolutional Networks (GCNs) has been demonstrated in a wide range of graph-based machine learning tasks. However, the update of parameters in GCNs is only from labeled nodes, lacking the utilization of unlabeled data. In this paper, we apply Virtual Adversarial Training (VAT), an adversarial regularization method based on both labeled and unlabeled data, on the supervised loss of GCN to enhance its generalization performance. By imposing virtually adversarial smoothness on the posterior distribution in semi-supervised learning, VAT yields improvement on the Symmetrical Laplacian Smoothness of GCNs. In addition, due to the difference of property in features, we perturb virtual adversarial perturbations on sparse and dense features, resulting in GCN Sparse VAT (GCNSVAT) and GCN Dense VAT (GCNDVAT) algorithms, respectively. Extensive experiments verify the effectiveness of our two methods across different training sizes. Our work paves the way towards better understanding the direction of improvement on GCNs in the future.
Multi-Stage Self-Supervised Learning for Graph Convolutional Networks
Feb 28, 2019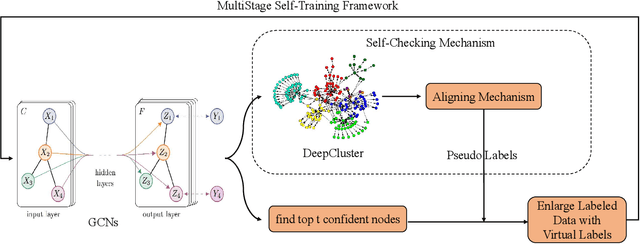
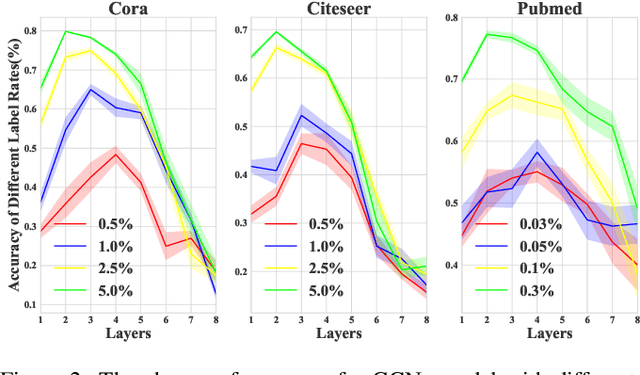
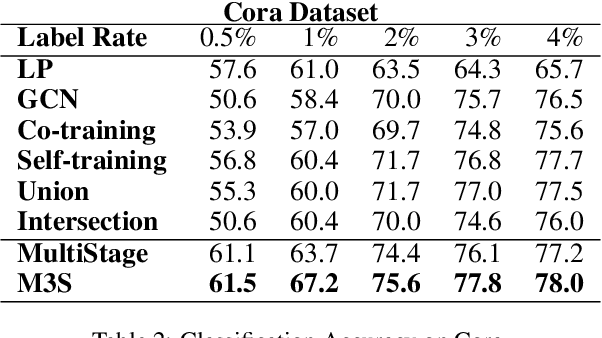
Graph Convolutional Networks(GCNs) play a crucial role in graph learning tasks, however, learning graph embedding with few supervised signals is still a difficult problem. In this paper, we propose a novel training algorithm for Graph Convolutional Network, called Multi-Stage Self-Supervised(M3S) Training Algorithm, combined with self-supervised learning approach, focusing on improving the generalization performance of GCNs on graphs with few labeled nodes. Firstly, a Multi-Stage Training Framework is provided as the basis of M3S training method. Then we leverage DeepCluster technique, a popular form of self-supervised learning, and design corresponding aligning mechanism on the embedding space to refine the Multi-Stage Training Framework, resulting in M3S Training Algorithm. Finally, extensive experimental results verify the superior performance of our algorithm on graphs with few labeled nodes under different label rates compared with other state-of-the-art approaches.
Enhancing the Robustness of Deep Neural Networks by Boundary Conditional GAN
Feb 28, 2019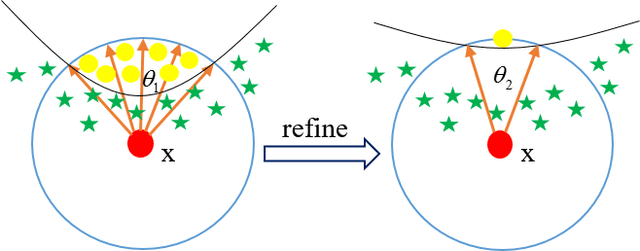
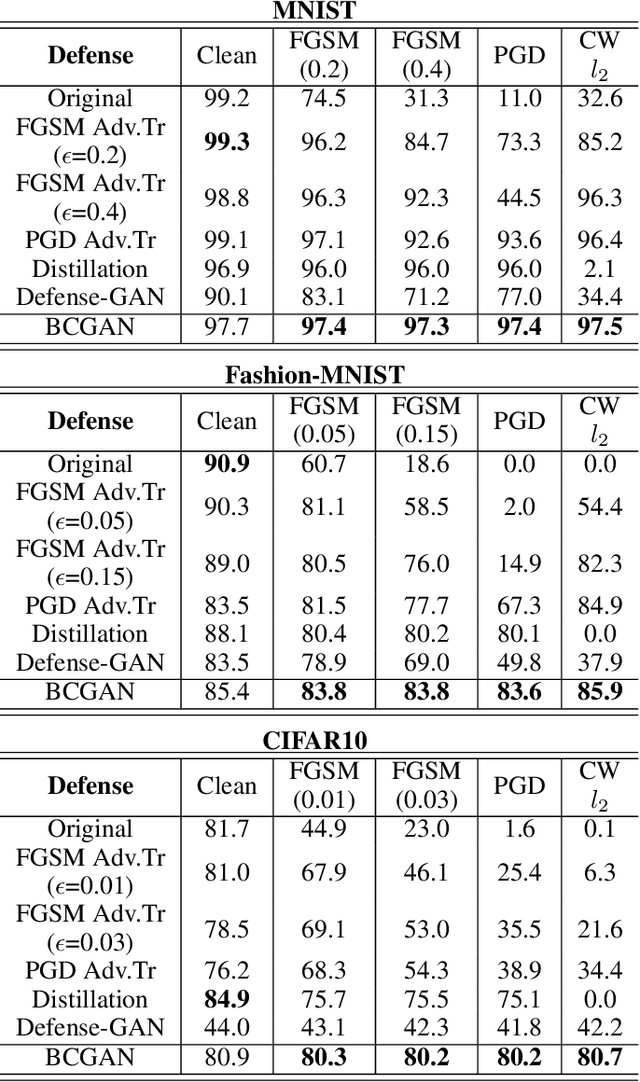
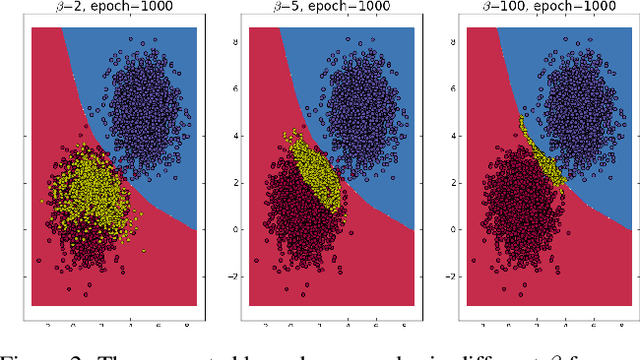
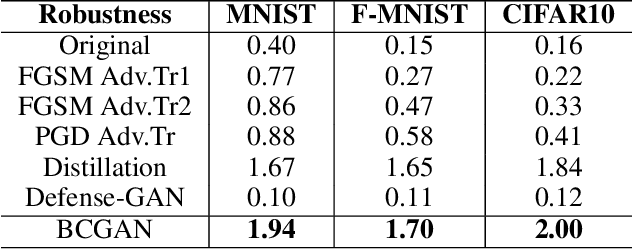
Deep neural networks have been widely deployed in various machine learning tasks. However, recent works have demonstrated that they are vulnerable to adversarial examples: carefully crafted small perturbations to cause misclassification by the network. In this work, we propose a novel defense mechanism called Boundary Conditional GAN to enhance the robustness of deep neural networks against adversarial examples. Boundary Conditional GAN, a modified version of Conditional GAN, can generate boundary samples with true labels near the decision boundary of a pre-trained classifier. These boundary samples are fed to the pre-trained classifier as data augmentation to make the decision boundary more robust. We empirically show that the model improved by our approach consistently defenses against various types of adversarial attacks successfully. Further quantitative investigations about the improvement of robustness and visualization of decision boundaries are also provided to justify the effectiveness of our strategy. This new defense mechanism that uses boundary samples to enhance the robustness of networks opens up a new way to defense adversarial attacks consistently.
Towards Understanding Adversarial Examples Systematically: Exploring Data Size, Task and Model Factors
Feb 28, 2019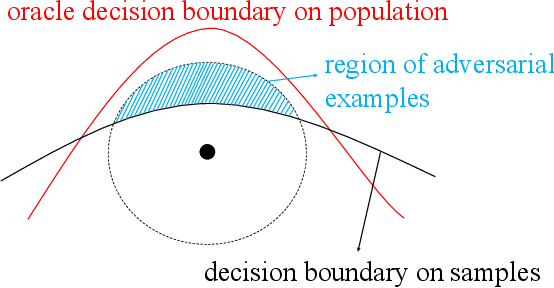
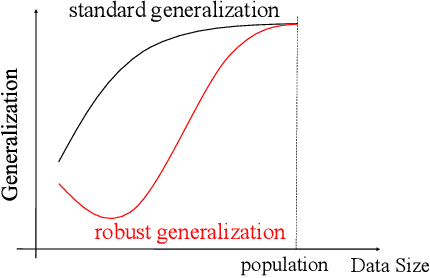
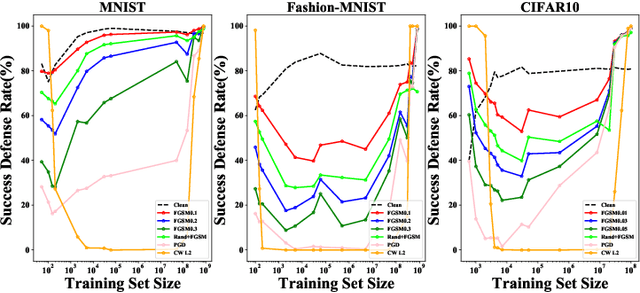
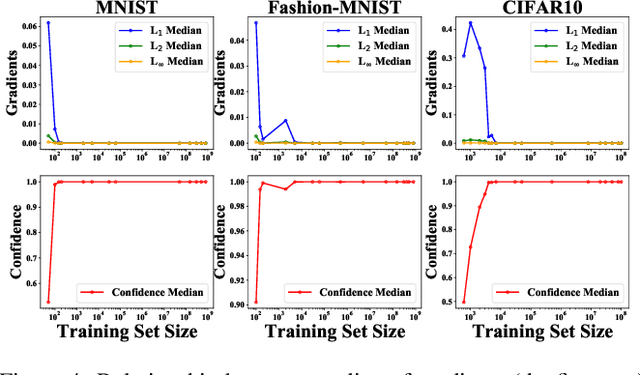
Most previous works usually explained adversarial examples from several specific perspectives, lacking relatively integral comprehension about this problem. In this paper, we present a systematic study on adversarial examples from three aspects: the amount of training data, task-dependent and model-specific factors. Particularly, we show that adversarial generalization (i.e. test accuracy on adversarial examples) for standard training requires more data than standard generalization (i.e. test accuracy on clean examples); and uncover the global relationship between generalization and robustness with respect to the data size especially when data is augmented by generative models. This reveals the trade-off correlation between standard generalization and robustness in limited training data regime and their consistency when data size is large enough. Furthermore, we explore how different task-dependent and model-specific factors influence the vulnerability of deep neural networks by extensive empirical analysis. Relevant recommendations on defense against adversarial attacks are provided as well. Our results outline a potential path towards the luminous and systematic understanding of adversarial examples.