 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimization-inspired Image Propagation with Control Mechanisms and Architecture Augmentations for Low-level Vision
Dec 10, 2020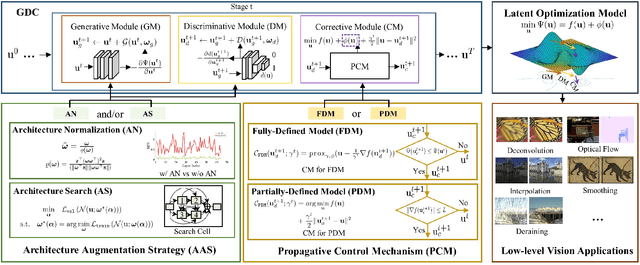



In recent years, building deep learning models from optimization perspectives has becoming a promising direction for solving low-level vision problems. The main idea of most existing approaches is to straightforwardly combine numerical iterations with manually designed network architectures to generate image propagations for specific kinds of optimization models. However, these heuristic learning models often lack mechanisms to control the propagation and rely on architecture engineering heavily. To mitigate the above issues, this paper proposes a unified optimization-inspired deep image propagation framework to aggregate Generative, Discriminative and Corrective (GDC for short) principles for a variety of low-level vision tasks. Specifically, we first formulate low-level vision tasks using a generic optimization objective and construct our fundamental propagative modules from three different viewpoints, i.e., the solution could be obtained/learned 1) in generative manner; 2) based on discriminative metric, and 3) with domain knowledge correction. By designing control mechanisms to guide image propagations, we then obtain convergence guarantees of GDC for both fully- and partially-defined optimization formulations. Furthermore, we introduce two architecture augmentation strategies (i.e., normalization and automatic search) to respectively enhance the propagation stability and task/data-adaption ability. Extensive experiments on different low-level vision applications demonstrate the effectiveness and flexibility of GDC.
A Multi-scale Optimization Learning Framework for Diffeomorphic Deformable Registration
Apr 30, 2020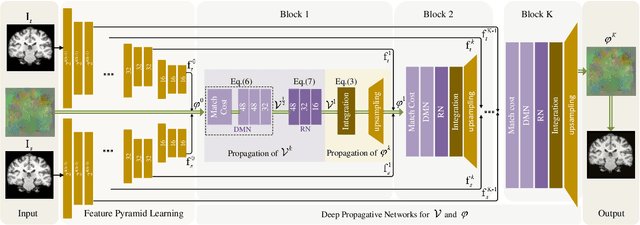


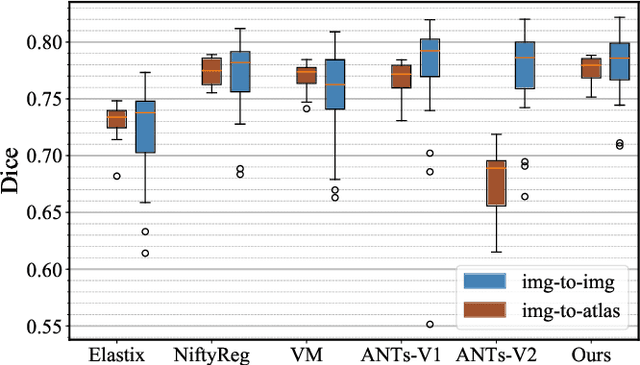
Conventional deformable registration methods aim at solving a specifically designed optimization model on image pairs and offer a rigorous theoretical treatment. However, their computational costs are exceptionally high. In contrast, recent learning-based approaches can provide fast deformation estimation. These heuristic network architectures are fully data-driven and thus lack explicitly domain knowledge or geometric constraints, such as topology-preserving, which is indispensable to generate plausible deformations. To integrate the advantages and avoid the limitations of these two categories of approaches, we design a new learning-based framework to optimize a diffeomorphic model via multi-scale propagations. Specifically, we first introduce a generic optimization model to formulate diffeomorphic registration with both velocity and deformation fields. Then we propose a schematic optimization scheme with a nested splitting technique. Finally, a series of learnable architectures are utilized to obtain the final propagative updating in the coarse-to-fine feature spaces. We conduct two groups of image registration experiments on 3D adult and child brain MR volume datasets including image-to-atlas and image-to-image registrations. Extensive results demonstrate that the proposed method achieves state-of-the-art performance with diffeomorphic guarantee and extreme efficiency.
Converged Deep Framework Assembling Principled Modules for CS-MRI
Oct 29, 2019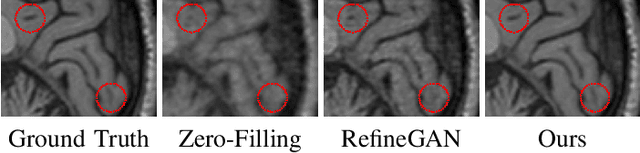
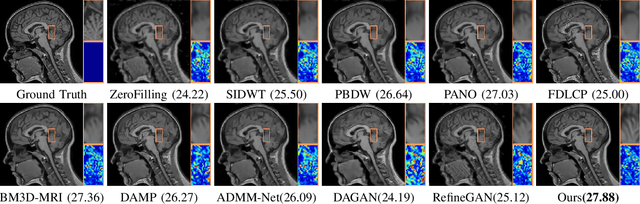

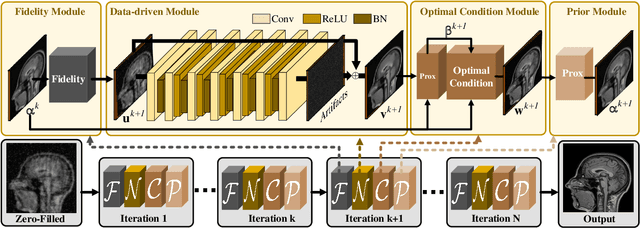
Compressed Sensing Magnetic Resonance Imaging (CS-MRI) significantly accelerates MR data acquisition at a sampling rate much lower than the Nyquist criterion. A major challenge for CS-MRI lies in solving the severely ill-posed inverse problem to reconstruct aliasing-free MR images from the sparse k-space data. Conventional methods typically optimize an energy function, producing reconstruction of high quality, but their iterative numerical solvers unavoidably bring extremely slow processing. Recent data-driven techniques are able to provide fast restoration by either learning direct prediction to final reconstruction or plugging learned modules into the energy optimizer. Nevertheless, these data-driven predictors cannot guarantee the reconstruction following constraints underlying the regularizers of conventional methods so that the reliability of their reconstruction results are questionable. In this paper, we propose a converged deep framework assembling principled modules for CS-MRI that fuses learning strategy with the iterative solver of a conventional reconstruction energy. This framework embeds an optimal condition checking mechanism, fostering \emph{efficient} and \emph{reliable} reconstruction. We also apply the framework to two practical tasks, \emph{i.e.}, parallel imaging and reconstruction with Rician noise. Extensive experiments on both benchmark and manufacturer-testing images demonstrate that the proposed method reliably converges to the optimal solution more efficiently and accurately than the state-of-the-art in various scenarios.
Investigating Task-driven Latent Feasibility for Nonconvex Image Modeling
Oct 18, 2019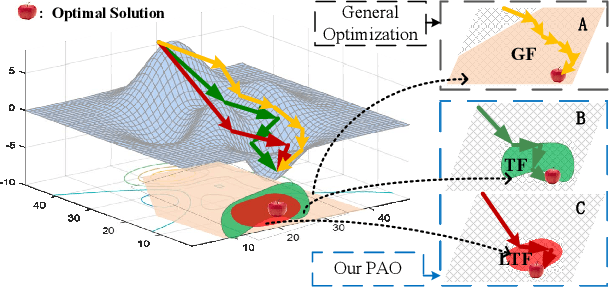


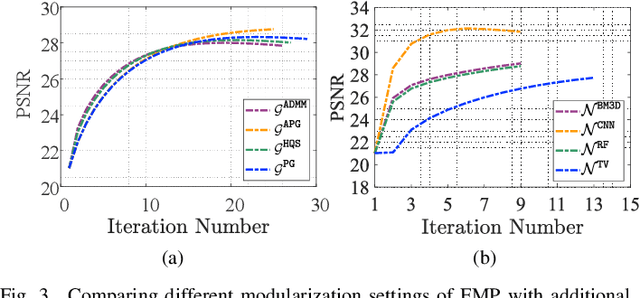
Properly modeling the latent image distributions always plays a key role in a variety of low-level vision problems. Most existing approaches, such as Maximum A Posterior (MAP), aimed at establishing optimization models with prior regularization to address this task. However, designing sophisticated priors may lead to challenging optimization model and time-consuming iteration process. Recent studies tried to embed learnable network architectures into the MAP scheme. Unfortunately, for the MAP model with deeply trained priors, the exact behaviors and the inference process are actually hard to investigate, due to their inexact and uncontrolled nature. In this work, by investigating task-driven latent feasibility for the MAP-based model, we provide a new perspective to enforce domain knowledge and data distributions to MAP-based image modeling. Specifically, we first introduce an energy-based feasibility constraint to the given MAP model. By introducing the proximal gradient updating scheme to the objective and performing an adaptive averaging process, we obtain a completely new MAP inference process, named Proximal Average Optimization (PAO), for image modeling. Owning to the flexibility of PAO, we can also incorporate deeply trained architectures into the feasibility module. Finally, we provide a simple monotone descent-based control mechanism to guide the propagation of PAO. We prove in theory that the sequence generated by both our PAO and its learning-based extension can successfully converge to the critical point of the original MAP optimization task. We demonstrate how to apply our framework to address different vision applications. Extensive experiments verify the theoretical results and show the advantages of our method against existing state-of-the-art approaches.
Underexposed Image Correction via Hybrid Priors Navigated Deep Propagation
Jul 17, 2019



Enhancing visual qualities for underexposed images is an extensively concerned task that plays important roles in various areas of multimedia and computer vision. Most existing methods often fail to generate high-quality results with appropriate luminance and abundant details. To address these issues, we in this work develop a novel framework, integrating both knowledge from physical principles and implicit distributions from data to solve the underexposed image correction task. More concretely, we propose a new perspective to formulate this task as an energy-inspired model with advanced hybrid priors. A propagation procedure navigated by the hybrid priors is well designed for simultaneously propagating the reflectance and illumination toward desired results. We conduct extensive experiments to verify the necessity of integrating both underlying principles (i.e., with knowledge) and distributions (i.e., from data) as navigated deep propagation. Plenty of experimental results of underexposed image correction demonstrate that our proposed method performs favorably against the state-of-the-art methods on both subjective and objective assessments. Additionally, we execute the task of face detection to further verify the naturalness and practical value of underexposed image correction. What's more, we employ our method to single image haze removal whose experimental results further demonstrate its superiorities.
Mode Collapse and Regularity of Optimal Transportation Maps
Feb 08, 2019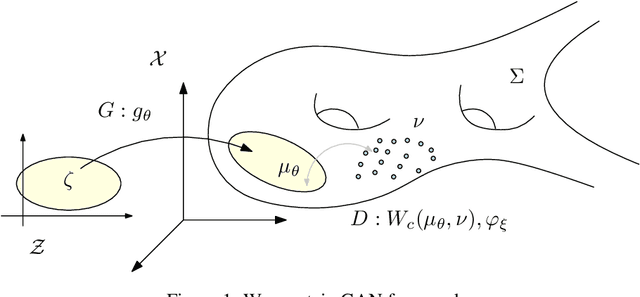
This work builds the connection between the regularity theory of optimal transportation map, Monge-Amp\`{e}re equation and GANs, which gives a theoretic understanding of the major drawbacks of GANs: convergence difficulty and mode collapse. According to the regularity theory of Monge-Amp\`{e}re equation, if the support of the target measure is disconnected or just non-convex, the optimal transportation mapping is discontinuous. General DNNs can only approximate continuous mappings. This intrinsic conflict leads to the convergence difficulty and mode collapse in GANs. We test our hypothesis that the supports of real data distribution are in general non-convex, therefore the discontinuity is unavoidable using an Autoencoder combined with discrete optimal transportation map (AE-OT framework) on the CelebA data set. The testing result is positive. Furthermore, we propose to approximate the continuous Brenier potential directly based on discrete Brenier theory to tackle mode collapse. Comparing with existing method, this method is more accurate and effective.
Real-world Underwater Enhancement: Challenging, Benchmark and Efficient Solutions
Jan 15, 2019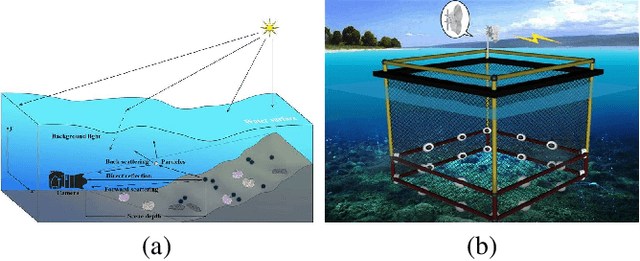



Underwater image enhancement is an important low-level vision task with many applications, and numerous algorithms have been proposed in recent years. Despite the demonstrated success, these results are often generated based on different assumptions using different datasets and metrics. In this paper, we propose a large-scale Realistic Underwater Image Enhancement (RUIE) dataset, in which all degraded images are divided into multiple sub-datasets according to natural underwater image quality evaluation metric and the degree of color deviation. Compared with exiting testing or training sets of realistic underwater scenes, the RUIE dataset contains three sub-datasets, which are specifically selected and classified for the experiment of non-reference image quality evaluation, color deviation and task-driven detection. Based on RUIE, we conduct extensive and systematic experiments to evaluate the effectiveness and limitations of various algorithms, on images with hierarchical classification of degradation. Our evaluation and analysis demonstrate the performance and limitations of state-of-the-art algorithms. The findings from these experiments not only confirm what is commonly believed, but also suggest new research directions. More importantly, we recognize that underwater image enhancement in practice usually serves as the preprocessing step for mid-level and high-level vision tasks. We thus propose to exploit the object detection performance on the enhanced images as a brand-new `task-specific' evaluation criterion for underwater image enhancement algorithms.
A Theoretically Guaranteed Deep Optimization Framework for Robust Compressive Sensing MRI
Nov 13, 2018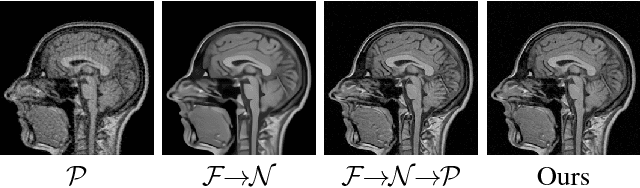

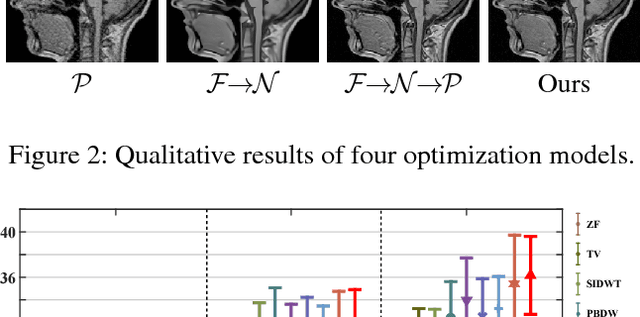
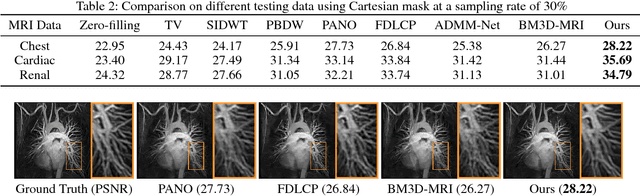
Magnetic Resonance Imaging (MRI) is one of the most dynamic and safe imaging techniques available for clinical applications. However, the rather slow speed of MRI acquisitions limits the patient throughput and potential indi cations. Compressive Sensing (CS) has proven to be an efficient technique for accelerating MRI acquisition. The most widely used CS-MRI model, founded on the premise of reconstructing an image from an incompletely filled k-space, leads to an ill-posed inverse problem. In the past years, lots of efforts have been made to efficiently optimize the CS-MRI model. Inspired by deep learning techniques, some preliminary works have tried to incorporate deep architectures into CS-MRI process. Unfortunately, the convergence issues (due to the experience-based networks) and the robustness (i.e., lack real-world noise modeling) of these deeply trained optimization methods are still missing. In this work, we develop a new paradigm to integrate designed numerical solvers and the data-driven architectures for CS-MRI. By introducing an optimal condition checking mechanism, we can successfully prove the convergence of our established deep CS-MRI optimization scheme. Furthermore, we explicitly formulate the Rician noise distributions within our framework and obtain an extended CS-MRI network to handle the real-world nosies in the MRI process. Extensive experimental results verify that the proposed paradigm outperforms the existing state-of-the-art techniques both in reconstruction accuracy and efficiency as well as robustness to noises in real scene.
On the Convergence of Learning-based Iterative Methods for Nonconvex Inverse Problems
Aug 16, 2018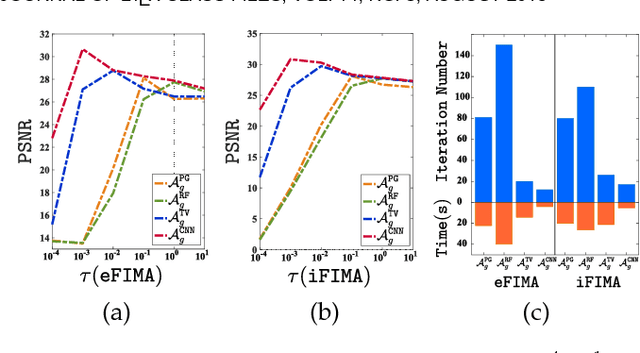
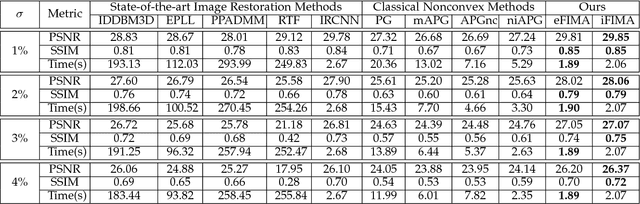
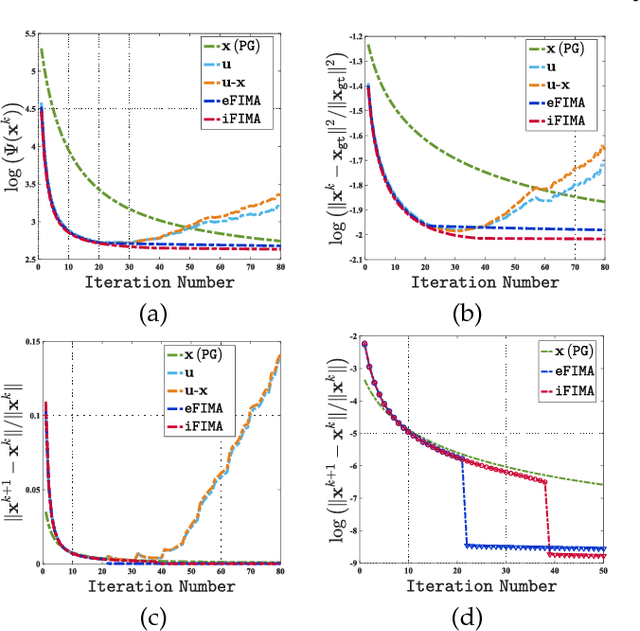
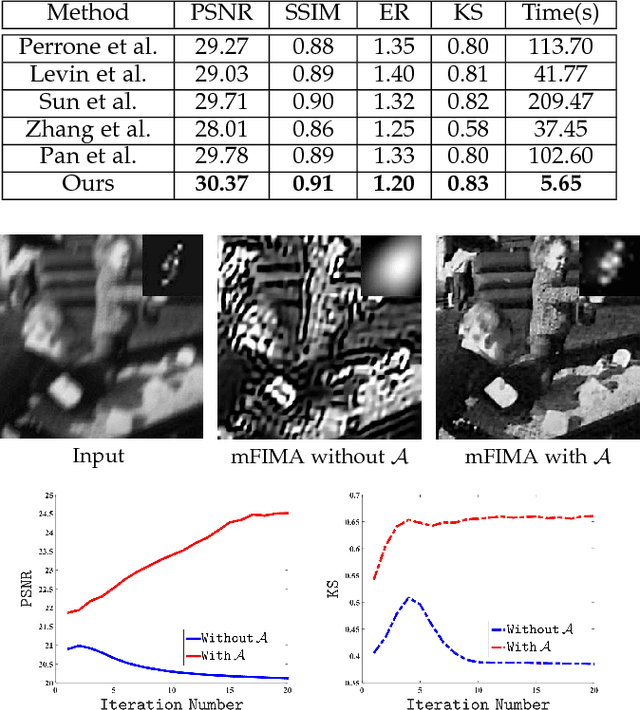
Numerous tasks at the core of statistics, learning and vision areas are specific cases of ill-posed inverse problems. Recently, learning-based (e.g., deep) iterative methods have been empirically shown to be useful for these problems. Nevertheless, integrating learnable structures into iterations is still a laborious process, which can only be guided by intuitions or empirical insights. Moreover, there is a lack of rigorous analysis about the convergence behaviors of these reimplemented iterations, and thus the significance of such methods is a little bit vague. This paper moves beyond these limits and proposes Flexible Iterative Modularization Algorithm (FIMA), a generic and provable paradigm for nonconvex inverse problems. Our theoretical analysis reveals that FIMA allows us to generate globally convergent trajectories for learning-based iterative methods. Meanwhile, the devised scheduling policies on flexible modules should also be beneficial for classical numerical methods in the nonconvex scenario. Extensive experiments on real applications verify the superiority of FIMA.
User-Guided Deep Anime Line Art Colorization with Conditional Adversarial Networks
Aug 10, 2018
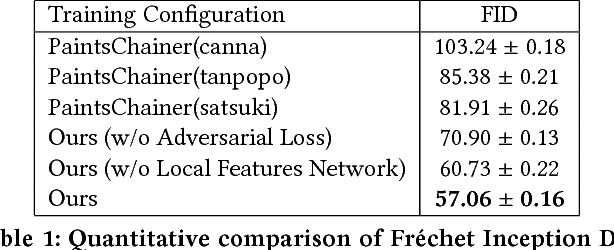
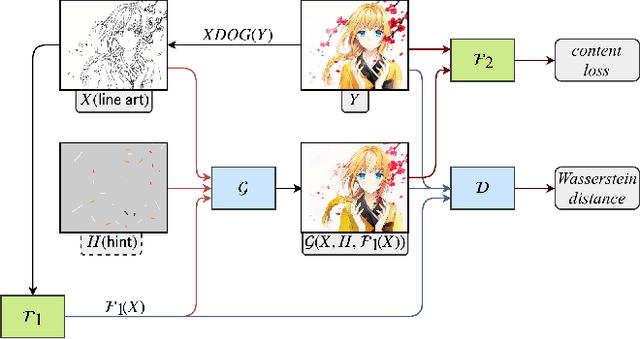
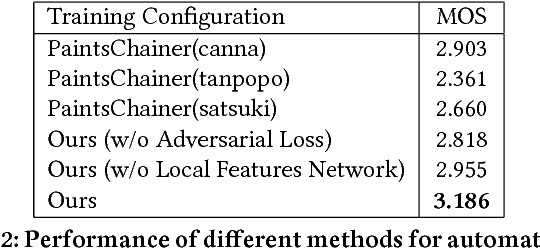
Scribble colors based line art colorization is a challenging computer vision problem since neither greyscale values nor semantic information is presented in line arts, and the lack of authentic illustration-line art training pairs also increases difficulty of model generalization. Recently, several Generative Adversarial Nets (GANs) based methods have achieved great success. They can generate colorized illustrations conditioned on given line art and color hints. However, these methods fail to capture the authentic illustration distributions and are hence perceptually unsatisfying in the sense that they often lack accurate shading. To address these challenges, we propose a novel deep conditional adversarial architecture for scribble based anime line art colorization. Specifically, we integrate the conditional framework with WGAN-GP criteria as well as the perceptual loss to enable us to robustly train a deep network that makes the synthesized images more natural and real. We also introduce a local features network that is independent of synthetic data. With GANs conditioned on features from such network, we notably increase the generalization capability over "in the wild" line arts. Furthermore, we collect two datasets that provide high-quality colorful illustrations and authentic line arts for training and benchmarking. With the proposed model trained on our illustration dataset, we demonstrate that images synthesized by the presented approach are considerably more realistic and precise than alternative approaches.